






Java的基本语法
标识符
标识符就是打上标记帮助识别的符号,给 Java 中的类、方法、变量和常量等的名称
标识符的命名规则(明规则):
- 标识符的组成:数字、字母、下划线(_)、美元符号($)
- 不能以数字开头
- 严格区分大小写
标识符的命名规范(潜规则):
- 见名知意,注意不能出现汉语拼音的简写、尽量用单词命名
- 类名:首字母大写,如果类名由多个单词组成,后续单词的首字母大写(大驼峰命名法)
- 方法名/变量名:首字母小写,如果方法名/变量名由多个单词组成,后续单词的首字母大写(小驼峰命名法)
- 常量名:所有字母全部大写,如果常量名称由多个单词组成,单词与单词之间用下划线(_)分隔(蛇形命名法)
标识符的分类:
- 语言预定义标识符---关键字(50个左右)
- 用户自定义表示符:
- 先人自定义标识符
- 开发者自定义标识符
类的基本结构
类的基本结构(类的定义)public class 类名{}
一个 Java 文件中只能有一个类,所有的内容必须写在大括号里面
注意:1、public 修饰的类名必须和文件名相同
2、修改文件名 鼠标右键选择 refactor 进行重构文件名
main方法/主方法 程序的入口
//public 修饰的类 类名需要和文件名一致
public class 类名{
public static void main(String[] args){
//数据可以是中文、英文、十进制数字
System.out.println("数据")
}
}注释
作用:描述代码的功能,起提示作用。当 Java 编译器编译文件时,会忽略注释
//单行注释 快捷键 ctrl+/
/*
多行注释
*/
/**
文档注释(一般情况下用在:类、变量、方法和常量上)
Javadoc 命令生成 API 文档
*/
计算机的存储单位
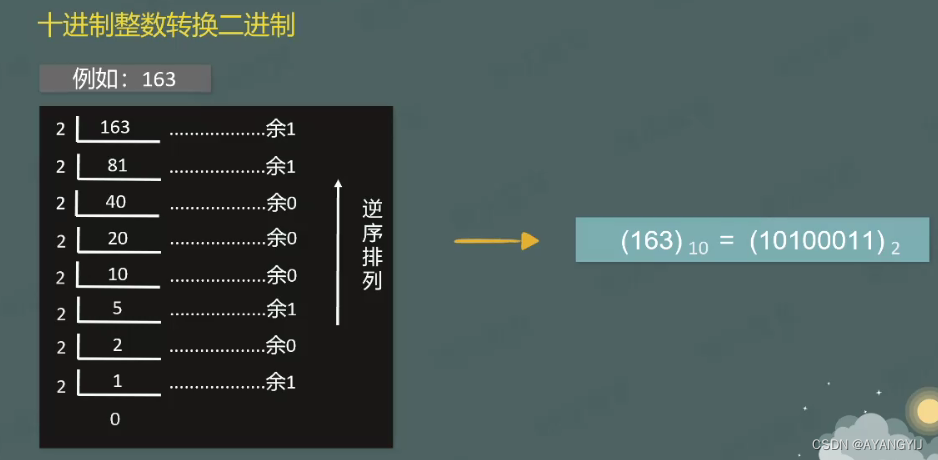
十进制转二进制
将十进制整数 除以 2 得到一个商和余数,然后再将商除以2循环往复执行,在这个过程,会得到一系列余数,然后把余数倒序排列就能得到该十进制数对应的二进制数。
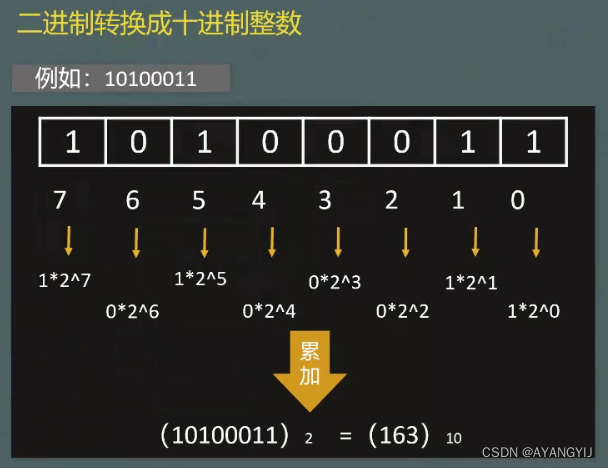
二进制转十进制
数据类型
作用:1、告知计算机,用什么方式存储数据
2、告知计算机,划分多大的空间存储数据
分类:
1、基本数据类型(4类8种)
2、引用数据类型(除了基本数据类型外的都是引用数据类型 String-字符串)
基本数据类型:(4类8种)
1、整型
| 类型名称 | 所占空间 | 范围 |
|---|---|---|
| byte | 1 个字节 | -128~127 |
| short | 2 个字节 | |
| int(整型) | 4 个字节 | |
| long(长整型) | 8 个字节 |
2、浮点型
| 类型名称 | 所占空间 | 范围 |
|---|---|---|
| float(单精度浮点数)(可以保证7位有效数字) | 4 个字节 | |
| double(双精度浮点数)(可以保证16位有效数字) | 8 个字节 |
3、字符型(char)
存储字符,所占空间是 【2 个字符】,字符在计算机中的存储也是采用的二进制的形式进行存放,为更好的存储字符,为全世界的符号都统一进行了编码(unicode 码),
最终以数字编码来表示字符,或 'a' 表示字符,且字符型只能表示单个字符
4、布尔型(boolean)
无固定字节,由 JVM - Java 虚拟机决定,用于表示逻辑状态:只有两个取值:true --> 真 false --> 假
引用数据类型:
字符数(String)、数组
变量(可以被修改)
有了数据类型,我们就可以使用声明指令在内存中划分空间、存放对应的数据,未使用的变量 是灰色状态
变量的声明 语法:
数据类型 变量名 = 变量值;
注意:先声明再使用:
1、先声明再使用,声明时养成初始化的习惯;(声明的同时就赋值。数据类型 变量名 = 变量值; 例:int number = 100;)
2、变量名是标识符,首字母小写,如果由多个单词组成,后面单词的首字母大写(小驼峰命名)
3、变量生命周期 始于声明,终于包含它离它最近的结束花括号;
常量(不可被修改)
分类:字面常量和符号常量
字面常量:读过去是什么就是什么,\n表示换行
符号常量:符号常量其本质就是给字面常量起一个名字
语法:final 数据类型 常量名 = 字面常量值;
运算符
-
算术运算符(+ - * /(求余%))
-
赋值运算符(= += -= *= /= %= ++(自增) --(自减)
-
比较运算符( > < >=(大于等于) <=(小于等于) ==(等于) !=(不等于))
-
三目运算符 ( ? : )【布尔表达式 ? 数据1 : 数据2】
-
逻辑运算符 (布尔表达式操作)&&(并且) ||(或者) !(非) ^(异或)
-
&&和||(短路)与 & 和 |(非短路)运算符
&&和||(短路):第一个布尔表达式能够表示整体结果时,第二个布尔表达式就不会被执行;
& 和 |(非短路):不管第一个布尔表达式的结果如何,第二个布尔表达式依然会被执行。
数据类型的转换
1、自动类型转换:发生在运算符两端数据类型不一致时
口诀:小(字节)转大(字节),低(精度)转高(精度)
两个整数做运算,结果默认是 int 类型的数据
在转换时,1、整型与整型之间转换考虑字节大小,整型与浮点型转换考虑精度
2、boolean 不参与数据类型转换
2、强制类型转换:发生在对数据运算的结果有要求时,利用强制类型转换可能会发生精度丢失的情况
语法:(目标数据类型)数据;
口诀:大(字节)转小(字节),高(精度)转低(精度)
语句
1、输入语句:
1、声明一个输入器:scanner 意为扫描,扫描控制台里面所输入的内容 --- Scanner 输入器名称自定义 = new Scanner(System.in);
2、声明整型变量接收输入器的信息 --- 数据类型 类型名称 = 输入器的类名.next数据类型();
3、关闭输入器 --- 输入器变量名.close();
Scanner (scanner=类名,自定义) = new Scanner(System.in);//声明一个输入器
int scanInt(类名2) = scanner(=类名).nextInt();//声明整型变量接收输入器的信息
System.out.println("接收到输入器的数据:"+ scanInt(=类名2));
scanner.close();//关闭输入器2、输出语句
System.out.println()//系统的输出打印换行语句
System.out.print()//系统的输出打印不换行语句3、字符串(引用数据类型)相当于多个字符进行串联,使用双引号进行包裹,字符串的拼接用“+”做连接
字符串在前,先做字符串的拼接; 字符串在后,先做数值运算,再把运算结果与字符串做拼接
System.out.println("数据")//引号包裹的数据是字符串
int a = 1;
int b = 2;
System.out.println(a+""+b);4、转译字符:\ 字符,可以把原本具有特殊含义的字符,转为普通字符
算法
算法的含义:解决问题的方法或步骤
算法的特征:
- 有穷性:一个算法必须在执行有限操作步骤后终止
- 确定性:算法中的每一步的含义必须是确切的,不可出现任何二义选
- 有效性:算法中的每一步操作都应该能有效执行,一个不可执行的操作是无效的
- 有零个或多个输入:这里的输入是指在算法开始之前所需要的初始数据,这些输入的多少取决于特定的 问题
- 有一个或多个输出:所谓输出是指得到算法执行的结果,在一个完整的算法中至少会有一个输出。如果 没有结果输出,那么它将变得毫无意义
流程控制语句分支语句
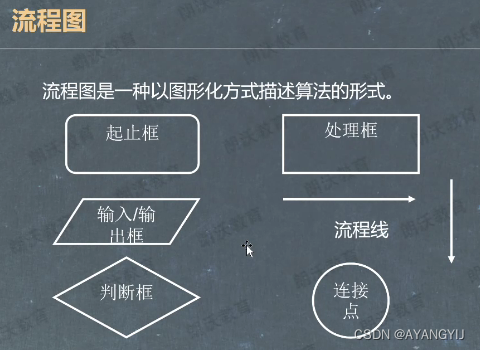
流程图
if 语句
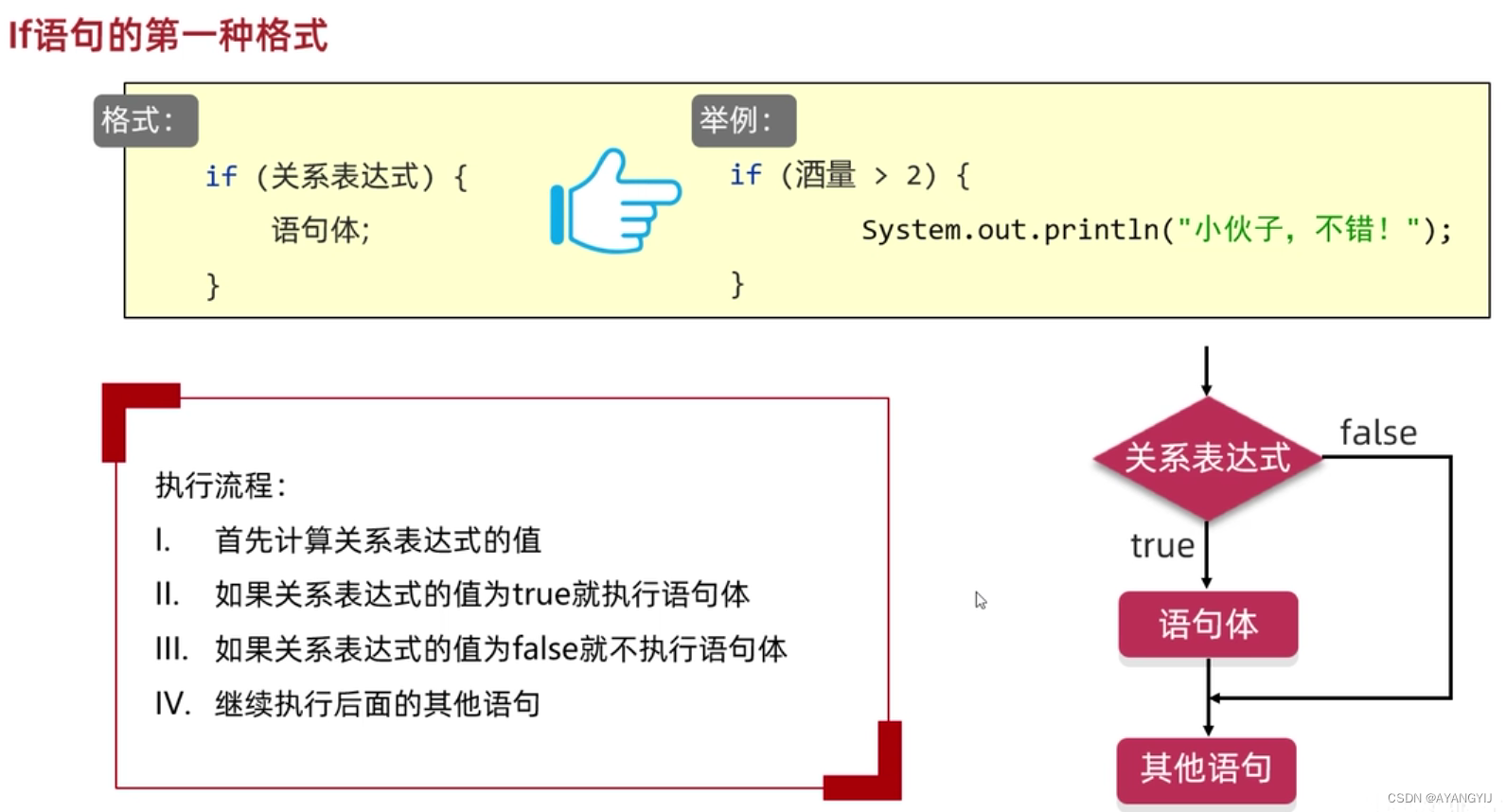
单分支 if 语句(一种情况的判断)
执行顺序:先做条件表达式的判断: 判断结果为真,进入 if 语句执行代码块,判断结果为假,跳过 if 语句代码块,执行后续代码
if (条件表达式){
//if 输出语句块
}
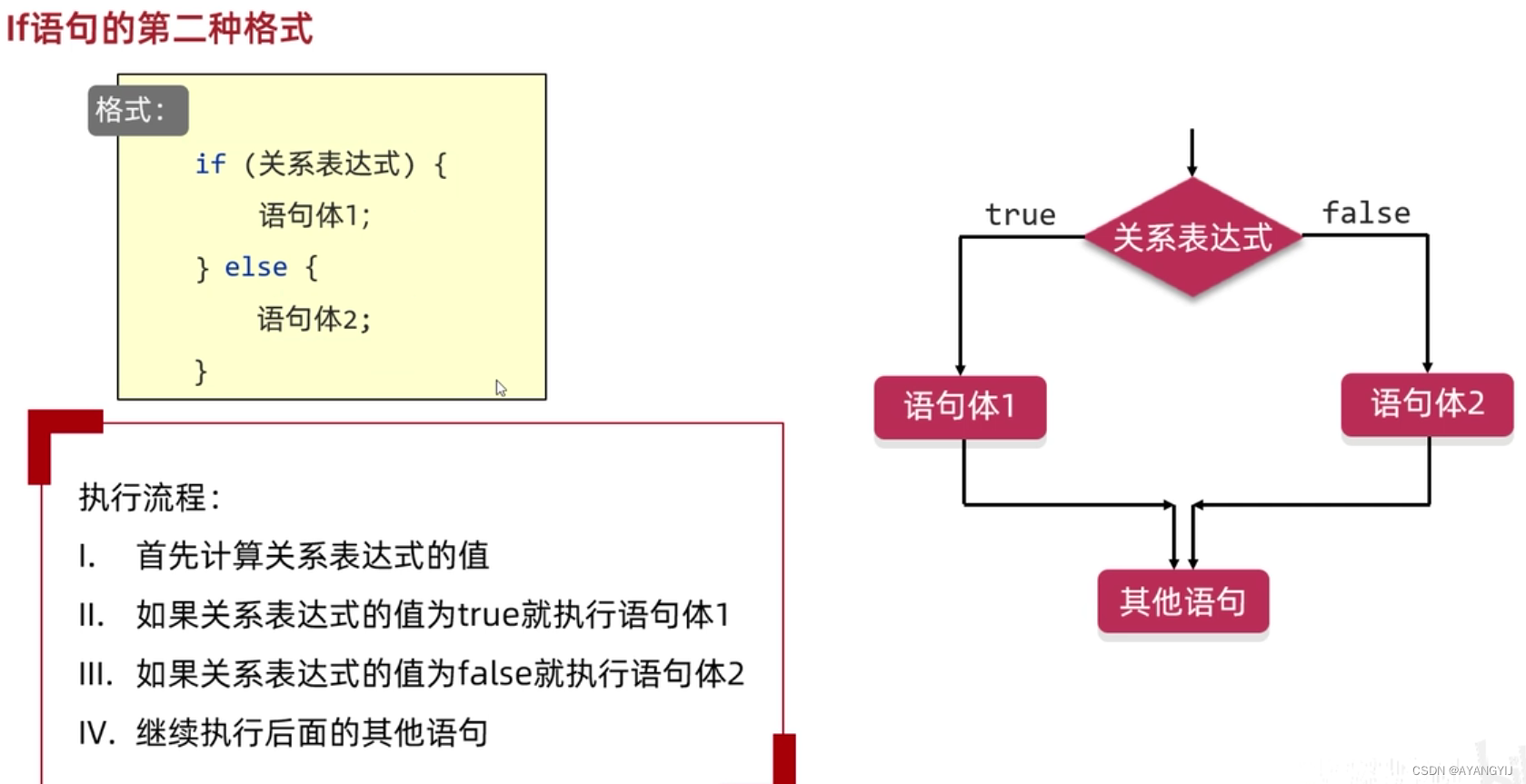
双分支 if 语句(两种情况的判断)二选一执行
执行顺序:先做条件表达式的判断:判断的结果为真,就会执行语句块 1 ;如果判断结果为假,就会执行else里面语句块 2 的内容。
if(布尔条件表达式){
//输出语句块1
}else{
//输出语句块2
}
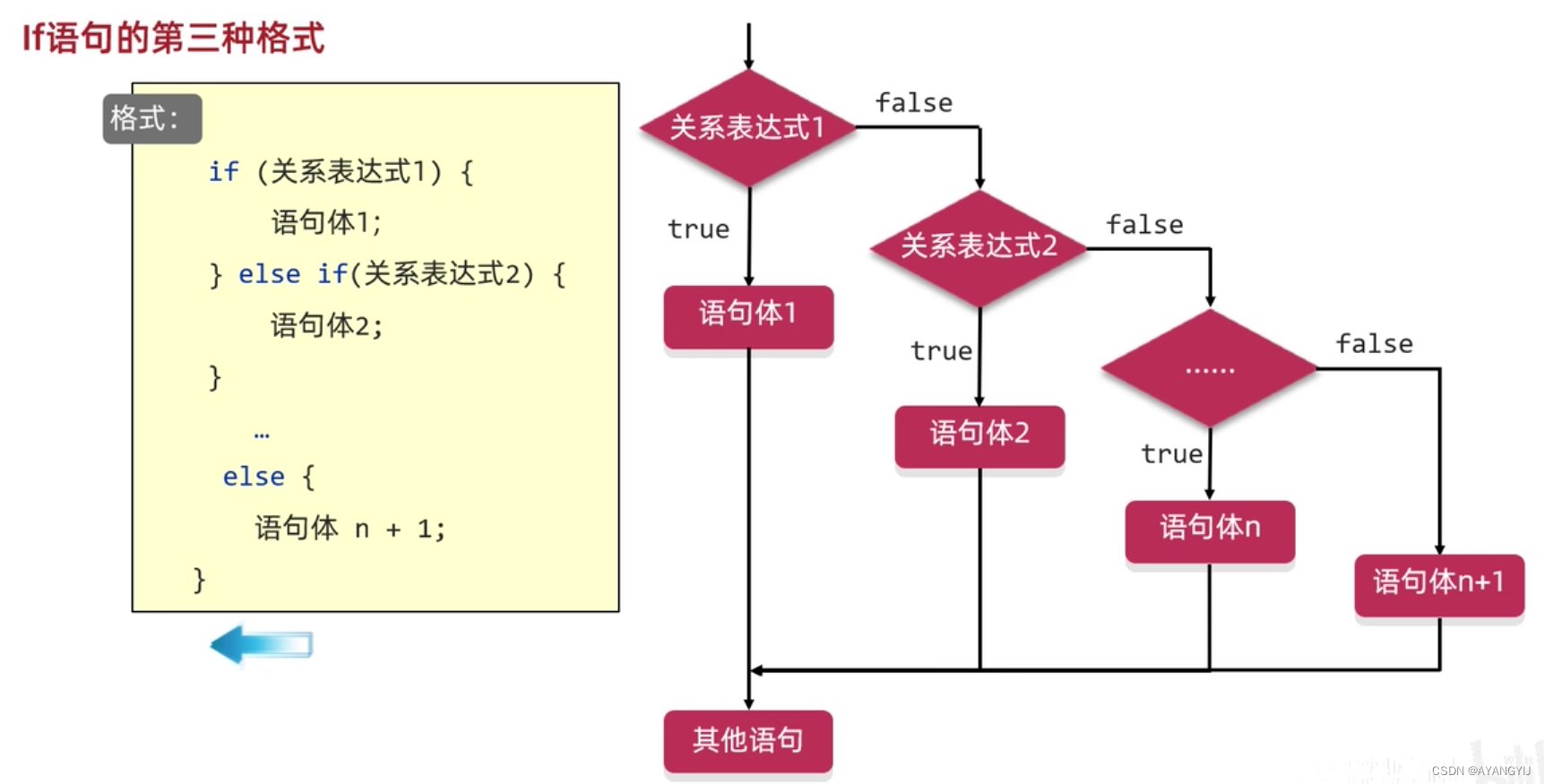
多分支 if 语句(多种情况的判断)多选一
执行顺序:依照条件表达式出现的顺序进行判断,从上到下某一处条件表达式结果为真,则执行对应语句块里 的代码,如果全面结果为假,则执行else 里面的语句块
if(布尔条件表达式1){
//输出语句块1
}else if(布尔条件表达式2){
//输出语句块2
}else if(布尔条件表达式3){
//输出语句块3
}
...
//如果所有条件表达式都为假,就会输出最后一个 else(条件表达式)的内容
else(条件表达式n){
//语句块n
}
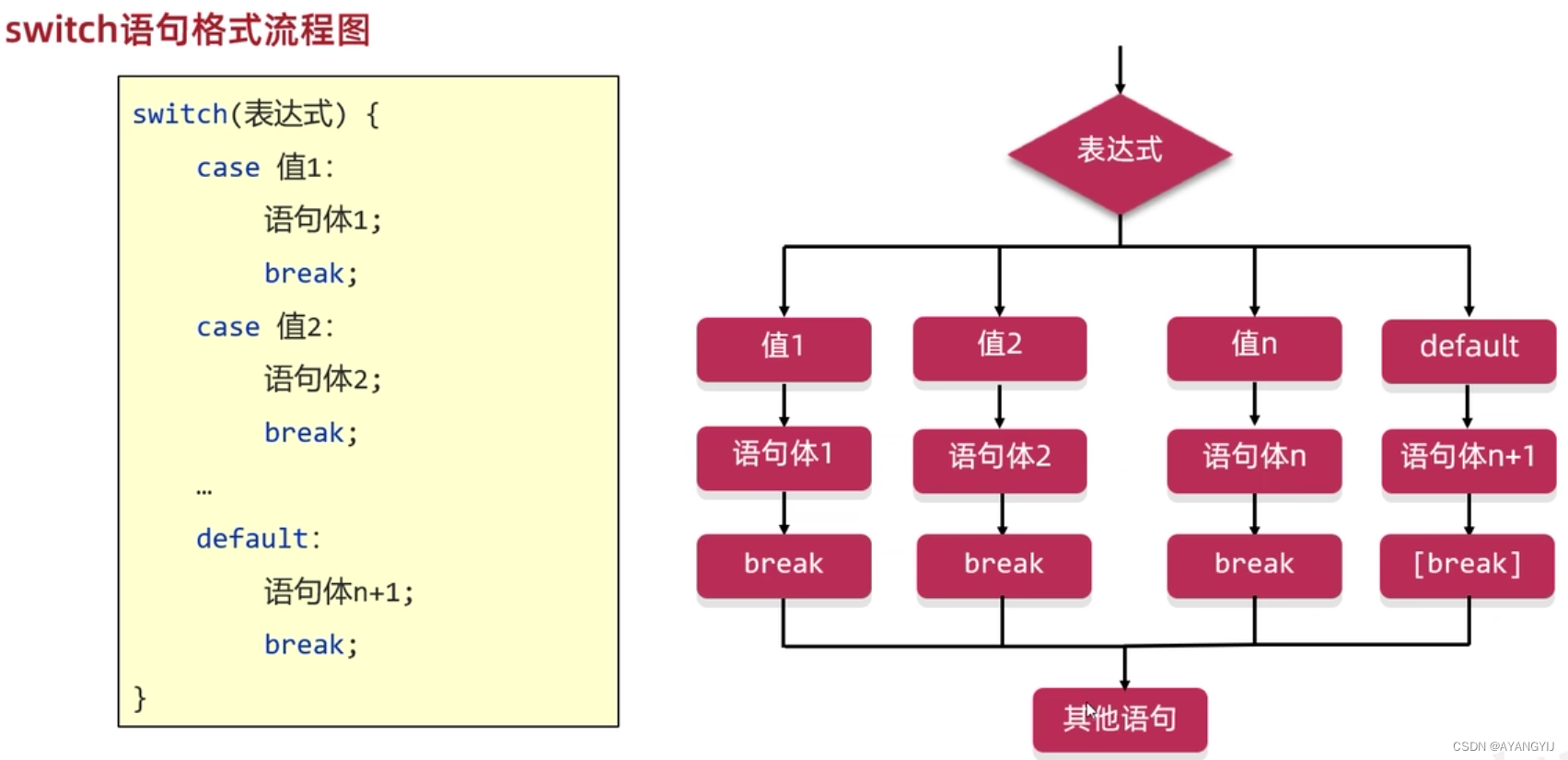
switch-case 语句(多种条件中选择一个)
执行顺序:
计算表达式的结果,把结果和case 后的数据做对比:比较成功,就会执行该 case 后方的语句块内容;如果全部都比较不成功,执行 default 后方的代码块,为了让代码执行case后面的代码,每一个语句块后面都必须加上 break;
注意:Switch 后面括号的内容只能放 byte、short、int、char、字符串String 数据类型的值
switch(表达式){
case 数据1:输出语句块1;//case后面跟的是要和表达式进行比较的值(被匹配的值),只能字面量,no变量
break;//表示结束switch语句
case 数据2:输出语句块2;
break;
case 数据3:输出语句块3;
break;
case 数据4:输出语句块4;
break;
default:输出语句块5//default表示所有情况都不匹配的时候就执行该处的内容,和if语句的else相似
break;
}
if 语句和 switch-case 区别
1.if语句在比较时,可以比较值和范围。
switch语句只能比较值
2.if语句在比较时,只能接受布尔值。
switch表达式语句可以接受byte、short、int、char、String的值
循环语句
含义:重复执行某些含有规律的指令语句的过程
组成:循环是由 反复被执行的循环体语句 和 循环终止的条件 共同组成的
for 循环
适用于明显知道循环的次数和循环的范围
执行顺序:
1、执行初始化语句1(通常是用于计数变量的声明,计数变量是用于计算循环次数的变量)
2、条件判断语句2(循环终止的条件)的判断,如果判断结果为真,循环继续
3、执行循环体语句
4、执行玩循环体语句后,执行表达式3(用于改变计数变量的值)
5、回到第二部2、-->3、-->4、-->2、-->3、-->4、-->2、直到步骤2判断结果为假时,终止循环
注意:在书写循环时,注意计数变量值的改变和循环的终止条件
在一般情况下,i 会默认给 0 ,i 做的自增(偶尔会是自减)
//格式:一般情况下必须给三个表达式;有些特殊情形下,可以省略其中的表达式
for(初始化语句1;条件判断语句2;条件控制语句3){
//循环体语句 反复被执行的语句
}
//表达式1:初始化语句,用于计数变量的声明 ,变量名可以不是i,但是在循环中一般都用i
//表达式2:条件判断语句,用于书写循环终止的条件(布尔表达式)
//表达式3:条件控制语句,用于改变计数变量的值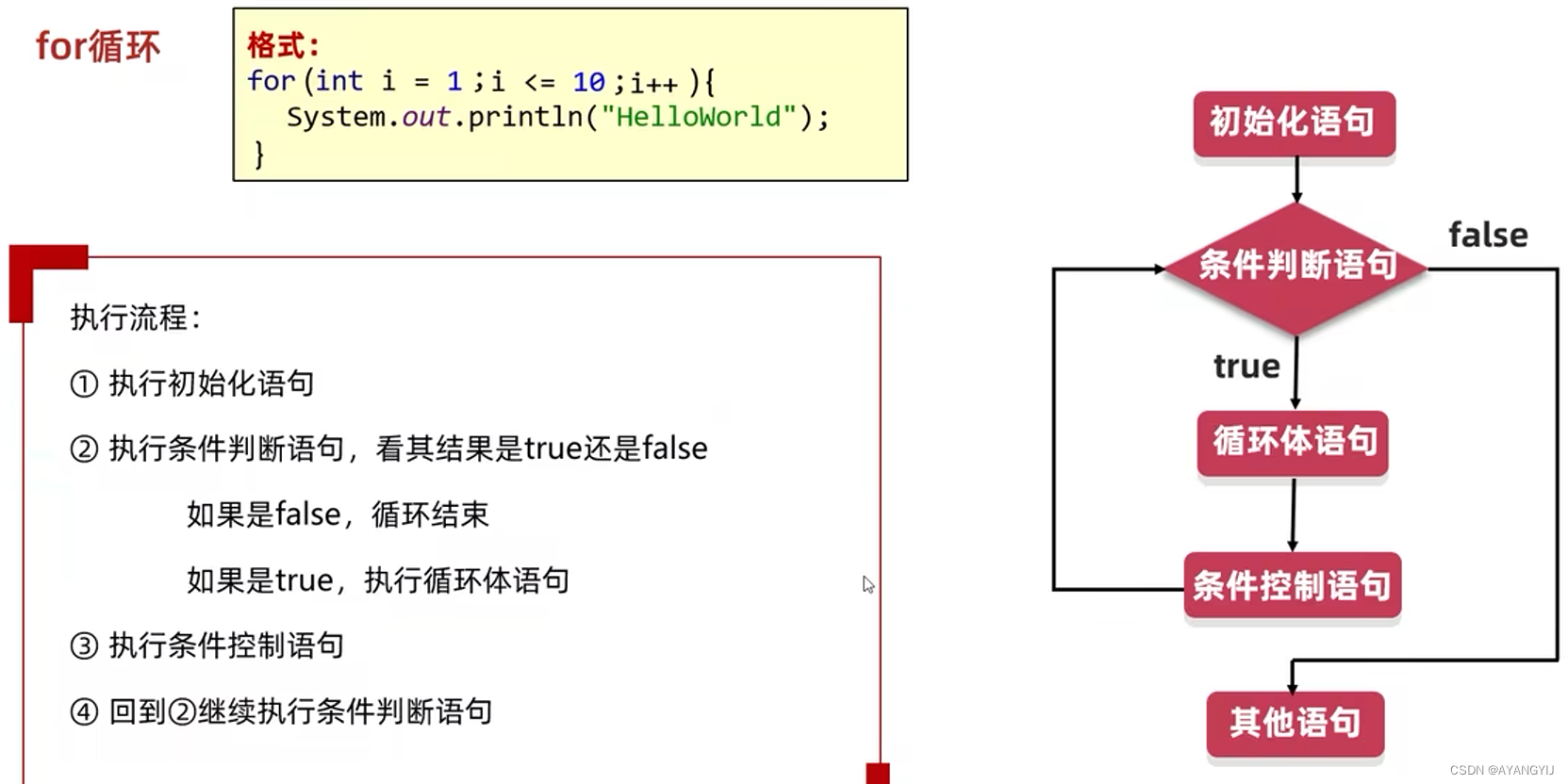
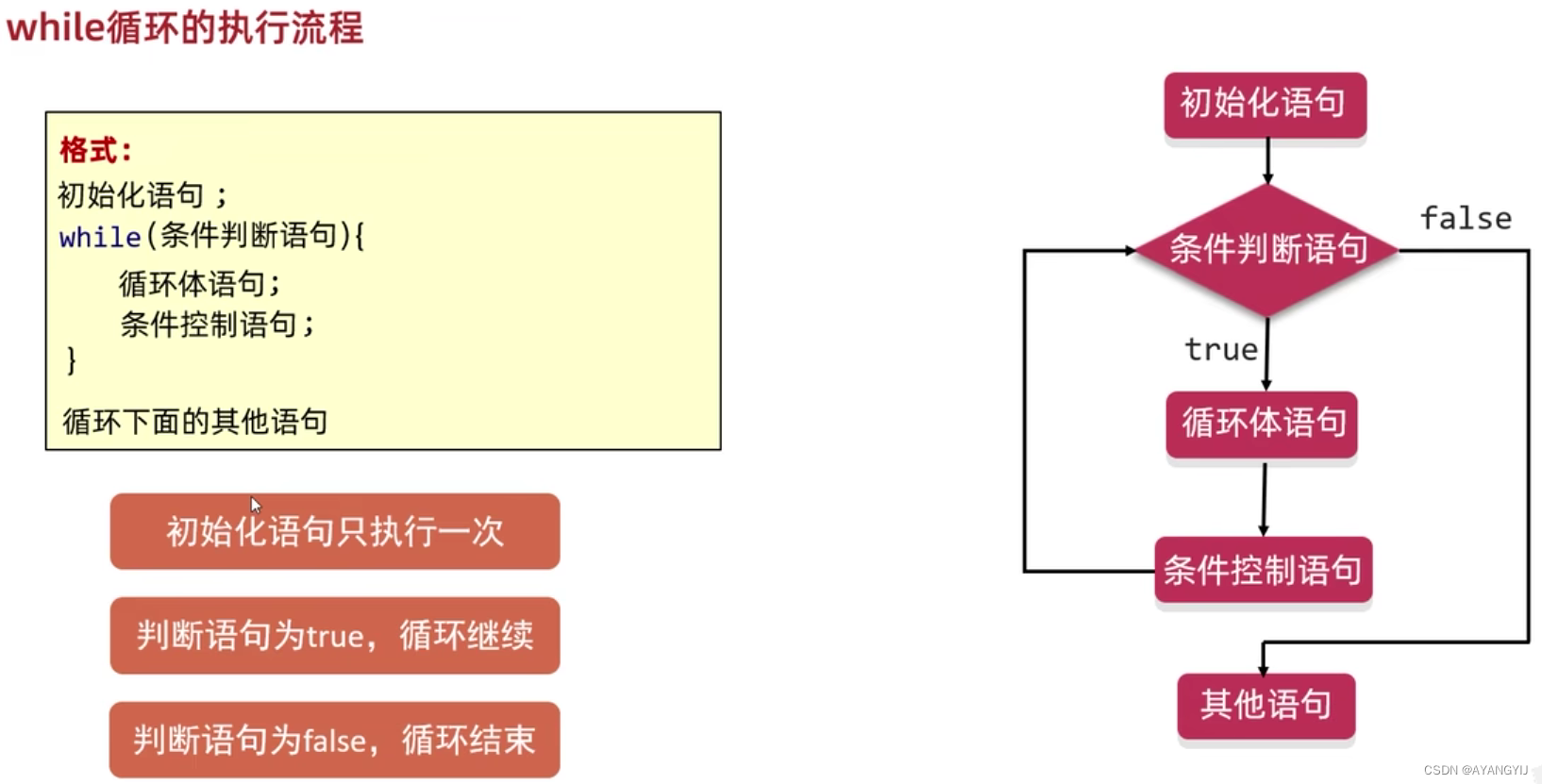
while 循环
适用于不知道循环的具体次数和不知道循环的范围,只知道达到某个条件的时候循环结束
执行顺序:首先做条件表达式的判断,判断结果为真,执行循环体语句内容,执行完成后,再做条件表达式的判断,如果判断结果为真,继续,为假则循环终止
注意:和 for 循环不同的是,while 循环没有专门的位置用于计数变量的声明和计数变量值改变的指令
while(条件(布尔)表达式){
//循环体语句
}
do-while 循环
适用于不知道循环的具体次数但至少要执行一次,只知道达到某个条件循环结束
执行顺序:先执行循环语句块内容,然后做条件表达式的判断,判断结果为真,再执行循环语句块内容;判断结果为假,循序终止
do{
//循环语句块 重复被执行的代码
}while(条件表达式);
循环的分类
1、先验循环:首先执行条件表达式的判断,后执行循环语句块的循环: for和while
2、后验循环:先执行循环语句块,后执行条件表达式判断的循环: do-while
循环中断 break和continue
break;
在循环中,出现 break; 语句,直接终止当前的循环(包含它,离它最近的循环)
只能用在循环或者 switch- case 语句中
continue;
在循环中,跳过本次循环( continue 后的内容),直接到循环终止条件的判断
循环嵌套
循环嵌套:在循环的内部,再写一个循环
执行顺序:外层循环执行一次,内层循环执行一圈,相当于内部执行完成再执行外层循环
外层循环{
内层循环{
//内层循环 相当于外层循环的循环体语句,相当于内部执行完成再执行外层循环
}
}数组
1、数组的概念
集合:将一组数据集中放置在一起,可以对数据进行批量操作
数组:是集合中的一种,且是集合中最原始简单的一种。
数据类型的分类:基本数据类型(4类8种)和引用数据类型(除了基本数据类型外的)
数组:是引用数据类型
2、数组的语法
数组的声明语法:注意:声明数组时,出现的数据类型时指指数组内存放的数据的类型
语法1:
数据类型[] 数组名称(数组名) = {数据1,数据2,数据3,……,数据n};
//数据类型[] 数组名称(数组名) = {数据1,数据2,数据3,……,数据n};
//声明一个存放整型数据的数组 数据有 10、20、30、40、80、100
int[] array = {10,20,30,40,80,100};语法2:
数据类型[] 数组名称 = new 数据类型[数组长度];
//数据类型[] 数组名称 = new 数据类型[数组长度];
//声明一个存放双精度浮点数的数组 数组存放数据个数为 8
double[] array = new double[8];3、数组的操作
3-1、访问数组元素的语法:
数组名[下标]
下标从 0 开始,最大的下标为 数组长度 - 1 (数组名.length 表示数组长度)
访问数组时超出最大下标范围时会出现数组下标越界异常,ArrayIndexOutOfBoundsException
示例代码如下:
//访问下面数组的最后一个数据 数组名[下标]
// 0 1 2 3 4 5
int[] array = {10,20,30,40,57,82};
System.out.println(array[5]);3-2:修改数组里的数据
格式:数组名[下标] = 具体数据(变量值)
注意:一旦修改之后,原来的数据就不存在了
示例代码如下:
//访问下面数组的最后一个数据 数组名[下标]
// 0 1 2 3 4 5
int[] array = {10,20,30,40,57,82};
System.out.println(array[5]);
//通过赋值语句 可以修改数组下标为5的元素修改为90
array[5] = 90;
System.out.println(array[5]);3-3:查看数组的所有元素信息(遍历数组)
遍历:指的是取出数据的过程
调用方式:数组名.length
遍历数组用 for(){}
注意:i 表示数组里面的每一个下标,ary[i] 表示数组里面的每一个元素
示例代码如下:
int[] ary = {123,12,11,3,41,12,54};
//数组元素访问的语法:数组名[下标] 只能访问 1 个元素
//所以利用循环 遍历数组元素
for (int i = 0;i < ary.length;i++){//在此处,充当数组的下标
System.out.println(ary[i]);
}3-4:反序遍历
示例代码如下:
int[] ary = {10,20,30,40,50};
//利用循环反序遍历
for (int i = ary.length - 1;i >= 0 ;i--){
System.out.println(ary[i]);
}3-5:整型数据的备份
示例代码如下:
1、新建一个整型数组,且数组长度 = 老数组长度
int[] newAry = new int[ary.length];
//2、遍历 老数组
for (int i = 0;i < ary.length;i++){
//3、将老数组的元素 -->赋值给 新数组
newAry[i] = ary[i];
}
//4、利用循环 查询新数组数据
//下标从 0 开始,最大下标为 数据长度 - 1 ,输出语句也可以在第三部直接输出
for (int i = 0;i < newAry.length;i++){
System.out.println(newAry[i]+"");
}……
4、数组的特点
1、只能存放同一数据类型的数据
2、所有的数组数据(元素)存放在连续的内存空间中
3、数组的大小(长度)一旦确定,不能更改
5、基本数据类型数组 和 引用数据类型数组的区分
基本数据类型数组:指数组内放的数据为:基本数据类型
引用数据类型数据:指数组内放的数据为:引用数据类型
6、基本数据类型和引用数据类型的区别
基本数据类型的变量空间中,存放的是值(数据本身)
引用数据类型的变量空间中,存放的是整个数组存放的地址值(引用值),该值指向真正的数据
7、数组的冒泡排序
冒泡排序,其本质是 数组元素两两相互比较
示例代码如下:
//例:有一个乱序数组,要将数组中的元素 按照数据从小到大的进行排序
int[] array = {20,42,3,412,90,7};
/*
比较轮数 = 数组长度 - 1
每次比较次数,随着比较轮数的递增而递减
*/
//5轮大比较,每轮比较次数都递减,54321
for (int i = 0;i < array.length - 1;i++){
//第一轮比较5次,二轮比较4次,三轮比较3次,四轮比较2次,五轮比较1 次
for (int j = 0;j < array.length - 1 - i;j++){
if (array[j] > array[j + 1]){ //交换两数位置
//临时变量
int temp = array[j];
array[j] = array[j + 1];
array[j + 1] = temp;
}
}
}
System.out.println("排序后");
for (int j = 0;j < array.length;j++){
System.out.print(array[j]+" ");
}补充知识
补充知识点1:字符串(本质- 底层代码封装的是一个 字符数组)
字符串 转换为 字符数组 :字符串.toCharArray();
示例代码如下:
String str = "adfbfdg";
char[] chars = str.toCharArray();
System.out.println(chars[3]);
for (int i = 0;i < chars.length;i++){
System.out.println(chars[i] + " ");
}补充知识点2:生成随机码 Math.random();
Math.random(); 可以生成 0-1 之间的浮点数
0.000000000000001-0.9999999999999999
借助它生成 某个整数范围随机数
--生成 0-10 之间的整型随机数: (int)(Math.random() * 11)
--生成 11-20 之间的整型随机数: 11 + 0-9 (int)(Math.random() * 10 +11)
---生成 整型随机数 规律 a-b (int)(Math.random() * (b -a + 1) + a)
--例如:30-48 30 + 0-18 (int)(Math.random() * (19)) + 30
示例代码如下:
// 1.出数字(由电脑产生4个0-9随机数,且不重复) (双色球)
/*
随机数 Math.random() 生成 0-1之间的浮点型随机数
整型随机数a-b--> a + 0~(b-a) (int)(Math.random() * (b - a + 1) + a)
*/
// 生成变量 保存数据
//随机数 0-9 且不能重复(做去重操作)
int[] suiJiShu = new int[4];
//遍历随机数数组
for (int i = 0; i < suiJiShu.length; i++) {
//生成随机数数据
int suiJiShu1 = (int)(Math.random() *( 9 - 0 + 1) + 0);
// 想要把放入数组中,且不与前面的数据重复
suiJiShu[i] = suiJiShu1;
for(int j = 0;j < i;j++){// j表示小于i的数组下标
if(suiJiShu[i] == suiJiShu[j]){
// 循环回滚
i--;
break;
}
}
}补充知识点3:== 和 equals 的区别
== 比较的是变量空间中的值(可以是数据、地址值)
String str1 = "aaa" :数据是放在常量池中,常量池
“”双引号字符串无法使用 == 比较,字符串需要用1.equals(字符串2)方法,才能保证比较的字符串内的字符
equals(一般用于字符串),比较的字符串内的字符是否相同
String str3 = new String("aaa")
例:System.out.println(str1(字符串1).equals(str3)(字符串2));
补充知识点4:结束程序 :System.exit();















 183
183











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









