









一、牛顿法
在博文“优化算法——牛顿法(Newton Method)”中介绍了牛顿法的思路,牛顿法具有二阶收敛性,相比较最速下降法,收敛的速度更快。在牛顿法中使用到了函数的二阶导数的信息,对于函数") ,其中
,其中 表示向量。在牛顿法的求解过程中,首先是将函数在
表示向量。在牛顿法的求解过程中,首先是将函数在 处展开,展开式为:
处展开,展开式为:
其中,") ,表示的是目标函数在的梯度,是一个向量。
,表示的是目标函数在的梯度,是一个向量。") ,表示的是目标函数在处的
Hesse
矩阵。省略掉最后面的高阶无穷小项,即为:
,表示的是目标函数在处的
Hesse
矩阵。省略掉最后面的高阶无穷小项,即为:
上式两边对求导,即为:
在基本牛顿法中,取得最值的点处的导数值为 ,即上式左侧为。则:
,即上式左侧为。则:
求出其中的:
从上式中发现,在牛顿法中要求
Hesse
矩阵是可逆的。
当 时,上式为:
时,上式为:
此时,是否可以通过 ,
, ,
,") 和
和") 模拟出
Hesse
矩阵的构造过程?此方法便称为拟牛顿法
(QuasiNewton),上式称为拟牛顿方程。在拟牛顿法中,主要包括DFP拟牛顿法,BFGS拟牛顿法。
模拟出
Hesse
矩阵的构造过程?此方法便称为拟牛顿法
(QuasiNewton),上式称为拟牛顿方程。在拟牛顿法中,主要包括DFP拟牛顿法,BFGS拟牛顿法。
二、DFP拟牛顿法
1、DFP拟牛顿法简介
DFP拟牛顿法也称为DFP校正方法,DFP校正方法是第一个拟牛顿法,是有Davidon最早提出,后经Fletcher和Powell解释和改进,在命名时以三个人名字的首字母命名。
对于拟牛顿方程:
化简可得:
令 ,可以得到:
,可以得到:
在DFP校正方法中,假设:
2、DFP校正方法的推导
令: ,其中
,其中 均为
均为 的向量。
的向量。-\bigtriangledown f\left ( x_k \right )") ,
, 。
。
则对于拟牛顿方程-\bigtriangledown f\left ( x_k \right ) \right ]=x_{k+1}-x_k") 可以简化为:
可以简化为:
将 代入上式:
代入上式:
将代入上式:
已知: 为实数,
为实数, 为的向量。上式中,参数
为的向量。上式中,参数 和
和 解的可能性有很多,我们取特殊的情况,假设
解的可能性有很多,我们取特殊的情况,假设 ,
, 。则:
。则:
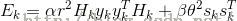
代入上式:
令 +1=0") ,
, -1=0") ,则:
,则:
则最终的
DFP
校正公式为:
3、DFP拟牛顿法的算法流程
设 对称正定,
对称正定, 由上述的
DFP
校正公式确定,那么对称正定的充要条件是
由上述的
DFP
校正公式确定,那么对称正定的充要条件是 。
。
在博文“优化算法——牛顿法(Newton Method)”中介绍了非精确的线搜索准则:Armijo搜索准则,搜索准则的目的是为了帮助我们确定学习率,还有其他的一些准则,如Wolfe准则以及精确线搜索等。在利用Armijo搜索准则时并不是都满足上述的充要条件,此时可以对DFP校正公式做些许改变:
DFP
拟牛顿法的算法流程如下:

4、求解具体的优化问题
求解无约束优化问题
=100\left ( x_1^2-x_2 \right )^2+\left ( x_1-1 \right )^2")
python
程序实现:
# -*- coding: utf-8 -*-
# 基于DFP的拟牛顿法
import numpy as np
from numpy import linalg
import matplotlib.pyplot as plt
def compute_original_fun(x):
""" 1. 计算原函数的值
input: x, 一个向量
output: value, 一个值
"""
value = x[0]**2 + 2*x[1]**2
return value
def compute_gradient(x):
""" 2. 计算梯度
input: x, 一个向量
output: value, 一个向量
"""
value = np.mat([[0],[0]], np.double)
value[0] = 2*x[0]
value[1] = 4*x[1]
return value
def draw_result(result):
""" 3. 将收敛过程(即最小值的变化情况)画图 """
plt.figure("min value")
plt.plot(range(len(result)), result, "y", label="min value")
plt.title("min value's change")
plt.legend()
return plt
def main(x0, H, epsilon = 1e-6, max_iter = 1000):
"""
x0: 初始迭代点
H: 校正的对角正定矩阵
eplison: 最小值上限
max_iter: 最大迭代次数
result: 最小值
alpha**m: 步长
d: 方向
"""
result = [compute_original_fun(x0)[0,0]]
for k in range(max_iter):
# 计算梯度
g = compute_gradient(x0)
# 终止条件
if linalg.norm(g) < epsilon:
break
# 计算搜索方向
d = -H*g
# 简单线搜索求步长
alpha = 1/2
for m in range(max_iter):
if compute_original_fun(x0 + alpha**m*d) <= (compute_original_fun(x0) + (1/2)*alpha**m*g.T*d):
break
x = x0 + alpha**m*d
# DFP校正迭代矩阵
s = x - x0
y = compute_gradient(x) - g
if s.T * y > 0:
H = H - (H*y*y.T*H)/(y.T*H*y) + (s*s.T)/(s.T*y)
x0 = x
result.append(compute_original_fun(x0)[0,0])
return result
if __name__ == "__main__":
x0 = np.asmatrix(np.ones((2,1)))
H = np.asmatrix(np.eye(x0.size))
result = main(x0, H)
draw_result(result).show()














 3861
3861











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









