







 本文详细解析神经网络中的反向传播算法,包括代价函数的假设、反向传播的四个关键等式,以及如何计算权重和偏置的导数。反向传播通过逐层计算误差,有效地更新网络参数,是现代深度学习模型训练的核心部分。
本文详细解析神经网络中的反向传播算法,包括代价函数的假设、反向传播的四个关键等式,以及如何计算权重和偏置的导数。反向传播通过逐层计算误差,有效地更新网络参数,是现代深度学习模型训练的核心部分。
在上一节中简单介绍了神经网络的结够和sigmoid neuro,以及神经网络的目标函数和学习方法。但是没有讲如何调整权重,通常是需要对目标函数求导,也就是说回避了对目标函数求导这个问题。这一节就将讲述这个问题。
关于代价函数的两个假设
反向传播算法的目标是计算代价函数对
w,b
的偏微分
∂C∂w
和
∂C∂b
。这里拿二次代价函数为例子,二次代价函数形式如下:
C=12n∑x||y(x)−aL(x)||2
这里,n是总的训练数据的对数,x是输入数据,y(x)是对应的期望的输出,L表示神经网络的层数,
aL(x)
是当输入为x时输出层的激活函数的输出。
假设1
代价函数可以表示为总代价在每一个训练数据对上的平均代价。这样做就可以对每一个训练数据都对代价函数进行求导,在训练的时候是对每一个训练数据,每一次训练就可以调整一次权值。当前还一个好处就可以让代价和训练数据的数量无关。
假设2
代价函数可以写成神经网络的输出的函数。
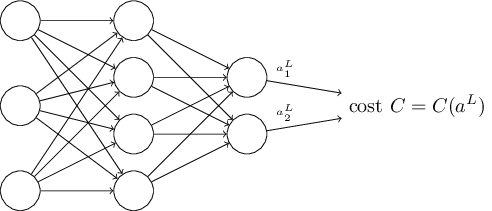
比如,对于上面说到的二次代价函数,对每一个输入
x
反向传播的四个等式
反向传播主要涉及到计算代价函数的偏微分,对每一个系数的微分,
∂C∂wljk
和
∂C∂blj
。为了计算这些偏微分,首先引入一个变量
δlj
,该变量表示第
l
层的第
首先是输出层的误差
δL
:
δLj=∂C∂aLjσ′(zLj)−−(BP1)
这是根据误差的定义来的,前面一项表示
∂C∂aLj
表示输出层第
j
个神经元的输出值的变化对代价函数的影响,如果代价函数不对某一个特别的神经元的输出敏感,则该项就会比较小。第二项
根据定义,
δLj=∂C∂zLj=∂C∂aLj∂aLj∂zLj=∂C∂aLjσ′(zLj)
.
把(BP1)写成向量的形式,
δL=∇aC⊙σ′(zL)=(aL−y)⊙σ′(zL)−−(BP1a)
用
l+1
层的误差项来表示
l
层的误差项
这里可以看到,第
l
的误差是把第
结合(BP1)(BP2)两个式子,就可以计算任意层的误差项。
证明:
δLj=∂C∂zlj
=∑k∂C∂zl+1k∂zl+1k∂zlj
=∑k∂zl+1k∂zljδl+1k
又因为有 zl+1k=∑jwl+1kjσ′(zlj) +b_k^{l+1},所以 ∂zl+1k∂zlj=wl+1kjσ′(zlj)
=∑kwl+1kjσ′(zlj)δl+1k
=((wl+1)Tδl+1)⊙σ′(zL)代价对偏置项 blj 的导数
∂C∂blj=δlj−−(BP3)
刚好就是我们前面定义的误差项。改写为向量形式。 ∂C∂b=δ代价对权重 wij 的导数
∂C∂wljk=al−1kδlj−−(BP4)
这样就可以把 wij 的导数用 al−1 和 δl 表示了,而这两者已经都计算出来了。改写一下:
∂C∂w=ainδout
这里可以理解为 ain 是神经元的激活输入, δout 是神经元的激活输出,连接两者的权重是 w ,注意,这里的输入、输出是相对反向而言的。
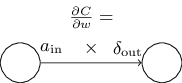
可以看出,当ain 很小时,导数 ∂C∂wjk 也将会比较小,这情况下,就说学习速率很慢。小结
反向传播算法
- 输入 x ,设置输入层对应的激活
a1 - 前向传播,对 l=2,3,...,L ,计算 zl=wlal−1+bl,al=σ(zl)
- 输出层误差,计算向量 δL=∇aC⊙σ′(zL)
- 反向传播误差,对 l=L−1,L−2,...2 ,计算 δl=((wl+1)Tδl+1)⊙σ′(zl)
输出,得到代价函数的梯度 ∂C∂wljk=al−1kδlj,∂C∂blj=δlj−−(BP3)
在实际中,使用的是最小堆随机梯度下降法mini-batch SGD,每次选定m个训练样本,对每一样本求导数,然后再平均,再应用到梯度下降的表达式中。
反向传播的代码
class Network(object): ... def update_mini_batch(self, mini_batch, eta): """Update the network's weights and biases by applying gradient descent using backpropagation to a single mini batch. The "mini_batch" is a list of tuples "(x, y)", and "eta" is the learning rate.""" nabla_b = [np.zeros(b.shape) for b in self.biases] nabla_w = [np.zeros(w.shape) for w in self.weights] for x, y in mini_batch: delta_nabla_b, delta_nabla_w = self.backprop(x, y) #累加导数项 nabla_b = [nb+dnb for nb, dnb in zip(nabla_b, delta_nabla_b)] nabla_w = [nw+dnw for nw, dnw in zip(nabla_w, delta_nabla_w)] self.weights = [w-(eta/len(mini_batch))*nw for w, nw in zip(self.weights, nabla_w)] self.biases = [b-(eta/len(mini_batch))*nb for b, nb in zip(self.biases, nabla_b)]大部分工是由 delta_nabla_b, delta_nabla_w = self.backprop(x, y) 这行代码做的。是用函数backpro计算两个导数项。
class Network(object): ... def backprop(self, x, y): """Return a tuple "(nabla_b, nabla_w)" representing the gradient for the cost function C_x. "nabla_b" and "nabla_w" are layer-by-layer lists of numpy arrays, similar to "self.biases" and "self.weights".""" nabla_b = [np.zeros(b.shape) for b in self.biases] nabla_w = [np.zeros(w.shape) for w in self.weights] # feedforward activation = x activations = [x] # list to store all the activations, layer by layer zs = [] # list to store all the z vectors, layer by layer for b, w in zip(self.biases, self.weights): z = np.dot(w, activation)+b zs.append(z) activation = sigmoid(z) activations.append(activation) # backward pass #首先计算最后一层的偏导数 delta = self.cost_derivative(activations[-1], y) * \ sigmoid_prime(zs[-1]) #公式(BP3) nabla_b[-1] = delta #公式(BP4) nabla_w[-1] = np.dot(delta, activations[-2].transpose()) # Note that the variable l in the loop below is used a little # differently to the notation in Chapter 2 of the book. Here, # l = 1 means the last layer of neurons, l = 2 is the # second-last layer, and so on. It's a renumbering of the # scheme in the book, used here to take advantage of the fact # that Python can use negative indices in lists. #在逐层反向传播,计算每一层的导数 for l in xrange(2, self.num_layers): z = zs[-l] sp = sigmoid_prime(z) delta = np.dot(self.weights[-l+1].transpose(), delta) * sp nabla_b[-l] = delta nabla_w[-l] = np.dot(delta, activations[-l-1].transpose()) return (nabla_b, nabla_w) ... def cost_derivative(self, output_activations, y): """Return the vector of partial derivatives \partial C_x / \partial a for the output activations.""" return (output_activations-y) def sigmoid(z): """The sigmoid function.""" return 1.0/(1.0+np.exp(-z)) def sigmoid_prime(z): """Derivative of the sigmoid function.""" return sigmoid(z)*(1-sigmoid(z))
彩蛋-为什么说反向传播是一种比较快的算法?
在其他地方很少有提到这一点的,大多数资料都会直接给你开始介绍反向传播算法的具体细节,然后说这是一个很有效的算法。实际上当神经元很多的时候,每两层的神经元之间两两连接,会有很多参数,计算起来还是会比较慢。那为什么说反向传播是一种比较快的算法呢?
要知道这一点,需要了解一些神经网络的历史。
最开始的时候,计算每一个权重的导数是通过近似的方法:
∂C∂wj≈C(w+ϵej)−C(w)ϵ
这个式子看上去很简单,也很好理解,比反向传播算法看上去简单多了。但是,实际上是很难计算的。因为需要对每一个 wj ,都做一个比较小的扰动,然后计算扰动后的代价函数,然后才能计算代价函数对 wj 的导数,如果有10000个参数,那就要计算10000次代价函数,而计算代价函数,必须要得到当前参数下神经网络的输出,结果就是要把神经网络的前向传播过程计算10000次!!
相反,对于反向传播算法,只需要对当前的输入 x <script id="MathJax-Element-20036" type="math/tex">x</script>计算一次,得到神经网络的预测值,然后通过反向传播算法,反向传播一次,就可以计算出所有的导数了!所以尽管反向传播看上去很复杂,但是确实是很有效!很快!
反向传播算法时在1980s提出来的,提出来之后,神经网络才开始又蓬勃发展了。参考
neuralnetworksanddeeplearning.com/chap2.html



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









