







 本文深入解析OpenCV中基于Viola & Jones算法的级联分类器,介绍了HAAR特征、积分图像、AdaBoost算法以及级联分类器的工作原理,用于物体识别,特别是人脸识别。
本文深入解析OpenCV中基于Viola & Jones算法的级联分类器,介绍了HAAR特征、积分图像、AdaBoost算法以及级联分类器的工作原理,用于物体识别,特别是人脸识别。
我把级联分类器分为三部分内容介绍,第一部分内容是原理。
物体识别,尤其是人脸识别,是近二、三十年里计算机视觉领域一个热门的课题。它的应用范围极广,目前成熟的算法也较多。OpenCV也集成了一个物体识别的算法,它主要是基于Viola和Jones这两个人于2001年提出的震惊业界的Viola & Jones算法,该算法最初是用于人脸识别,但在对其它刚性物体的识别上效果也极佳。
Viola & Jones算法创新之处在于,它把下面三种方法首次集成用于人脸识别中:
(1)、应用HAAR状特征,并采用积分图像的方法计算该特征值;
(2)、应用AdaBoost算法选择适用于人脸的HAAR状特征;
(3)、把各类由AdaBoost算法得到的强分类器级联起来得到最终的级联分类器。
这三种方法整合在一起,大大提高了最终的级联分类器的准确率和速度。下面我们就来详细讲解Viola & Jones算法。
Viola & Jones算法采用大量的正样本图像和负样本图像来训练级联分类器,正样本图像是各种人脸图像,负样本图像是任意非人脸图像。我们要从正、负样本中找到区别于其他物体的人脸特征。Viola & Jones算法不是采用基于像素的特征,而是采用HAAR状特征。图1呈现了一些常用于人脸识别的HAAR状特征。
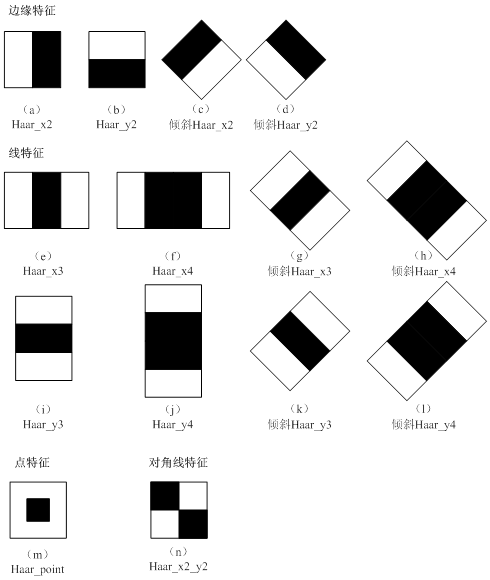
图1 HAAR状特征
从图1可以看出,每个HAAR状特征就是一个模板,模板内包括黑色区域和白色区域。例如,如果想检测图像中的边缘,则用代表边缘的HAAR状特征模板对图像进行扫描,分别计算模板所覆盖的白色区域内和黑色区域内的所有像素灰度值之和,然后两者相减,这个差值就是该模板在该位置上的特征值。只要把该特征值与事先设置好的阈值相比较,就可以判断出该位置是否为边缘像素。特征值判断的一般公式为:

式中,x表示图像,f(x)表示该图像的特征值,θ为阈值,h(x)表示该图像最终的分类结果。一般情况下,我们很难得到这个阈值θ,或者说根本不存在这样一个能准确分类图像的值。因此我们只要把使分类错误程度最小的那个值作为阈值即可。

图2 人脸检测所用到的HAAR状特征的示例
很显然,HAAR状特征不仅有类别的差异,还有大小的不同,即模板的大小尺寸也是可以变化的。图2表现了一些HAAR状特征对人脸检测的示例。
因此对于图像的特征,不仅涉及到模板的类型,还涉及到模板的大小,以及模板的位置。这样一来,图像的特征会有成千上万。例如对于一个24×24大小的人脸图像来说,它共有大约180,000多个特征,这要远远大于该尺寸大小的像素的数量(24×24=576)。但如果我们采用积分图像的方法,则计算HAAR状特征的特征值的效率会显著提高,以至于比计算特征是像素的方法还要快。这是因为积分图像非常适用于对矩形区域内所有像素灰度值之和的计算,而HAAR状特征的特征值正是这类计算。
积分图像很早就被应用在计算机图形学中,但直到Viola & Jones算法的提出,才把它应用到计算机视觉领域中。积分图像IΣ(x, y)的大小尺寸与原图像I(x, y)的大小尺寸相等,而积分图像在(x, y)处的值等于原图像中横坐标小于等于x并且纵坐标也小于等于y的所有像素灰度值之和,也就是在原图像中,从其左上角到(x, y)处所构成的矩形区域内所有像素灰度值之和,即
< 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 948
948

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









