







文章目录
- 定义
- 顺序表
- 单链表
- 双链表
- 循环链表
- 小结
- 408真题
- 1. [2010年全国统一考试] 将n(n>1)个整数存放到一维数组R中。设计一个算法,将R中保存的序列循环左移p(p>0且q<n)个位置,即将R中的数据由(X~0~,X~1~...X~p-1~,X~p~,X~p+1~...X~n-1~)变换为(X~p~,X~p+1~...X~n-1~,X~0~,X~1~...X~p-1~)
- 2.[2000年北京航空航天大学] 长度为n的线性表A采用顺序存储结构,写一个时间复杂度为O(n)、空间复杂度为O(1)的算法,删除线性表中所有值为item的元素。
- 3. [2009年全国统一考试 ]一个带有头结点的单链表,结点结构为(data,link),假设链表只给出头指针list.在不该改变链表的前提下,查找链表中倒数第k个位置上的结点(k为正整数),若查找成功,则输出该结点的data域的值并返回1;否则,返回0.
- 参考资料
作者: 蔡钧浩
专业: 计算机学院 计算机科学与技术
定义
线性表一种是最简单、最基本的线性结构。它是数据元素约束力最强的。应掌握对其增删改查
顺序表
定义:在内存用地址连续的有限的一块存储空间顺序 存放线性表的各个元素。
特点:逻辑上相邻的数据元素,物理次序也是相邻的。
只要确定好了存储线性表的起始位置,线性表中任一数据元素都可以随机存取,所以线性表的顺序存储结构是一种随机存取的储存结构,因为高级语言中的数组类型也是有随机存取的特性,所以通常我们都使用数组来描述数据结构中的顺序储存结构,用动态分配的一维数组表示线性表。
由于线性表中的元素个数是动态的,采用动态数组。
保存一个动态数组,需要3个变量:
- 指向元素类型的指针,如
elemType *data - 数组规模(容量),即顺序表的最大长度,如
int maxSize, - 元素个数(表长),即当前顺序表中存储的元素个数,如
int curLength
下面是顺序表的类型定义(重要的部分会给一个二级标题,后面也一样)
#ifndef _SEQLIST_H_
#define _SEQLIST_H_
#include "List.h"
template <class elemType> // elemType为顺序表存储的元素类型
class seqList: public List<elemType>{
private:
elemType *data; // 利用数组存储数据元素
int curLength; // 当前顺序表中存储的元素个数
int maxSize; // 顺序表的最大长度
void resize(); // 表满时扩大表空间
public:
seqList(int initSize = 10); // 构造函数
seqList(seqList & sl) ; // 拷贝构造函数
~seqList() {delete [] data;} // 析构函数
void clear() {curLength = 0;} // 清空表,只需修改curLength
bool empty() const {return curLength==0;} // 判空
int size() const {return curLength;} // 返回顺序表的当前存储元素的个数
void insert(int i,const elemType &value); // 在位置i上插入一个元素value,表的长度增1
void remove(int i); // 删除位置i上的元素value,若删除位置合法,表的长度减1
int search(const elemType &value) const ; // 查找值为value的元素第一次出现的位序
elemType visit(int i) const; // 访问位序为i的元素值,“位序”0表示第一个元素,类似于数组下标
void traverse() const ; // 遍历顺序表
void inverse(); // 逆置顺序表
};
template <class elemType>
template: 这个关键字表明后面的代码是一个模板,可以用不同的数据类型替换其中的占位符。
<class elemType>: 这里定义了一个模板参数 elemType,表示顺序表存储的元素类型。
class seqList: public List<elemType>
class: 这里表示 elemType 是一个类类型的参数,可以是任意类。
seqList: 这是一个类名,表示定义了一个名为 seqList 的类。
::表示类的继承关系,后面紧跟着的是基类。
public: 表示继承方式为公有继承,基类的成员在派生类中保持原有的访问权限。
List<elemType>: 这表示 seqList 类继承自 List 类,并且 List 类是一个模板类,其中的元素类型为 elemType。
综合起来,这段代码定义了一个模板类 seqList,它继承自一个模板类 List,其中使用了模板参数 elemType 来表示顺序表中存储的元素类型。
构造函数
构造一个空顺序表。时间复杂性O(1)
template <class elemType>
seqList<elemType>::seqList(int initSize)
{
if (initSize <= 0) throw badSize(); //判断长度
maxSize = initSize;
data = new elemType[maxSize]; // 创建一个大小为maxSize的顺序表,动态数组
curLength = 0;
}
seqList<elemType>::seqList(int initSize)
seqList: 这是一个类名,表示定义了一个名为 seqList 的类。
<elemType>::seqList: 这里是 seqList 类的构造函数的定义,构造函数的名称与类名相同,表示这是 seqList 类的构造函数。
(int initSize): 这是构造函数的参数列表,表示构造函数接受一个整型参数 initSize 作为初始大小。
查找值为value的元素
顺序查找值为value的元素在线性表中第一次出现的位置,需要遍历线性表,将每个元素与value比较。时间复杂性O(n)
template<class elemType>
int seqList<elemType>::search(const elemType & value) const
{
for (int i = 0;i < curLength;i++) {
if (value == data[i]) {
return i;
}
return -1; //查找失败返回-1
}
int seqList<elemType>::search(const elemType & value) const
int: 表示函数返回一个整数类型的值。
seqList<elemType>::search: 这里seqList<elemType>表示seqList是一个模板类,search是这个类中的一个成员函数。
const elemType & value: 这里const表示这个参数是常量,不可被修改,elemType是一个类型,&表示引用,即函数接收一个类型为elemType的常量引用参数。
const: 表示这个函数不会修改类的成员变量,是一个常成员函数。
插入运算
在位序i处插入一个值为 value 的新元素。这插入使得 ai 和 ai-1 的逻辑关系发生了变化,表长由n变成n+1.i的取值范围为[0,n],当i=n时,只需要在an-1的后面插入value即可;当0<=i<=n-1时,需要将an-1至ai顺序向后移动,为新元素让出位置,将值为value的元素放入空出的位序为i的位置,并修改表的长度。
时间复杂性O(n)
步骤:
(1)将第n 至第 i 位的元素向后移动一个位置;
(2)将要插入的元素写到第 i 个位置;
(3)表长加 1。
template <class elemType>
void seqList<elemType>::insert(int i, const elemType &value)
{
if (i < 0 || i > curLength) throw outOfRange(); // 合法的插入位置为[0..curLength]
if (curLength == maxSize) resize(); // 表满,扩大数组容量
for (int j = curLength;j > i;j--) {
data[j] = data[j - 1]; //下标在[curLength-1,i范围内的元素往后移动一步]
}
data[i] = value; //将值为value的元素放入到位序为i的位置
++curLength; //表的实际长度增1
}
注意:
(1)检测插入位置的有效性
(2)检查表空间是否已满
(3)最先移动的时表尾元素
删除运算
将位序i处的元素 ai 从线性表中删除。这删除使得 ai-1 , ai ,ai+1的逻辑关系发生了变化,表长由n变成n-1. i的取值范围为[0,n-1], 当i=n-1时,删除的是表尾元素,无需移动,要修改表长即可 ;当i<n-1时,删除元素ai需要将其后的元素 ai+1 至 an-1 顺序向前移动,并修改表的长度。
时间复杂性O(n)
步骤:
(1)将第i+1 至第 n 位的元素向前移动一个位置;
(2)表长减 1。
template <class elemType>
void seqList<elemType>::remove(int i)
{
if (i < 0 || i > curLength - 1) //合法的删除范围为[0...curLength-1]
throw outOfRange();
for (int j = i;j < curLength - 1;j++){
data[j] = data[j+1]; //下标在[i+1...curLength-1]范围内的元素往前移动一步
}
--curLength; //表的实际长度减1
}
注意:
(1)检测插入位置的有效性
(2)顺序表为空时不能做删除操作
(3)删除 ai 之后,该数据会被覆盖,若需要保留它的值,则先取出 ai ,再做删除操作。
其他
拷贝构造函数
时间复杂性O(n)
template <class elemType>
seqList<elemType>::seqList(seqList & sl) { //参数为指向元素类型的指针s1
maxSize = sl.maxSize;
curLength = sl. curLength;
data = new elemType[maxSize]; //在动态内存中为 data 成员变量分配了一段内存空间,可以存储 elemType 类型的元素
for (int i = 0; i < curLength; ++i)
data[i] = sl.data[i];
}
遍历函数
时间复杂性O(n)
template<class elemType>
void seqList<elemType>::traverse()const {
if(empty()) {
cout << "is empty" << endl; //空表没有元素
}
else {
cout << "output element:\n" << endl;
//关键代码
for (int i = 0;i < curLength;i++) //依次访问所有元素
cout << data[i] << " ";
cout << endl;
}
}
逆置运算
首尾对称交换,循环控制变量的终值是线性表的一半。时间复杂性O(n)
template<class elemType>
void seqList<elemType>::inverse() {
elemType tmp; //定义临时变量
for(int i = 0;i < curLength/2;i++) { //控制交换的次数
tmp = data[i];
data[i] = data[curLength-i-1];
data[curLength-i-1] = tmp;
}
}
扩大表空间
由于数组空间再内存中是连续的,要扩大只能重新申请一个更大规模的新数组,把原有的数组内容复制到新数组,释放原数组空间。时间复杂性O(n)
template <class elemType>
void seqList<elemType>::resize(){
elemType *p = data; // p指向原顺序表空间
maxSize *= 2; // 表空间扩大2倍
data = new elemType[maxSize]; // data指向新的表空间
for (int i = 0;i < curLength; ++i)
data[i] = p[i]; //复制元素
delete [] p;
}
单链表
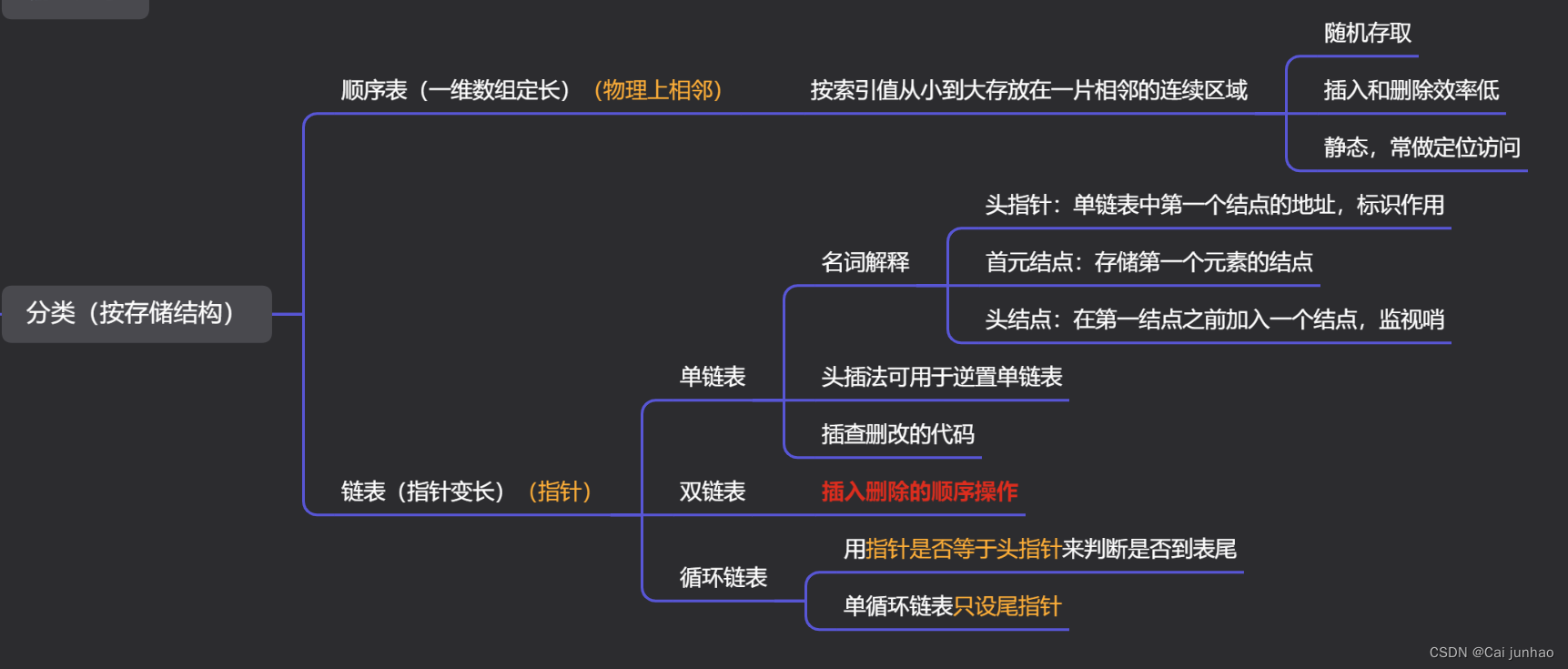
定义:链式结构最简单的一种,每个结点只包含一个指针,指向后继。
构成:数据域(元素的信息)+指针域(后继元素的存储地址)
名词解释:
(1)头指针:单链表中第一个结点的存储位置。
头指针具有标识一个链表的作用,故经常用头指针代表单链表的名字。
(2)空链表:头结点的直接后继为空。
(3)首元结点:存储第一个元素的结点
(4)头结点:在第一结点之前加入一个结点,用于监视哨或存放线性表的长度等附加信息
下面是单链表的类型定义:
#ifndef _LINKLIST_H_
#define _LINKLIST_H_
#include<stack>
#include "List.h"
template <class elemType> // elemType为单链表存储的元素类型
class linkList: public List<elemType> {
private:
struct Node {
public:
elemType data; // 结点的数据域
Node * next; // 结点的指针域,指向后继结点
Node(const elemType value, Node* p = NULL) { // 具有两个参数的Node构造函数
data = value;
next = p;
}
Node(Node* p = NULL) { // 具有一个参数的Node构造函数
next = p;
}
};
Node* head; // 单链表的头指针
Node* tail; // 单链表的尾
int curLength; // 单链表的当前长度
Node* getPosition(int i)const; // 返回指向单链表中第i个元素的指针
public:
linkList(); // 构造函数
~linkList(); // 析构函数
void clear(); // 将单链表清空,使之成为空表
bool empty()const{return head->next==NULL;} // 判空
int size()const{return curLength;}; // 返回单链表的当前实际长度
void insert(int i,const elemType &value); // 在位置i上插入一个元素value,表的长度增1
void remove(int i); // 删除位置i上的元素value,若删除位置合法,表的长度减1
int search(const elemType&value)const; // 查找值为value的元素第一次出现的位序
elemType visit(int i)const; // 访问位序为i的元素值,“位序”0表示第一个元素,类似于数组下标
void traverse()const; // 遍历单链表
void headCreate(); // “头插法”
void tailCreate(); // “尾插法”
void inverse(); // 逆置单链表
int prior(const elemType&value)const; // 查找值为value的元素的前驱
};
查找位序为i的结点的内存地址
合法的查找范围为[-1…curLength-1]。当i=0时,查找的是首元结点;当i=-1时,查找的是头结点;若i值非法,没有位序为i的结点,则返回NULL。
设一个移动指针p和计数器count,初始时p指向头结点,每当指针p移向下一个结点时,计数器count加1,直到p指向位序为i的结点位置,返回p。
时间复杂性O(n)
template <class elemType>
typename linkList<elemType> :: Node* linkList<elemType> :: getPosition(int i)const {
if (i < -1 ||i > curLength-1) //合法的查找范围为[-1...curLength-1]
return NULL; //i非法时,返回NULL
Node* p = head; //指针p指向头结点
int count = 0;
while (count <= i && p) {
p = p -> next;
count++;
}
return p; //返回位序为i的结点的指针
}
查找值为value的结点的位序
查找值为value的结点的位序,设置计数器count,从单链表的第一个结点起,判断当前结点的值是否等于给定值value,若查找成功,则返回结点的位序,否则继续查找直到单链表结束位置;若查找失败,则返回-1.
时间复杂性O(n)
template <class elemType>
int linkList<elemType> ::search(const elemType&value)const{
Node *p = head -> next; //指针p指向首元结点
int count = 0; //首元结点的位序为0
while (p != NULL && p -> data != value) {
p = p -> next;
count++;
}
if (p == NULL) return -1; //查找失败返回-1,这里-1并非头结点
else return count; //查找成功,count为结点的位序
}
插入结点
在位序i处插入值为value的新结点q。因为单链表中的结点只有一个指向后继的指针,因此需要先找到位序为i-1的结点p,让q的指针域指向p原来的后继,然后修改p的后继为q。
主要操作是移动指针寻找结点。
时间复杂度O(n)
template <class elemType>
void linkList<elemType> :: insert(int i,const elemType &value) {
Node *p,*q;
if (!(p = getPosition(i-1)))
throw outOfRang();
q->next=p->next;
p->next=q;
//上面两行也等价于下面三行
// p = getPosition(n-1);
// q = new Node(value,p -> next);
// p -> next = q; //q结点插到p结点的后面
if ( p ==tail ) //插入点在链表尾,则q成为新的尾结点
tail = q;
curLength++;
}
若将节点s插入到节点p和结点p->next之间,如下图所示,其核心操作是:
s->next=p->next;
p->next=s;
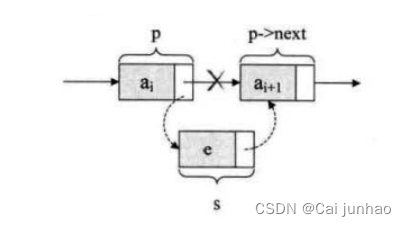
注意:不要因修改指针而使单链表断开,注意步骤顺序:
(1)添加插入结点的next (2)修改前一结点的next
删除结点
删除位序为i的结点,合法的删除范围为[0…curLength-1]
时间复杂度O(n)
template <class elemType>
void linkList<elemType>::remove(int i){
Node *p,*pre = getPosition(i-1);
if (pre == NULL || pre -> next == NULL)
throw outOfRang();
p = pre -> next;
if(p == tail){ //待删结点为尾结点,则修改尾指针
tail = pre;
pre->next;
delete p; //修改指针并删除结点p
}
else{
pre -> next = p -> next;
delete p;
}
curLength--;
}
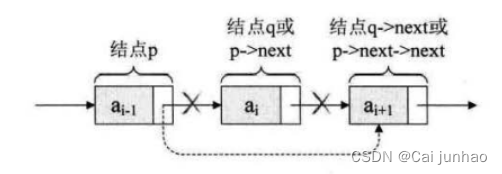
若删除结点q(即p->next),如下图所示,其核心操作是:
q = p -> next;
p ->next = q -> next;
free(q);
其他
构造函数:初始化单链表
申请一个新的结点作为头结点,只需其指针域置空
时间复杂度O(1)
template <class elemType>
linkList<elemType>::linkList(){
head = tail = new Node(); // 创建带有头结点的空表
curLength=0;
}
析构函数
时间复杂度O(n)
template <class elemType>
linkList<elemType>::~linkList(){
clear(); // 清空单链表
delete head; // 删除头结点
}
清空单链表
将工作指针从头结点一直移动到表尾,边移动指针边释放结点
时间复杂度O(n)
template <class elemType>
void linkList<elemType>::clear(){
Node* p,* tmp; //工作指针p指向首元结点
p = head -> next; //引入工作指针是为了防止随意修改头指针
while (p != NULL) {
tmp = p;
p = p -> next;
delete tmp;
}
head -> next = NULL; //头指针的指针域置空
tail - head; //头尾指针均指向头指针
curLength = 0;
}
求表长
若单链表中无定义curLength存储表长,则从第一个结点开始,一个结点一个结点地记数,直至表尾。
时间复杂性O(n)
template <class elemType>
int linkList<elemType>::size()const{
return curLength;
}
template <class elemType>
int linkList<elemType>::size()const{ //若单链表中无定义curLength存储表长
Node *p = head->next; //则从头遍历单链表
int count=0;
while(p){
count++;
p=p->next;
}
return count;
}
遍历单链表
时间复杂度O(n)
template <class elemType>
void linkList<elemType> ::traverse()const{
Node *p = head -> next; //工作指针p指向首元结点
while (p != NULL) {
cout << p -> data << " ";
p = p->next;
}
cout << endl;
}
查找值为value的结点的前驱的位序
设置两个指针p和pre,分别指向当前正在访问的结点和它的前驱,还要一个计数器count。我们从单链表的第一个结点开始遍历:
(1)若p==NULL,则查找值为value的结点失败,返回-1;
(2)若找到值为value的结点,且该结点是首元结点,则无前驱,返回-1;
(3)若找到值为value的结点,且该结点不是首元结点,则返回其前驱的位序。
时间复杂性O(n)
template <class elemType>
int linkList<elemType> ::prior(const elemType&value)const{
Node *p = head->next; //工作指针p指向首元结点
Node *pre = NULL; //pre指向p的前驱
int count = -1; //-1是首元结点无前驱
while(p && p->data !=value){
pre = p;
p = p->next;
count++;
}
if(p == NULL) return -1;
else return count;
}
头插法创建单链表
在链表的头部插入结点建立单链表,即每次将新增结点插在头结点之后、首元结点之前.
头插法可以用于逆置单链表。
时间复杂性O(n)
template <class elemType>
void linkList<elemType> :: headCreate(){
Node *p;
elemType value,flag;
cin>>flag; // 输入结束标志
while (cin >> value && value != flag) {
p = new Node(value,head -> next);
head -> next = p; //结点p插在头结点的后面
if(head==tail) //原链表为空,新结点p成为尾节点
tail = p;
curLength++;
}
尾插法创建单链表
在链表的尾部插入结点建立单链表,单链表类linkList中的尾指针tail将派上用场
时间复杂性O(n)
template <class elemType> // 尾插法创建链表
void linkList<elemType> ::tailCreate(){
Node *p;
elemType value,flag;
cin>>flag; // 输入结束标志
while (cin >> value && value != flag) {
p = new Node(value,NULL);
tail -> next = p; //结点p插在尾结点的后面
tail = p; //结点p成为新的尾结点
curLength++;
}
}
逆置单链表
利用头插法建立的单链表,其中元素的顺序与读入的元素的顺序是相反的。因此,用工作指针p依次访问单链表中的每个结点,每访问一个结点,就将它插在头结点的后面,然后向后移动工作指针p,直到所有结点都全部重新插入单链表中。
时间复杂性O(n)
template <class elemType> // 头插法逆置
void linkList<elemType> :: inverse(){
Node *p,*tmp;
p = head -> next; //工作指针p指向首元结点
head -> next = NULL; //头结点的指针域置空,构成空链表
if(p) tail = p; //逆置后,原首元结点将变成尾结点
while(p) {
tmp = p -> next; //暂存p的后继
p -> next = head -> next;
head -> next = p; //结点p插在头结点的后面
p = tmp; //继续处理下一个结点
}
}
双链表
定义:在单链表的每个结点中,再设置一个指向其前驱结点的指针域,使得链表可以双向查找。
构成:指针域(前驱元素的存储地址)+数据域(元素的信息)+指针域(后继元素的存储地址)

双向链表中,对于链表中的某一个结点p,它的后继的前驱以及它的前驱的后继都是它自己,即:
p->next-prior == p
p->prior-next == p
插入操作
在双链表中p所指的结点之后插入结点s,其指针的变化过程如下图所示:
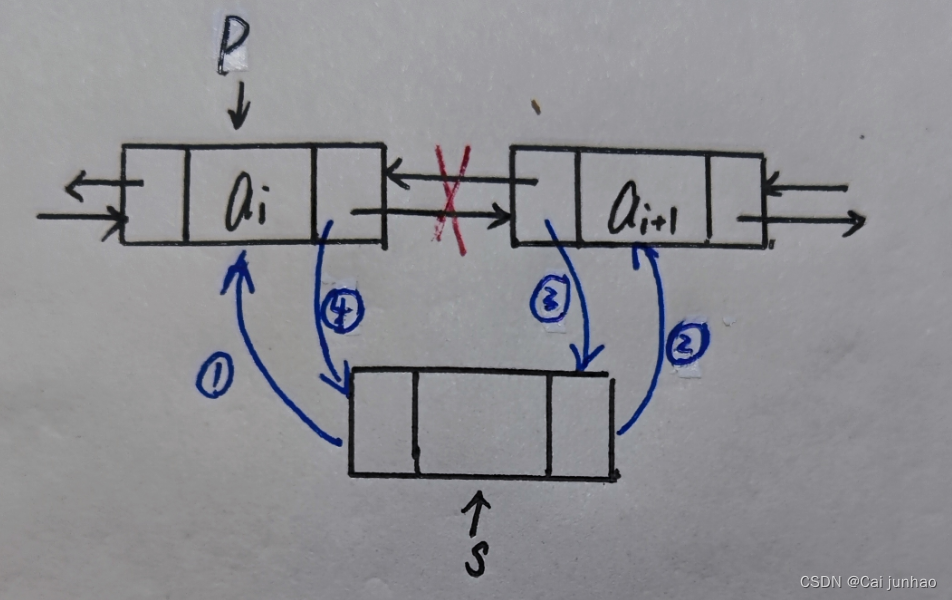
s->prior = p; //第一步:把p赋值给s的前驱
s->next = p->next; //第二步:把p->next赋值给s的后继
p->next->prior = s; //第三步:把s赋值给p->next的前驱
p->next = s; //第四步:把s赋值给p的后继
要注意这四条语句的顺序,语句③一定不能出现在语句①、②的前面,否则p的前驱就“断”了,找不到p原来的前驱。
删除操作
p指向双链表中某个结点,删除p所指的结点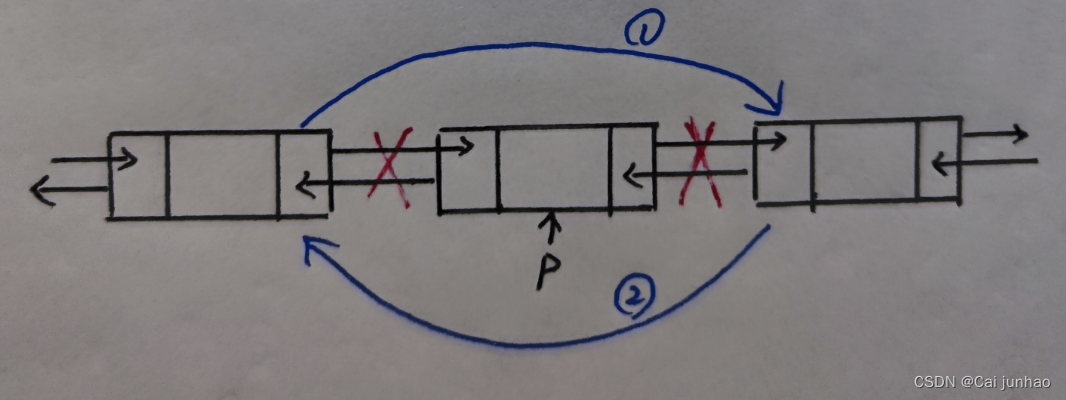
p->prior->next = p->next; //第一步
p->next->prior = p->prior; //第二步
free(q);
循环链表
单循环链表
定义:将单链表通过指针域首尾相接,即尾结点的指针域指向头结点
优点:从任意一个结点开始都可访问到其他结点。
单链表中,用指针是否为NULL来判断是否到表尾
单循环链表中,用指针是否等于头指针来判断是否到表尾。
单循环链表只设尾指针而不设头指针,用一个指向尾结点的尾指针来标识单循环链表。既方便查找尾结点又方便查找头结点,因为通过尾结点的指针域可以找到头结点。

为什么只设头指针的效率低于尾指针呢?
上述图为仅设头指针的循环链表,我们可以用O(1)的时间访问第一个节点,但对于最后一个节点,却需要O(n)的时间

合并两个单循环链表
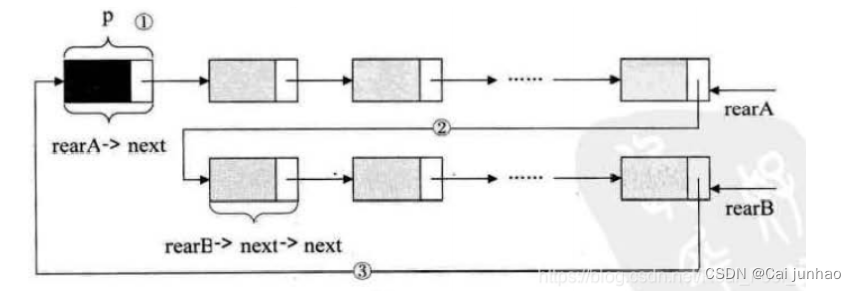
Q:下面的这两个循环链表,它们的尾指针分别是rearA和rearB,要将两个循环链表合成一个表。
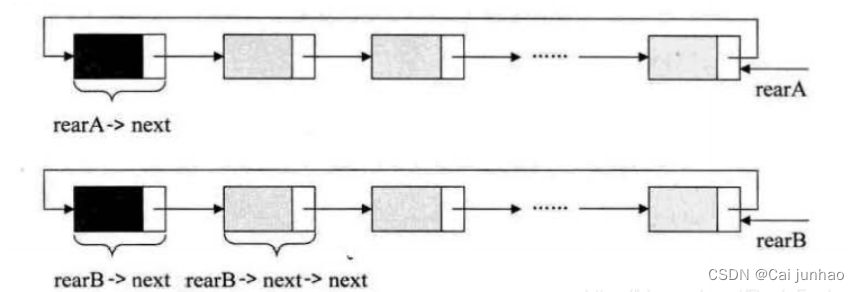
//第一步:保存A的头结点
p = rearA->next;
//第二步:将本是指向B表的第一个节点(不是头结点)赋值给rearA->next
rearA->next = rearB->next->next;
//第三步:将原A表的头结点赋值给rearB->next
rearB->next=p;
//释放p
free(p);
小结
-
线性表的逻辑结构,指线性表的数据元素间存在着线性关系。在顺序存储结构中,元素存储的先后位置反映出这种线性关系,而在链式存储结构中,是靠指针来反映这种关系的。
-
顺序存储结构用一维数组表示,给定下标,可以存取相应元素,属于随机存取的存储结构。
-
链表操作中应注意不要使链意外“断开”。因此,若在某结点前插入一个元素,或删除某元素,必须知道该元素的前驱结点的指针。
-
掌握通过画出结点图来进行链表(单链表、循环链表等)的生成、插入、删除、遍历等操作。
-
在单链表中,除了首元结点外,任一结点的存储位置由 其直接前驱结点的链域的值 指示。
-
sizeof(x): 计算变量 x 的长度(字节数);
malloc(m):开辟 m 字节长度的地址空间,并返回这段空间的首地址;
free(p):释放指针 p 所指变量的存储空间,即彻底删除一个变量。 -
顺序存储和链式存储的区别和优缺点?
| 顺序存储 | 链式存储 | |
|---|---|---|
| 优点 | 存储密度大,存储空间利用率高 | 插入或删除元素时很方便,使用灵活。 |
| 缺点 | 插入或删除元素时不方便 | 缺点是存储密度小,存储空间利用率低。 |
| 存储特点 | 逻辑上相邻的数据元素,其物理存放地址也相邻 | 相邻数据元素可随意存放,但所占存储空间分两部分,一部分存放结点值, 另一部分存放表示结点间关系的指针 |
| 应用范围 | 适宜于做查找这样的静态操作 | 宜于做插入、删除这样的动态操作 |
408真题
1. [2010年全国统一考试] 将n(n>1)个整数存放到一维数组R中。设计一个算法,将R中保存的序列循环左移p(p>0且q<n)个位置,即将R中的数据由(X0,X1…Xp-1,Xp,Xp+1…Xn-1)变换为(Xp,Xp+1…Xn-1,X0,X1…Xp-1)
题目分析:采用顺序表的逆置。数字大小为n,将下标分为[0…p-1]和[p…n-1]两个区间分别逆置,然后再对整个数组区间[0…n-1]进行整体逆置。
void leftShift(int R[],int p,int n){
int t,i;
for(i=0;i<p/2;i++){ //逆置[0...p-1]
t = R[i];
R[i] = R[p-1-i];
R[p-1-i] = t;
}
for(i=p;i<(n+p)/2;i++){ //逆置[p...n-1]
t = R[i];
R[i] = R[n-1-i+p];
R[n-1-i+p] = t;
}
for(i=0;i<n/2;i++){ //逆置[0...n-1]
t = R[i];
R[i] = R[n-1-i];
R[n-1-i] = t;
}
}
2.[2000年北京航空航天大学] 长度为n的线性表A采用顺序存储结构,写一个时间复杂度为O(n)、空间复杂度为O(1)的算法,删除线性表中所有值为item的元素。
题目分析:用两个指针i,j,i和j相向移动,其中i从小下标向大下标移动查找值为value的元素,j从大下标向小下标移动查找值不为value的元素,用下标为j的元素覆盖下标为i(值为item)的元素,重复此过程。
template <class elemType>
void seqList<elemType> ::delEqualItem(elemType item){
int i=0, j=curLength-1;
while(i<=j){
while(i<=j && data[i]!=item) i++; //若值不为item,则指针右移
while(i<=j && data[j]==item) j--; //若值为item,则指针左移
if(i<j)
data[i++]=data[j--];
}
curLength = i;
}
题目分析:可采用顺序表的遍历。设置两个指针,一个遍历所有元素,一个重新保存值不等于item的元素。
template <class elemType>
void seqList<elemType> ::delEqualItem2(elemType item){
int i=0; //重新保存顺序表,只保存非item值
int j=0; //遍历整个顺序表
while(j<curLength)
if(data[i]==item) j++: //值为item的元素跳过
else data[i++]=data[j++]; //值不等于item的元素保存
curLength = i;
}
3. [2009年全国统一考试 ]一个带有头结点的单链表,结点结构为(data,link),假设链表只给出头指针list.在不该改变链表的前提下,查找链表中倒数第k个位置上的结点(k为正整数),若查找成功,则输出该结点的data域的值并返回1;否则,返回0.
题目分析:遍历操作.第一次遍历得出整个链表的长度n,第二次遍历找到倒数第k格结点(即正数第n-k+1个结点).
int findKthFromEnd(Node* list, int k) {
if (list == nullptr || k <= 0) {
return 0;
}
Node* current = list;
int length = 0;
// 第一次遍历得出整个链表的长度n
while (current != nullptr) {
length++;
current = current->link;
}
// 找到倒数第k个结点
if (k > length) {
return 0; // 如果k大于链表长度,则返回0
}
current = list;
for (int i = 1; i < length - k + 1; i++) {
current = current->link;
}
std::cout << "The data at the " << k << "th node from the end is: " << current->data << std::endl;
return 1;
}
题目分析:设两个指针p,q用于遍历链表,指针q不动,指针p先向后移动k个结点,然后p和q一起移动,它们之间的距离保持在k.当指针p遍历完链表时,指针q刚好停留在倒数第k个结点上.
int searchInvK(int k){
int i=1;
Node *p,*q;
p = list->link; //p指向当前待处理的结点,遍历整个链表
q = list; //若查找成功,则q指向倒数第k个结点
while(p && i<k){ //查找正数第k个结点
i++;
p=p->next;
}
if(p==NULL){ //正数第k个结点不存在,即倒数第k个结点也不存在
cout<<"不存在\n";
return 0;
}
while(p){ //p,q指针一起向后移动
q=q->link;
p=p->link;
}
cout<<"倒数第k个结点的data域:"<<q->data<<endl;
return 1;
}
参考资料
- 数据结构:线性表(List)【详解】
- 冯广惠.吴昊.文全刚 编著《算法与数据结构C++语言版》
















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









