







出处:http://blog.csdn.net/zhongkejingwang/article/details/44132771
KNN即K-Nearest Neighbor,是数据挖掘中一种最简单的分类方法,即要判断某一个样本属于已知样本种类中的哪一类时,通过计算找出所有样本中与测试样本最近或者最相似的K个样本,统计这K个样本中哪一种类最多则把测试样本归位该类。如何衡量两个样本的相似度?可以用向量的p-范数来定义。
假设有两个样本X=(x1, x2, ..., xn),Y=(y1, y2, ..., yn),则他们之间的相似度可以用以下向量p-范数定义:
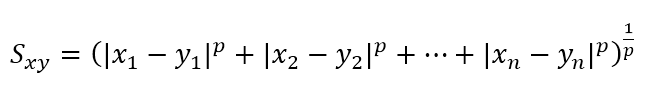
当p=2时即为计算X、Y的欧几里得距离。
本文将介绍用Java实现KNN分类器对Iris数据进行分类。Iris数据如下:
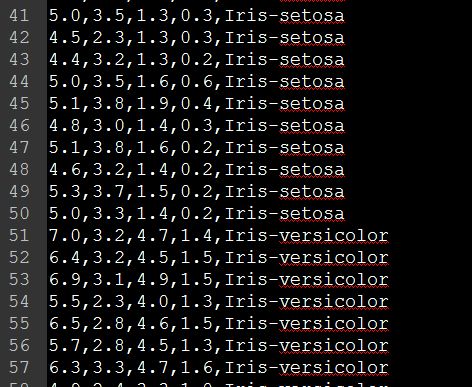
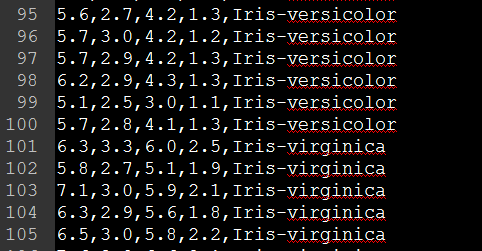
前面四个item是属性,最后一个是类别名,总共有三类。完整的数据集可点击这里下载。
拿到原始数据后为了测试KNN分类效果,需要在原始数据中随机抽取一部分作为测试集,另一部分作为训练集。随机抽取的方法可以用下面代码实现:
- /**
- * 将数据集划分为训练集和测试集,随机划分
- *
- * @param filePath
- * 数据集文件路径
- * @param testCount
- * 测试集个数
- * @param outputPath
- * 输出路径
- * @throws Exception
- */
- public static void splitDataSet(String filePath, int testCount,
- String outputPath) throws Exception
- {
- BufferedWriter trainFile = new BufferedWriter(new FileWriter(new File(
- outputPath + "/train.txt")));
- BufferedWriter testFile = new BufferedWriter(new FileWriter(new File(
- outputPath + "/test.txt")));
- BufferedReader input = new BufferedReader(new FileReader(new File(
- filePath)));
- List<String> lines = new ArrayList<String>();
- String line = null;
- //将所有数据读取到一个List里
- while ((line = input.readLine()) != null)
- lines.add(line);
- //遍历一次List,每次产生一个随机序号,将该随机序号和当前序号内容进行交换
- for (int i = 0; i < lines.size(); i++)
- {
- int ran = (int) (Math.random() * lines.size());
- String temp = lines.get(i);
- lines.set(i, lines.get(ran));
- lines.set(ran, temp);
- }
- int i = 0;
- //将指定数目的测试集写进test.txt中
- for (; i < testCount; i++)
- {
- testFile.write(lines.get(i) + "\n");
- testFile.flush();
- }
- //剩余的写进train.txt中
- for (; i < lines.size(); i++)
- {
- trainFile.write(lines.get(i) + "\n");
- trainFile.flush();
- }
- testFile.close();
- trainFile.close();
- }
调用这个方法后就可以得到train.txt和test.txt两份数据了。
接下来将数据读入:
- /**
- * 根据文件生成训练集,注意:程序将以第一个出现的非数字的属性作为类别名称
- *
- * @param fileName
- * 文件名
- * @param sep
- * 分隔符
- * @return
- * @throws Exception
- */
- public List<DataNode> getDataList(String fileName, String sep)
- throws Exception
- {
- List<DataNode> list = new ArrayList<DataNode>();
- BufferedReader br = new BufferedReader(new FileReader(
- new File(fileName)));
- String line = null;
- while ((line = br.readLine()) != null)
- {
- String splits[] = line.split(sep);
- //DataNode类用于保存数据属性和数据类别
- DataNode node = new DataNode();
- int i = 0;
- for (; i < splits.length; i++)
- {
- try
- {
- node.addAttrib(Float.valueOf(splits[i]));
- } catch (NumberFormatException e)
- {
- // 非数字,则为类别名称,将类别映射为数字
- if (!mTypes.containsKey(splits[i]))
- {
- mTypes.put(splits[i], mTypeCount);
- mTypeCount++;
- }
- node.setType(mTypes.get(splits[i]));
- list.add(node);
- }
- }
- }
- return list;
- }
KnnClassifier.java
- package com.jingchen.knn;
- import java.util.List;
- /**
- * @author chenjing
- *
- */
- public class KnnClassifier
- {
- //k个近邻节点
- private int k;
- private KNode[] mNearestK;
- private List<DataNode> mTrainData;
- public KnnClassifier(int k, List<DataNode> trainList)
- {
- mTrainData = trainList;
- this.k = k;
- mNearestK = new KNode[k];
- for (int i = 0; i < k; i++)
- mNearestK[i] = new KNode();
- }
- public void setK(int k){
- this.k = k;
- mNearestK = new KNode[k];
- for (int i = 0; i < k; i++)
- mNearestK[i] = new KNode();
- }
- private void train(DataNode test, float p)
- {
- for (int i = 0; i < mTrainData.size(); i++)
- {
- putNode(getSim(test, mTrainData.get(i), p));
- }
- }
- /**
- * 将新计算出来的节点与k个近邻节点比较,如果比其中之一小则插入
- * @param node
- */
- private void putNode(KNode node)
- {
- for (int i = 0; i < k; i++)
- {
- if (node.getD() < mNearestK[i].getD())
- {
- for (int j = k - 1; j > i; j--)
- mNearestK[j] = mNearestK[j - 1];
- mNearestK[i] = node;
- break;
- }
- }
- }
- /**
- * 获取相似度并封装成一个KNode类型返回
- * @param test
- * @param trainNode
- * @param p
- * @return
- */
- private KNode getSim(DataNode test, DataNode trainNode, float p)
- {
- List<Float> list1 = test.getAttribs();
- List<Float> list2 = trainNode.getAttribs();
- float d = 0;
- for (int i = 0; i < list1.size(); i++)
- d += Math.pow(
- Math.abs(list1.get(i).floatValue() - list2.get(i).floatValue()), p);
- d = (float) Math.pow(d, 1/p);
- KNode node = new KNode(d, trainNode.getType());
- return node;
- }
- private void reset()
- {
- for (int i = 0; i < k; i++)
- mNearestK[i].reset();
- }
- /**
- * 返回K个近邻节点
- * @param test
- * @param p
- * @return
- */
- public KNode[] getKNN(DataNode test, float p)
- {
- reset();
- train(test, p);
- return mNearestK;
- }
- }
main方法:
- public static void main(String[] args) throws Exception
- {
- DataUtil util = DataUtil.getInstance();
- //获得训练集和测试集
- List<DataNode> trainList = util.getDataList("E:/train.txt", ",");
- List<DataNode> testList = util.getDataList("E:/test.txt", ",");
- int K = BASE_K;
- KnnClassifier classifier = new KnnClassifier(K, trainList);
- BufferedWriter output = new BufferedWriter(new FileWriter(new File(
- "E:/output.txt")));
- int typeCount = util.getTypeCount();
- int[] count = new int[typeCount];
- for (int i = 0; i < testList.size();)
- {
- for (int m = 0; m < typeCount; m++)
- count[m] = 0;
- DataNode test = testList.get(i);
- classifier.setK(K);
- KNode[] nodes = classifier.getKNN(test, 2);
- for (int j = 0; j < nodes.length; j++)
- count[nodes[j].getType()]++;
- int type = -1;
- int max = -1;
- for (int j = 0; j < typeCount; j++)
- {
- if (count[j] > max)
- {
- max = count[j];
- type = j;
- } else if (count[j] == max)
- {
- // 存在两个类型分个数相同,无法判断属于哪个类型,增加K的值继续从该节点开始
- type = -1;
- K++;
- break;
- }
- }
- if (type == -1)
- continue;
- else
- {
- i++;
- K = BASE_K;
- }
- //将分类结果写入文件
- List<Float> attribs = test.getAttribs();
- for (int n = 0; n < attribs.size(); n++)
- {
- output.write(attribs.get(n) + ",");
- output.flush();
- }
- output.write(util.getTypeName(type) + "\n");
- output.flush();
- }
- output.close();
- }
经测试,KNN对Iris数据集分类准确率基本都在90+%以上,此分类方法也比较直观。数据集及完整的项目代码可以从这里下载: 点击下载 。















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









