










KNN分类器
从测试样本x开始生长,不断扩大区域,直至包含进K个训练样本,把测试样本x的类别归于与之最近的k个训练样本中出现频率最大的类别。k近邻一般采用k为奇数,跟投票表决一样,避免因两种票数相等而难以决策。
其决策规则:

通俗易懂的规则是:
1.计算待分类数据和不同类中每一个数据的距离(欧氏或马氏)。
2.选出最小的前K数据个距离。
3.对比这前K个距离,找出K个数据中包含最多的是那个类的数据,即为待分类数据所在的类。
总结:
如何选取K是关键,如何选择一个最佳的k值取决于数据。一般情况下,在分类时较大的k值能够减小噪声的影响,但会使类别之间的界限变得模糊。如下图所示:
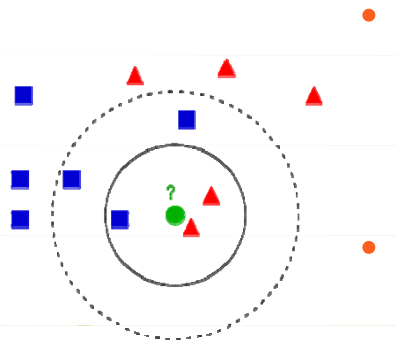
待测样本(绿色圆圈)既可能分到红色三角形类,也可能分到蓝色正方形类。
k= 3,属于红色三角形类;k= 5,属于蓝色正方形类
近邻分类器的优点:
原理和实现简单,特别适用于大类别问题。性能好:当训练样本数较多时,其错误率的上下界都是在一倍到两倍贝叶斯决策方法的错误率范围内。从这点来说最近邻法是优良的,因此它是模式识别重要方法之一。
近邻分类器的缺点 :
由于训练样本数有限,近邻法估计的后验概率往往并不精确,从而导致分类错误率远远大于Bayesian最小错误率。
搜索近邻需要遍历每一个样本,计算复杂度较大。
需要存储所有样本。
受噪声和距离测度的选择影响较大。
MATLAB实现:
clc;
clear;
% 第一个类数据和标号
% 均值
mu1 = [-1 -1];
% 协方差
S1 = [0.3 0;0 0.3];
% 产生高斯分布数据
data1 = mvnrnd(mu1, S1, 100);
plot(data1(:,1), data1(:,2), '+');
% 类别标签
label1 = ones(100, 1);
hold on;
grid on;
% 第二个类数据和标号
mu2 = [1 1];
S2 = [0.3 0;0 0.3];
data2 = mvnrnd(mu2, S2, 100);
plot(data2(:,1), data2(:,2), 'ro');
label2 = label1+1;
hold on;
data = [data1; data2];
label = [label1; label2];
% 两个类,K取奇数才能够区分测试数据属于那个类
K = 11;
% 测试数据,KNN算法看这个数属于哪个类
for ii=-4:0.1:4
for jj=-4:0.1:4
% 测试数据
test_data = [ii jj];
% 下面开始KNN算法,这里是11NN。
% 求测试数据和类中每个数据的距离,欧式距离
distance = zeros(200,1);
for i = 1:200
distance(i) = sqrt((test_data(1)-data(i,1)).^2+(test_data(2)-data(i,2)).^2);
end
% 找出最小的前K个数据
[dis, index] = sort(distance);
% 统计类1中距离测试数据最近的个数
cls1 = length(find(label(index(1:K,:))==1));
% 类2中距离测试数据最近的个数
cls2 = K - cls1;
% 属于类1的数据画小黑点
if cls1 > cls2
plot(ii, jj, '.');
end
end
end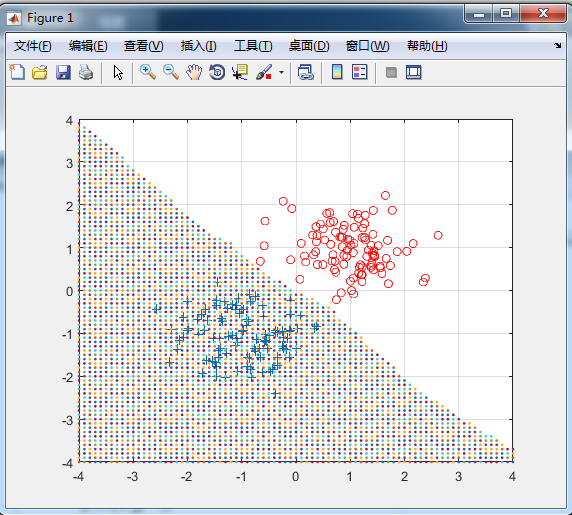















 802
802

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









