







上一章节学习了神经网络中的反向传播算法,反向传播算法的出现,使得大型神经网络的训练变得可能了。这一节,继续学习神经网络中常用到的一些小技巧,用来改善神经网络。
- 学习一个更好的代价函数,交叉熵代价函数。
- 四个正则化(regularization)的方法,L1、L2正则化,以及dropout,数据扩充(data argument),这些方法可以使神经网络有更好的泛化性
- 更好的初始化神经网络的方法
- 一系列选择 hyper-parameters 的启示
交叉熵函数-The cross-entropy cost function
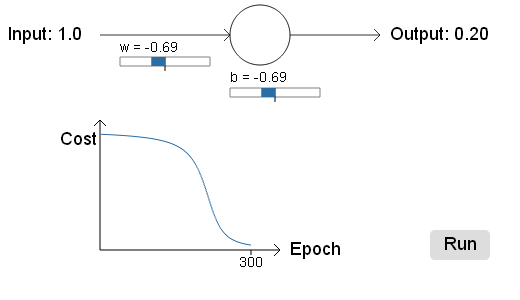
首先举个例子,当神经网络的输出不对时(输出为1,而正确的输出应该为0),可以发现刚开始学习的非常慢,差不多200epochs后cost才开始迅速下降,然后才学习到输出0。这和人类的学习过程是不相符的,因为如果错误了就应该很快就改正过来!而不是慢慢地改正过来。
那么为什么会这样呢?
来看看使用的代价函数,比如二次代价函数:
这里 a 是神经元的输出。
回忆sigmoid函数的曲线:
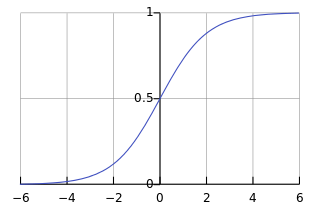
当输出接近1时,曲线的斜率很小,所以上面导数项中的 σ′(z) 就很小,就导致了 ∂C/∂w 和 ∂C/∂b 都很小。所以学习很慢learning slowly.
交叉熵函数
所以为了避免这个问题,引进了一个新的代价函数,交叉熵函数。
这里,n是训练样本的数量,代价函数对所有的训练样本求和,然后求平均值。这里还不能明显看出来交叉熵函数如何解决了二次代价函数的learning downing问题。
先用文字描述来解释一下, y 是对每一个输入
当
同样可以这样分析当
下面来用公式分析一下:
记住
a=σ(z)
,代入到上面的代价函数中,然后求导
使用sigmoid函数的定义式,得到 σ′(z)=σ(z)(1−σ(z)) 代入到上面的式子,得到:
可以看到,对参数的导数与sigmoid函数的导数无关了!与输出的误差( σ(z)−y )是成正比的,误差越大,学习速率越大!可以看到通过交叉熵函数的引入,消除了二次代价函数的learning slow down问题。
同样可以计算出偏置项的导数:
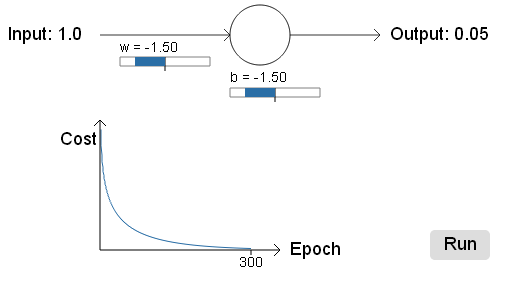
与上面的二次代价函数对比,交叉熵函数学习得很好!
交叉熵的概念其实来自于信息论,在信息论中被称为 binary entropy
当然,还要说明一下的时这是针对激活函数为sigmoid的情况,使用交叉熵函数作为代价函数会比二次函数要好,但是当神经元的激活函数是线性函数时,二次代价函数并不会有这个问题。
交叉熵函数的由来
不禁要想,人们是怎么想到用交叉熵函数的呢?
反向来推,假设现在,想要一个代价函数,可以消掉系数的导数中的
σ′(z)
项,那么对每一个训练样本
x
都满足:
又因为sigmoid函数的性质, σ′(z)=σ(z)(1−σ(z))=a(1−a)
所以进一步可以得到
两边对 a 积分,可以得到
这是对单个训练样本,对所有的训练样本:
Softmax
除了使用交叉熵函数可以解决learning slowdown的问题,还可以通过添加一个被称为Softmax层的神经元来解决这个问题。
通常情况输出层使用的sigmoid函数作为激活函数,激活函数的输入为
zLj=∑kwLjkaL−1k+bLj
,对于softmax层,我们用softmax来得到输出,对于第j和神经元的激活输出:
在分母,对softmax层的所有神经元求和。
可以看到,输出相当于在求一个加权的权重,只不过求权重的方法是通过指数函数。这样的话,输出层的所有输出就可以看是是一个概率分布了,因为加起来合为1。
对softmax,使用的是对数似然函数作为代价函数:
同样,求出偏导数:
可以看到,偏导数和sigmoid函数的导数项无关。这样就可以避免learning slowdown的问题了。
过拟合和正则化-Overfitting and regularization
关于过拟合的概念,可以理解为在训练数据上参数拟合过度了,在训练数据上的代价比较小,而泛化性不好,在测试数据集上的代价却比较大。在机器学习问题中常常要想办法避免过拟合。
关于正则化,就是一系列避免过拟合的措施。
首先介绍一个最常用的正则化方法,L2正则化,也叫权重衰减。对于使用交叉熵函数的代价函数,L2正则化就是在代价函数中加上权重的平方这一项:
这里, λ 是正则化系数。通常是不对偏置做正则化处理的,当然也可以加上,没有太大区别。这样就可以改写代价函数为:
C0 表示原本的代价函数。
加入了L2正则化项之后,导数变为了:
权值更新:
可以看到,加入了L2 正则化项之后, w 更新的式子中
直观地来说,没有正则项,在学习的过程中某些权重可能会变得比较大,而陷入到局部最小。而有了正则项,就可以避免某些权重变得特别大,能够很好地使参数在整个参数空间学习。也有用奥卡姆剃刀原理来解释这个问题的。
除了L2正则化,还有L1正则化。对权重使用L1模。
导数变为:
和L2正则化相比,当 |w| 很小时,L1正则化会使权重减小得更多,而当 |w| 很大时,L1正则化会使权重减小得更少,这样就使权重集中在少数几个比较重要的系数上,不重要的系数就变为0。
Dropout是一种比较特别的正则化技术,dropout不改变代价函数,而是改变神经网络的结构。在训练的过程中,每一次epoch,随机丢掉隐藏层中的神经元的一半学习参数,然后再恢复,然后进入到下一次epoch。
假设在学习一个如下所示的神经网络:
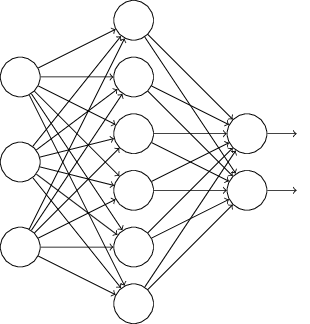
在某一次epoch中,把隐藏层的神经元随机地暂时丢掉一半,如下所示。然后再开始训练,仍然使用mini-batch SGD,更新了相应的权重之后,恢复神经网络的结构,再开始下一轮的学习。
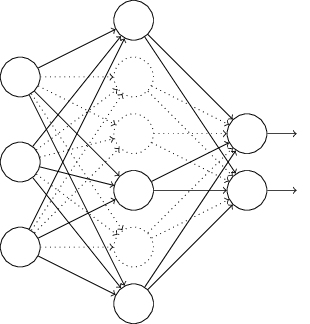
关于dropout为什么会有效,可以参考这篇论文,drouout原理解释-Hinton (2012)
简单说来,dropout去除掉了隐藏层神经元之间的耦合,之前每次都是所有神经元同时学习,现在不同步了。另外,这样训练,相当于训练了多个神经网络,最后的结果相当于多个神经网络的投票的结过,就可以比较好地抑制过拟合发生。
Data argument数据扩充是另外一种正则化方法,在机器学习问题中,一般而言,训练数据越多算法效果越好,尤其是深度学习,需要大量的训练数据,那么人为地创造出训练数据就很有帮助了。
对于图像领域,可以把图像旋转一个小的角度,或者放射变换一下,增加一些噪声之类的,来模拟真实世界中的情况,就可以很有效地扩充数据了。
使用数据扩充技术的论文-Platt (2003).
对于语音领域,也可以通过加入噪声,背景声,加快速率或者减慢速率等方法来扩充数据。
权重初始化-Weight initialization
如果所有的权重都按照标准正态分布来初始化,那么隐藏层的输入会是一个方差很大的随机变量,因为每一个输入都是一个正态分布的随机变量,加起来就会使方差变大了,也就是说隐藏层的输入的范围可能比较大。那么神经元的输出就会很接近0或者1,而饱和了。就会让学习变得很慢。
初始化权重时,可以使权重的分布的标准方差为
1/nin−−−√
,这里
nin
是输入权重的个数。这样就可以使隐藏层神经元的输入为一个标准正态分布的随机变量了。
怎么选择神经网络的超参数-How to choose a neural network’s hyper-parameters?
前面部分的内容都没有涉及到超参数的选择,比如学习速率
η
和正则化参数
λ
等等。
关于这部分,推荐两篇文章可以参考。
Practical Bayesian optimization of machine learning algorithms
Random search for hyper-parameter optimization.















 6982
6982

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









