









还记的我们的代价函数吧:J=12∑mi=1(y(i)−θTx(i))2
现在让我们来看看为什么选择它来作为代价函数。
假设我们的模型如下:
y(i)=θTx(i)+ε(i)
其中ε(i)是误差补偿值,根据中心极限定理可知,一般而言ε(i)是满足高斯分布的,确切的说是正态分布,即ε(i)∼N(0,σ2)因此ε(i)的概率密度为:
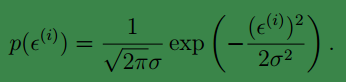
通过公式y(i)=θTx(i)+ε(i)我们可以得知:
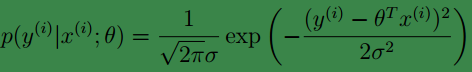
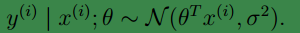
下面我们定义:L(θ)=L(θ;X,y⃗ )=p(y⃗ |X;θ),我们称L(θ)为似然函数(likehood)。
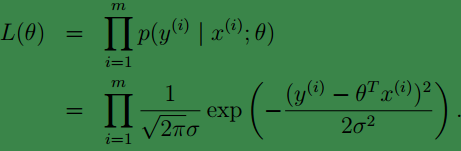
似然性表示了
y
在条件
这不就是求最大值吗!果断求导!
为了方便运算起见令:
ℓ(θ)=logL(θ)
,我们称
ℓ(θ)
为log likehood
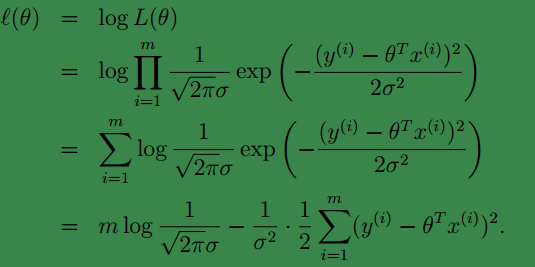
因此为了最大化
ℓ(θ)
,等价于最小化
12∑mi=1(y(i)−θTx(i))2
。这就是我们的代价函数啦!















 6608
6608

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









