






💥💥💥💞💞💞欢迎来到本博客❤️❤️❤️💥💥💥
🏆博主优势:🌞🌞🌞博客内容尽量做到思维缜密,逻辑清晰,为了方便读者。
⛳️座右铭:行百里者,半于九十。
目录
💥1 文献来源

如有侵权请联系删除。
📚2 概述
为了改善粒子群算法易早熟收敛、精度低等缺点,提出一种多尺度协同变异的粒子群优化算法,并证明了该算法以概率1收敛到全局最优解.算法采用多尺度高斯变异机制实现局部解逃逸.在算法初期阶段,利用大尺度变异及均匀变异算子实现全局最优解空间的快速定位;随着适应值的提升,变异尺度随之降低;最终在算法后期阶段,利用小尺度变异算子完成局部精确解空间的搜索.将算法应用6个典型复杂函数优化问题,并同其他带变异操作的PSO算法比较,结果表明,该算法在收敛速度及稳定性上有显著提高。
多尺度协同变异粒子群算法:
粒子群算法迭代过程中,如果某个粒子发现了一个当前最优位置,其他粒子会迅速向其靠拢.如果该最优位置是局部最优点,粒子群就无法在解空间内重新搜索,算法就会陷入局部最优,从而出现早熟收敛的现象.为了避免这种情况的发生,此时,如果我们对粒子的速度进行变异,就可以改变粒子的前进方向,使粒子进入解空间的其他区域搜索,从而有可能发现新的个体最优位置和种群最优位置,增加算法找到全局最优解的几率.然而,在上述提到的通过增加变异操作来帮助算法逃出局部最优的改进算法中,粒子的逃逸能力都取决于均匀变异尺度,均匀变异虽然具有很强的逃离原点的能力,但是由于我们事先无法预知函数局部极间的距离,因此无法给出合适的变异尺度.如果初始尺度较大,则无法保证所逃离到的新位置的适应值一定优于现有的最优解,尤其是在算法进化后期最优解可能就存在于现有最优解周边的区域,这样,通过单纯的均匀变异无法确定更优的位置,最终因迭代次数的限制使其无法收敛到全局最优解.为此,本文提出一种多尺度协同变异粒子群优化算法,算法的逃逸能力取决于不同尺度方差的高斯变异算子,不同尺度的变异有助于算法在搜索空间中进行分散式搜索.同时,变异尺度随着适应度的提升逐渐减少.这样,在保证算法逃逸能力的同时,提高了最优解的
精度.
🎉3 运行结果
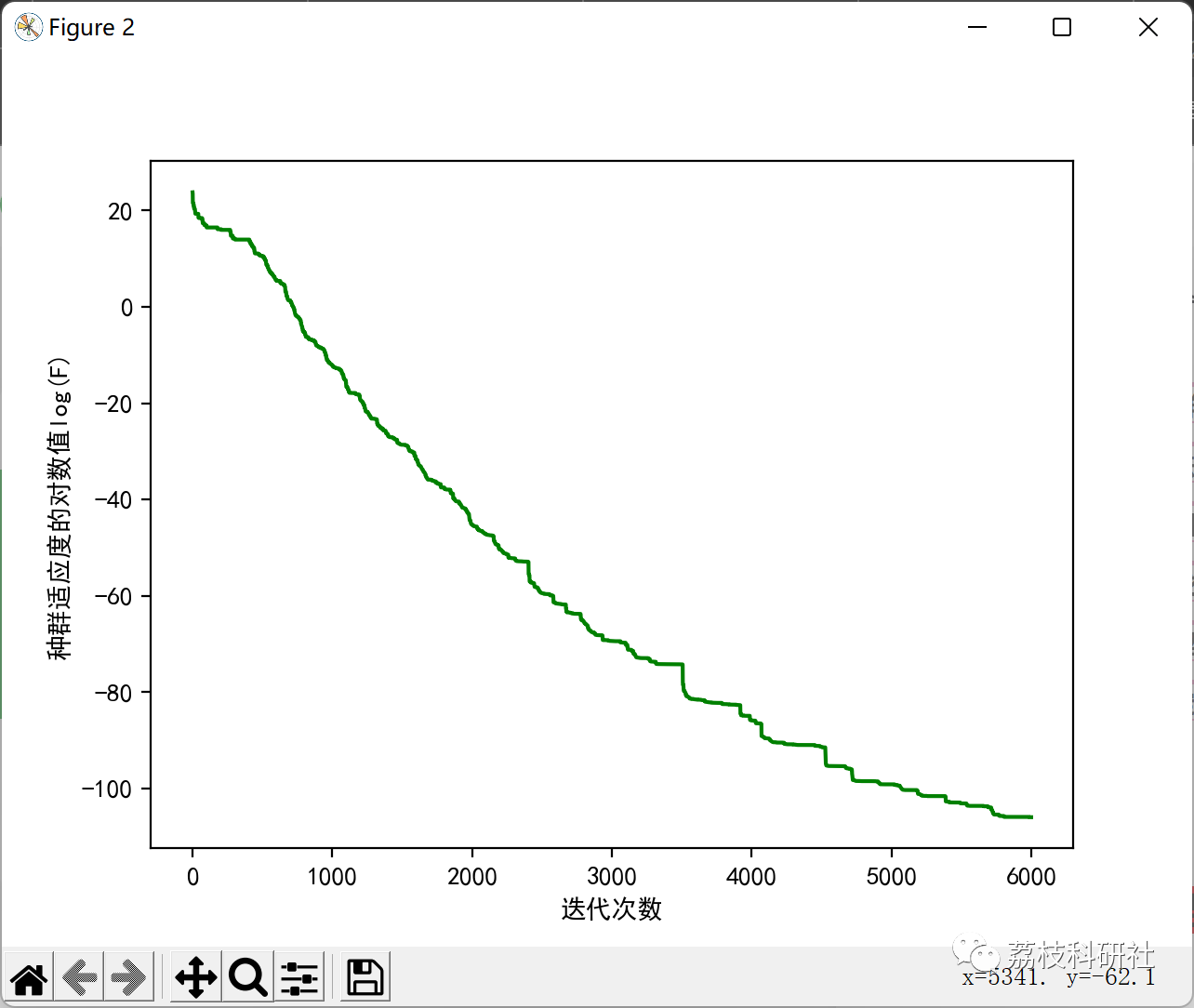
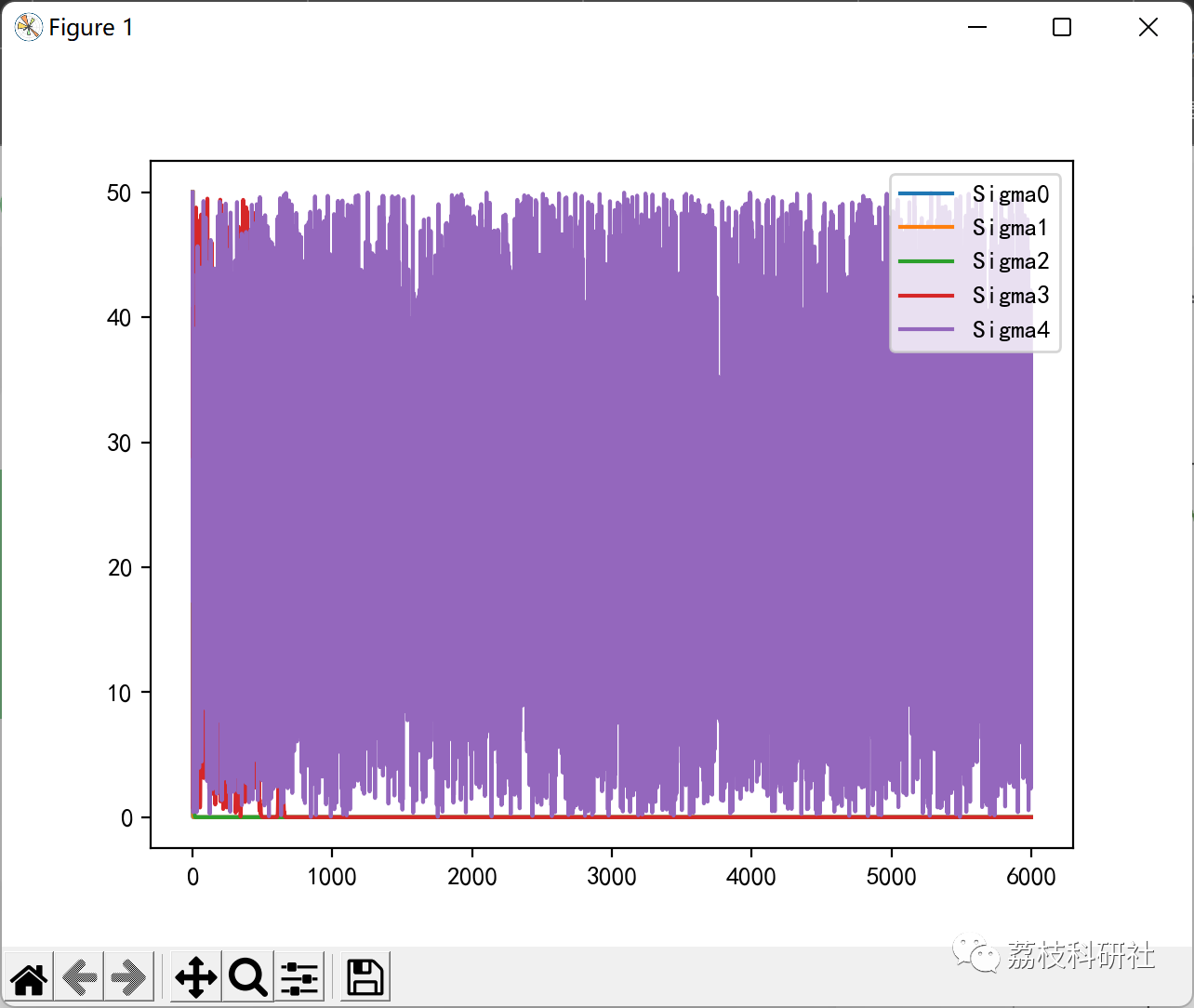
部分代码:
def find_min(self, func, region):
W = np.abs(region[0]-region[1]).astype(np.double)
Vmax = W/4.0
sigma = self.initSigma(W)
x = self.initX(region)
v = self.initV(Vmax)
Td = self.initTd(Vmax)
G = self.initG()
pbfx = func(x)
# print(x.shape)
# print(pbfx.shape)
# print(np.unravel_index(pbfx.argmin(), pbfx.shape))
pb = x*1.0
gbfx = np.min(pbfx)*1.0
gb = pb[pbfx.argmin()]*1.0
plt_sigma = np.expand_dims(sigma, -1)
plt_x = np.array([0])
plt_gbfx = gbfx*1.0
for i in range(self.maxK):
print(func(gb))
# print(gb)
fx = func(x)
mask = fx<pbfx
pbfx[mask] = fx[mask]*1.0
pb[mask] = x[mask]*1.0
if gbfx >= np.min(pbfx):
gbfx = np.min(pbfx)*1.0
gb = pb[pbfx.argmin()]*1.0
v = self.update_V(v, x, pb, gb, i)
v, Td, G = self.escape(v, x, func, Td, G, sigma, Vmax)
# v[v>Vmax] = Vmax
# v[v<-Vmax] = -Vmax
x += v
x[x>np.max(region)] = np.max(region)
x[x<np.min(region)] = np.min(region)
sigma, _ = self.update_Sigma(sigma, func, x, W)
plt_sigma = np.hstack([plt_sigma,np.expand_dims(sigma,-1)])
plt_x = np.hstack([plt_x, i])
plt_gbfx = np.hstack([plt_gbfx, gbfx])
return gbfx, gb, plt_sigma, plt_x, plt_gbfx


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









