







1. 代码基本结构
定义theano符号变量,作为函数的输入变量
byte: bscalar, bvector, bmatrix, brow, bcol, btensor3, btensor4
16-bit integers: wscalar, wvector, wmatrix, wrow, wcol, wtensor3, wtensor4
32-bit integers: iscalar, ivector, imatrix, irow, icol, itensor3, itensor4
64-bit integers: lscalar, lvector, lmatrix, lrow, lcol, ltensor3, ltensor4
float: fscalar, fvector, fmatrix, frow, fcol, ftensor3, ftensor4
double: dscalar, dvector, dmatrix, drow, dcol, dtensor3, dtensor4
complex: cscalar, cvector, cmatrix, crow, ccol, ctensor3, ctensor4定义shared共享变量,作为需要更新的权重,可以使用
get_value()和set_value()方法访问和设置变量的值。shared(value, name=None, strict=False, allow_downcast=None, kwargs)
name仅仅表示调试过程中的名称,可以带有参数borrow=True,表示访问该变量时不用从内存中拷贝;broadcastable=[True or False],表示变量在哪些维度上可以扩展
构建theano表达式(模型),通过点乘或者卷积将输入的符号变量前向传播获得输出,定义损失函数,并确定待优化的权重参数,利用
grad()直接求取梯度并得到更新参数列表编译训练和预测函数
function(inputs, outputs=None, mode=None, updates=None, givens=None, no_default_updates=False, accept_inplace=False, name=None, rebuild_strict=True, allow_input_downcast=None, profile=None, on_unused_input=None)
参数allow_input_downcast=True表示使用GPU运算时可以允许精度损失;
训练过程,每一轮训练(称为
epoch)使用mini-batch分批处理数据集,batch的大小控制着每一轮训练参数更新的次数,不同的更新次数可能会导致不同的训练结果,因此调整batch的大小时其他参数也需要微调
2. 使用技巧
1. 基础
- 数据格式
- 输入的数据集格式为4D矩阵(样本数,特征图个数,图像行数,图像列数)
- 卷积层连接权重w=(本层特征图个数,上层特征图个数,卷积核行数,卷积核列数),偏置b=(1,本层特征图个数,1,1)
- 全连接层就是普通的MLP,输入神经元就是最后一个卷积层所有展开成一维的神经元,输出使用softmax分类器
- 可以调整的参数有:
- 每个卷积层中特征图的个数
- 卷积核的大小,调整后需要重新计算最后一层特征图的大小,以调整全连接层的输入神经元个数
- MLP隐藏层的神经元个数
- 其他超参数,包括学习率、惩罚系数、卷积层和隐藏层的dropout比例。
2. 语法使用
broadcastable
broadcastable为一个bool变量列表,其中True表示可以在该维度上扩展dimshuffle
给tensor插入可以扩展的维度,使之可以与相同维度的矩阵相加,新插入维度为1,broadcastable属性为True。也可以改变维度的顺序,和reshape效果相同。其中元素的顺序不发生改变,只改变构成的维度。conv2d
卷积操作有两个实现:nnet.conv.conv2d和nnet.conv2dnnet.conv.conv2d:旧的CPU卷积实现,是标准的CNN中二维卷积操作(滤波器会被翻转),也可以用于GPU上,但是没有良好的图形优化,会相对慢一些,接口为:conv2d(input, filters, image_shape=None, filter_shape=None, border_mode=’valid’, subsample=(1, 1), kargs)
注意: border_mode只有两个选项 {‘valid’, ‘full’}nnet.conv2d:2015年12月提出的新的GPU卷积实现,基于符号化图形优化速度会更快,接口为:conv2d(input, filters, input_shape=None, filter_shape=None, border_mode=’valid’, subsample=(1, 1), filter_flip=True, image_shape=None, kwargs)
注意: border_mode有5个选项 {‘valid’, ‘full’, ‘half’, int, (int, int)},但是后三个仅支持GPU,在CPU上运行只能选择前两个(与旧接口一致)。- 特点:在GPU实现时有极高的优化,应该尽量使用
conv2d操作(例如可以用滤波器大小为1 × 1的卷积代替全连接所使用的dot操作) - 对
conv2d操作的理解:
input=(样本数n,输入特征图数p,输入图行数r,输入图列数c)
filters=(本层特征图数q,上层输入特征图数p,滤波器行数3,滤波器列数3)
output=(样本数n,本层特征图数q,输出图行数r’,输出图列数c’)
对p个输入特征图分别对应p个3 × 3滤波器去卷积,所得结果特征图全部相加,得到1张本层特征图;换不同的(p,3,3)滤波器重复操作q次,得到本层所有的q张特征图;对所有的样本n都共享同样的滤波器参数和操作。- 特点:在GPU实现时有极高的优化,应该尽量使用
pool_2d
原始的signal.downsample.max_pool_2d移动到了signal.pool.pool_2d,提供的选项更多,接口为:pool_2d(input, ds, ignore_border=None, st=None, padding=(0, 0), mode=’max’)
dot
对于两个2维矩阵:矩阵乘法
对于两个向量:内积
有一个是标量:逐个元素乘法
对于2维矩阵A和3维矩阵B:例如A是(5,2),B是(4,2,3),结果为(5,4,3),A的最后维度与B的中间维度相乘,可以看作A分别与B的(2,3)矩阵相乘4次得到4个(5,3)矩阵,而它们的每一行放在一起增加了一个维度4tensordot
实现了任意维度的张量乘法。可以将之展开成多层循环来计算,需要保留的维度在循环外层,求和相加的维度在循环内层,且先求和的循环在后求和的循环的内层。参考numpy.tensordotreshape
可以在不改变数据总数的情况下改变数据的维度,也可以有split和stack的方法,但是reshape效率最高。其中元素的顺序不发生改变,只改变构成的维度。transpose
张量维度的重排列,对于一般2维矩阵就是转置(axes=(1,0)),矩阵元素的顺序发生改变(与reshape不同)。对于多维矩阵就可以按照维度进行重新组合,利用元素的顺序的变化可以实现张量按照一个维度的拼接。对(64,32,n,28,28),想要将32个(n,28,28)在第二维度拼接,可以transpose(axes=(0,2,1,3,4))得到(64,n,32,28,28)scan
scan(fn, # 函数的引用,每次迭代需要进行的基本操作
sequences=None, # 可迭代序列
outputs_info=None, # 输出的初始值
non_sequences=None, # 在迭代中不变的变量
n_steps=None, # 迭代的次数
truncate_gradient=-1,
go_backwards=False,
mode=None,
name=None,
profile=False,
allow_gc=None,
strict=False)fn函数的输入变量顺序:[sequences, outputs_info, non_sequences],每个都可以是一个列表,需要和fn输入变量依次对应。
scan的返回结果:(1)迭代结果:将每一步迭代的结果在原有维度之前增加维度进行拼接,这个维度的值就是迭代的次数。(2)更新:如果non_sequences中有shared变量,且fn返回更新的字典,那么更新可以将shared变量在迭代中更新赋值。fn的返回可以既包括迭代结果,也包括更新。
python循环转化scan的技巧:对于含有索引值的单层python循环,可以将索引值的集合作为sequences,在fn中使用这些索引值的就可以了。注意索引结果的该维度消失,如果计算中需要保留该维度应该提前dimshuffle。对于含有索引值的多层python循环,提供多层索引值就可以了。其中经常使用reshape,dimshuffle,transpose
for i in range(64):
x[i] += 1
index = theano.tensor.arange(64, dtype='int32') # 0,1,...,63
results, updates = theano.scan(fn=lambda i, x : x[i] + 1,
sequences=[index],
outputs_info=None,
non_sequences=[x])
for i in range(64):
for j in range(32):
x[i,j] += 1
indexi = theano.tensor.arange(64, dtype='int32')
indexi = theano.tensor.repeat(indexi, 32, axis=0) # 0,0,...,0,1,1,...,1,2,2,...,2,...,63,63,...,63
indexj = theano.tensor.arange(32, dtype='int32')
indexj = theano.tensor.tile(indexj, 64) # 0,1,...,31,0,1,...,31,0,1,...,31,...,0,1,...,31,
results, updates = theano.scan(fn=lambda i, j, x : x[i,j] + 1,
sequences=[indexi, indexj],
outputs_info=None,
non_sequences=[x])3. GPU加速
1. 配置
参考deeplearning.net/theano/config
- 可以使用
THEANO_FLAGS=[key1]=[value1],[key2]=[value2]放在python *.py之前来配置环境变量 - 配置文件
.theanorc放在用户主目录下,这些配置对于theano模块只读行且不能被用户代码修改。其内容为
[global]
device = gpu # or cpu
floatX = float32 # GPU只允许32位
allow_gc = False # 不进行垃圾回收可加速,但容易OOM
openmp = True # 允许CPU并行计算
mode = FAST_RUN
assert_no_cpu_op = warn # 网络图是否存在CPU计算
optimizer = fast_run
optimizer_verbose = True # 输出优化信息
exception_verbosity = high
[cuda]
root = /usr/local/cuda-7.5
[dnn]
enabled = True # 使用cuDNN加速
[nvcc]
fastmath = True
[lib]
cnmem = 1 # 使用CNMeM(快速CUDA内存分配)的比例说明: 直接在config下面的属性放在[global]区块内,而在其子属性下面的放在相应区块内
2. 能被加速的操作
参考deeplearning.net/theano/using_gpu
float32类型的数据
矩阵乘法、卷积、逐元素操作
索引,dimshuffle,reshape与CPU相同
tensor逐行/列求和比CPU慢
从GPU复制数据比较慢,但实验证明将数据集装入shared变量不能提高运行速度,反而降低了不少
3. 使用borrow=True
参考deeplearning.net/theano/aliasing
import theano
# shared变量使用borrow可以避免复制
s = theano.shared(array, borrow=True)
s.get_value(borrow=True)
s.set_value(fn(s.get_value(borrow=True)), borrow=True)
# function中使用In/Out可以避免重新分配内存
f = theano.function([theano.In(x, borrow=True)], theano.Out(y, borrow=True))3. 网络设计技巧
1. 每一层dropout操作
dropout是指在模型一个batch样本训练时随机舍弃网络某些隐含层节点,这些节点可以暂时认为不是网络结构的一部分,但是它的权重保留下来(暂时不更新),下一个batch样本训练时重新随机舍弃节点,上一次舍弃的节点可能仍旧舍弃或者得以工作。这样做可以有如下的作用:
- 节点都是以一定概率随机出现,这样权值的更新不再依赖于有固定关系节点的共同作用,阻止了某些依赖于其它特定特征的情况
- 是一种模型平均(类似于bagging),每一个batch样本都只是部分特征参与训练,而对应的网络模型都是不同的(与bagging相同),但每个模型只在一个batch上训练一步(到下一个batch时该模型不再使用而换成了另一个模型), 且所有模型共享节点的权值(与bagging不同)。
2. 使用线性修正单元relu作为激活函数
传统神经网络中最常用的两个激活函数(Logistic-Sigmoid、Tanh-Sigmoid)被视为神经网络的核心所在。而从生物学角度,脑神经元接受信号更精确的激活模型为relu,公式:
max(0,x)
,具有特点:(参考ReLu(Rectified Linear Units)激活函数)
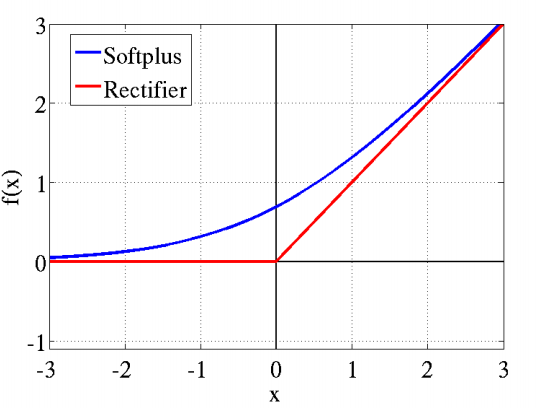
- 稀疏激活性:原始数据中通常有高度相关的特征而互相影响,稀疏特征则具有鲁棒性。这里神经元同时只对少量输入信号选择性响应,大量信号被刻意的屏蔽,这样可以提高学习的精度,更好更快地提取稀疏特征。传统的
sigmoid系函数同时近乎有一半的神经元被激活,这不符合神经科学的研究,而且会导致梯度消失,深度网络训练慢的问题。但是过分的强制稀疏处理,会减少模型的有效容量,即特征屏蔽太多,导致模型无法学习到有效特征。所以要通过调整relu的比较值来控制稀疏的比例 - 单侧抑制和具有非饱和的线性端:神经元与神经元之间为线性激活,则网络的非线性部分仅来自于神经元选择性激活,如下图所示。这种激活函数计算速度快,训练速度快,并解决了
sigmoid中梯度消失的问题。
3. 参数更新
rmsprop使用了当前梯度大小的均方根来归一化当前梯度更新,使用中发现初始学习率需要选择较小的数值(<1e-3)。sgd_momentum则使用SGD结合动量项,再结合学习率和动量项系数退火的策略,即每当验证集误差停止减小或者执行一定数量的epoch后学习率降低2或10倍继续迭代,同时也可以结合动量项系数[0.5, 0.9, 0.95, 0.99]的退火策略(动量项系数越大,学习率更新的越平稳)。这里初始学习率可以选择较大的数值(<1e-2)。
4. 调试错误
结果中出现nan:输入数据中是否有nan,参数初始化是否有nan,是否会有除以0的计算,是否会在计算中出现数值过大的情况(注意数据归一化,或者学习率过大导致损失指数增加)
无法获得符号表示的tensor的数字维度:符号表示的tensor直到具体值输入的时候才会有具体的维度,否则其维度也只是一个符号Shape.0,在有具体值输入的时候获取维度可以使用
.eval()或theano.function()获得。]x = theano.tensor.matrix() x.shape.eval({x: concrete_x}) theano.function(inputs=[x], outputs=x.shape)(concrete_x)构建theano符号图中出现python循环和python表达式(列表,元组,字典,range):
单层循环:只是优化过程比较复杂,编译时间会比较长
多层循环:只是两层就已经无法优化了,编译时间会无限制延长
python表达式:导致优化过程明显变复杂,使用过多会无法编译(递归栈溢出)
应该使用theano.scan来实现循环,这样的好处是迭代的次数是符号图的一部分,最小化GPU的迁移,通过连续的步骤计算梯度,降低总的内存使用情况。对
TensorVariable的索引可以直接使用int值或者TensorVariable都可以,都会使索引的维度消失,因此索引后注意dimshuffle添加入消失的维度。














 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









