







ABS 和 ABS+
[Rush, 2015] A Neural Attention Model for Abstractive Sentence Summarization
这篇 facebook 的论文是用神经网络来做生成式摘要的开山之作,后续的论文基本都会引用。而且在 github 上有开源的代码放出来,可以参考 facebook/NAMAS.
模型的主要结构见下图(a),即左边的那部分,其实本质上就是个 conditional neural network language model,也就是要最大化概率 p(yi+1|x,yc;θ) ,这一套框架还是逃不了 Bengio 那篇2003年的经典论文 A Neural Probabilistic Language Model.
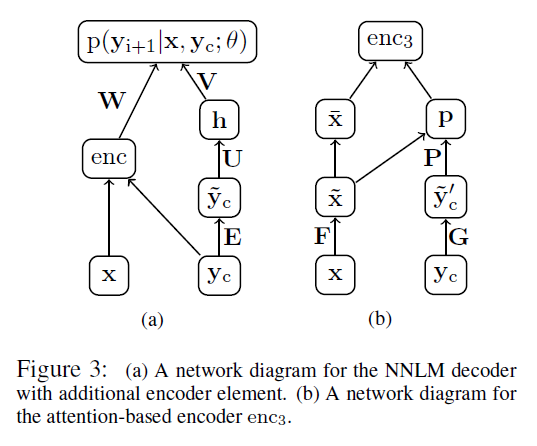
图中的 x,y 表示输入/输出的序列, yc 是 yi+1 的前 C 个词(不够就做 padding),可以看做是
子网络 enc 是 encoder,要把输入序列 x 和 context 信息融合,(b) 图就是就是其中一种设计,用上了 Attention 的思想。这个后面再细讲。回到 (a) 图上来, ỹ c 是 yc 的词向量表示。具体公式如下,
论文尝试了三种 encoder 的方式,分别是 Bag-of-Words,CNN 和 Attention-Based,公式如下,

其中 BoW 的做法是直接把 x 的词向量叠加,不考虑和 context 信息的融合,最后的效果也比较差一些;Convolutional Encoder 就是标准的卷积和池化操作,其中 Ql 就是第 l 层的卷积核,最上面的 max 操作是沿着时间找个最大的,剩下的维度只是卷积核的个数了,也就是 encoder 网络得到的特征维度大小。Attention-Based Encoder 和之前的 Attention 做法很类似,想要把
上面的模型可以简称为 ABS,作者还尝试了与 extractive 的方法结合,就有了 ABS+ 模型。即在每次解码出一个词的时候,不仅考虑神经网络对当前词的预测概率 logp(yi+1|x,yc;θ) ,还要开个窗口,去找一找当前窗口内的词是否在原文中出现过,如果有的话,概率会变大。根据窗口的不同大小,就等价于 unigram, bigram 和 trigram 特征。
论文在 DUC-2004 和 Gigawords 上做实验,结果也是 enc1 < enc2 < enc3,而且基本都比之前非 neural-network 的模型效果好。ABS+ 的效果明显好于 ABS,因为这篇论文是个 baseline,具体的实验结果会和后面的论文一起对比,这里略过。
LCSTS, SimpleAttention, TextSum 和 RAS
下面这几个工作简单提一下,
- [Hu, 2015] LCSTS: A large scale Chinese short text summarization dataset
- [Lopyrev, 2015] Generating News Headlines with Recurrent Neural Networks
- [Google, 2015] Sequence-to-Sequence with Attention Model for Text Summarization
- [Chopra, 2016] Abstractive sentence summarization with attentive recurrent neural networks
首先,[Hu 2015] 的贡献在于提出了一个新的中文数据集,LCSTS,该数据集是从新浪微博中爬取过滤得到的,训练集(Part I)有 240w 对数据,验证集(Part II)有 1w,测试集(Part III)有 1k 多一点。而且验证集和测试集用人工标注了正文和标题之间的相关度(relevance),并且从 1-5 打分,分数越高越好。见 Table 1 所示。
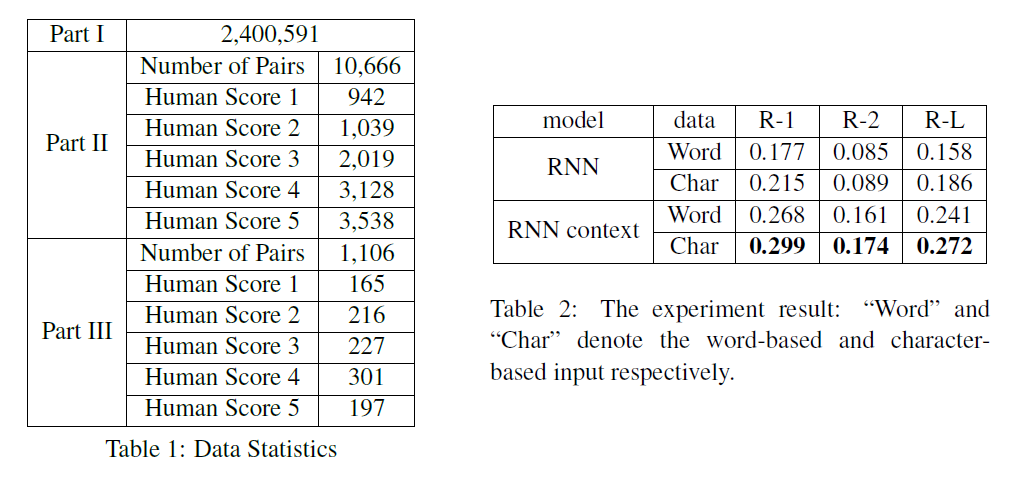
此外,论文对该数据集做了一个 baseline,用 GRU 搭建 seq2seq 和 Context(就是Attention) 两个模型,并且用字符(char)和词语(word)分别实验,共四个模型,见 Table 2 的结果。由于结巴分词后的词表必然比单字要大很多,因此有很多 OOV 的词,而且词表大了训练也很慢,预测起来也相对较难,因此还是 Char + RNN context 效果最好。
提一个小的点,就是这篇论文用了标准的 rouge 来评测,但是这个网站我一直登陆不了,不知道 pip 工具 rouge 和 pyrouge 和这个有没有区别,待挖掘。
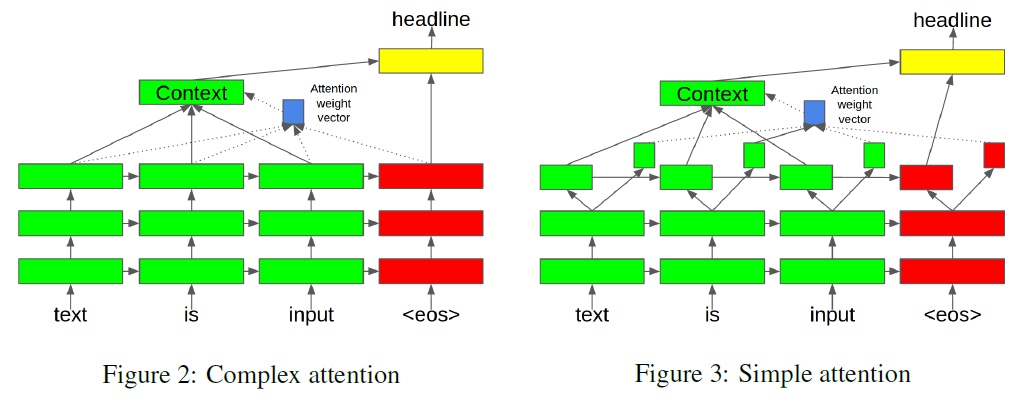
[Lopyrev, 2015] 没有什么亮点,就是把 encoder 和 decoder 都拆成两部分,算 Attention 的时候用小的那部分,正常的用大的那部分。一图以蔽之,
[Google, 2015] 其实不是论文,而是代码,但是挺具有参考意义,包括 Attention,BeamSearch 的实现等等。
[Chopra, 2016] 这篇说白了就是 CNN-RNN 的 seq2seq 结构,和第一篇论文 [Rush 2015] 是同一个小组(facebook 和 Harvard SEAS)的工作。根据 RNN 用的不同,模型叫做 RAS-Elman 和 RAS-LSTM,代码实现和 [Rush 2015] 放到了一起,见 facebook/NAMAS.
RNNs and Beyond
[Nallapati, 2016] Abstractive Text Summarization using Sequence-to-sequence RNNs and Beyond
这篇论文是 IBM Watson 实验室的工作,针对前面的 baseline 做的改进还挺多的,主要是下面几个方面
- 引入 Large Vocablary Trick 来解决 decoder 词表过大的问题;
- 加入传统的 TF-IDF,POS,NER 等特征来尝试抓住句子的关键部分;
- 引入 Generator-Pointer 来解决 OOV 和低频词的问题;
- 引入 Hierarchical Attention 来抓住句子的重要性信息;
- 引入 Temporal Attention 来缓解连续生成重复词的问题;
- 提出新的数据集 CNN/Daily Mail.
首先引入 LVT,这个 tensorflow 也有实现,参考 tf.nn.sampled_softmax_loss 和原始论文 On Using Very Large Target Vocabulary for Neural Machine Translation. 因此大部分的计算都在 decoder 预测词得分 logits,特别是如果用词级别来编码,词表可以到几万或者几十万的大小,使用 LVT 以后可以缩小一两个数量级,因此很有必要。因为交叉熵只关心正确答案对应词的概率,LVT 的原理大致是用负采样来估计 softmax 的分母,其他的就不用算了,因此可以大大节约计算量和训练时间。实际实验中,作者发现 2k 个负采样就基本够了。
引入语言学特征(linguistic feature)的目的是为了抓住句子中的关键概念和关键实体等,就是说哪些词是这段话想要表达的主体和重点。论文的做法比较简单,抽取了词性标注(POS tagging)、命名实体识别(NER)和 TF-IDF 特征,直接 embedding 后和词向量拼接到一起。这里只是 encoder 做这些工作,decoder 还是只用词向量。注意这里的 TF-IDF 是连续值,需要先离散化才能 embedding 成向量。见下图,
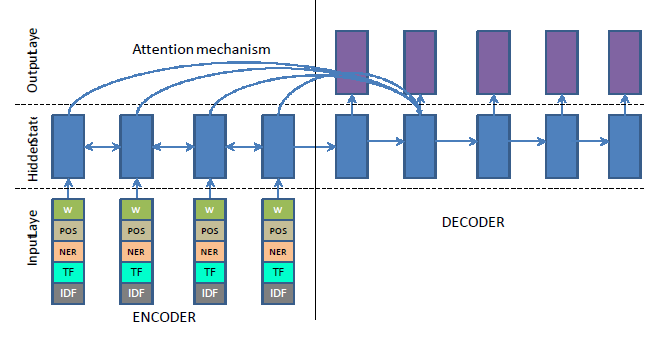
Generator-Pointer 的机制和后面要讲的 Pointing,CopyNet 等都是一个思路。因为摘要的任务特点,很多 OOV 或者不常见的 的词其实可以从输入序列中找到,因此一个很自然的想法就是去预测一个开关(switch)的概率 P(si=1)=f(hi,yi−1,ci) ,如果开关打开了,就是正常地预测词表;如果开关关上了,就需要去原文中指向一个位置作为输出。在训练的过程中,这个 P(st) 是有监督地给出,假设给出的 pointer label 叫做 gi 。见下面的 loss,
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









