






import torch
import random
from torch import nn, optim
from torch.nn import functional as F
from torch.utils.data import DataLoader
import torchvision.transforms as transforms
from torchvision.datasets import ImageFolder
import matplotlib.pyplot as plt
from PIL import Image
import os
# 检查是否有可用的CUDA设备
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
print(f"Using device: {device}")
# 数据集根目录路径
dataset_path = r'D:\pytorch_code\LOL峡谷识别'
# 定义图像变换
transform = transforms.Compose([
transforms.Resize((980, 500)), # 调整图像大小
transforms.ToTensor(), # 将图像转换为张量
transforms.Normalize((0.5,), (0.5,)) # 归一化到[-1, 1]
])
# 加载训练集
train_dataset = ImageFolder(root=dataset_path, transform=transform)
# 使用DataLoader创建数据加载器
batch_size = 16 # 定义批量大小
train_loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True)
# 加载测试集
test_dataset = ImageFolder(root=dataset_path, transform=transform)
# 创建测试集 DataLoader
test_loader = DataLoader(test_dataset, batch_size=batch_size, shuffle=False)
# 打印类别名称和数量
print(f"Classes: {train_dataset.classes}")
print(f"Number of training samples: {len(train_dataset)}")
class SimpleCNN(nn.Module):
def __init__(self):
super(SimpleCNN, self).__init__()
self.conv1 = nn.Conv2d(3, 16, 3, 1) # 输入3通道,输出16通道
self.conv2 = nn.Conv2d(16, 32, 3, 1) # 输入16通道,输出32通道
# 使用AdaptiveAvgPool2d来自适应调整特征图的大小
self.pool = nn.AdaptiveAvgPool2d((7, 15))
# 定义全连接层的输入大小
self.fc_input_size = 32 * 7 * 15
self.fc1 = nn.Linear(self.fc_input_size, 128)
self.fc2 = nn.Linear(128, len(train_dataset.classes))
def forward(self, x):
x = F.relu(self.conv1(x))
x = F.max_pool2d(x, 2, 2)
x = F.relu(self.conv2(x))
x = F.max_pool2d(x, 2, 2)
# 使用AdaptiveAvgPool2d来动态调整特征图的大小
x = self.pool(x)
x = x.view(-1, self.fc_input_size) # 展平张量
x = F.relu(self.fc1(x))
x = self.fc2(x)
return F.log_softmax(x, dim=1)
# 创建模型实例并移动到设备
model = SimpleCNN().to(device)
# 定义损失函数和优化器
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=0.001)
# 记录每个epoch的损失和准确率
train_losses = []
train_accuracies = []
# 训练模型
def train(model, train_loader, criterion, optimizer, epoch, device):
model.train()
correct = 0
total_loss = 0
for batch_idx, (data, target) in enumerate(train_loader):
data, target = data.to(device), target.to(device) # 将数据移动到设备
optimizer.zero_grad()
output = model(data)
loss = criterion(output, target)
loss.backward()
optimizer.step()
total_loss += loss.item()
pred = output.argmax(dim=1, keepdim=True)
correct += pred.eq(target.view_as(pred)).sum().item()
if batch_idx % 10 == 0:
print(f'Train Epoch: {epoch} [{batch_idx * len(data)}/{len(train_loader.dataset)} '
f'({100. * batch_idx / len(train_loader):.0f}%)]\tLoss: {loss.item():.6f}')
avg_loss = total_loss / len(train_loader)
accuracy = 100. * correct / len(train_loader.dataset)
train_losses.append(avg_loss)
train_accuracies.append(accuracy)
# 测试模型
def test(model, test_loader, criterion, device):
model.eval()
test_loss = 0
correct = 0
with torch.no_grad():
for data, target in test_loader:
data, target = data.to(device), target.to(device) # 将数据移动到设备
output = model(data)
test_loss += criterion(output, target).item() # 累加batch的损失
pred = output.argmax(dim=1, keepdim=True) # 获取最大概率的类别
correct += pred.eq(target.view_as(pred)).sum().item()
test_loss /= len(test_loader.dataset)
accuracy = 100. * correct / len(test_loader.dataset)
print(f'\nTest set: Average loss: {test_loss:.4f}, Accuracy: {correct}/{len(test_loader.dataset)} '
f'({accuracy:.0f}%)\n')
# 运行训练和测试
num_epochs = 100
for epoch in range(1, num_epochs + 1):
train(model, train_loader, criterion, optimizer, epoch, device)
test(model, test_loader, criterion, device)
# 示例函数,用于展示预测结果
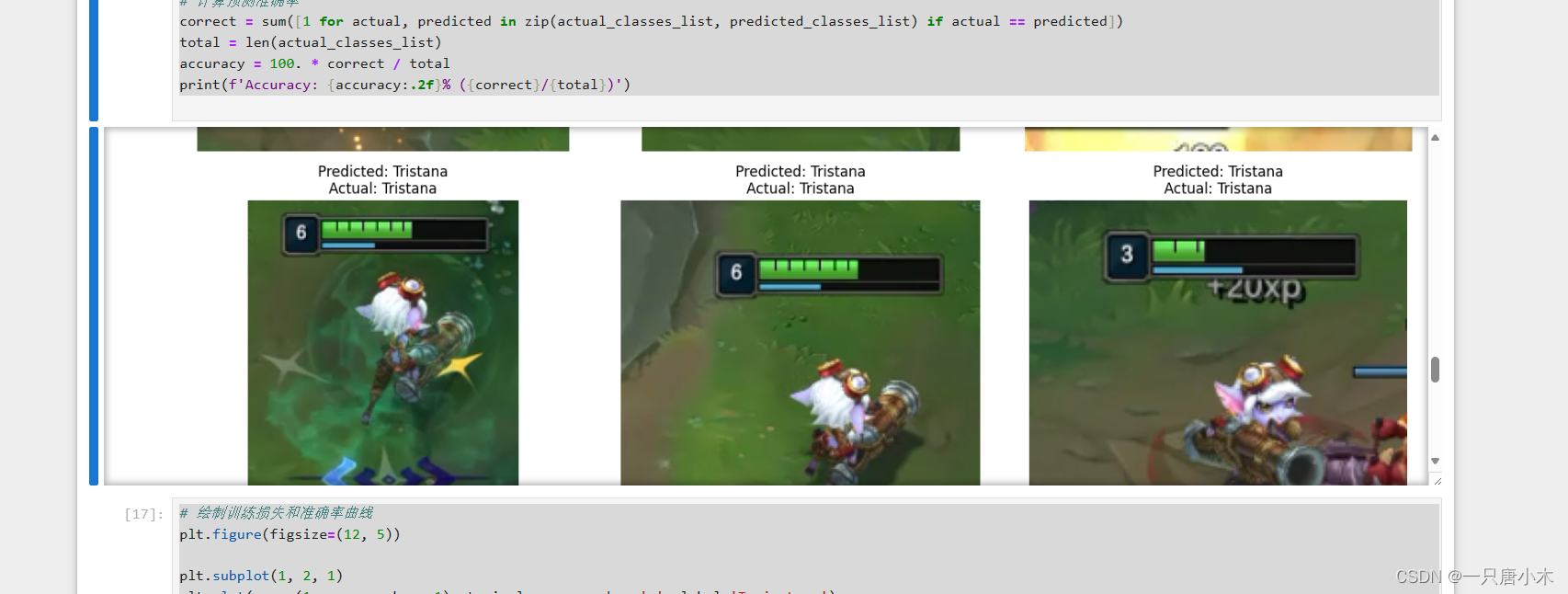
def show_predictions(images, actual_classes, predicted_classes, num_images_per_row=3):
num_images = len(images)
num_rows = (num_images + num_images_per_row - 1) // num_images_per_row # 计算行数
plt.figure(figsize=(15, 5 * num_rows)) # 根据行数调整图像大小
for idx in range(num_images):
plt.subplot(num_rows, num_images_per_row, idx + 1)
plt.imshow(images[idx])
plt.title(f'Predicted: {predicted_classes[idx]}\nActual: {actual_classes[idx]}')
plt.axis('off')
plt.tight_layout()
plt.show()
# 设置设备
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
# 自定义测试数据集的路径(使用原始字符串或双反斜杠来避免转义问题)
custom_data_dir = r'D:\pytorch_code\LOL峡谷测试数据'
# 定义图像预处理和转换
transform = transforms.Compose([
transforms.Resize((224, 224)), # 调整大小为模型输入尺寸
transforms.ToTensor(), # 转换为Tensor
transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]), # 归一化
])
# 加载自定义测试数据集
images_list = []
actual_classes_list = []
predicted_classes_list = []
# 遍历每个类别文件夹
for class_name in os.listdir(custom_data_dir):
class_folder = os.path.join(custom_data_dir, class_name)
if os.path.isdir(class_folder):
for filename in os.listdir(class_folder):
if filename.endswith('.jpg') or filename.endswith('.png'): # 假设你的数据集是jpg或png格式的图像
image_path = os.path.join(class_folder, filename)
image = Image.open(image_path).convert('RGB') # 加载图像并转换为RGB格式
image_tensor = transform(image).unsqueeze(0).to(device) # 进行预处理和转换,并添加批次维度
# 使用模型进行预测
with torch.no_grad():
outputs = model(image_tensor)
_, predicted = torch.max(outputs, 1)
# 存储图像、实际类别和预测类别
images_list.append(image)
actual_classes_list.append(class_name) # 使用文件夹名称作为实际类别
predicted_classes_list.append(train_dataset.classes[predicted.item()])
# 显示预测结果
show_predictions(images_list, actual_classes_list, predicted_classes_list)
# 计算预测准确率
correct = sum([1 for actual, predicted in zip(actual_classes_list, predicted_classes_list) if actual == predicted])
total = len(actual_classes_list)
accuracy = 100. * correct / total
print(f'Accuracy: {accuracy:.2f}% ({correct}/{total})')
# 绘制训练损失和准确率曲线
plt.figure(figsize=(12, 5))
plt.subplot(1, 2, 1)
plt.plot(range(1, num_epochs + 1), train_losses, marker='o', label='Train Loss')
plt.xlabel('Epoch')
plt.ylabel('Loss')
plt.title('Training Loss')
plt.legend()
plt.subplot(1, 2, 2)
plt.plot(range(1, num_epochs + 1), train_accuracies, marker='o', label='Train Accuracy')
plt.xlabel('Epoch')
plt.ylabel('Accuracy (%)')
plt.title('Training Accuracy')
plt.legend()
plt.tight_layout()
plt.show()
# 添加用户输入图像路径并进行预测的功能
def predict_image(image_path, model, transform, device, classes):
image = Image.open(image_path).convert('RGB') # 加载图像并转换为RGB格式
image_tensor = transform(image).unsqueeze(0).to(device) # 进行预处理和转换,并添加批次维度
# 使用模型进行预测
model.eval()
with torch.no_grad():
outputs = model(image_tensor)
_, predicted = torch.max(outputs, 1)
return classes[predicted.item()]
#r"C:\Users\29847\Desktop\测试\Mundo\蒙多 (3).png"
# 输入图像路径并进行预测
while True:
image_path = input("请输入图像路径 (或输入'退出'结束程序): ")
if image_path.lower() == '退出':
break
predicted_class = predict_image(image_path, model, transform, device, train_dataset.classes)
print(f'图像的预测类别是: {predicted_class}')


















 4174
4174

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











