







 本文介绍了使用Python爬虫从北京小猪短租网站抓取300个房源详情,包括标题、地址、日租金、图片链接等。通过梳理代码逻辑,强调了思路和函数间联系的重要性。
本文介绍了使用Python爬虫从北京小猪短租网站抓取300个房源详情,包括标题、地址、日租金、图片链接等。通过梳理代码逻辑,强调了思路和函数间联系的重要性。
需要爬取的资料
网址: http://bj.xiaozhu.com/
爬取信息:
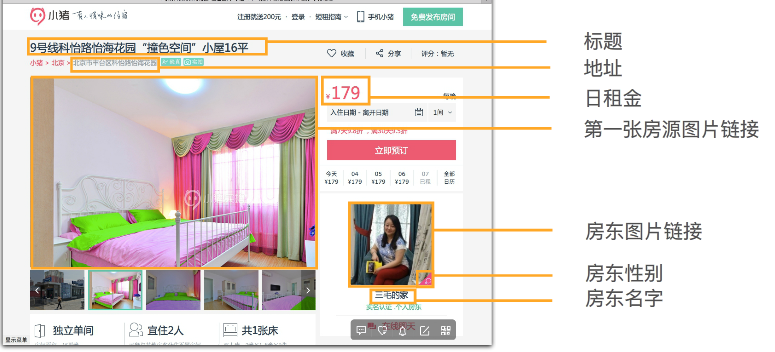
爬取网页上300个房源信息,包括标题,地址,日租金,第一张房源图片链接,房东图片链接,房东性别,房东名字
代码
from bs4 import BeautifulSoup
import requests
# 判断性别
def get_sex(sex_icon):
if sex_icon == ['member_ico']:
return "男"
if sex_icon == ['member_ico1']:
return "女"
else:
return "未标识"
# 获取每页的url链接
def get_page_url(url):
web_url = requests.get(url)
web_url_soup = BeautifulSoup(web_url.text,'lxml')
page_urls = web_url_soup.select('#page_list > ul > li > a')
for page_url in page_urls:
each_url = page_url.get('href')
get_detail_info(each_url)
def get_detail_info(url):
web_data = requests.get(url)
soup = BeautifulSoup(web_data.text,'lxml')
titles = soup.select('body > div.wrap.clearfix.con_bg > div.con_l > div.pho_info > h4 > em')
addresses = soup.select('body > div.wrap.clearfix.con_bg > div.con_l > div.pho_info > p > span.pr5')
prices = soup.select('#pricePart > div.day_l > span')
pics1 = soup.select('#curBigImage')
owner_pics = soup.select('#floatRightBox > div.js_box.clearfix > div.member_pic > a > img')
owner_names = soup.select('#floatRightBox > div.js_box.clearfix > div.w_240 > h6 > a')
sexes = soup.select('#floatRightBox > div.js_box.clearfix > div.member_pic > div')
for title, address, price, pic1, owner_name, owner_pic, sex in zip(titles, addresses, prices, pics1, owner_names,
owner_pics, sexes):
data = {
'title': title.get_text(),
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 524
524

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









