







项目需求与任务分析
项目背景
中国自古以来就是一个农业大国,农业关系到国计民生,是国民经济的支柱产业。农产品价格是否合理,不仅影响农业生产的发展,农产品的流通、消费和农民的收入水平,而且影响工业品的成本和价格,影响国家同农民之间、城乡人民之间以及农民内部的物质利益关系,对整个社会经济生活的安定也关系重大。与其他一般商品不同,农产品价格受到气候、供求关系、宏观经济等因素的影响后波动性较大。近年来,有关国内农产品涨价的信息频频见诸媒体,有些城市已经吃不到 3 元以下的蔬菜了,而春节前批发价只有五六元一斤的绿豆,如今接近 10 元钱。最疯狂的涨价产品是大蒜,借“甲流”概念疯涨过后,又卷土重来,据报道,河南大蒜身价短时间内涨了 100 倍。针对波动幅度如此之大的农产品价格,能否对其进行宏观调控与管理,不仅关系到广大农民的生计问题,更是影响国计民生的头等大事
任务分析
- 对所选取的 935 种农产品价格数据进行基本的统计描述、可视化展示和探索性分析。
- 将对数据进行清洗、去重、缺失值填充等操作,确保数据的质量和可用性。
- 应用样条插值法对缺失数据进行补全,提高数据的质量和完整性。
- 根据农产品的特点和数据的特点,选择合适的模型并进行训练。
- 将对训练好的模型评估,优化模型性能,提高预测准确率。
项目数据特征说明
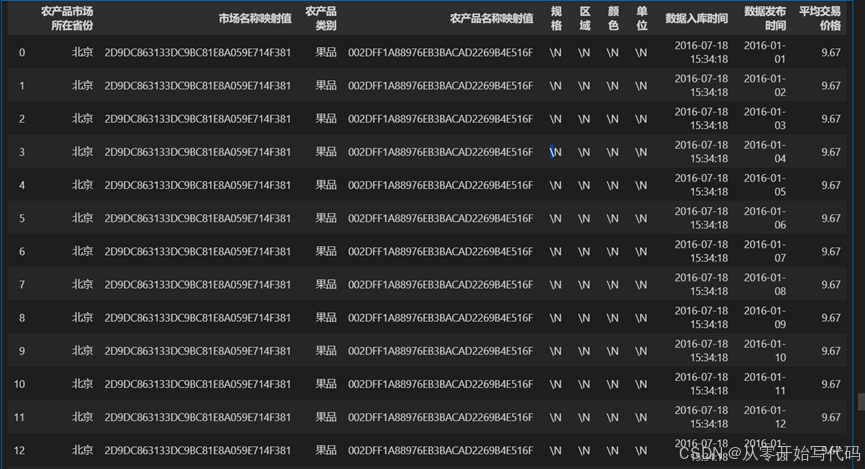
本案例数据来源为 2016 年以前全国各农场品交易市场,数据中保留了交易市场所在地,市场名称,农场品类别、名称、最低交易价格、评价交易价格、最高交易价格、抓取时间、交易时间。在提供的数据中,已经对市场名称、农产品名称做了映射处理。数据提供方除了提供 2016 年以前全国各农场品交易市场农产品交易数据外还给出了 935 种农产品及其对应的交易市场,并对需要预测的日期做出要求。如图1- 2图1- 1。
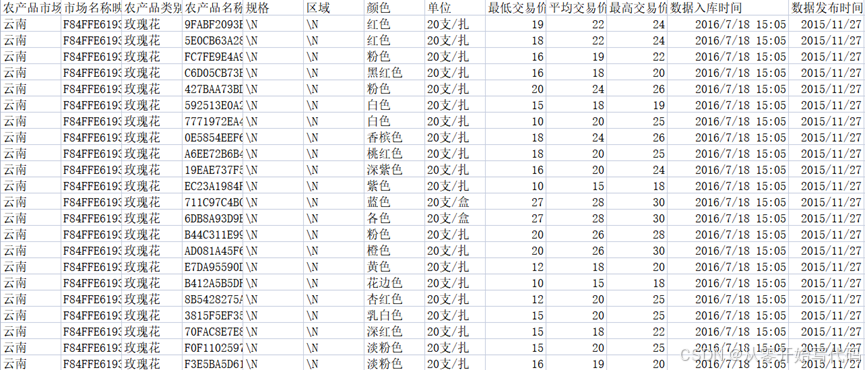
图1- 1 数据样例
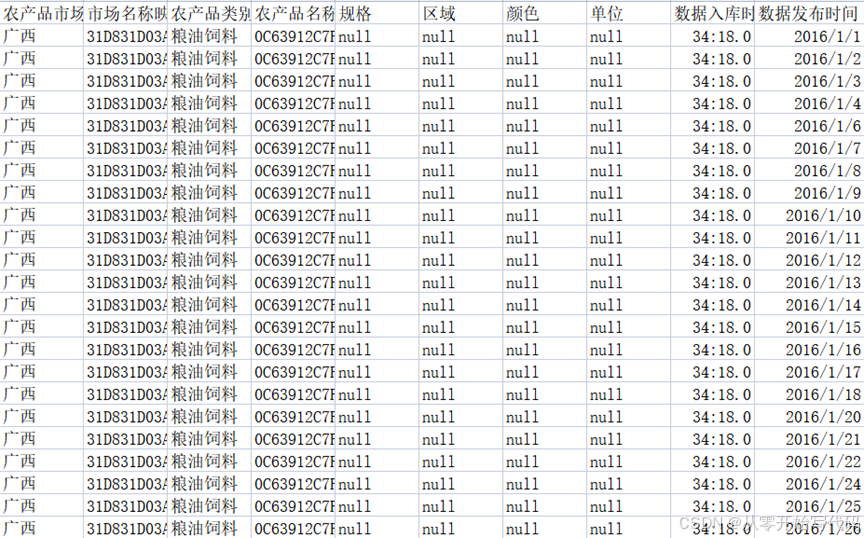
图1- 2 预测目标数据
数据探索
一致性校验
- 所给数据进行一致性校验得到如下表格
-
import pandas as pd import numpy as np import matplotlib.pyplot as plt pd.set_option('display.max_rows',None) data=pd.read_csv('../6/数据源/farming2.csv',low_memory=False) print(data.shape) print(data.columns) print(data.dtypes) 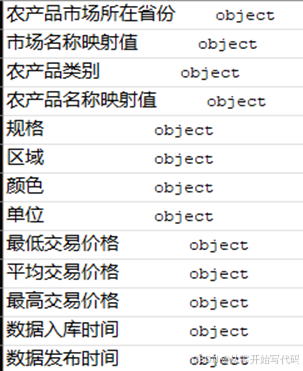
由以上表格可以得出虽然数据集中包括多个重要的字段(如价格、时间字段),但所有字段当前存储为 object 类型,这意味着即使是数值型和日期型数据也以字符串形式存储。这一发现表明,必须对部分字段进行类型转换,特别是“最低交易价格”、“平均交易价格”和“最高交易价格”这三个字段需要转换为数值型,以便执行准确的统计分析和建模。时间字段(“数据入库时间”和“数据发布时间”)也需转换为日期时间格式,以支持时间序列分析或数据延迟分析。数据集具有丰富的信息量,但在进行深度分析前,必须完成数据的类型转换和清洗工作。完成这些预处理后,可以深入挖掘农产品市场中的价格、分布、区域特征等多维度的规律和趋势,为市场分析和策略制定提供更可靠的依据。
缺失值校验
print('数据缺失情况:\n',data.columns.isnull())
print('数据缺失率:\n',1-data.count()/len(data))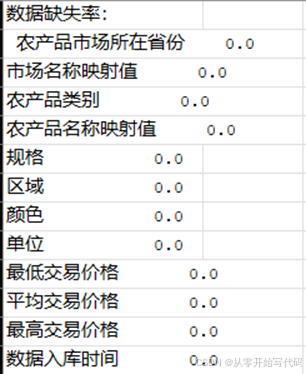
经校验无缺失
异常值校验
#数据类型转换
converted_series = pd.to_numeric(data['平均交易价格'],errors='coerce')
# 过滤出无法转换的数据(即 NaN 值)
nor_index = data[converted_series.isna()].index
invalid_data=data.loc[nor_index,'平均交易价格']
# 打印无法转换的数据
print("无法转换的数据:")
print(invalid_data)
print('一共有:',len(invalid_data))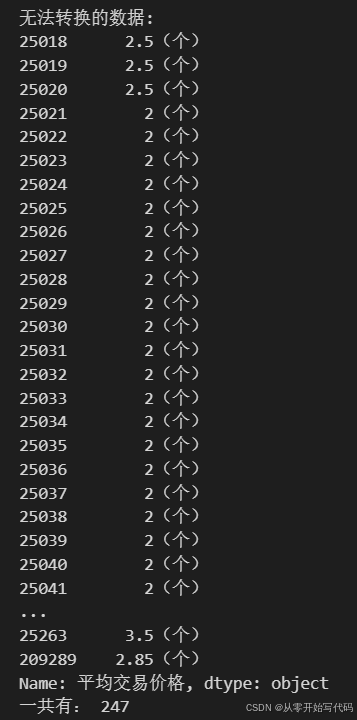
# 由于本题要求是对农产品价格进行预测,所以现只对农产品的平均交易价格做异常值分析
# 删除空值数据
data.drop(nor_index, inplace=True)
#数据类型转换
data['平均交易价格'] = pd.to_numeric(data['平均交易价格'],errors='coerce')
# 使用这些随机索引选择数据
price_sample = data['平均交易价格'].iloc[::100] #以100为间距
# 查看抽样数据的形状
print(price_sample.shape)
print(price_sample.dtype)
# 通过IQR原则对异常值进行检验
Percentitle=np.percentile(price_sample,[0,25,50,75,100])
IQR=Percentitle[3]-Percentitle[1]
UpLimit=Percentitle[3]+IQR*1.5
arrayownLimit=Percentitle[1]-IQR*1.5
# 计算偏差
abnormal=[i for i in price_sample if i > UpLimit or i < arrayownLimit]
#打印
print('IQR准则的异常值为:\n',abnormal)
print('IQR准则检出的异常比例为:\n',len(abnormal)/len(price_sample))
print('异常值的数量为:',len(abnormal)) 发现10%的数据存在异常情况,再次绘制箱线图代码如下,效果如图所示
发现10%的数据存在异常情况,再次绘制箱线图代码如下,效果如图所示
# 箱线图
np.random.seed(42)
data_drow=np.random.choice(price_sample.dropna(),size=1000,replace=False) # 由于数据量大故取其中的1000个点用于画图
data_drow=pd.Series(data_drow)
# 计算四分位数和四分位距
Q1 = data_drow.quantile(0.25)
Q3 = data_drow.quantile(0.75)
IQR =Q3 - Q1
# 计算下界和上界
lower =Q1- 1.5 * IQR
upper = Q3 + 1.5 * IQR
#设置字体和图形参数
plt.rcParams['font.sans-serif']=['SimHei']# 用来正常显示中文标签
plt.rcParams['axes.unicode_minus']=False # 用来正常显示负号
# 创建箱线图
fig,ax= plt.subplots(figsize=(15,6))
ax.boxplot(data_drow)
ax.set_title('平均交易价格箱线图')
# 设置 y 轴的范围
ax.set_ylim(bottom=min(data_drow.min(), lower), top=max(data_drow.max(), upper))
# 显示图形
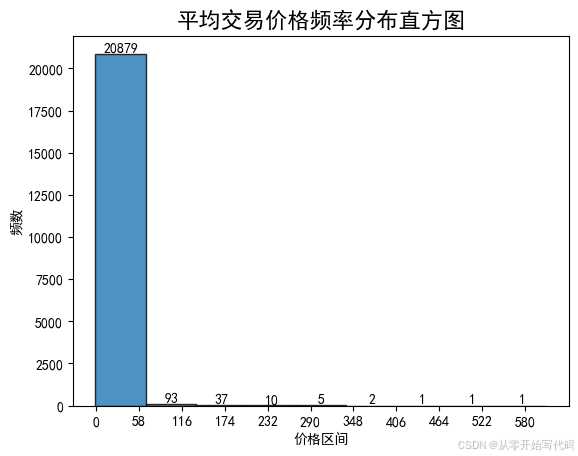
plt.show()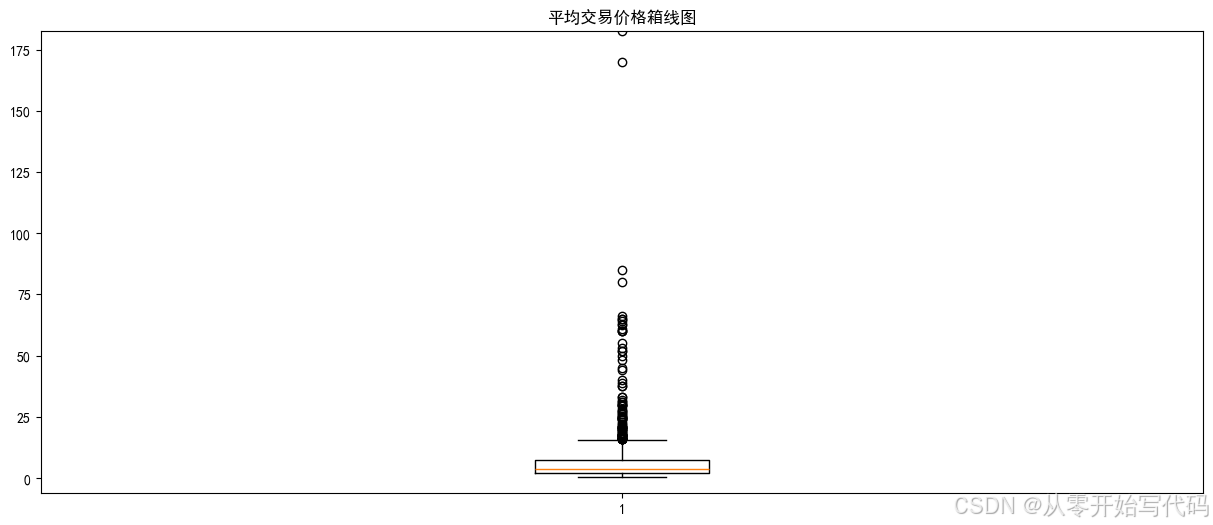 为更好的展示农产品交易价格的分布规律,绘制了平均交易价格频率分布直方图,代码,效果如下
为更好的展示农产品交易价格的分布规律,绘制了平均交易价格频率分布直方图,代码,效果如下
# 求极差
distance=price_sample.max()-price_sample.min()
# 组距
group=distance/58
# bins设置
bins = np.linspace(price_sample.min(), price_sample.max(), 10) # 使用linspace创建10个边界点,包含0和580
bin_edges = bins[:-1] # 直方图使用的左边界
bin_centers = (bins[:-1] + bins[1:]) / 2 # 柱子的中心位置,用于标注
# 计算每个bin的频数
hist, _ = np.histogram(price_sample, bins=bins)
# 画图
plt.hist(price_sample, bins=bins-1, range=[price_sample.min(), price_sample.max()], alpha=0.8, edgecolor='black')
plt.title('平均交易价格频率分布直方图', fontsize=16)
plt.xlabel('价格区间')
plt.ylabel('频数')
# 在柱子上标注数据
for i, freq in enumerate(hist):
y_pos = freq # 柱子的高度
x_pos = bin_centers[i] # 柱子的中心位置
plt.text(x_pos, y_pos + 1, str(freq), ha='center', va='bottom') # 在柱子顶部稍微偏移一点位置标注
# 设置x轴刻度
xlabel=[]
for i in range(11):
xlabel.append(58*i)
plt.xticks(xlabel)
plt.show()
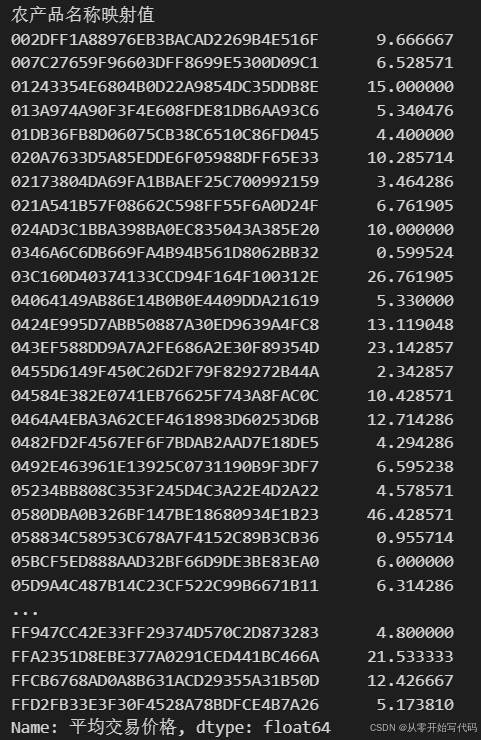
通过对每个农产品的所有交易数据求均值之后再对每个大类的农产品求均值得到以下数据
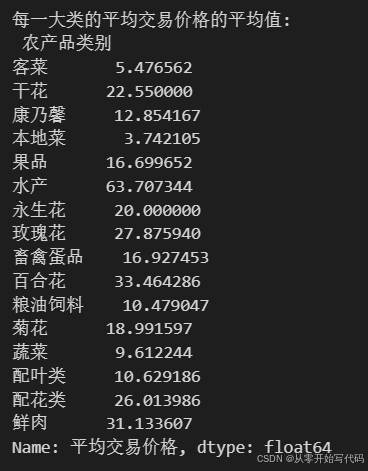
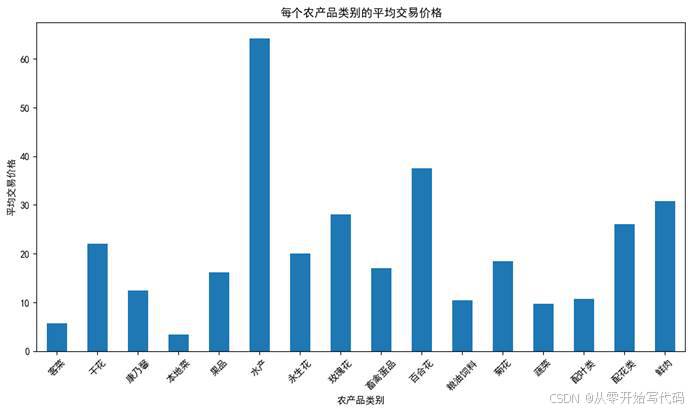
可以看出在0—58的范围内农产品的出现频率超过了20000次说明在这个区间内农产品的更受人亲赖。该柱状图展示了不同农产品类别的平均交易价格。"水产"类别的平均价格最高,超过60。而"大宗粮油"类别的平均价格最低,接近0。
数据结构包含x轴上的各类农产品类别及其对应的y轴上的平均交易价格。不同类别之间的价格存在明显差异,显示出农产品类型之间的价格范围较大,图表突出了基于农产品类别的定价多样性。
数据预处理
异常值处理
经统计有247个数据是异常的,经分析由于数据量小,并且原因不明,所以就考虑将其删去。同时,数据入库时间无意义所以将其删去,处理结果如下表2-1:
表2-1异常值处理结果
| 行 | 列 | |
| 处理前的数据 | 2103048 | 12 |
| 处理后的数据 | 2102801 | 12 |
特征工程
缺失值处理(插值法)、数据变换、、数据合并
缺失值处理:为了填补数据集中缺失的日期记录,并为这些缺失的记录填充平均交易价格采取了此方法。
- **处理步骤**:
1. 转换日期格式并定义日期范围。
2. 遍历每个农产品,筛选出当前农产品的所有记录。
3. 遍历日期范围,检查并填补缺失日期的数据。
4. 合并所有农产品的数据,得到最终结果。
这段特征工程确保了每个农产品在指定日期范围内都有记录,即使某些日期在原始数据集中缺失。通过均值填补这些缺失的日期记录,可以确保后续的分析和建模过程不受缺失数据的影响。
#特征工程
df=new_data
# 将'数据发布时间'转换为日期格式
df.loc[:,'数据发布时间'] = pd.to_datetime(df['数据发布时间'])
# 定义日期范围
january_range = pd.date_range(start='2015-01-01',end='2015-12-30', freq='D')
# 创建一个空的DataFrame来存储结果
result = pd.DataFrame()
# 获取所有农产品名称
all_products = df['农产品名称映射值'].unique()
# all_products.shape
for product in all_products:# 筛选出当前农产品的所有记录
product_data = df[df['农产品名称映射值']== product].copy()
product_data['数据发布时间']= pd.to_datetime(product_data['数据发布时间'])
# select_data.shape
# 初始化一个DataFrame来存储当前农产品的结果
product_result = pd.DataFrame()
avg_price=average_prices[product] #取该产品的平均交易价格用于填充空值
for date in january_range:
if date not in product_data['数据发布时间'].dt.date.values:
missing_row=pd.DataFrame({
'数据发布时间':[date],
'农产品名称映射值':[product],
'平均交易价格':[avg_price],
})
product_result=pd.concat([product_result,missing_row],ignore_index=True)
else:
product_result=pd.concat([product_result,product_data[product_data['数据发布时间'].dt.date == date]], ignore_index=True)
# 合并结果
result = pd.concat([result, product_result], ignore_index=True)
# 查看结果
result.head()
数据建模及模型评估
随机森林的基础介绍、模型应用(样本划分)、模型评估(随机森林的默认评估指标是均方误差(Mean Squared Error,MSE)和决定系数(Coefficient of Determination,R),也可以加入精确率、召回率)
将数据集划分为训练集和测试集,其中测试集占30%。然后使用随机森林回归模型对训练集进行训练,并应用训练好的模型对测试集进行预测。最后使用训练好的模型对另一个数据集进行预测,并将预测结果保存到一个新的数据框中并将预测结果与原始数据合并到一起。
#建模部分
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestRegressor
from sklearn.preprocessing import OneHotEncoder
from sklearn.compose import ColumnTransformer
from sklearn.pipeline import Pipeline
from sklearn.preprocessing import StandardScaler
# 提取日期特征
result['year'] = result['数据发布时间'].dt.year
result['month'] = result['数据发布时间'].dt.month
result['day'] = result['数据发布时间'].dt.day
# 过滤 2015 年的数据用于训练
train_data = result[result['year'] == 2015]
# 定义特征和目标
X = train_data[['year', 'month', 'day', '农产品名称映射值']]
y = train_data['平均交易价格']
# 使用 train_test_split 来分割数据,30% 作为测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
# 准备2016年1月的数据
future_dates = pd.date_range(start='2016-01-01', end='2016-01-31', freq='D')
all_products = result['农产品名称映射值'].unique() # 获取所有独特的农产品名称映射值
# 创建未来的数据框架
future_data = []
for product in all_products:
temp_df = pd.DataFrame({
'数据发布时间': future_dates,
'year': future_dates.year,
'month': future_dates.month,
'day': future_dates.day,
'农产品名称映射值': [product] * len(future_dates)
})
future_data.append(temp_df)
future_data = pd.concat(future_data, ignore_index=True)
X_future = future_data[['year', 'month', 'day', '农产品名称映射值']]
# 预处理和建模
preprocessor = ColumnTransformer(
transformers=[
('num', StandardScaler(), ['year', 'month', 'day']),
('cat', OneHotEncoder(), ['农产品名称映射值'])
])
model = Pipeline(steps=[
('preprocessor', preprocessor),
('regressor', RandomForestRegressor(n_estimators=100, n_jobs=-1))
])
# 训练模型
model.fit(X_train, y_train)
# 由于我们需要针对每种农产品分别预测,我们需要分组预测
predictions_df = []
for product in all_products:
product_future_data = future_data[future_data['农产品名称映射值'] == product]
y_future_pred = model.predict(product_future_data[['year', 'month', 'day', '农产品名称映射值']])
product_future_data['平均交易价格'] = y_future_pred
predictions_df.append(product_future_data)
predictions_df = pd.concat(predictions_df, ignore_index=True)
为了预测 2016 年 1 月份不同农产品的平均交易价格,我们基于历史数据进行了模型训练和未来数据预测。我们首先从原始数据中提取了日期特征(年、月、日),并过滤了 2015 年的数据作为训练集。使用 2015 年的农产品交易数据构建预测模型后,针对 2016 年 1 月每种农产品的交易价格进行了预测。
(由于数据一些数据缺失,我们选择用平均价格去做差补以便确保一五年的每一个数据都有)
以下为部分预测结果的展示:
| 数据发布时间 | 农产品名称映射值 | 预测平均交易价格 |
| 2016-01-01 | 002DFF1A88976EB3BACAD2269B4E516F | 9.666667 |
| 2016-01-02 | 002DFF1A88976EB3BACAD2269B4E516F | 9.666667 |
| 2016-01-03 | 002DFF1A88976EB3BACAD2269B4E516F | 9.666667 |
| 2016-01-04 | 002DFF1A88976EB3BACAD2269B4E516F | 9.666667 |
| 2016-01-05 | 002DFF1A88976EB3BACAD2269B4E516F | 9.666667 |
| 2016-01-06 | 002DFF1A88976EB3BACAD2269B4E516F | 9.666667 |
| 2016-01-07 | 002DFF1A88976EB3BACAD2269B4E516F | 9.666667 |
| 2016-01-08 | 002DFF1A88976EB3BACAD2269B4E516F | 9.666667 |
| 2016-01-09 | 002DFF1A88976EB3BACAD2269B4E516F | 9.666667 |
| 2016-01-10 | 002DFF1A88976EB3BACAD2269B4E516F | 9.666667 |
| 2016-01-11 | 002DFF1A88976EB3BACAD2269B4E516F | 9.666667 |
| 2016-01-12 | 002DFF1A88976EB3BACAD2269B4E516F | 9.666667 |
| 2016-01-13 | 002DFF1A88976EB3BACAD2269B4E516F | 9.666667 |
| 2016-01-14 | 002DFF1A88976EB3BACAD2269B4E516F | 9.666667 |
| 2016-01-15 | 002DFF1A88976EB3BACAD2269B4E516F | 9.666667 |
| 2016-01-16 | 002DFF1A88976EB3BACAD2269B4E516F | 9.666667 |
| 2016-01-17 | 002DFF1A88976EB3BACAD2269B4E516F | 9.666667 |
| 2016-01-18 | 002DFF1A88976EB3BACAD2269B4E516F | 9.666667 |
| 2016-01-19 | 002DFF1A88976EB3BACAD2269B4E516F | 9.666667 |
| 2016-01-20 | 002DFF1A88976EB3BACAD2269B4E516F | 9.666667 |
由于数据特征未达要求,故还需补充特征
#由于数据不全故需合并补充数据
result = pd.merge(sampled_data,predictions_df, on='农产品名称映射值',how='left')
# print(result.head())
print(result.shape)
# result.drop(columns=['平均交易价格_x','数据发布时间_x'],inplace=True)
result = result.rename(columns={
'平均交易价格_y': '平均交易价格',
'数据发布时间_y': '数据发布时间'
})
# 删除'数据发布时间'为空或'农产品平均交易价格'为空的数据
result = result.dropna(subset=['数据发布时间','平均交易价格'])
# 根据'农产品名称映射值'和'数据发布时间'进行去重
result = result.drop_duplicates(subset=['农产品名称映射值','数据发布时间'])
# 重置索引
result.reset_index(drop=True, inplace=True)
# 数据精度转换
result['平均交易价格']=result['平均交易价格'].round(2)
result.shape此补充是根据已求得的数据来补充‘农产品市场所在省份 市场名称映射值 农产品类别 农产品名称映射值 规格 区域 颜色 单位 数据入库时间’等特征
最后完成的结果如下:
模型验证部分,我们通过可视化的方式直观展示了模型预测结果与实际值的差异。主要通过绘制三类交易价格的对比图:平均交易价格、最高交易价格以及最低交易价格。该步骤有助于深入理解模型的预测效果,并发现潜在的误差和改进空间。
在训练完优化后的随机森林回归模型后,我们需要对模型的预测效果进行进一步验证。可视化是一个有效的方式,能够直观展示模型的预测结果与实际数据之间的差异。通过绘制对比图,可以分析模型在不同交易价格上的预测能力。模型预测结果与实际情况的差别如下所示:
R^2 Score: 1.0
Mean Squared Error (MSE): 5.702859101854953e-27
Root Mean Squared Error (RMSE): 7.551727684348102e-14
经分析可得,此模型的精度较高性能较好,可以完成此次的价格预测任务。
完整项目源码链接
通过网盘分享的文件:多种农产品价格预测项目.rar
链接: https://pan.baidu.com/s/1Jlffks70N9t1Sa7ow4YPtw?pwd=q4zs 提取码: q4zs

















 239
239

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









