







概述:以数据为中心,覆盖数据的采集到可视化展现整个流程,提供流式和离线两种实时计算方式加工处理数据,针对加工后的数据提供丰富的可视化展现,也可以自行定制个性化的数据展现。
整体方案:

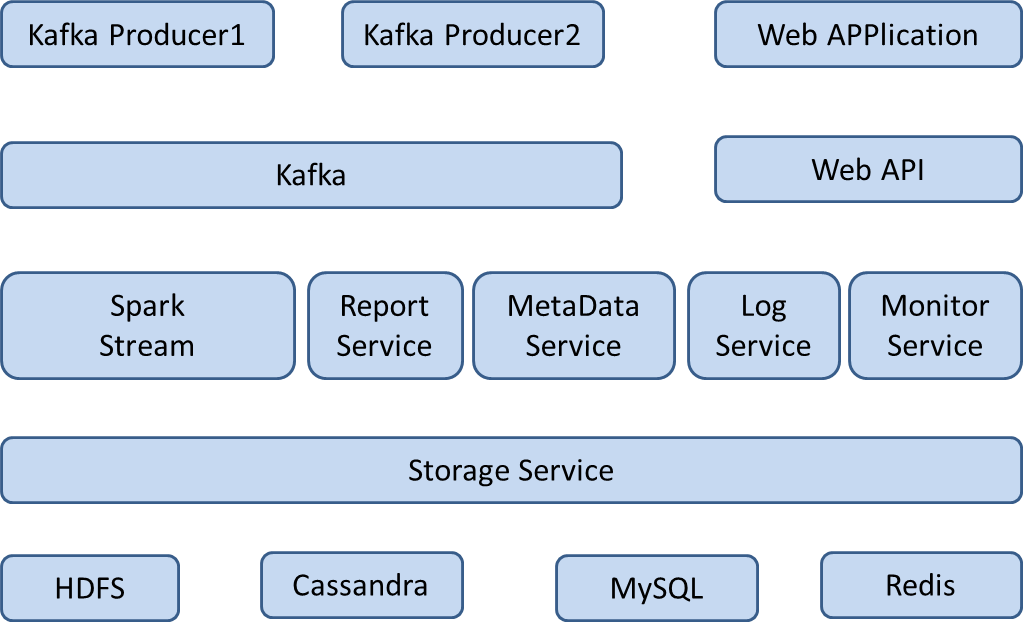
流程:1,数据采集 ---→ 2,数据预处理 ---→ 3,数据实时聚合(单批数据)---→ 4,数据存储 ---→ 5,数据查询 —→ 6,数据聚合 ---→ 7,数据展现
主要模块:
元数据配置(采集项、统计项、报表):MetaData Service,WebApp
数据采集/加工/存储(1,数据采集、2,数据预处理、3,数据实时聚合、4,数据存储)-----流式实时计算:Spark Stream/SQL,MetaData Service,ExpressionParser
可视化包含(5,数据查询、6,数据聚合、7,数据展现)-----离线实时计算 :Report Service,MetaData Service,WebAPP
日志:Log Service
监控:Monitor Service
相关技术:Scala、Spark、Akka、Spray、Slick、Kafka、AngularJS、React、Cassandra、MySQL、Redis
WebAPI:REST API
使用Spray.can构建的HttpServer,底层基于Akaka的ActorSystem,启动ActorSystem时实例化了ApiRouterActor,外部通过http访问api时,由ApiRouterActor路由到不同的Actor,进而调用不同的Service
ApiRouterActor:api路由actor,通过路由规则分发url请求到不同的Actor
SparkActor:负责启动SparkStramActor,并通过同步消息跟踪其状态、查询实时数据
SparkStreamActor:流式计算Actor,从Kafka实时分批次接收数据,经过预处理后进行实时聚合计算加工,在此过程中会把预处理后的数据和计算后的发送到Kafka,后续的存储服务会从Kafka接收数据并保存到Cassandra
ReportActor:报表Actor,响应可视化报表的请求,通过Storage Service检索数据,启动SparkOfflineActor,并通过同步消息跟踪其状态,把计算后的结果返回给可视化报表
SparkOfflineActor:离线计算Actor,从ReportActor接收查询数据根据可视化报表的配置进行实时聚合计算加工,计算后的结果通过ReportActor返回给可视化报表
object ApiRouterActor {
val routes = Map(
"inputdto" -> "cn.xiaoneng.actors.routes.InputDtoRouteActor",
"dashboarddto" -> "cn.xiaoneng.actors.routes.DashboardDtoRouteActor",
"dtoproperty" -> "cn.xiaoneng.actors.routes.Dto_PropertyRouteActor",
"statisdto" -> "cn.xiaoneng.actors.routes.StatisDtoRouteActor",
"eventgroup" -> "cn.xiaoneng.actors.routes.EventGroupRouteActor",
"spark"->"cn.xiaoneng.actors.routes.SparkActor",
"report"->"cn.xiaoneng.actors.routes.ReportActor")
def instance: Props = Props(new ApiRouterActor(routes))
}
class ApiRouterActor(routes: Map[String,String]) extends HttpServiceActor
with ActorLogging {
override def preStart = {
for ((key, value) <- ApiRouterActor.routes) actorRefFactory.actorOf(Props(Class.forName(value).asInstanceOf[Class[Actor]]), key)
}
def receive = runRoute {
compressResponseIfRequested() {
pathPrefix("api") {
respondWithHeader(RawHeader("Access-Control-Allow-Origin", "*")) {
(options) {
respondWithHeaders(List(RawHeader("Access-Control-Allow-Methods", "POST, GET, DELETE, PUT, PATCH, OPTIONS"), RawHeader("Access-Control-Allow-Headers", "Content-Type, Authorization, Accept,X-Requested-With"))) {
complete(StatusCodes.NoContent)
}
} ~
pathPrefix("person") { ctx => actorRefFactory.actorSelection("person") ! ctx } ~
pathPrefix("order") { ctx => actorRefFactory.actorSelection("order") ! ctx } ~
pathPrefix("inputdto") { ctx => actorRefFactory.actorSelection("inputdto") ! ctx } ~
pathPrefix("dashboarddto") { ctx => actorRefFactory.actorSelection("dashboarddto") ! ctx } ~
pathPrefix("dtoproperty") { ctx => actorRefFactory.actorSelection("dtoproperty") ! ctx } ~
pathPrefix("statisdto") { ctx => actorRefFactory.actorSelection("statisdto") ! ctx }~
pathPrefix("spark") { ctx => actorRefFactory.actorSelection("spark") ! ctx }~
pathPrefix("report") { ctx => actorRefFactory.actorSelection("report") ! ctx }~
pathPrefix("eventgroup") { ctx => actorRefFactory.actorSelection("eventgroup") ! ctx }
}
} ~
getFromResourceDirectory("app")
}
}
}
class SparkActor extends HttpServiceActor with SprayJsonSupport {
var sparkStreamActor = None: Option[ActorRef]
def receive = runRoute {
path(Segment) { (actionName: String) =>
actionName match {
case "start_stream" =>
sparkStreamActor = Some(actorRefFactory.actorOf(Props(new SparkStreamActor()),"stream"))
sparkStreamActor.get ! "start"
complete { HttpResponse(OK, "{\"state\":\"starting\"}") }
case "stop_stream" =>
if(!sparkStreamActor.isEmpty) sparkStreamActor.get ! "stop"
complete { HttpResponse(OK, "{\"state\":\"stoping\"}") }
case x :String => {
complete { HttpResponse(OK, "{\"result\":\"unknowed command\"}") }
}
}
}
}
}
class SparkStreamActor extends Actor {
val ssc = innerSparkStream.init
def receive = {
case "start" => {
ssc.start()
sender() ! "starting"
}
case "stop" => {
ssc.stop(true, true)
sender() ! "stoping"
}
case "state" => sender() ! ssc.getState()
case "running_metrics" => sender() ! innerSparkStream.statisResultMap
case _ =>
}
}object innerSparkStream extends Serializable {
def init(): StreamingContext = {
val sparkConf = new SparkConf().setMaster("spark://spark129:7077").setAppName("streaming-query").set("spark.driver.host", "192.168.30.172")
val sc = new SparkContext(sparkConf)
val topics = Set("test")
val brokers = "spark129:9092,spark130:9092,spark131:9092"
val kafkaParams = Map[String, String]("metadata.broker.list" -> brokers, "serializer.class" -> "org.apache.spark.serializer.KryoSerializer")
val kafkaStream = KafkaUtils.createDirectStream[String, String, StringDecoder, StringDecoder](ssc, kafkaParams, topics).map(_._2)
val sparkSqlContext = new SQLContext(sc)
import sparkSqlContext.implicits._
kafkaStream.foreachRDD(rdd => {
if (!rdd.isEmpty()) {
val jsonDF = sparkSqlContext.read.json(rdd)
mapGlobalStatis.foreach(item => {
var df = jsonDF.filter(jsonDF("name") isin (item._2.event_source.split(","): _*))
if (df.count() > 0) {
df = preProcess(df, item._2, secondInputResultMap, sparkSqlContext)
if (df.count() > 0) {
println("加工后的数据:")
df.cache()
df.show()
//发送到kafka进行二次处理
df.toJSON.foreach(row => MyKafkaProducerSingleton.send(new KeyedMessage[String, String]("testspark", row)))
//计算引擎继续后续处理(groupExp)
var colDimensions = item._2.properties.filter(p => !p.propertyType.isEmpty && p.propertyType.get == 1).map(_.name)
colDimensions = Array.concat(Array("time_key"), colDimensions)
val colMetrics = item._2.properties.filter(p => !p.propertyType.isEmpty && p.propertyType.get == 2).map(p => {
p.groupSumExpresion match {
case Some("sum") => sum(p.name).alias(p.name)
case Some("max") => max(p.name).alias(p.name)
case Some("min") => min(p.name).alias(p.name)
case Some("avg") => avg(p.name).alias(p.name)
case _ => col(p.name)
}
})
val getTimeKeyStr = udf((event_time: Long, format: String) => getGroupType(event_time, format))
df = df.withColumn("time_key", getTimeKeyStr($"event_time", lit(item._2.properties.filter(_.name == "event_time").head.groupType.getOrElse(""))))
df = df.groupBy(colDimensions.head, colDimensions.tail: _*).agg(colMetrics.head, colMetrics.tail: _*)
df.cache()
df.show()
//发送到kafka进行序列化存储
df.withColumn("name", lit(item._1)).toJSON.collect().foreach(row => MyKafkaProducerSingleton.send(new KeyedMessage[String, String]("computed_data", row)))
println("计算后的数据:")
if (statisResultMap.contains(item._1)) {
val oldresultDF = statisResultMap.apply(item._1)
df = oldresultDF.unionAll(df) //.groupBy(groupByStr: _*).agg(sum("num").alias("num"))
df.cache()
statisResultMap.update(item._1, df)
} else {
//df.cache()
statisResultMap.put(item._1, df)
}
df.show()
}
}
})
} else {
println("no data")
}
})
ssc
}
//采集数据根据业务逻辑进行预处理(outputExp)
def preProcess(jsonDF: DataFrame, input: InputDtoNew, secondInputResultMap: mutable.HashMap[String, DataFrame], sqlContext: SQLContext): DataFrame = {
//从当前采集事件中提取数据并进行计算
var df = jsonDF
df.show()
val fields = input.properties.map(prop => StructField(prop.name, getDataType(prop.`type`), true))
var st = StructType.apply(fields)
val rddRow = df.rdd.map(row => extractData(row, input))
df = sqlContext.createDataFrame(rddRow, st)
df.cache()
df.show()
//追加当前采集事件的处理结果到内存中未完成的状态事件集合中为后续合并数据作准备
val mapKey = input.name
if (secondInputResultMap.contains(mapKey)) {
val oldresultDF = secondInputResultMap.apply(mapKey)
df = oldresultDF.union(df)
df.cache()
df.show()
} else {
secondInputResultMap.put(mapKey, df)
}
//合并多个采集事件生成新的数据,多了一列cnt用来标识事件状态是否结束
df = mergeExtractedData(df, input)
df.cache()
df.show()
//过滤出未完成的状态事件保存到内存中参与下一批数据处理
import sqlContext.implicits._
val eventCount = input.event_source.split(",").length
println("未完成的状态事件:")
val dfEventCurrentState = df.where($"cnt" < eventCount).select(input.properties.map(p => col(p.name)).toArray: _*)
dfEventCurrentState.cache()
secondInputResultMap.update(mapKey, dfEventCurrentState)
dfEventCurrentState.show()
//过滤出已完成的状态事件通过触发beforecompute事件进行二次加工
//println("已完成的状态事件:")
df = df.where($"cnt" >= eventCount)
val tmpRDDRow = df.rdd.map(row => computeExtractedData(row, input))
df = sqlContext.createDataFrame(tmpRDDRow, st)
//df.cache()
//df.show()
df
}
}
ReportActor
class ReportActor extends HttpServiceActor with SprayJsonSupport with SyncMessage {
import cn.xiaoneng.report.model.reportJsonProtocol._
private val svc = ReportService
var sparkOfflineActors = ArrayBuffer[ActorRef]()
def receive = runRoute {
path(Segment) { (actionName: String) =>
actionName match {
case "running_metrics" =>
val sparkStreamActor = actorRefFactory.actorSelection("../spark/stream")
onComplete(send(actionName, sparkStreamActor)) {
case Success(value) => {
val result = value match {
case map: scala.collection.mutable.HashMap[String, org.apache.spark.sql.DataFrame] => {
val sb = new StringBuilder()
sb.append("{")
map.foreach(kv => {
sb.append("\"" + kv._1 + "\":[")
sb.append(kv._2.toJSON.collect().mkString(","))
sb.append("],")
})
if (map.size > 0) sb.length -= 1
sb.append("}")
sb.toString()
}
case _ => value.toString
}
complete(HttpResponse(OK, result))
}
case Failure(ex) => complete(StatusCodes.ExpectationFailed)
}
case "stream_state" =>
val sparkStreamActor = actorRefFactory.actorSelection("../spark/stream")
onComplete(send("state", sparkStreamActor)) {
case Success(value) => complete(HttpResponse(OK, "{\"state\":\"" + value.toString + "\"}"))
case Failure(ex) => complete(StatusCodes.ExpectationFailed)
}
case "second_input_data" => complete(svc.getSecondInputData)
case "grid" => complete(svc.grid)
case "chart" => complete(svc.chart())
case "grid_spark" => {
val actorid = "offline" + sparkOfflineActors.length.toString
val q = new Query(new QueryItem("name", "String", "totalchat", "="))
val actor = actorRefFactory.actorOf(Props(new SparkOfflineActor()), actorid)
sparkOfflineActors += actor
onComplete(query(q, actor)) {
case Success(value) => complete(HttpResponse(OK, "{\"state\":\"" + value.toString + "\", \"id\":\"" + actorid + "\"}"))
case Failure(ex) => complete(StatusCodes.ExpectationFailed)
}
//sparkOfflineActors -= actor;
}
case "chart_spark" => complete(svc.chart_spark())
case actorid: String if actorid.startsWith("offline") => {
//println(actorid)
val actor = actorRefFactory.actorSelection(actorid)
onComplete(send("query", actor)) {
case Success(value) => {
value match {
case msg: String => complete(HttpResponse(OK, "{\"state\":\"" + msg.toString + "\"}"))
case rpt: ReportBase => {
import cn.xiaoneng.report.model.reportJsonProtocol._
sparkOfflineActors.remove(sparkOfflineActors.indexWhere(_.path.name.endsWith(actorid)))
complete(HttpResponse(OK, "{\"state\":\"ok\",\"result\":" + rpt.toJson.compactPrint + "}"))
}
case _ => complete(HttpResponse(OK, "{\"state\":\"" + value.toString + "\", \"id\":\"" + sparkOfflineActors.length + "\"}"))
}
}
case Failure(ex) => complete(StatusCodes.ExpectationFailed)
}
}
case x: String => complete(HttpResponse(OK, s"actionName: $x"))
}
}
}
}
trait SyncMessage {
def send(msg: String, actorSel: ActorSelection): Future[Any] = {
/**
* 以ask模式来向一个actor发送消息时,需要一个 implicit `akka.util.Timeout`
**/
implicit val timeout = Timeout(20 seconds)
if (actorSel == null) {
Future {
msg
}
} else {
actorSel.ask(msg)
}
}
def query(q: Query, actorRef: ActorRef): Future[Any] = {
implicit val timeout = Timeout(8 seconds)
if (actorRef == null) {
Future {
q
}
} else {
actorRef.ask(q)
}
}
}SparkOfflineActor
class SparkOfflineActor extends Actor with SparkConfTrait {
val timeout = 1 * 1000
var status = "inited";
var result: Option[ReportBase] = None
def receive = {
case q: Query => {
status = "starting"
Future {
getData(q)
}
sender() ! status
}
case cmd: String => {
var m = 0
while (m < 5) {
if (status == "executed") {
m = 5
} else {
Thread.sleep(timeout)
}
m = m + 1
}
val msg = if (m == 5) status else result.get
sender() ! msg
}
case _ =>
}
def getData(q: Query) {
val reportBase = ReportService.grid_spark(q)
val pos = reportBase.columns.indexWhere(_.name == "chatnumber")
//spark计算查询出来的数据
val sc = SparkContext.getOrCreate(sparkConf)
status = "executing"
import cn.xiaoneng.report.model.reportJsonProtocol._
try {
val colMTC = reportBase.columns.filter(_.columnType == "mtc")
var colDMS = reportBase.columns.filter(_.columnType == "dms")
var colIndexDMS = colDMS.map(_.index)
val rdd = sc.parallelize(reportBase.rows)
var tmpRDD = rdd
colDMS.length - 1 to 0 by -1 map(i=> {
val colIndex = colDMS.filter(_.index<=i).map(_.index)
println("colIndex last= "+colIndex.last)
tmpRDD = tmpRDD.groupBy(row => row.cells.filter(cell => colIndex.contains(cell.index)).mkString(",")).map(kv => {
val row = kv._2.head.copy()
colMTC.foreach(col => {
val cnt = kv._2.map(_.cells.apply(col.index).value.get.asInstanceOf[Long]).sum
row.cells.update(col.index, ReportCell(pos, Some(cnt)))
})
row.rowKey = colDMS.apply(i).name
if(colDMS.length - 1 > i) row.children = Some(kv._2.toArray)
row
})
val cnt = tmpRDD.count()
})
tmpRDD = tmpRDD.sortBy(row => row.cells.apply(0).value.get.toString).groupBy(row => "totalsum").map(kv => {
val row = kv._2.head.copy()
colMTC.foreach(col => {
val cnt = kv._2.map(_.cells.apply(col.index).value.get.asInstanceOf[Long]).sum
row.cells.update(col.index, ReportCell(pos, Some(cnt)))
})
row.rowKey = "totalsum"
row.children = Some(kv._2.toArray)
row
})
result = Some(reportBase.copy(rows = tmpRDD.collect()))
status = "executed"
} catch {
case ex: Exception => {
var msg = ex.getMessage
msg = msg.substring(0, msg.indexOf("\n\t"))
status = "error:" + msg
}
}
}
}WebApp:元数据配置管理、数据可视化(报表),目前版本使用的是AngularJs,后面会切换到客户端的封装的框架(底层基于React)
UI组件:https://ant.design/
Chart组件:https://g2.alipay.com/
日志:ELK Stack
表达式解析器:ExpressionParser,参考资料:仿查询分析器的C#计算器 面向 Java 开发人员的 Scala 指南: 构建计算器















 988
988

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









