






Numpy实现K-means算法
import numpy as np
import matplotlib.pyplot as plt
def kmeans(X, k, max_iters=1000, tol=1e-4):
"""
K-means聚类算法的NumPy实现
Parameters:
X (numpy.ndarray): 输入数据集,每一行代表一个样本,每一列代表一个特征。
k (int): 簇的数量。
max_iters (int): 最大迭代次数。
tol (float): 收敛阈值,当簇中心变化小于该值时停止迭代。
Returns:
centroids (numpy.ndarray): 最终的簇中心。
labels (numpy.ndarray): 每个样本的簇标签。
"""
m, n = X.shape
centroids = X[np.random.choice(m, k, replace=False)]
labels = np.zeros(m)
for _ in range(max_iters):
distances = np.linalg.norm(X - centroids[:, np.newaxis], axis=2)
new_labels = np.argmin(distances, axis=0)
new_centroids = np.array([X[new_labels == z].mean(axis=0) for z in range(k)])
if np.linalg.norm(new_centroids - centroids) < tol:
break
centroids = new_centroids
labels = new_labels
return centroids, labels
# 生成100个随机数据点作为示例
np.random.seed(0)
X = np.random.rand(1000, 2) * 10
# 使用自定义的K-means算法进行聚类
k = 3
centroids, labels = kmeans(X, k)
# 可视化结果
colors = ["g.", "r.","b."]
for i in range(len(X)):
plt.plot(X[i][0], X[i][1], colors[labels[i]], markersize=5)
# 绘制簇中心
plt.scatter(centroids[:, 0], centroids[:, 1], marker="x", s=150, linewidths=5, zorder=10)
plt.show()
K=3时的聚类结果

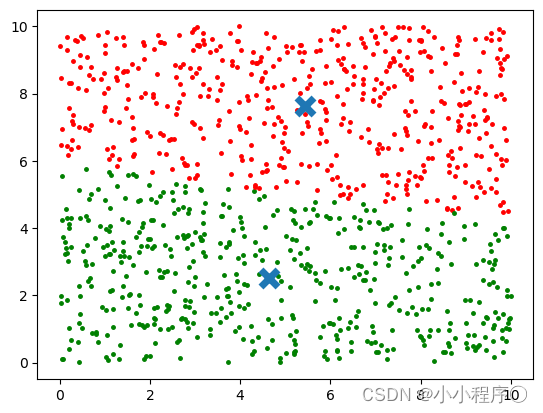
k=2时的聚类结果
k=4的聚类结果
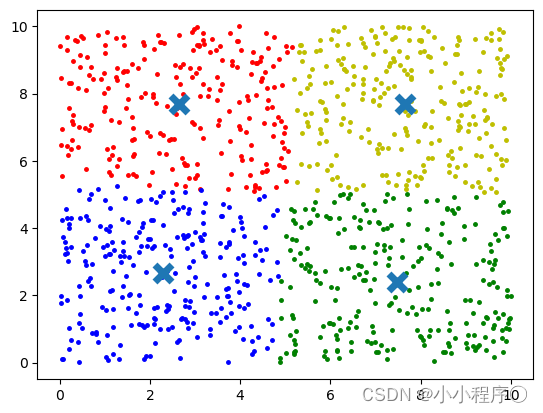
不同的k对应不同的结果,运行的时间也不相同。并且随着数据的增加,K-means计算的消耗成倍增长。
基于上篇博客K-means算法的代码实现
到这里,如果还有什么疑问欢迎私信、或评论博主问题哦,博主会尽自己能力为你解答疑惑的!
如果对你有帮助,你的赞和关注是对博主最大的支持!!
















 3530
3530











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











