







对于分时操作系统而言,表面上看起来是多个进程同时在执行,而在系统内部则进行着从一个进程到另一个进程的切换动作。这样的进程并发执行涉及到进程切换(process switch)和进程调度(process scheduling)两大问题。其中进程调度是操作系统的核心功能,它是一个非常复杂的过程,需要多个系统协同工作完成。Linux作为一个通用操作系统,其调度器的设计一直是一个颇有颇有挑战性的课题。一方面它涉及应用Linux的使用模型。尽管Linux最初开发为桌面操作系统环境,但现在在服务器、微型嵌入式设备、主机和超级计算机中都能发现它,无疑这些领域的调度负载有很大差异。另一方面,它要考虑平台方面的技术进步,包括架构(多处理、对称多线程、非一致内存访问 [NUMA] 和虚拟化)。另外,这里还要考虑交互性(用户响应能力)和整体公平性之间的平衡。通常Linux调度器将进程分为三类:
(1)交互式进程:此类进程有大量的人机交互,因此进程不断地处于睡眠状态,等待用户输入。典型的应用比如编辑器vi。此类进程对系统响应时间要求比较高,否则用户会感觉系统反应迟缓。
(2)批处理进程:此类进程不需要人机交互,在后台运行,需要占用大量的系统资源。但是能够忍受响应延迟。比如编译器。
(3)实时进程:实时对调度延迟的要求最高,这些进程往往执行非常重要的操作,要求立即响应并执行。比如视频播放软件或飞机飞行控制系统,很明显这类程序不能容忍长时间的调度延迟,轻则影响电影放映效果,重则机毁人亡。
根据进程的不同分类Linux采用不同的调度策略。对于实时进程,采用FIFO或者Round Robin的调度策略。对于普通进程,则需要区分交互式和批处理式的不同。传统Linux调度器提高交互式应用的优先级,使得它们能更快地被调度。而CFS和RSDL等新的调度器的核心思想是“完全公平”。这个设计理念不仅大大简化了调度器的代码复杂度,还对各种调度需求的提供了更完美的支持。注意Linux通过将进程和线程调度视为一个,同时包含二者。进程可以看做是单个线程,但是进程可以包含共享一定资源(代码和/或数据)的多个线程。因此进程调度也包含了线程调度的功能。
2. Linux调度器的简史
(1)Linux 2.4之前的内核调度器
早期的Linux进程调度器使用了最低的设计,它显然不关注具有很多处理器的大型架构,更不用说是超线程了。1.2 Linux调度器使用了环形队列用于可运行的任务管理,使用循环调度策略。 此调度器添加和删除进程效率很高(具有保护结构的锁)。简而言之,该调度器并不复杂但是简单快捷。Linux版本2.2引入了调度类的概念,允许针对实时任务、非抢占式任务、非实时任务的调度策略。2.2 调度器还包括对称多处理 (SMP) 支持。
(2)Linux 2.4的调度器
Linux2.4.18中使用的调度器采用基于优先级的设计,这个调度器和Linus在1992年发布的调度器没有大的区别。该调度器的 pick next 算法非常简单:对 runqueue 中所有进程的优先级进行依次进行比较,选择最高优先级的进程作为下一个被调度的进程。(Runqueue 是 Linux 内核中保存所有就绪进程的队列) 。术语 pick next 用来指从所有候选进程中挑选下一个要被调度的进程的过程。
每个进程被创建时都被赋予一个时间片。时钟中断递减当前运行进程的时间片,当进程的时间片被用完时,它必须等待重新赋予时间片才能有机会运行。Linux2.4 调度器保证只有当所有 RUNNING 进程的时间片都被用完之后,才对所有进程重新分配时间片。这段时间被称为一个epoch。这种设计保证了每个进程都有机会得到执行。每个epoch中,每个进程允许执行到其时间切片用完。如果某个进程没有使用其所有的时间切片,那么剩余时间切片的一半将被添加到新时间切片使其在下个epoch中可以执行更长时间。调度器只是迭代进程,应用goodness函数(指标)决定下面执行哪个进程。当然,各种进程对调度的需求并不相同,Linux 2.4调度器主要依靠改变进程的优先级,来满足不同进程的调度需求。事实上,所有后来的调度器都主要依赖修改进程优先级来满足不同的调度需求。
实时进程:实时进程的优先级是静态设定的,而且始终大于普通进程的优先级。因此只有当 runqueue 中没有实时进程的情况下,普通进程才能够获得调度。实时进程采用两种调度策略,SCHED_FIFO 和 SCHED_RR。FIFO 采用先进先出的策略,对于所有相同优先级的进程,最先进入 runqueue 的进程总能优先获得调度;Round Robin采用更加公平的轮转策略,使得相同优先级的实时进程能够轮流获得调度。
普通进程:对于普通进程,调度器倾向于提高交互式进程的优先级,因为它们需要快速的用户响应。普通进程的优先级主要由进程描述符中的 Counter 字段决定 (还要加上 nice 设定的静态优先级) 。进程被创建时子进程的 counter 值为父进程 counter 值的一半,这样保证了任何进程不能依靠不断地 fork() 子进程从而获得更多的执行机会。
Linux2.4调度器是如何提高交互式进程的优先级的呢?如前所述,当所有 RUNNING 进程的时间片被用完之后,调度器将重新计算所有进程的 counter 值,所有进程不仅包括 RUNNING 进程,也包括处于睡眠状态的进程。处于睡眠状态的进程的 counter 本来就没有用完,在重新计算时,他们的 counter 值会加上这些原来未用完的部分,从而提高了它们的优先级。交互式进程经常因等待用户输入而处于睡眠状态,当它们重新被唤醒并进入 runqueue 时,就会优先于其它进程而获得 CPU。从用户角度来看,交互式进程的响应速度就提高了。
该调度器的主要缺点:
可扩展性不好:调度器选择进程时需要遍历整个 runqueue 从中选出最佳人选,因此该算法的执行时间与进程数成正比。另外每次重新计算 counter 所花费的时间也会随着系统中进程数的增加而线性增长,当进程数很大时,更新 counter 操作的代价会非常高,导致系统整体的性能下降。
高负载系统上的调度性能比较低:2.4的调度器预分配给每个进程的时间片比较大,因此在高负载的服务器上,该调度器的效率比较低,因为平均每个进程的等待时间于该时间片的大小成正比。
交互式进程的优化并不完善:Linux2.4识别交互式进程的原理基于以下假设,即交互式进程比批处理进程更频繁地处于SUSPENDED状态。然而现实情况往往并非如此,有些批处理进程虽然没有用户交互,但是也会频繁地进行IO操作,比如一个数据库引擎在处理查询时会经常地进行磁盘IO,虽然它们并不需要快速地用户响应,还是被提高了优先级。当系统中这类进程的负载较重时,会影响真正的交互式进程的响应时间。
对实时进程的支持不够:Linux2.4内核是非抢占的,当进程处于内核态时不会发生抢占,这对于真正的实时应用是不能接受的。
为了解决这些问题,Ingo Molnar开发了新的O(1)调度器,在CFS和RSDL之前,这个调度器不仅被Linux2.6采用,还被backport到Linux2.4中,很多商业的发行版本都采用了这个调度器。
(3)Linux 2.6的O(1)调度器
从名字就可以看出O(1)调度器主要解决了以前版本中的扩展性问题。O(1)调度算法所花费的时间为常数,与当前系统中的进程个数无关。此外Linux 2.6内核支持内核态抢占,因此更好地支持了实时进程。相对于前任,O(1)调度器还更好地区分了交互式进程和批处理式进程。Linux 2.6内核也支持三种调度策略。其中SCHED_FIFO和SCHED_RR用于实时进程,而SCHED_NORMAL用于普通进程。O(1)调度器在两个方面修改了Linux 2.4调度器,一是进程优先级的计算方法;二是pick next算法。O(1)调度器跟踪运行队列中可运行的任务(实际上,每个优先级水平有两个运行队列,一个用于活动任务,一个用于过期任务), 这意味着要确定接下来执行的任务,调度器只需按优先级将下一个任务从特定活动的运行队列中取出即可。
1)普通进程的优先级计算
不同类型的进程应该有不同的优先级。每个进程与生俱来(即从父进程那里继承而来)都有一个优先级,我们将其称为静态优先级。普通进程的静态优先级范围从100到139,100为最高优先级,139 为最低优先级,0-99保留给实时进程。当进程用完了时间片后,系统就会为该进程分配新的时间片(即基本时间片),静态优先级本质上决定了时间片分配的大小。静态优先级和基本时间片的关系如下:
静态优先级<120,基本时间片=max((140-静态优先级)*20, MIN_TIMESLICE)
静态优先级>=120,基本时间片=max((140-静态优先级)*5, MIN_TIMESLICE)
其中MIN_TIMESLICE为系统规定的最小时间片。从该计算公式可以看出,静态优先级越高(值越低),进程得到的时间片越长。其结果是,优先级高的进程会获得更长的时间片,而优先级低的进程得到的时间片则较短。进程除了拥有静态优先级外,还有动态优先级,其取值范围是100到139。当调度程序选择新进程运行时就会使用进程的动态优先级,动态优先级和静态优先级的关系可参考下面的公式:
动态优先级=max(100 , min(静态优先级 – bonus + 5) , 139)
从上面看出,动态优先级的生成是以静态优先级为基础,再加上相应的惩罚或奖励(bonus)。这个bonus并不是随机的产生,而是根据进程过去的平均睡眠时间做相应的惩罚或奖励。所谓平均睡眠时间(sleep_avg,位于task_struct结构中)就是进程在睡眠状态所消耗的总时间数,这里的平均并不是直接对时间求平均数。平均睡眠时间随着进程的睡眠而增长,随着进程的运行而减少。因此,平均睡眠时间记录了进程睡眠和执行的时间,它是用来判断进程交互性强弱的关键数据。如果一个进程的平均睡眠时间很大,那么它很可能是一个交互性很强的进程。反之,如果一个进程的平均睡眠时间很小,那么它很可能一直在执行。另外,平均睡眠时间也记录着进程当前的交互状态,有很快的反应速度。比如一个进程在某一小段时间交互性很强,那么sleep_avg就有可能暴涨(当然它不能超过 MAX_SLEEP_AVG),但如果之后都一直处于执行状态,那么sleep_avg就又可能一直递减。理解了平均睡眠时间,那么bonus的含义也就显而易见了。交互性强的进程会得到调度程序的奖励(bonus为正),而那些一直霸占CPU的进程会得到相应的惩罚(bonus为负)。其实bonus相当于平均睡眠时间的缩影,此时只是将sleep_avg调整成bonus数值范围内的大小。可见平均睡眠时间可以用来衡量进程是否是一个交互式进程。如果满足下面的公式,进程就被认为是一个交互式进程:
动态优先级≤3*静态优先级/4 + 28
平均睡眠时间是进程处于等待睡眠状态下的时间,该值在进程进入睡眠状态时增加,而进入RUNNING状态后则减少。该值的更新时机分布在很多内核函数内:时钟中断scheduler_tick();进程创建;进程从TASK_INTERRUPTIBLE状态唤醒;负载平衡等。
2)实时进程的优先级计算
实时进程的优先级由sys_sched_setschedule()设置。该值不会动态修改,而且总是比普通进程的优先级高。在进程描述符中用rt_priority域表示。
3)pick next算法
普通进程的调度选择算法基于进程的优先级,拥有最高优先级的进程被调度器选中。2.4中,时间片counter同时也表示了一个进程的优先级。2.6中时间片用任务描述符中的time_slice域表示,而优先级用prio(普通进程)或者rt_priority(实时进程)表示。调度器为每一个CPU维护了两个进程队列数组:指向活动运行队列的active数组和指向过期运行队列的expire数组。数组中的元素着保存某一优先级的进程队列指针。系统一共有140个不同的优先级,因此这两个数组大小都是140。它们是按照先进先出的顺序进行服务的。被调度执行的任务都会被添加到各自运行队列优先级列表的末尾。每个任务都有一个时间片,这取决于系统允许执行这个任务多长时间。运行队列的前100个优先级列表保留给实时任务使用,后40个用于用户任务,参见下图:
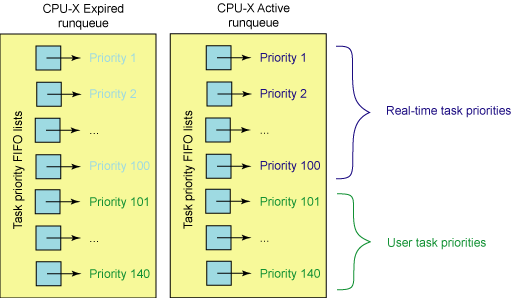
图1 调度器的运行队列结构
当需要选择当前最高优先级的进程时,2.6调度器不用遍历整个runqueue,而是直接从active数组中选择当前最高优先级队列中的第一个进程。假设当前所有进程中最高优先级为50(换句话说,系统中没有任何进程的优先级小于50)。则调度器直接读取 active[49],得到优先级为50的进程队列指针。该队列头上的第一个进程就是被选中的进程。这种算法的复杂度为O(1),从而解决了2.4调度器的扩展性问题。为了实现O(1)算法active数组维护了一个由5个32位的字(140个优先级)组成的bitmap,当某个优先级别上有进程被插入列表时,相应的比特位就被置位。 sched_find_first_bit()函数查询该bitmap,返回当前被置位的最高优先级的数组下标。在上例中sched_find_first_bit函数将返回49。在IA处理器上可以通过bsfl等指令实现。可见查找一个任务来执行所需要的时间并不依赖于活动任务的个数,而是依赖于优先级的数量。这使得 2.6 版本的调度器成为一个复杂度为 O(1) 的过程,因为调度时间既是固定的,而且也不会受到活动任务个数的影响。
为了提高交互式进程的响应时间,O(1)调度器不仅动态地提高该类进程的优先级,还采用以下方法:每次时钟tick中断时,进程的时间片(time_slice)被减一。当time_slice为0时,表示当前进程的时间片用完,调度器判断当前进程的类型,如果是交互式进程或者实时进程,则重置其时间片并重新插入active数组。如果不是交互式进程则从active数组中移到expired数组,并根据上述公式重新计算时间片。这样实时进程和交互式进程就总能优先获得CPU。然而这些进程不能始终留在active数组中,否则进入expire数组的进程就会产生饥饿现象。当进程已经占用CPU时间超过一个固定值后,即使它是实时进程或者交互式进程也会被移到expire数组中。当active数组中的所有进程都被移到expire数组中后,调度器交换active数组和expire数组。因此新的active数组又恢复了初始情况,而expire数组为空,从而开始新的一轮调度。
Linux 2.6调度器改进了前任调度器的可扩展性问题,schedule()函数的时间复杂度为O(1)。这取决于两个改进:
1)Pick next算法借助于active数组,无需遍历runqueue;
2)取消了定期更新所有进程counter的操作,动态优先级的修改分布在进程切换,时钟tick中断以及其它一些内核函数中进行。
O(1)调度器区分交互式进程和批处理进程的算法与以前虽大有改进,但仍然在很多情况下会失效。有一些著名的程序总能让该调度器性能下降,导致交互式进程反应缓慢。例如fiftyp.c, thud.c, chew.c, ring-test.c, massive_intr.c等。而且O(1)调度器对NUMA支持也不完善。为了解决这些问题,大量难以维护和阅读的复杂代码被加入Linux2.6.0的调度器模块,虽然很多性能问题因此得到了解决,可是另外一个严重问题始终困扰着许多内核开发者,那就是代码的复杂度问题。很多复杂的代码难以管理并且对于纯粹主义者而言未能体现算法的本质。
为了解决 O(1) 调度器面临的问题以及应对其他外部压力, 需要改变某些东西。这种改变来自Con Kolivas的内核补丁staircase scheduler(楼梯调度算法),以及改进的RSDL(Rotating Staircase Deadline Scheduler)。它为调度器设计提供了一个新的思路。Ingo Molnar在RSDL之后开发了CFS,并最终被2.6.23内核采用。接下来我们开始介绍这些新一代调度器。
3. Linux 2.6的新一代调度器CFS
(1)楼梯调度算法staircase scheduler
楼梯算法(SD)在思路上和O(1)算法有很大不同,它抛弃了动态优先级的概念。而采用了一种完全公平的思路。前任算法的主要复杂性来自动态优先级的计算,调度器根据平均睡眠时间和一些很难理解的经验公式来修正进程的优先级以及区分交互式进程。这样的代码很难阅读和维护。楼梯算法思路简单,但是实验证明它对应交互式进程的响应比其前任更好,而且极大地简化了代码。
和O(1)算法一样,楼梯算法也同样为每一个优先级维护一个进程列表,并将这些列表组织在active数组中。当选取下一个被调度进程时,SD算法也同样从active数组中直接读取。与O(1)算法不同在于,当进程用完了自己的时间片后,并不是被移到expire数组中。而是被加入active数组的低一优先级列表中,即将其降低一个级别。不过请注意这里只是将该任务插入低一级优先级任务列表中,任务本身的优先级并没有改变。当时间片再次用完,任务被再次放入更低一级优先级任务队列中。就象一部楼梯,任务每次用完了自己的时间片之后就下一级楼梯。任务下到最低一级楼梯时,如果时间片再次用完,它会回到初始优先级的下一级任务队列中。比如某进程的优先级为1,当它到达最后一级台阶140后,再次用完时间片时将回到优先级为2的任务队列中,即第二级台阶。不过此时分配给该任务的time_slice将变成原来的2倍。比如原来该任务的时间片time_slice为10ms,则现在变成了20ms。基本的原则是,当任务下到楼梯底部时,再次用完时间片就回到上次下楼梯的起点的下一级台阶。并给予该任务相同于其最初分配的时间片。总结如下:设任务本身优先级为P,当它从第N级台阶开始下楼梯并到达底部后,将回到第N+1级台阶。并且赋予该任务N+1倍的时间片。
以上描述的是普通进程的调度算法,实时进程还是采用原来的调度策略,即FIFO或者Round Robin。
楼梯算法能避免进程饥饿现象,高优先级的进程会最终和低优先级的进程竞争,使得低优先级进程最终获得执行机会。对于交互式应用,当进入睡眠状态时,与它同等优先级的其他进程将一步一步地走下楼梯,进入低优先级进程队列。当该交互式进程再次唤醒后,它还留在高处的楼梯台阶上,从而能更快地被调度器选中,加速了响应时间。
楼梯算法的优点:从实现角度看,SD基本上还是沿用了O(1)的整体框架,只是删除了O(1)调度器中动态修改优先级的复杂代码;还淘汰了expire数组,从而简化了代码。它最重要的意义在于证明了完全公平这个思想的可行性。
(2)RSDL(Rotating Staircase Deadline Scheduler)
RSDL也是由Con Kolivas开发的,它是对SD算法的改进。核心的思想还是“完全公平”。没有复杂的动态优先级调整策略。RSDL重新引入了expire数组。它为每一个优先级都分配了一个 “组时间配额”,记为Tg;同一优先级的每个进程都拥有同样的"优先级时间配额",用Tp表示。当进程用完了自身的Tp时,就下降到下一优先级进程组中。这个过程和SD相同,在RSDL中这个过程叫做minor rotation(次轮询)。请注意Tp不等于进程的时间片,而是小于进程的时间片。下图表示了minor rotation。进程从priority1的队列中一步一步下到priority140之后回到priority2的队列中,这个过程如下图左边所示,然后从priority 2开始再次一步一步下楼,到底后再次反弹到priority3队列中,如下图所示。
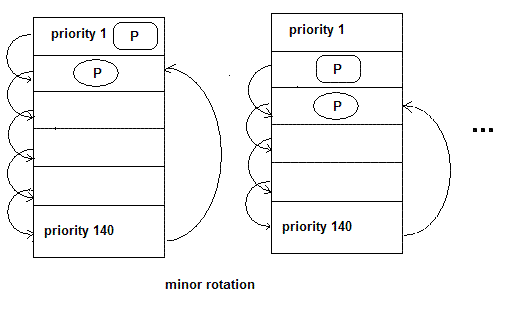
图2 RSDL的次轮询过程
在SD算法中,处于楼梯底部的低优先级进程必须等待所有的高优先级进程执行完才能获得CPU。因此低优先级进程的等待时间无法确定。RSDL中,当高优先级进程组用完了它们的Tg(即组时间配额)时,无论该组中是否还有进程Tp尚未用完,所有属于该组的进程都被强制降低到下一优先级进程组中。这样低优先级任务就可以在一个可以预计的未来得到调度。从而改善了调度的公平性。这就是RSDL中Deadline代表的含义。
进程用完了自己的时间片time_slice时(下图中T2),将放入expire数组指向的对应初始优先级队列中(priority 1)。
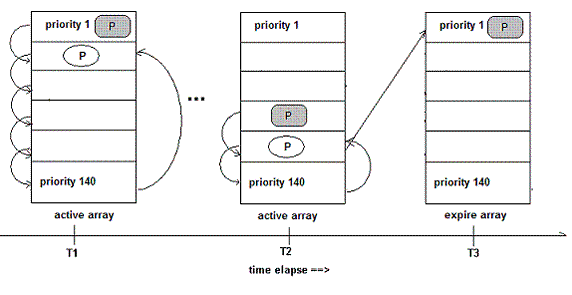
图3 时间片用完时的处理
当active数组为空,或者所有的进程都降低到最低优先级时就会触发主轮询major rotation。Major rotation交换active数组和expire数组,所有进程都恢复到初始状态,再一次从新开始minor rotation的过程。
RSDL对交互式进程的支持:和SD同样的道理,交互式进程在睡眠时间时,它所有的竞争者都因为minor rotation而降到了低优先级进程队列中。当它重新进入RUNNING状态时,就获得了相对较高的优先级,从而能被迅速响应。
(3)完全公平的调度器CFS
CFS是最终被内核采纳的调度器。它从RSDL/SD中吸取了完全公平的思想,不再跟踪进程的睡眠时间,也不再企图区分交互式进程。它将所有的进程都统一对待,这就是公平的含义。CFS的算法和实现都相当简单,众多的测试表明其性能也非常优越。按照作者Ingo Molnar的说法(参考Documentation/scheduler/sched-design-CFS.txt),CFS百分之八十的工作可以用一句话概括:CFS在真实的硬件上模拟了完全理想的多任务处理器。在真空的硬件上,同一时刻我们只能运行单个进程,因此当一个进程占用CPU时,其它进程就必须等待,这就产生了不公平。但是在“完全理想的多任务处理器 “下,每个进程都能同时获得CPU的执行时间,即并行地每个进程占1/nr_running的时间。例如当系统中有两个进程时,CPU的计算时间被分成两份,每个进程获得50%。假设runqueue中有n个进程,当前进程运行了10ms。在“完全理想的多任务处理器”中,10ms应该平分给n个进程(不考虑各个进程的nice值),因此当前进程应得的时间是(10/n)ms,但是它却运行了10ms。所以CFS将惩罚当前进程,使其它进程能够在下次调度时尽可能取代当前进程。最终实现所有进程的公平调度。
与之前的Linux调度器不同,CFS没有将任务维护在链表式的运行队列中,它抛弃了active/expire数组,而是对每个CPU维护一个以时间为顺序的红黑树。该树方法能够良好运行的原因在于:
* 红黑树可以始终保持平衡,这意味着树上没有路径比任何其他路径长两倍以上。
* 由于红黑树是二叉树,查找操作的时间复杂度为O(log n)。但是除了最左侧查找以外,很难执行其他查找,并且最左侧的节点指针始终被缓存。
* 对于大多数操作(插入、删除、查找等),红黑树的执行时间为O(log n),而以前的调度程序通过具有固定优先级的优先级数组使用 O(1)。O(log n) 行为具有可测量的延迟,但是对于较大的任务数无关紧要。Molnar在尝试这种树方法时,首先对这一点进行了测试。
* 红黑树可通过内部存储实现,即不需要使用外部分配即可对数据结构进行维护。
要实现平衡,CFS使用“虚拟运行时”表示某个任务的时间量。任务的虚拟运行时越小,意味着任务被允许访问服务器的时间越短,其对处理器的需求越高。CFS还包含睡眠公平概念以便确保那些目前没有运行的任务(例如,等待 I/O)在其最终需要时获得相当份额的处理器。
1)CFS如何实现pick next
下图是一个红黑树的例子。
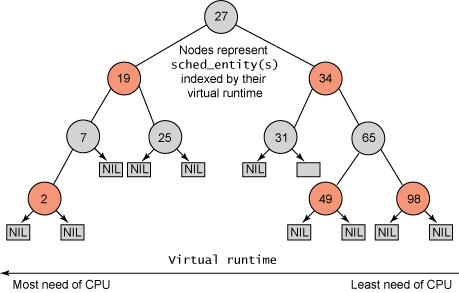
图4 一个红黑树示例
所有可运行的任务通过不断地插入操作最终都存储在以时间为顺序的红黑树中(由 sched_entity 对象表示),对处理器需求最多的任务(最低虚拟运行时)存储在树的左侧,处理器需求最少的任务(最高虚拟运行时)存储在树的右侧。 为了公平,CFS调度器会选择红黑树最左边的叶子节点作为下一个将获得cpu的任务。这样,树左侧的进程就被给予时间运行了。
2)tick中断
在CFS中,tick中断首先更新调度信息。然后调整当前进程在红黑树中的位置。调整完成后如果发现当前进程不再是最左边的叶子,就标记need_resched标志,中断返回时就会调用scheduler()完成进程切换。否则当前进程继续占用CPU。从这里可以看到 CFS抛弃了传统的时间片概念。Tick中断只需更新红黑树,以前的所有调度器都在tick中断中递减时间片,当时间片或者配额被用完时才触发优先级调整并重新调度。
3)红黑树键值计算
理解CFS的关键就是了解红黑树键值的计算方法。该键值由三个因子计算而得:一是进程已经占用的CPU时间;二是当前进程的nice值;三是当前的cpu负载。进程已经占用的CPU时间对键值的影响最大,其实很大程度上我们在理解CFS时可以简单地认为键值就等于进程已占用的 CPU时间。因此该值越大,键值越大,从而使得当前进程向红黑树的右侧移动。另外CFS规定,nice值为1的进程比nice值为0的进程多获得10%的 CPU时间。在计算键值时也考虑到这个因素,因此nice值越大,键值也越大。
CFS为每个进程都维护两个重要变量:fair_clock和wait_runtime。这里我们将为每个进程维护的变量称为进程级变量,为每个CPU维护的称作CPU级变量,为每个runqueue维护的称为runqueue级变量。进程插入红黑树的键值即为fair_clock – wait_runtime。其中fair_clock从其字面含义上讲就是一个进程应获得的CPU时间,即等于进程已占用的CPU时间除以当前 runqueue中的进程总数;wait_runtime是进程的等待时间。它们的差值代表了一个进程的公平程度。该值越大,代表当前进程相对于其它进程越不公平。对于交互式任务,wait_runtime长时间得不到更新,因此它能拥有更高的红黑树键值,更靠近红黑树的左边。从而得到快速响应。
红黑树是平衡树,调度器每次总最左边读出一个叶子节点,该读取操作的时间复杂度是O(LgN)。
4)调度器管理器
为了支持实时进程,CFS提供了调度器模块管理器。各种不同的调度器算法都可以作为一个模块注册到该管理器中。不同的进程可以选择使用不同的调度器模块。2.6.23中,CFS实现了两个调度算法,CFS算法模块和实时调度模块。对应实时进程,将使用实时调度模块。对应普通进程则使用CFS算法。CFS 调度模块(在 kernel/sched_fair.c 中实现)用于以下调度策略:SCHED_NORMAL、SCHED_BATCH 和 SCHED_IDLE。对于 SCHED_RR 和 SCHED_FIFO 策略,将使用实时调度模块(该模块在 kernel/sched_rt.c 中实现)。
5)CFS组调度
CFS组调度(在 2.6.24 内核中引入)是另一种为调度带来公平性的方式,尤其是在处理产生很多其他任务的任务时。 假设一个产生了很多任务的服务器要并行化进入的连接(HTTP 服务器的典型架构)。不是所有任务都会被统一公平对待, CFS 引入了组来处理这种行为。产生任务的服务器进程在整个组中(在一个层次结构中)共享它们的虚拟运行时,而单个任务维持其自己独立的虚拟运行时。这样单个任务会收到与组大致相同的调度时间。您会发现 /proc 接口用于管理进程层次结构,让您对组的形成方式有完全的控制。使用此配置,您可以跨用户、跨进程或其变体分配公平性。
考虑一个两用户示例,用户 A 和用户 B 在一台机器上运行作业。用户 A 只有两个作业正在运行,而用户 B 正在运行 48 个作业。组调度使 CFS 能够对用户 A 和用户 B 进行公平调度,而不是对系统中运行的 50 个作业进行公平调度。每个用户各拥有 50% 的 CPU 使用。用户 B 使用自己 50% 的 CPU 分配运行他的 48 个作业,而不会占用属于用户 A 的另外 50% 的 CPU 分配。
4、Linux调度器的主要数据结构
(1)进程描述符:struct task_struct
下面代码剖析使用的内核版本为2.6.32.45。CFS去掉了struct prio_array,并引入调度实体(scheduling entity)和调度类 (scheduling classes),分别由struct sched_entity 和 struct sched_class 定义。因此,task_struct结构(在./linux/include/linux/sched.h中)包含关于 sched_entity 和 sched_class。如下:
struct task_struct {
volatile long state; /* -1 unrunnable, 0 runnable, >0 stopped */
void *stack;
atomic_t usage;
unsigned int flags; /* per process flags, defined below */
unsigned int ptrace;
/* ...... */
int prio, static_prio, normal_prio;
unsigned int rt_priority;
const struct sched_class *sched_class;
struct sched_entity se;
struct sched_rt_entity rt;
/* ...... */
};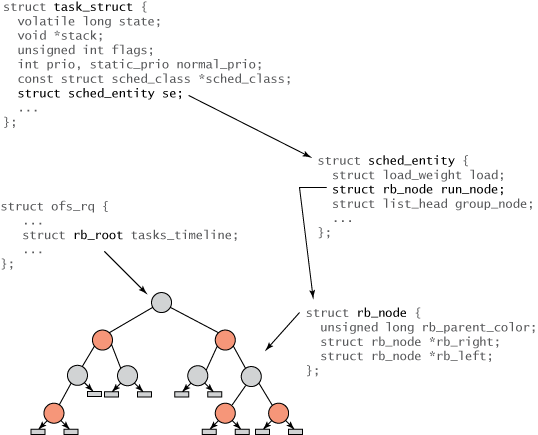
图5 进程调度的数据结构层次
各种结构的关系如上图所示。树的根通过 rb_root 元素通过 cfs_rq 结构(在 ./kernel/sched.c 中)引用。红黑树的叶子不包含信息,但是内部节点代表一个或多个可运行的任务。红黑树的每个节点都由 rb_node 表示,它只包含子引用和父对象的颜色。 rb_node 包含在 sched_entity 结构中,该结构包含 rb_node 引用、负载权重以及各种统计数据。最重要的是, sched_entity 包含 vruntime(64 位字段),它表示任务运行的时间量,并作为红黑树的索引。 最后,task_struct 位于顶端,它完整地描述任务并包含 sched_entity 结构。
就 CFS 部分而言,调度函数非常简单。 在 ./kernel/sched.c 中,您会看到通用 schedule() 函数,它会先抢占当前运行任务(除非它通过 yield() 代码先抢占自己)。注意 CFS 没有真正的时间切片概念用于抢占,因为抢占时间是可变的。 当前运行任务(现在被抢占的任务)通过对 put_prev_task 调用(通过调度类)返回到红黑树。 当 schedule 函数开始确定下一个要调度的任务时,它会调用 pick_next_task 函数。此函数也是通用的(在 ./kernel/sched.c 中),但它会通过调度器类调用 CFS 调度器。 CFS 中的 pick_next_task 函数可以在 ./kernel/sched_fair.c(称为 pick_next_task_fair())中找到。 此函数只是从红黑树中获取最左端的任务并返回相关 sched_entity。通过此引用,一个简单的 task_of() 调用确定返回的 task_struct 引用。通用调度器最后为此任务提供处理器。
(2)调度实体:struct sched_entity
该结构在./linux/include/linux/sched.h中,表示一个可调度实体(进程,进程组,等等)。它包含了完整的调度信息,用于实现对单个任务或任务组的调度。调度实体可能与进程没有关联。
struct sched_entity {
struct load_weight load; /* 用于负载平衡 */
struct rb_node run_node; /* 对应的红黑树结点 */
struct list_head group_node;
unsigned int on_rq;
u64 exec_start;
u64 sum_exec_runtime;
u64 vruntime; /* 虚拟运行时 */
u64 prev_sum_exec_runtime;
u64 last_wakeup;
u64 avg_overlap;
u64 nr_migrations;
u64 start_runtime;
u64 avg_wakeup;
u64 avg_running;
#ifdef CONFIG_SCHEDSTATS
u64 wait_start;
u64 wait_max;
u64 wait_count;
u64 wait_sum;
u64 iowait_count;
u64 iowait_sum;
u64 sleep_start;
u64 sleep_max;
s64 sum_sleep_runtime;
u64 block_start;
u64 block_max;
u64 exec_max;
u64 slice_max;
u64 nr_migrations_cold;
u64 nr_failed_migrations_affine;
u64 nr_failed_migrations_running;
u64 nr_failed_migrations_hot;
u64 nr_forced_migrations;
u64 nr_wakeups;
u64 nr_wakeups_sync;
u64 nr_wakeups_migrate;
u64 nr_wakeups_local;
u64 nr_wakeups_remote;
u64 nr_wakeups_affine;
u64 nr_wakeups_affine_attempts;
u64 nr_wakeups_passive;
u64 nr_wakeups_idle;
#endif
#ifdef CONFIG_FAIR_GROUP_SCHED
struct sched_entity *parent;
/* rq on which this entity is (to be) queued: */
struct cfs_rq *cfs_rq;
/* rq "owned" by this entity/group: */
struct cfs_rq *my_q;
#endif
};(3)调度类:struct sched_class
该调度类也在sched.h中,是对调度器操作的面向对象抽象,协助内核调度程序的各种工作。调度类是调度器管理器的核心,每种调度算法模块需要实现struct sched_class建议的一组函数。
struct sched_class {
const struct sched_class *next;
void (*enqueue_task) (struct rq *rq, struct task_struct *p, int wakeup,
bool head);
void (*dequeue_task) (struct rq *rq, struct task_struct *p, int sleep);
void (*yield_task) (struct rq *rq);
void (*check_preempt_curr) (struct rq *rq, struct task_struct *p, int flags);
struct task_struct * (*pick_next_task) (struct rq *rq);
void (*put_prev_task) (struct rq *rq, struct task_struct *p);
#ifdef CONFIG_SMP
int (*select_task_rq)(struct rq *rq, struct task_struct *p,
int sd_flag, int flags);
unsigned long (*load_balance) (struct rq *this_rq, int this_cpu,
struct rq *busiest, unsigned long max_load_move,
struct sched_domain *sd, enum cpu_idle_type idle,
int *all_pinned, int *this_best_prio);
int (*move_one_task) (struct rq *this_rq, int this_cpu,
struct rq *busiest, struct sched_domain *sd,
enum cpu_idle_type idle);
void (*pre_schedule) (struct rq *this_rq, struct task_struct *task);
void (*post_schedule) (struct rq *this_rq);
void (*task_waking) (struct rq *this_rq, struct task_struct *task);
void (*task_woken) (struct rq *this_rq, struct task_struct *task);
void (*set_cpus_allowed)(struct task_struct *p,
const struct cpumask *newmask);
void (*rq_online)(struct rq *rq);
void (*rq_offline)(struct rq *rq);
#endif
void (*set_curr_task) (struct rq *rq);
void (*task_tick) (struct rq *rq, struct task_struct *p, int queued);
void (*task_fork) (struct task_struct *p);
void (*switched_from) (struct rq *this_rq, struct task_struct *task,
int running);
void (*switched_to) (struct rq *this_rq, struct task_struct *task,
int running);
void (*prio_changed) (struct rq *this_rq, struct task_struct *task,
int oldprio, int running);
unsigned int (*get_rr_interval) (struct rq *rq,
struct task_struct *task);
#ifdef CONFIG_FAIR_GROUP_SCHED
void (*task_move_group) (struct task_struct *p, int on_rq);
#endif
};* enqueue_task:当某个任务进入可运行状态时,该函数将得到调用。它将调度实体(进程)放入红黑树中,并对 nr_running 变量加 1。从前面“Linux进程管理”的分析中可知,进程创建的最后会调用该函数。
* dequeue_task:当某个任务退出可运行状态时调用该函数,它将从红黑树中去掉对应的调度实体,并从 nr_running 变量中减 1。
* yield_task:在 compat_yield sysctl 关闭的情况下,该函数实际上执行先出队后入队;在这种情况下,它将调度实体放在红黑树的最右端。
* check_preempt_curr:该函数将检查当前运行的任务是否被抢占。在实际抢占正在运行的任务之前,CFS 调度程序模块将执行公平性测试。这将驱动唤醒式(wakeup)抢占。
* pick_next_task:该函数选择接下来要运行的最合适的进程。
* load_balance:每个调度程序模块实现两个函数,load_balance_start() 和 load_balance_next(),使用这两个函数实现一个迭代器,在模块的 load_balance 例程中调用。内核调度程序使用这种方法实现由调度模块管理的进程的负载平衡。
* set_curr_task:当任务修改其调度类或修改其任务组时,将调用这个函数。
* task_tick:该函数通常调用自 time tick 函数;它可能引起进程切换。这将驱动运行时(running)抢占。
调度类的引入是接口和实现分离的设计典范,你可以实现不同的调度算法(例如普通进程和实时进程的调度算法就不一样),但由于有统一的接口,使得调度策略被模块化,一个Linux调度程序可以有多个不同的调度策略。调度类显著增强了内核调度程序的可扩展性。每个任务都属于一个调度类,这决定了任务将如何调度。 调度类定义一个通用函数集,函数集定义调度器的行为。例如,每个调度器提供一种方式,添加要调度的任务、调出要运行的下一个任务、提供给调度器等等。每个调度器类都在一对一连接的列表中彼此相连,使类可以迭代(例如, 要启用给定处理器的禁用)。注意,将任务函数加入队列或脱离队列只需从特定调度结构中加入或移除任务。 核心函数 pick_next_task 选择要执行的下一个任务(取决于调度类的具体策略)。调度类的图形视图如下:

图6 调度类图形视图
这里sched_rt.c, sched_fair.c, sched_idletask.c等(都在kernel/目录下)就是不同的调度算法实现。不要忘了调度类是任务结构本身的一部分(参见task_struct)。这一点简化了任务的操作,无论其调度类如何。因为进程描述符中有sched_class引用,这样就可以直接通过进程描述符来调用调度类中的各种操作。在调度类中,随着调度域的增加,其功能也在增加。 这些域允许您出于负载平衡和隔离的目的将一个或多个处理器按层次关系分组。 一个或多个处理器能够共享调度策略(并在其之间保持负载平衡),或实现独立的调度策略。
不过Linux调度程序本身还没有被模块化,这是一个可以改进的地方。例如对Pluggable CPU调度程序框架,在内核编译时可以选择默认调度程序,在启动时通过向内核传递参数也可以选择其他的CPU调度程序。
(4)可运行队列:struct rq
调度程序每次在进程发生切换时,都要从可运行队列中选取一个最佳的进程来运行。Linux内核使用rq数据结构(以前的内核中该结构为runqueue)表示一个可运行队列信息(也就是就绪队列),每个CPU都有且只有一个这样的结构。该结构在kernel/sched.c中,不仅描述了每个处理器中处于可运行状态(TASK_RUNNING),而且还描述了该处理器的调度信息。如下:
struct rq {
/* runqueue lock: */
spinlock_t lock;
/*
* nr_running and cpu_load should be in the same cacheline because
* remote CPUs use both these fields when doing load calculation.
*/
unsigned long nr_running;
#define CPU_LOAD_IDX_MAX 5
unsigned long cpu_load[CPU_LOAD_IDX_MAX];
#ifdef CONFIG_NO_HZ
unsigned long last_tick_seen;
unsigned char in_nohz_recently;
#endif
/* capture load from *all* tasks on this cpu: */
struct load_weight load;
unsigned long nr_load_updates;
u64 nr_switches;
struct cfs_rq cfs;
struct rt_rq rt;
#ifdef CONFIG_FAIR_GROUP_SCHED
/* list of leaf cfs_rq on this cpu: */
struct list_head leaf_cfs_rq_list;
#endif
#ifdef CONFIG_RT_GROUP_SCHED
struct list_head leaf_rt_rq_list;
#endif
/*
* This is part of a global counter where only the total sum
* over all CPUs matters. A task can increase this counter on
* one CPU and if it got migrated afterwards it may decrease
* it on another CPU. Always updated under the runqueue lock:
*/
unsigned long nr_uninterruptible;
struct task_struct *curr, *idle;
unsigned long next_balance;
struct mm_struct *prev_mm;
u64 clock;
u64 clock_task;
atomic_t nr_iowait;
#ifdef CONFIG_SMP
struct root_domain *rd;
struct sched_domain *sd;
unsigned long cpu_power;
unsigned char idle_at_tick;
/* For active balancing */
int post_schedule;
int active_balance;
int push_cpu;
/* cpu of this runqueue: */
int cpu;
int online;
unsigned long avg_load_per_task;
struct task_struct *migration_thread;
struct list_head migration_queue;
u64 rt_avg;
u64 age_stamp;
u64 idle_stamp;
u64 avg_idle;
#endif
#ifdef CONFIG_IRQ_TIME_ACCOUNTING
u64 prev_irq_time;
#endif
/* calc_load related fields */
unsigned long calc_load_update;
long calc_load_active;
#ifdef CONFIG_SCHED_HRTICK
#ifdef CONFIG_SMP
int hrtick_csd_pending;
struct call_single_data hrtick_csd;
#endif
struct hrtimer hrtick_timer;
#endif
#ifdef CONFIG_SCHEDSTATS
/* latency stats */
struct sched_info rq_sched_info;
unsigned long long rq_cpu_time;
/* could above be rq->cfs_rq.exec_clock + rq->rt_rq.rt_runtime ? */
/* sys_sched_yield() stats */
unsigned int yld_count;
/* schedule() stats */
unsigned int sched_switch;
unsigned int sched_count;
unsigned int sched_goidle;
/* try_to_wake_up() stats */
unsigned int ttwu_count;
unsigned int ttwu_local;
/* BKL stats */
unsigned int bkl_count;
#endif
};spinlock_t lock:保护进程链表的自旋锁。
unsigned long nr_running:目前处理器的运行队列中进程数量。
unsigned long cpu_load[CPU_LOAD_IDX_MAX]:用以表示处理器的负载,在每个处理器的rq中都会有对应到该处理器的cpu_load参数配置,在每次处理器触发scheduler tick时,都会呼叫函数update_cpu_load_active,进行cpu_load的更新。在系统初始化的时候会呼叫函数sched_init把rq的cpu_load array初始化为0。了解他的更新方式最好的方式是通过函数update_cpu_load,公式如下:
cpu_load[0]会直接等待rq中load.weight的值。
cpu_load[1]=(cpu_load[1]*(2-1)+cpu_load[0])/2
cpu_load[2]=(cpu_load[2]*(4-1)+cpu_load[0])/4
cpu_load[3]=(cpu_load[3]*(8-1)+cpu_load[0])/8
cpu_load[4]=(cpu_load[4]*(16-1)+cpu_load[0]/16
呼叫函数this_cpu_load时,所返回的cpu load值是cpu_load[0]。而在进行cpu blance或migration时,就会呼叫函数source_load target_load取得对该处理器cpu_load index值,来进行计算。
struct load_weight load:负载权重,即load->weight值。会是目前所执行的schedule entity的load->weight的总和,也就是说rq的load->weight越高,说明所负责的进程单元load->weight总和越高,表示处理器所负荷的执行单元也越重。
unsigned long nr_load_updates:在每次scheduler tick中呼叫update_cpu_load时,这个值就增加一,可以用来反馈目前cpu load更新的次数。
u64 nr_switches:CPU执行进程切换的次数。用来累加处理器进行context switch的次数,会在函数schedule呼叫时进行累加,并可以通过函数nr_context_switches统计目前所有处理器总共的context switch次数,或是可以透过查看文件/proc/stat中的ctxt位得知目前整个系统触发context switch的次数。
struct cfs_rq cfs:用于公平调度的CFS运行队列。
struct rt_rq rt:用于实时进程调度的运行队列。
struct list_head leaf_cfs_rq_list:目前CPU上叶子cfs_rq的列表。
unsigned long nr_uninterruptible:之前在运行队列中而现在处于重度睡眠状态的进程总数。
task_t *curr:指向本地CPU当前正在运行的进程的进程描述符,即current。
task_t *idle:指向本地CPU上的idle进程描述符的指针。
unsigned long next_balance:基于处理器的jiffies值,用以记录下次进行处理器balancing的时间点。
struct mm_struct *prev_mm:在进程进行切换时用来存放被替换进程内存描述符的地址。
u64 clock:目前CPU的时钟值。
int cpu:本运行队列对应的CPU
最后是调度的一个些统计信息,包括sys_sched_yield()、schedule()、try_to_wake_up()的统计信息。注意现在rq结构中已经没有active/expire数组了,因此现在rq结构并不直接维护进程队列,对CFS进程队列由红黑树来维护(对实时调度则仍使用组链表),并且以时间为顺序。rq结构中的cfs结构有指向红黑树的根结点,由此可以访问到红黑树。
(5)CFS运行队列:struct cfs_rq
该结构在kernel/sched.c中,是用于CFS调度的运行队列。对于每个运行队列信息,都提供了一个cfs_rq结构来保存相关红黑树的信息。
struct cfs_rq {
struct load_weight load; /* 运行负载 */
unsigned long nr_running; /* 运行进程个数 */
u64 exec_clock;
u64 min_vruntime; /* 保存的最小运行时间 */
struct rb_root tasks_timeline; /* 运行队列树根 */
struct rb_node *rb_leftmost; /* 保存的红黑树最左边的节点,这个为最小运行时间的节点,
当进程选择下一个来运行时,直接选择这个 */
struct list_head tasks;
struct list_head *balance_iterator;
/*
* 'curr'指针指向本cfs_rq上当前正在运行的进程,如果本cfs_rq上没有正在运行的进程,则指向NULL
*/
struct sched_entity *curr, *next, *last;
unsigned int nr_spread_over;
#ifdef CONFIG_FAIR_GROUP_SCHED
struct rq *rq; /* 本cfs_rq关联的运行队列 */
/* 叶子cfs_rqs是那些层次中最底层的可调度实体,它们持有进程。非叶子lrqs持有其他更高层的可调用实体(例如用户,容器等)
* leaf_cfs_rq_list用来把一个CPU上的叶子cfs_rq列表串结成一个列表,这个列表被用在负载平衡中
*/
struct list_head leaf_cfs_rq_list;
struct task_group *tg; /* 拥有本运行队列的组 */
#ifdef CONFIG_SMP
/*
* 由进程贡献的load.weight部分
*/
unsigned long task_weight;
/*
* h_load = weight * f(tg)
* 其中f(tq)表示分配给组的迭代权重值
*/
unsigned long h_load;
/*
* this cpu's part of tg->shares
*/
unsigned long shares;
/*
* load.weight at the time we set shares
*/
unsigned long rq_weight;
#endif
#endif
};(6)红黑树结点:struct rb_node, struct rb_root
struct rb_node
{
unsigned long rb_parent_color;
#define RB_RED 0
#define RB_BLACK 1
struct rb_node *rb_right;
struct rb_node *rb_left;
} __attribute__((aligned(sizeof(long))));
/* The alignment might seem pointless, but allegedly CRIS needs it */
struct rb_root
{
struct rb_node *rb_node;
};还有很多其他的数据结构,如调度域sche_domain(在include/linux/sched.h中)、根域root_domain(在kernel/sched.c中)、任务组task_group(在kernel/sched.c中)等,这里不一一介绍了。
我们可以从设计层面来总结Linux进程调度一些设计思想:
把进程抽象成进程描述符task_struct:包含进程所必需的数据,如状态信息、调度信息、优先级信息、内存页信息等。
把需要调度的东西抽象成调度实体sched_entity:调度实体可以是进程、进程组、用户等。这里包含负载权重值、对应红黑树结点、虚拟运行时vruntime等。
把调度策略(算法)抽象成调度类sched_class:包含一组通用的调度操作接口,将接口和实现分离。你可以根据这组接口实现不同的调度算法,使得一个Linux调度程序可以有多个不同的调度策略。
把调度的组织抽象成可运行队列rq:包含自旋锁、进程数量、用于公平调度的CFS信息结构、当前正在运行的进程描述符等。实际的进程队列用红黑树来维护(通过CFS信息结构来访问)。
把CFS调度的运行队列信息抽象成cfs_rq:包含红黑树的根结点、正在运行的进程指针、用于负载平衡的叶子队列等。















 682
682

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









