







作者:wjmishuai
出处:http://blog.csdn.net/wjmishuai/article/details/50854162
一:下载训练集和测试集
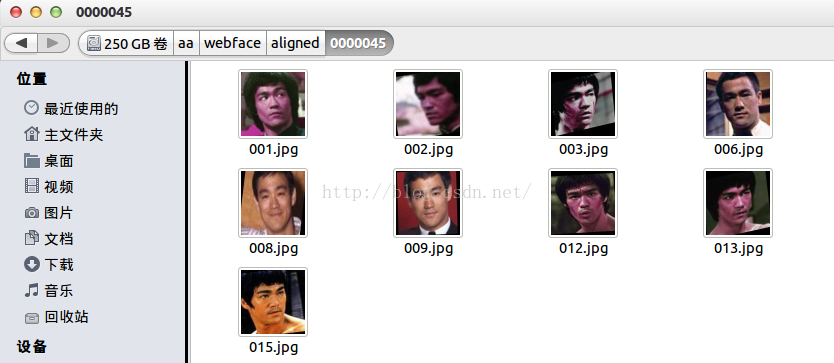
测试集的下载地址:
http://vis-www.cs.umass.edu/lfw/
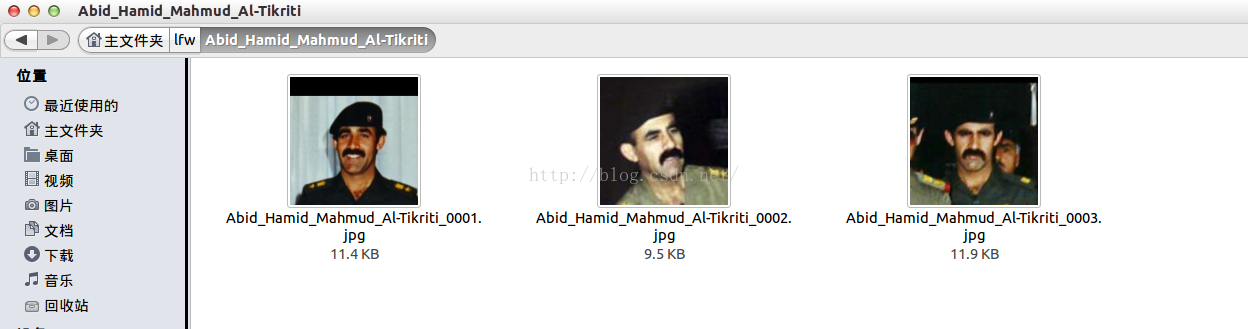
二:利用linux脚本生成训练集
#!/bin/bash
#-----------------------------------------------------------------------------------------
#生成训练集和验证集
#made by 郭开
#-----------------------------------------------------------------------------------------
#保存图片的路径
PATH=/media/gk/9ec75485-26b1-471f-9b7b-d18554ca3fdd/aa
echo "start..."
#遍历文件夹
for name in $PATH/webface_img/*;do
var=0
#遍历文件夹中的图片
for file_name in $name/*;do
var=$(($var+1));
str=$file_name
#保存图片路径
str=${str#*img}
#保存图片lable
lable=${str#*/}
lable=${lable%%/*}
if [ "$var" = "1" ] || [ "$var" = "3" ] || [ "$var" = "5" ]; then
#验证集
echo $str" "$lable>>/home/gk/val.txt
else
#测试集
echo $str" "$lable>>/home/gk/train.txt
fi
done
done
echo "Done."
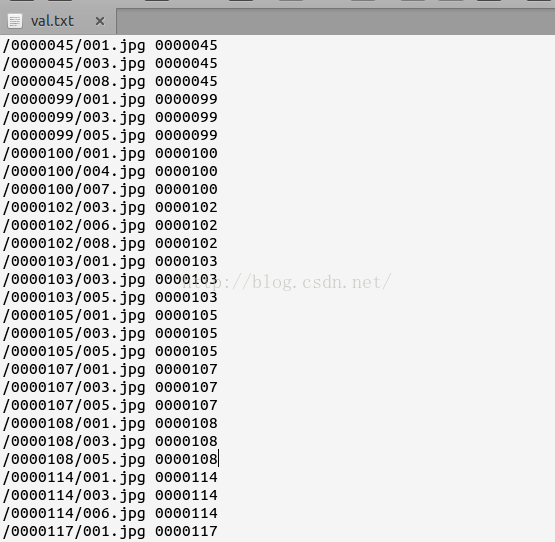
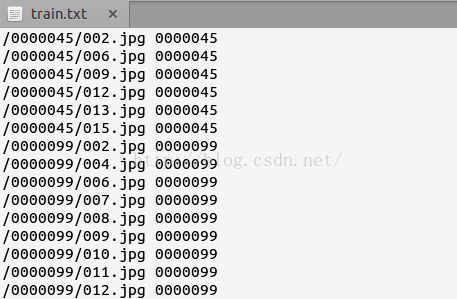
生成的文件如下图:
#!/bin/bash
#-----------------------------------------------------------------------------------------
#生成训练集和验证集
#made by 郭开
#-----------------------------------------------------------------------------------------
#保存图片的路径
PATH=/media/gk/9ec75485-26b1-471f-9b7b-d18554ca3fdd/aa
echo "start..."
#遍历文件夹
for name in $PATH/webface_img/*;do
var=0
#遍历文件夹中的图片
for file_name in $name/*;do
var=$(($var+1));
str=$file_name
#保存图片路径
str=${str#*img}
#保存图片lable
lable=${str#*/}
lable=${lable%%/*}
if [ "$var" = "1" ] || [ "$var" = "3" ] || [ "$var" = "5" ]; then
#验证集
echo $str" "$lable>>/home/gk/val.txt
else
#测试集
echo $str" "$lable>>/home/gk/train.txt
fi
done
done
echo "Done."
三:将图片转换成LMDB格式
#!/usr/bin/env sh
#-----------------------------------------------------------------------------------------
# 将图片批量生成lmbd格式的数据存储
#made by 郭开
#-----------------------------------------------------------------------------------------
#保存生成的lmdb的目录
EXAMPLE=/media/gk/9ec75485-26b1-471f-9b7b-d18554ca3fdd/aa/lmdb_webface
#train.txt和val.txt所在的目录
DATA=/home/gk
#转换图片的工具所在的目录
TOOLS=/home/gk/caffe-master/build/tools
#图片所在的目录
TRAIN_DATA_ROOT=/media/gk/9ec75485-26b1-471f-9b7b-d18554ca3fdd/aa/webface_img
VAL_DATA_ROOT=/media/gk/9ec75485-26b1-471f-9b7b-d18554ca3fdd/aa/webface_img
# 设置 RESIZE=true 可以把图片resize成想要的尺寸。
RESIZE=true
if $RESIZE; then
RESIZE_HEIGHT=227
RESIZE_WIDTH=227
else
RESIZE_HEIGHT=0
RESIZE_WIDTH=0
fi
if [ ! -d "$TRAIN_DATA_ROOT" ]; then
echo "Error: TRAIN_DATA_ROOT is not a path to a directory: $TRAIN_DATA_ROOT"
echo "Set the TRAIN_DATA_ROOT variable in create_imagenet.sh to the path" \
"where the ImageNet training data is stored."
exit 1
fi
if [ ! -d "$VAL_DATA_ROOT" ]; then
echo "Error: VAL_DATA_ROOT is not a path to a directory: $VAL_DATA_ROOT"
echo "Set the VAL_DATA_ROOT variable in create_imagenet.sh to the path" \
"where the ImageNet validation data is stored."
exit 1
fi
echo "Creating train lmdb..."
GLOG_logtostderr=1 $TOOLS/convert_imageset \
--resize_height=$RESIZE_HEIGHT \
--resize_width=$RESIZE_WIDTH \
--shuffle \
$TRAIN_DATA_ROOT \
$DATA/train.txt \
$EXAMPLE/train_lmdb
echo "Creating val lmdb..."
GLOG_logtostderr=1 $TOOLS/convert_imageset \
--resize_height=$RESIZE_HEIGHT \
--resize_width=$RESIZE_WIDTH \
--shuffle \
$VAL_DATA_ROOT \
$DATA/val.txt \
$EXAMPLE/val_lmdb
echo "Done."
四:计算图片的mean或者设置scale:0.00390625
#!/usr/bin/env sh
#-----------------------------------------------------------------------------------------
# 计算图像均值
#made by 郭开
#-----------------------------------------------------------------------------------------
#lmdb格式的文件所在的路径
EXAMPLE=/media/gk/9ec75485-26b1-471f-9b7b-d18554ca3fdd/aa/lmdb_webface
#均值文件保存的路径
DATA=/media/gk/44CA719BCA718A46
#转换图片的工具所在的目录
TOOLS=/home/gk/caffe-master/build/tools
$TOOLS/compute_image_mean $EXAMPLE/train_lmdb \
$DATA/mean.binaryproto
echo "Done."
五:训练模型
slover.prototxt
net: "/home/gk/caffe-master/examples/vgg/train.prototxt"
test_iter: 100
test_interval: 1000
base_lr: 0.001
lr_policy: "step"
gamma: 0.95
stepsize: 100000
momentum: 0.9
weight_decay: 0.0005
display: 100
max_iter: 5000000
snapshot: 50000
snapshot_prefix: "/home/gk/caffe-master/examples/DeepID/snapshot"
solver_mode: GPU
device_id:0
#debug_info: true
tarin.prototxt
name: "VGG_FACE_16_layers"
layer {
top: "data_1"
top: "label_1"
name: "data_1"
type: "Data"
data_param {
source: "/media/gk/9ec75485-26b1-471f-9b7b-d18554ca3fdd/aa/webface_lmdb/train"
backend:LMDB
batch_size: 128
}
transform_param {
mean_file: "/media/gk/9ec75485-26b1-471f-9b7b-d18554ca3fdd/aa/webface_lmdb/mean.binaryproto"
mirror: true
}
include: { phase: TRAIN }
}
layer {
top: "data_1"
top: "label_1"
name: "data_1"
type: "Data"
data_param {
source: "/media/gk/9ec75485-26b1-471f-9b7b-d18554ca3fdd/aa/webface_lmdb/val"
backend:LMDB
batch_size: 128
}
transform_param {
mean_file: "/media/gk/9ec75485-26b1-471f-9b7b-d18554ca3fdd/aa/webface_lmdb/mean.binaryproto"
mirror: true
}
include: {
phase: TEST
}
}
layers {
bottom: "data"
top: "conv1_1"
name: "conv1_1"
type: CONVOLUTION
convolution_param {
num_output: 64
pad: 1
kernel_size: 3
}
}
layers {
bottom: "conv1_1"
top: "conv1_1"
name: "relu1_1"
type: RELU
}
layers {
bottom: "conv1_1"
top: "conv1_2"
name: "conv1_2"
type: CONVOLUTION
convolution_param {
num_output: 64
pad: 1
kernel_size: 3
}
}
layers {
bottom: "conv1_2"
top: "conv1_2"
name: "relu1_2"
type: RELU
}
layers {
bottom: "conv1_2"
top: "pool1"
name: "pool1"
type: POOLING
pooling_param {
pool: MAX
kernel_size: 2
stride: 2
}
}
layers {
bottom: "pool1"
top: "conv2_1"
name: "conv2_1"
type: CONVOLUTION
convolution_param {
num_output: 128
pad: 1
kernel_size: 3
}
}
layers {
bottom: "conv2_1"
top: "conv2_1"
name: "relu2_1"
type: RELU
}
layers {
bottom: "conv2_1"
top: "conv2_2"
name: "conv2_2"
type: CONVOLUTION
convolution_param {
num_output: 128
pad: 1
kernel_size: 3
}
}
layers {
bottom: "conv2_2"
top: "conv2_2"
name: "relu2_2"
type: RELU
}
layers {
bottom: "conv2_2"
top: "pool2"
name: "pool2"
type: POOLING
pooling_param {
pool: MAX
kernel_size: 2
stride: 2
}
}
layers {
bottom: "pool2"
top: "conv3_1"
name: "conv3_1"
type: CONVOLUTION
convolution_param {
num_output: 256
pad: 1
kernel_size: 3
}
}
layers {
bottom: "conv3_1"
top: "conv3_1"
name: "relu3_1"
type: RELU
}
layers {
bottom: "conv3_1"
top: "conv3_2"
name: "conv3_2"
type: CONVOLUTION
convolution_param {
num_output: 256
pad: 1
kernel_size: 3
}
}
layers {
bottom: "conv3_2"
top: "conv3_2"
name: "relu3_2"
type: RELU
}
layers {
bottom: "conv3_2"
top: "conv3_3"
name: "conv3_3"
type: CONVOLUTION
convolution_param {
num_output: 256
pad: 1
kernel_size: 3
}
}
layers {
bottom: "conv3_3"
top: "conv3_3"
name: "relu3_3"
type: RELU
}
layers {
bottom: "conv3_3"
top: "pool3"
name: "pool3"
type: POOLING
pooling_param {
pool: MAX
kernel_size: 2
stride: 2
}
}
layers {
bottom: "pool3"
top: "conv4_1"
name: "conv4_1"
type: CONVOLUTION
convolution_param {
num_output: 512
pad: 1
kernel_size: 3
}
}
layers {
bottom: "conv4_1"
top: "conv4_1"
name: "relu4_1"
type: RELU
}
layers {
bottom: "conv4_1"
top: "conv4_2"
name: "conv4_2"
type: CONVOLUTION
convolution_param {
num_output: 512
pad: 1
kernel_size: 3
}
}
layers {
bottom: "conv4_2"
top: "conv4_2"
name: "relu4_2"
type: RELU
}
layers {
bottom: "conv4_2"
top: "conv4_3"
name: "conv4_3"
type: CONVOLUTION
convolution_param {
num_output: 512
pad: 1
kernel_size: 3
}
}
layers {
bottom: "conv4_3"
top: "conv4_3"
name: "relu4_3"
type: RELU
}
layers {
bottom: "conv4_3"
top: "pool4"
name: "pool4"
type: POOLING
pooling_param {
pool: MAX
kernel_size: 2
stride: 2
}
}
layers {
bottom: "pool4"
top: "conv5_1"
name: "conv5_1"
type: CONVOLUTION
convolution_param {
num_output: 512
pad: 1
kernel_size: 3
}
}
layers {
bottom: "conv5_1"
top: "conv5_1"
name: "relu5_1"
type: RELU
}
layers {
bottom: "conv5_1"
top: "conv5_2"
name: "conv5_2"
type: CONVOLUTION
convolution_param {
num_output: 512
pad: 1
kernel_size: 3
}
}
layers {
bottom: "conv5_2"
top: "conv5_2"
name: "relu5_2"
type: RELU
}
layers {
bottom: "conv5_2"
top: "conv5_3"
name: "conv5_3"
type: CONVOLUTION
convolution_param {
num_output: 512
pad: 1
kernel_size: 3
}
}
#!/usr/bin/env sh
#-----------------------------------------------------------------------------------------
# 将图片批量生成lmbd格式的数据存储
#made by 郭开
#-----------------------------------------------------------------------------------------
#保存生成的lmdb的目录
EXAMPLE=/media/gk/9ec75485-26b1-471f-9b7b-d18554ca3fdd/aa/lmdb_webface
#train.txt和val.txt所在的目录
DATA=/home/gk
#转换图片的工具所在的目录
TOOLS=/home/gk/caffe-master/build/tools
#图片所在的目录
TRAIN_DATA_ROOT=/media/gk/9ec75485-26b1-471f-9b7b-d18554ca3fdd/aa/webface_img
VAL_DATA_ROOT=/media/gk/9ec75485-26b1-471f-9b7b-d18554ca3fdd/aa/webface_img
# 设置 RESIZE=true 可以把图片resize成想要的尺寸。
RESIZE=true
if $RESIZE; then
RESIZE_HEIGHT=227
RESIZE_WIDTH=227
else
RESIZE_HEIGHT=0
RESIZE_WIDTH=0
fi
if [ ! -d "$TRAIN_DATA_ROOT" ]; then
echo "Error: TRAIN_DATA_ROOT is not a path to a directory: $TRAIN_DATA_ROOT"
echo "Set the TRAIN_DATA_ROOT variable in create_imagenet.sh to the path" \
"where the ImageNet training data is stored."
exit 1
fi
if [ ! -d "$VAL_DATA_ROOT" ]; then
echo "Error: VAL_DATA_ROOT is not a path to a directory: $VAL_DATA_ROOT"
echo "Set the VAL_DATA_ROOT variable in create_imagenet.sh to the path" \
"where the ImageNet validation data is stored."
exit 1
fi
echo "Creating train lmdb..."
GLOG_logtostderr=1 $TOOLS/convert_imageset \
--resize_height=$RESIZE_HEIGHT \
--resize_width=$RESIZE_WIDTH \
--shuffle \
$TRAIN_DATA_ROOT \
$DATA/train.txt \
$EXAMPLE/train_lmdb
echo "Creating val lmdb..."
GLOG_logtostderr=1 $TOOLS/convert_imageset \
--resize_height=$RESIZE_HEIGHT \
--resize_width=$RESIZE_WIDTH \
--shuffle \
$VAL_DATA_ROOT \
$DATA/val.txt \
$EXAMPLE/val_lmdb
echo "Done."
#!/usr/bin/env sh
#-----------------------------------------------------------------------------------------
# 计算图像均值
#made by 郭开
#-----------------------------------------------------------------------------------------
#lmdb格式的文件所在的路径
EXAMPLE=/media/gk/9ec75485-26b1-471f-9b7b-d18554ca3fdd/aa/lmdb_webface
#均值文件保存的路径
DATA=/media/gk/44CA719BCA718A46
#转换图片的工具所在的目录
TOOLS=/home/gk/caffe-master/build/tools
$TOOLS/compute_image_mean $EXAMPLE/train_lmdb \
$DATA/mean.binaryproto
echo "Done."
net: "/home/gk/caffe-master/examples/vgg/train.prototxt"
test_iter: 100
test_interval: 1000
base_lr: 0.001
lr_policy: "step"
gamma: 0.95
stepsize: 100000
momentum: 0.9
weight_decay: 0.0005
display: 100
max_iter: 5000000
snapshot: 50000
snapshot_prefix: "/home/gk/caffe-master/examples/DeepID/snapshot"
solver_mode: GPU
device_id:0
#debug_info: true
tarin.prototxt
name: "VGG_FACE_16_layers"
layer {
top: "data_1"
top: "label_1"
name: "data_1"
type: "Data"
data_param {
source: "/media/gk/9ec75485-26b1-471f-9b7b-d18554ca3fdd/aa/webface_lmdb/train"
backend:LMDB
batch_size: 128
}
transform_param {
mean_file: "/media/gk/9ec75485-26b1-471f-9b7b-d18554ca3fdd/aa/webface_lmdb/mean.binaryproto"
mirror: true
}
include: { phase: TRAIN }
}
layer {
top: "data_1"
top: "label_1"
name: "data_1"
type: "Data"
data_param {
source: "/media/gk/9ec75485-26b1-471f-9b7b-d18554ca3fdd/aa/webface_lmdb/val"
backend:LMDB
batch_size: 128
}
transform_param {
mean_file: "/media/gk/9ec75485-26b1-471f-9b7b-d18554ca3fdd/aa/webface_lmdb/mean.binaryproto"
mirror: true
}
include: {
phase: TEST
}
}
layers {
bottom: "data"
top: "conv1_1"
name: "conv1_1"
type: CONVOLUTION
convolution_param {
num_output: 64
pad: 1
kernel_size: 3
}
}
layers {
bottom: "conv1_1"
top: "conv1_1"
name: "relu1_1"
type: RELU
}
layers {
bottom: "conv1_1"
top: "conv1_2"
name: "conv1_2"
type: CONVOLUTION
convolution_param {
num_output: 64
pad: 1
kernel_size: 3
}
}
layers {
bottom: "conv1_2"
top: "conv1_2"
name: "relu1_2"
type: RELU
}
layers {
bottom: "conv1_2"
top: "pool1"
name: "pool1"
type: POOLING
pooling_param {
pool: MAX
kernel_size: 2
stride: 2
}
}
layers {
bottom: "pool1"
top: "conv2_1"
name: "conv2_1"
type: CONVOLUTION
convolution_param {
num_output: 128
pad: 1
kernel_size: 3
}
}
layers {
bottom: "conv2_1"
top: "conv2_1"
name: "relu2_1"
type: RELU
}
layers {
bottom: "conv2_1"
top: "conv2_2"
name: "conv2_2"
type: CONVOLUTION
convolution_param {
num_output: 128
pad: 1
kernel_size: 3
}
}
layers {
bottom: "conv2_2"
top: "conv2_2"
name: "relu2_2"
type: RELU
}
layers {
bottom: "conv2_2"
top: "pool2"
name: "pool2"
type: POOLING
pooling_param {
pool: MAX
kernel_size: 2
stride: 2
}
}
layers {
bottom: "pool2"
top: "conv3_1"
name: "conv3_1"
type: CONVOLUTION
convolution_param {
num_output: 256
pad: 1
kernel_size: 3
}
}
layers {
bottom: "conv3_1"
top: "conv3_1"
name: "relu3_1"
type: RELU
}
layers {
bottom: "conv3_1"
top: "conv3_2"
name: "conv3_2"
type: CONVOLUTION
convolution_param {
num_output: 256
pad: 1
kernel_size: 3
}
}
layers {
bottom: "conv3_2"
top: "conv3_2"
name: "relu3_2"
type: RELU
}
layers {
bottom: "conv3_2"
top: "conv3_3"
name: "conv3_3"
type: CONVOLUTION
convolution_param {
num_output: 256
pad: 1
kernel_size: 3
}
}
layers {
bottom: "conv3_3"
top: "conv3_3"
name: "relu3_3"
type: RELU
}
layers {
bottom: "conv3_3"
top: "pool3"
name: "pool3"
type: POOLING
pooling_param {
pool: MAX
kernel_size: 2
stride: 2
}
}
layers {
bottom: "pool3"
top: "conv4_1"
name: "conv4_1"
type: CONVOLUTION
convolution_param {
num_output: 512
pad: 1
kernel_size: 3
}
}
layers {
bottom: "conv4_1"
top: "conv4_1"
name: "relu4_1"
type: RELU
}
layers {
bottom: "conv4_1"
top: "conv4_2"
name: "conv4_2"
type: CONVOLUTION
convolution_param {
num_output: 512
pad: 1
kernel_size: 3
}
}
layers {
bottom: "conv4_2"
top: "conv4_2"
name: "relu4_2"
type: RELU
}
layers {
bottom: "conv4_2"
top: "conv4_3"
name: "conv4_3"
type: CONVOLUTION
convolution_param {
num_output: 512
pad: 1
kernel_size: 3
}
}
layers {
bottom: "conv4_3"
top: "conv4_3"
name: "relu4_3"
type: RELU
}
layers {
bottom: "conv4_3"
top: "pool4"
name: "pool4"
type: POOLING
pooling_param {
pool: MAX
kernel_size: 2
stride: 2
}
}
layers {
bottom: "pool4"
top: "conv5_1"
name: "conv5_1"
type: CONVOLUTION
convolution_param {
num_output: 512
pad: 1
kernel_size: 3
}
}
layers {
bottom: "conv5_1"
top: "conv5_1"
name: "relu5_1"
type: RELU
}
layers {
bottom: "conv5_1"
top: "conv5_2"
name: "conv5_2"
type: CONVOLUTION
convolution_param {
num_output: 512
pad: 1
kernel_size: 3
}
}
layers {
bottom: "conv5_2"
top: "conv5_2"
name: "relu5_2"
type: RELU
}
layers {
bottom: "conv5_2"
top: "conv5_3"
name: "conv5_3"
type: CONVOLUTION
convolution_param {
num_output: 512
pad: 1
kernel_size: 3
}
}














 245
245











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









