









支持向量机(Support vector machines, SVM)
支持向量机提出了一种聪明的优化目标(pose a cleverly-chosen optimization objective),它是目前最流行应用最广的学习算法之一。这里有 July 写的
支持向量机通俗导论(理解SVM的三层境界)供大家阅读。
大间距分类器
优化目标
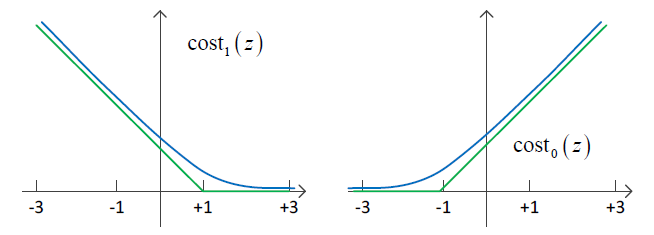
代价函数:
J(θ)=−yloghθ(x)+(1−y)log(1−hθ(x))hθ(x)=11+e−θTxcost1(z)=−loghθ(x),cost0(z)=−log(1−hθ(x))
目标方程:
minθJ=1m[∑i=0my(i)cost1(θTx(i))+(1−y(i))cost0(θTx(i))]+λ2m∑j=1nθ2j −→−−−−−−−J=J⋅mλ,c=1λJ=c[∑i=0my(i)cost1(θTx(i))+(1−y(i))cost0(θTx(i))]+12∑j=1nθ2j
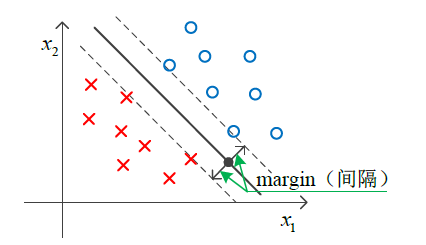
大间距指导
SVM又被称为大间距分类器。
1 支持向量机
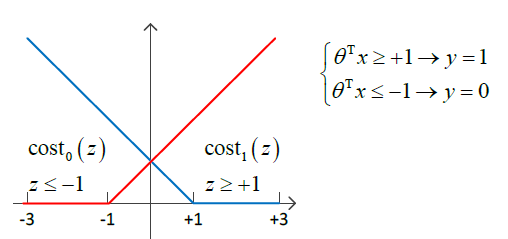
2 SVM决策边界
当常数 c 很大时,目标函数近似为
求得该优化目标,得到的结果就是最大间隔。
3 针对异常值
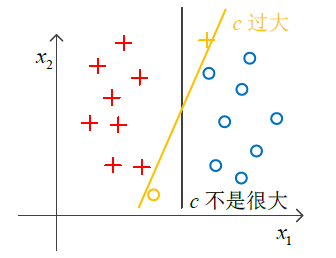
通过调整 c 的大小,减少异常值对分类器的影响。
大间距分类器下的数学
本模块描述了 SVM 的数学原理,主要包含向量间距的内积表述。
1 向量内积
其中,
2 SVM 决策边界
当 n=2 时,其表达式与几何图形如下所示,
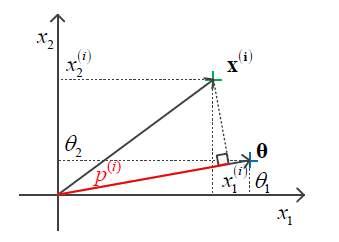
其中,
由此,我们可以把目标方程转换成新的形式,即
接下来,我们通过 n=2 的几何图像表述的方法来描述这个方程与间距量的关系,
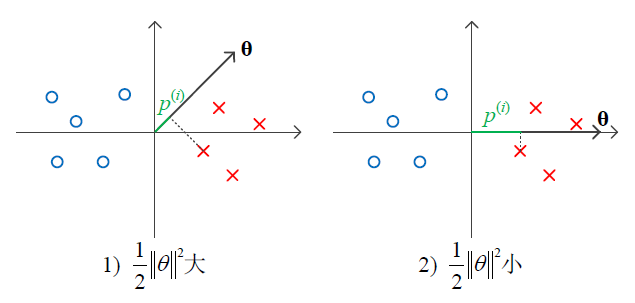
我们假定
p(i)∥θ∥⩾+1
,则当
1)
p(i)
较大时,
∥θ∥
较小,即目标值
12∥θ∥2
较小;
2)
p(i)
较小时,
∥θ∥
较大,即目标值
12∥θ∥2
较大。
因此,我们可以发现,2) 的情况相比于 1) 更优,即目标值更小,代表的意义是间距更大。
核函数
核函数 1
在 SVM 中采用“核函数”,使其被构造成为一种复杂的非线性分类器,相对应的,得到非线性决策边界。
1 非线性决策边界
类似逻辑回归中的决策边界 hθ(x) ,对于非线性的的 hθ(x) ,例如
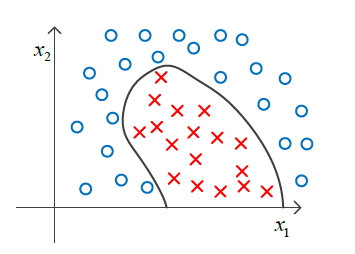
2 核函数
核函数的实质,是一种定义特征的方法,原有特征记作 x,新特征记作 f。根据原有特征计算得到新的特征。
其中一种定义(或称之为“计算”)的方法是相似度映射,记作
其中 l(i) 是特征标记(或称为基),一般可以取 l(i)=x(i) 。
新特征 f 的计算形式为
其中,similarity 可以被称作是一种核函数,上式的核函数是高斯核函数(Gaussian kernel),核函数记作 K(x,l(i)) 。
3 高斯核函数
高斯核函数类似高斯密度函数,呈钟形。
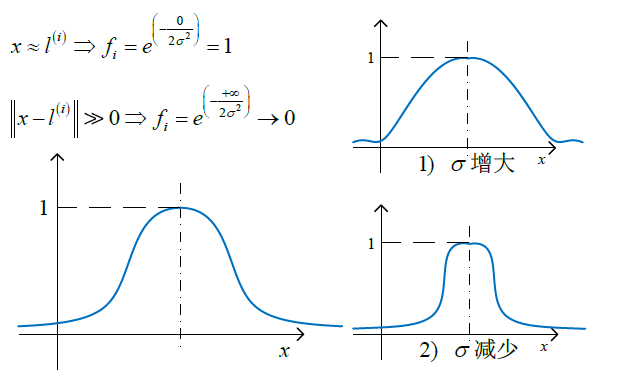
最终,我们通过核函数
K(x,l(i))
得到关于
x
的新特征集合
核函数 2
在该模块中, SVM 中应用核函数,讨论权衡偏差、方差的问题。
1 选择标记点
在 SVM 的基中, l(i)=x(i) ,使得新特征 fi 表示为 x(i) 与其他数据的离散程度,即每一个样本与其他样本的距离。
2 带核函数的 SVM
- 给定样本: (x(1),y(1)),⋯,(x(m),y(m))
- 选择标记点: l(1)=x(1),⋯,l(m)=x(m)
- 特征映射: f(i)j=K(x(i),l(j)),f(i)0=1 f(i)=[f(i)0f(i)1f(i)2⋯f(i)m]T
- 特征向量: x(i)∈Rn+1→f(i)∈Rm+1
- 参数 θ : θ∈Rm+1
最终,我们得到了关于新特征 f(i) 与参数 θ 的目标方程:
值得注意的事,当
m
很大时,
3 SVM 参数
该模块讨论支持向量机的参数对算法的偏差、方差的关系。
-
c (1/λ)
-
c
过大,可能引起低偏差、高方差,同样地,增大
c 可以降低偏差; c 过小,可能引起高偏差、低方差,同样地,减少c 可以降低方差。
σ2
高斯核
- σ2 过大,高斯核函数会变得平滑,可能引起高偏差、低方差; σ2 过小,高斯核函数会变得陡峭,可能引起低偏差、高方差,适用于偏差、方差调整。(在“高斯核函数”小节中有函数示意图)
SVM 实践
使用 SVM
熟悉使用 SVM 软件包
liblinear/libsvm去求解参数 θ ,是非常有利于工作的,liblinear 可以从这里下载到,libsvm 可以从这里下载到。
当然,我们必需学习一些如何使用软件包的知识:
- 选择参数 c
- 选择核函数(可称作相似度函数),核函数包括无核(线性核,Linear Kernel,
θTx )、高斯核(标记点的选择,参数 σ2 )等的函数。无核函数适用于 n 很大,m 很小的情况;高斯核函数,适用于 n 很小,m 很大的情况。
1 核(相似度)函数
function f = kernel(x1, x2)
f = exp(-||x1 - x2||/(2 ))
return注意:在使用高斯核前,有必要对特征进行归一化,防止大数特征“吃了”小数特征。
2 其它的核函数
任何一个相似度函数作为一个有效的核函数,必须满足默塞尔定理(Mercer’s Theorem)。这是为了保证 SVM 的软件包能够利用内部的数值计算的优化方法进行有效的求解。
适用的核函数包含:
- 多项式核函数 Polynomial kernel: K(x,l)=(xTl+c)d
- 字符串核函数 String kernel:文本分类,两字符串的相似度
- 卡方核函数 Chi-square
- 直方图交叉核函数 Histogram intersection kernel
3 多类别分类器
y∈{1,2,3,⋯,k}
SVM 软件包内置多类别的分类器。另外,一对多分类方法(One-vs.-all Method)进行多类别分类,需要训练 0−1k 次。
4 逻辑回归 vs. SVMs + 神经网络
n
为特征数(
n 很大,近似等于 m- 使用逻辑回归或者无核的 SVM(“Linear kernel”)。
n 很小, m 数量中等- 使用高斯核的 SVM,或者可以尝试神经网络。
n 很小, m <script type="math/tex" id="MathJax-Element-2246">m</script> 很大- 定值/增加更多多特征数,然后采用逻辑回归或者无核的 SVM。
注意:SVM 中的优化问题是凸优化,采用优化方法可获得全局最优;神经网络中的优化也许是能求得局部最优,虽然不差,对结果影响不大,但它仍是局部最优。
神经网络的运行效率可能没有 SVM 高。
我的 QQ 1026163725 欢迎大家一起和我交流关于机器学习的问题。















 389
389

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









