







 本文详细解析神经网络中的反向传播算法,包括代价函数的假设、反向传播的四个关键等式,以及如何计算权重和偏置的导数。反向传播通过逐层计算误差,有效地更新网络参数,是现代深度学习模型训练的核心部分。
本文详细解析神经网络中的反向传播算法,包括代价函数的假设、反向传播的四个关键等式,以及如何计算权重和偏置的导数。反向传播通过逐层计算误差,有效地更新网络参数,是现代深度学习模型训练的核心部分。
在上一节中简单介绍了神经网络的结够和sigmoid neuro,以及神经网络的目标函数和学习方法。但是没有讲如何调整权重,通常是需要对目标函数求导,也就是说回避了对目标函数求导这个问题。这一节就将讲述这个问题。
关于代价函数的两个假设
反向传播算法的目标是计算代价函数对 w,b 的偏微分 ∂C∂w 和 ∂C∂b 。这里拿二次代价函数为例子,二次代价函数形式如下:
C=12n∑x||y(x)−aL(x)||2
这里,n是总的训练数据的对数,x是输入数据,y(x)是对应的期望的输出,L表示神经网络的层数, aL(x) 是当输入为x时输出层的激活函数的输出。
假设1
代价函数可以表示为总代价在每一个训练数据对上的平均代价。这样做就可以对每一个训练数据都对代价函数进行求导,在训练的时候是对每一个训练数据,每一次训练就可以调整一次权值。当前还一个好处就可以让代价和训练数据的数量无关。
假设2
代价函数可以写成神经网络的输出的函数。
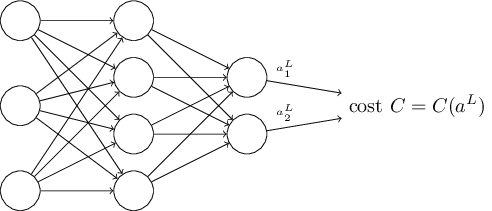
比如,对于上面说到的二次代价函数,对每一个输入 x
反向传播的四个等式
反向传播主要涉及到计算代价函数的偏微分,对每一个系数的微分, ∂C∂wljk 和 ∂C∂blj 。为了计算这些偏微分,首先引入一个变量 δlj ,该变量表示第 l 层的第
首先是输出层的误差 δL :
δLj=∂C∂aLj
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 623
623

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









