






一、前馈网络
前馈网络(Feedforward Network),也称为前馈神经网络(Feedforward Neural Network,简称FNN),是人工神经网络的一种。其特点在于每一层的输出信号只能作为下一层的输入信号,而不能作为当前或之前层的输入信号。也就是说,整个网络中的信息是从输入层到输出层单向传播的,没有反馈连接。
前馈网络的结构通常包括输入层、隐藏层和输出层。输入层的节点数与问题的输入特征数量相对应,输出层的节点数与问题的输出类别相对应。隐藏层的数量和每层的节点数量可以根据问题的复杂性和训练数据的特性进行调整。
在前馈网络中,信息流动的过程可以分为以下几个步骤:
- 输入层接收外部输入的数据,并将其传递给下一层。
- 隐层是网络中位于输入层和输出层之间的一层或多层,负责对输入数据进行非线性变换和特征提取。
- 输出层接收隐层的输出,并将最终的结果输出。
在前馈神经网络的每个神经元中,输入信号和对应的权重进行加权求和,然后经过激活函数进行非线性变换。这样,通过多层神经元的传递,网络可以学习到输入数据的复杂特征,并最终输出相应的结果。
前馈神经网络是应用最广泛、发展最迅速的人工神经网络之一。其研究和应用始于20世纪60年代,并在理论研究和实际应用中都达到了很高的水平。
二、实验介绍
1. 实验内容
在实验3中,我们通过观察感知器来介绍神经网络的基础,感知器是现存最简单的神经网络。感知器的一个历史性的缺点是它不能学习数据中存在的一些非常重要的模式。例如,查看图4-1中绘制的数据点。这相当于非此即彼(XOR)的情况,在这种情况下,决策边界不能是一条直线(也称为线性可分)。在这个例子中,感知器失败了。

在这一实验中,我们将探索传统上称为前馈网络的神经网络模型,以及两种前馈神经网络:多层感知器和卷积神经网络。多层感知器在结构上扩展了我们在实验3中研究的简单感知器,将多个感知器分组在一个单层,并将多个层叠加在一起。我们稍后将介绍多层感知器,并在“示例:带有多层感知器的姓氏分类”中展示它们在多层分类中的应用。
本实验研究的第二种前馈神经网络,卷积神经网络,在处理数字信号时深受窗口滤波器的启发。通过这种窗口特性,卷积神经网络能够在输入中学习局部化模式,这不仅使其成为计算机视觉的主轴,而且是检测单词和句子等序列数据中的子结构的理想候选。我们在“卷积神经网络”中概述了卷积神经网络,并在“示例:使用CNN对姓氏进行分类”中演示了它们的使用。
在本实验中,多层感知器和卷积神经网络被分组在一起,因为它们都是前馈神经网络,并且与另一类神经网络——递归神经网络(RNNs)形成对比,递归神经网络(RNNs)允许反馈(或循环),这样每次计算都可以从之前的计算中获得信息。在实验6和实验7中,我们将介绍RNNs以及为什么允许网络结构中的循环是有益的。
在我们介绍这些不同的模型时,需要理解事物如何工作的一个有用方法是在计算数据张量时注意它们的大小和形状。每种类型的神经网络层对它所计算的数据张量的大小和形状都有特定的影响,理解这种影响可以极大地有助于对这些模型的深入理解。
2.实验目的
- 掌握MLP的基本结构和工作原理:通过构建一个简单的MLP模型,并使用其进行特定的NLP任务(如姓氏分类、情感分析等),来理解和掌握MLP的基本结构和工作原理。
- 探究正则化技术的影响:实现并研究如Dropout等正则化技术,观察这些技术对MLP模型性能的影响,并分析其在不同训练阶段的作用。
- 验证优化技术的效果:实验可能还包括对模型训练速度和收敛性的优化,如通过批处理标准化(BatchNorm)等技术来加速模型训练和提高模型稳定性。
- 探讨模型在其他NLP任务中的应用:除了姓氏分类任务,实验还可能探究MLP模型在其他NLP任务(如语言模型构建、序列标注、机器翻译等)中的应用和效果。
3. 实验要点
- 通过“示例:带有多层感知器的姓氏分类”,掌握多层感知器在多层分类中的应用
- 掌握每种类型的神经网络层对它所计算的数据张量的大小和形状的影响
4.实验环境
- Python 3.6.7
三、The Multilayer Perceptron(多层感知器)
多层感知器(MLP)被认为是最基本的神经网络构建模块之一。最简单的MLP是对第3章感知器的扩展。感知器将数据向量作为输入,计算出一个输出值。在MLP中,许多感知器被分组,以便单个层的输出是一个新的向量,而不是单个输出值。在PyTorch中,正如您稍后将看到的,这只需设置线性层中的输出特性的数量即可完成。MLP的另一个方面是,它将多个层与每个层之间的非线性结合在一起。
最简单的MLP,如图4-2所示,由三个表示阶段和两个线性层组成。第一阶段是输入向量。这是给定给模型的向量。在“示例:对餐馆评论的情绪进行分类”中,输入向量是Yelp评论的一个收缩的one-hot表示。给定输入向量,第一个线性层计算一个隐藏向量——表示的第二阶段。隐藏向量之所以这样被调用,是因为它是位于输入和输出之间的层的输出。我们所说的“层的输出”是什么意思?理解这个的一种方法是隐藏向量中的值是组成该层的不同感知器的输出。使用这个隐藏的向量,第二个线性层计算一个输出向量。在像Yelp评论分类这样的二进制任务中,输出向量仍然可以是1。在多类设置中,将在本实验后面的“示例:带有多层感知器的姓氏分类”一节中看到,输出向量是类数量的大小。虽然在这个例子中,我们只展示了一个隐藏的向量,但是有可能有多个中间阶段,每个阶段产生自己的隐藏向量。最终的隐藏向量总是通过线性层和非线性的组合映射到输出向量。
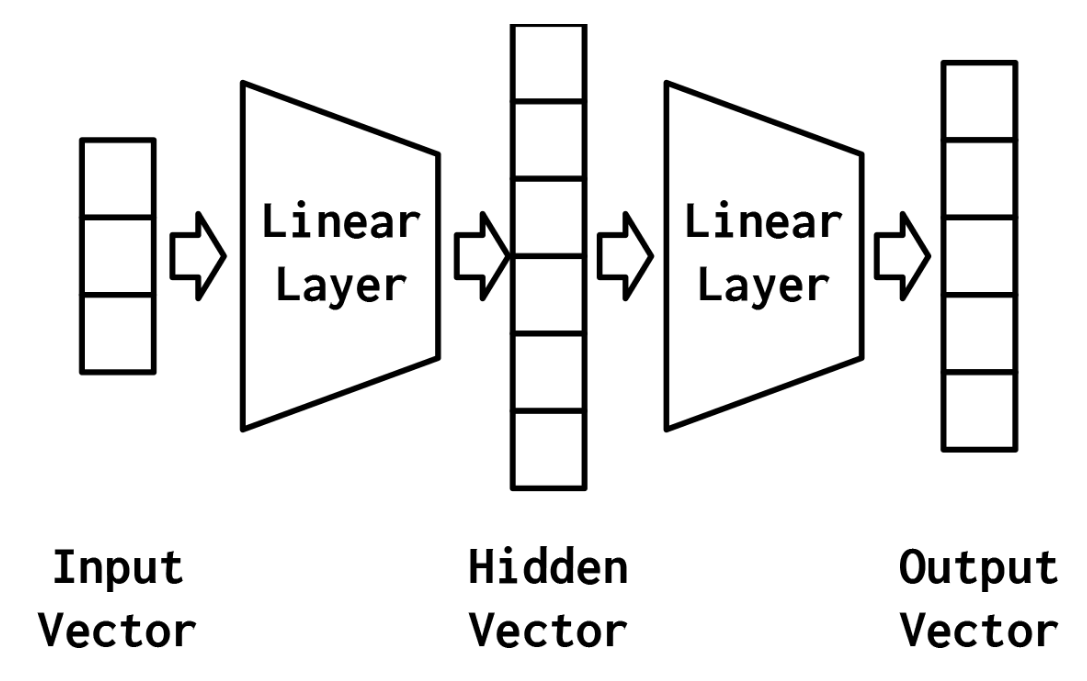
mlp的力量来自于添加第二个线性层和允许模型学习一个线性分割的的中间表示——该属性的能表示一个直线(或更一般的,一个超平面)可以用来区分数据点落在线(或超平面)的哪一边的。学习具有特定属性的中间表示,如分类任务是线性可分的,这是使用神经网络的最深刻后果之一,也是其建模能力的精髓。在下一节中,我们将更深入地研究这意味着什么。
2.1 A Simple Example: XOR
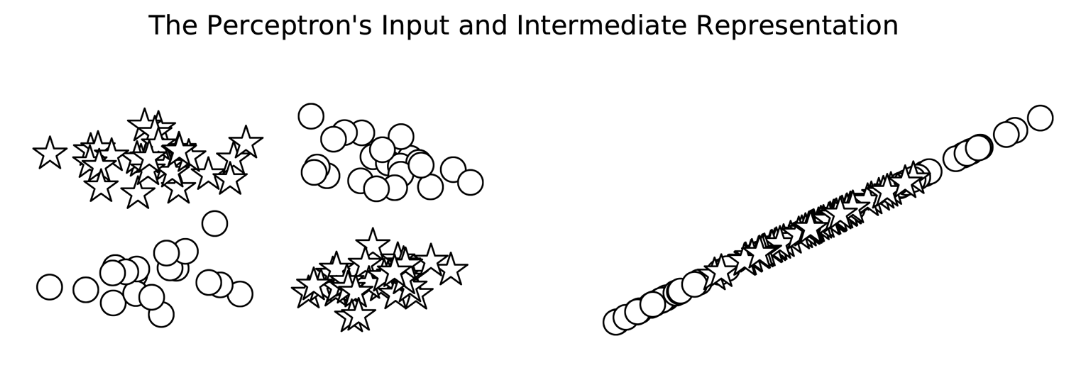
让我们看一下前面描述的XOR示例,看看感知器与MLP之间会发生什么。在这个例子中,我们在一个二元分类任务中训练感知器和MLP:星和圆。每个数据点是一个二维坐标。在不深入研究实现细节的情况下,最终的模型预测如图4-3所示。在这个图中,错误分类的数据点用黑色填充,而正确分类的数据点没有填充。在左边的面板中,从填充的形状可以看出,感知器在学习一个可以将星星和圆分开的决策边界方面有困难。然而,MLP(右面板)学习了一个更精确地对恒星和圆进行分类的决策边界。

图4-3中,每个数据点的真正类是该点的形状:星形或圆形。错误的分类用块填充,正确的分类没有填充。这些线是每个模型的决策边界。在边的面板中,感知器学习—个不能正确地将圆与星分开的决策边界。事实上,没有一条线可以。在右动的面板中,MLP学会了从圆中分离星。
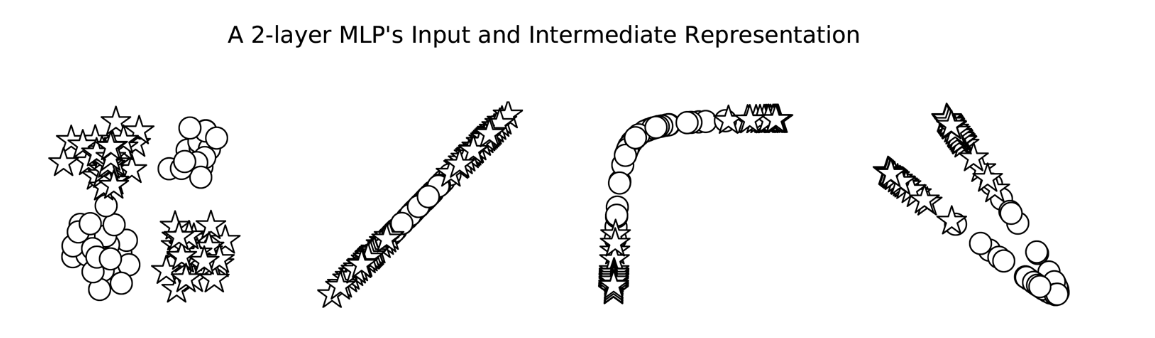
虽然在图中显示MLP有两个决策边界,这是它的优点,但它实际上只是一个决策边界!决策边界就是这样出现的,因为中间表示法改变了空间,使一个超平面同时出现在这两个位置上。在图4-4中,我们可以看到MLP计算的中间值。这些点的形状表示类(星形或圆形)。我们所看到的是,神经网络(本例中为MLP)已经学会了“扭曲”数据所处的空间,以便在数据通过最后一层时,用一线来分割它们。
相反,如图4-5所示,感知器没有额外的一层来处理数据的形状,直到数据变成线性可分的。
2.2 Implementing MLPs in PyTorch
在上一节中,我们概述了MLP的核心思想。在本节中,我们将介绍PyTorch中的一个实现。如前所述,MLP除了实验3中简单的感知器之外,还有一个额外的计算层。在我们在例4-1中给出的实现中,我们用PyTorch的两个线性模块实例化了这个想法。线性对象被命名为fc1和fc2,它们遵循一个通用约定,即将线性模块称为“完全连接层”,简称为“fc层”。除了这两个线性层外,还有一个修正的线性单元(ReLU)非线性(在实验3“激活函数”一节中介绍),它在被输入到第二个线性层之前应用于第一个线性层的输出。由于层的顺序性,必须确保层中的输出数量等于下一层的输入数量。使用两个线性层之间的非线性是必要的,因为没有它,两个线性层在数学上等价于一个线性层4,因此不能建模复杂的模式。MLP的实现只实现反向传播的前向传递。这是因为PyTorch根据模型的定义和向前传递的实现,自动计算出如何进行向后传递和梯度更新。
四、部分代码及结果
import torch.nn as nn
import torch.nn.functional as F
class MultilayerPerceptron(nn.Module):
def __init__(self, input_dim, hidden_dim, output_dim):
"""
Args:
input_dim (int): 输入向量的维度
hidden_dim (int): 第一个线性层的输出维度(隐藏层的维度)
output_dim (int): 第二个线性层的输出维度(输出层的维度)
"""
super(MultilayerPerceptron, self).__init__()
self.fc1 = nn.Linear(input_dim, hidden_dim)
self.fc2 = nn.Linear(hidden_dim, output_dim)
def forward(self, x_in, apply_softmax=False): # 定义前向传播方法
intermediate = F.relu(self.fc1(x_in)) # 通过第一个线性层并应用ReLU激活函数
output = self.fc2(intermediate) # 通过第二个线性层
if apply_softmax: # 如果需要应用Softmax激活函数
output = F.softmax(output, dim=1) # 在第二个维度上对输出张量应用Softmax函数
return output # 返回输出张量
在例4-2中,我们实例化了MLP。由于MLP实现的通用性,可以为任何大小的输入建模。为了演示,我们使用大小为3的输入维度、大小为4的输出维度和大小为100的隐藏维度。请注意,在print语句的输出中,每个层中的单元数很好地排列在一起,以便为维度3的输入生成维度4的输出。
batch_size = 2 # number of samples input at once
input_dim = 3
hidden_dim = 100
output_dim = 4
# Initialize model
mlp = MultilayerPerceptron(input_dim, hidden_dim, output_dim)
print(mlp)
MultilayerPerceptron(
(fc1): Linear(in_features=3, out_features=100, bias=True)
(fc2): Linear(in_features=100, out_features=4, bias=True)
)
我们可以通过传递一些随机输入来快速测试模型的“连接”,如示例4-3所示。因为模型还没有经过训练,所以输出是随机的。在花费时间训练模型之前,这样做是一个有用的完整性检查。请注意PyTorch的交互性是如何让我们在开发过程中实时完成所有这些工作的,这与使用NumPy或panda没有太大区别:
import torch
def describe(x):
print("Type: {}".format(x.type()))
print("Shape/size: {}".format(x.shape))
print("Values: \n{}".format(x))
x_input = torch.rand(batch_size, input_dim)
describe(x_input)
Type: torch.FloatTensor
Shape/size: torch.Size([2, 3])
Values:
tensor([[0.8329, 0.4277, 0.4363],
[0.9686, 0.6316, 0.8494]])
上述代码运行结果:
Type: torch.FloatTensor
Shape/size: torch.Size([2, 3])
Values:
tensor([[0.6193, 0.7045, 0.7812],
[0.6345, 0.4476, 0.9909]])y_output = mlp(x_input, apply_softmax=False)
describe(y_output)
Type: torch.FloatTensor
Shape/size: torch.Size([2, 4])
Values:
tensor([[-0.2456, 0.0723, 0.1589, -0.3294],
[-0.3497, 0.0828, 0.3391, -0.4271]], grad_fn=<AddmmBackward>)
上述代码运行结果:
Type: torch.FloatTensor
Shape/size: torch.Size([2, 4])
Values:
tensor([[ 0.2356, 0.0983, -0.0111, -0.0156],
[ 0.1604, 0.1586, -0.0642, 0.0010]], grad_fn=<AddmmBackward>)学习如何读取PyTorch模型的输入和输出非常重要。在前面的例子中,MLP模型的输出是一个有两行四列的张量。这个张量中的行与批处理维数对应,批处理维数是小批处理中的数据点的数量。列是每个数据点的最终特征向量。在某些情况下,例如在分类设置中,特征向量是一个预测向量。名称为“预测向量”表示它对应于一个概率分布。预测向量会发生什么取决于我们当前是在进行训练还是在执行推理。在训练期间,输出按原样使用,带有一个损失函数和目标类标签的表示。我们将在“示例:带有多层感知器的姓氏分类”中对此进行深入介绍。
但是,如果想将预测向量转换为概率,则需要额外的步骤。具体来说,需要softmax函数,它用于将一个值向量转换为概率。softmax有许多根。在物理学中,它被称为玻尔兹曼或吉布斯分布;在统计学中,它是多项式逻辑回归;在自然语言处理(NLP)社区,它是最大熵(MaxEnt)分类器。不管叫什么名字,这个函数背后的直觉是,大的正值会导致更高的概率,小的负值会导致更小的概率。在示例4-3中,apply_softmax参数应用了这个额外的步骤。在例4-4中,可以看到相同的输出,但是这次将apply_softmax标志设置为True:
y_output = mlp(x_input, apply_softmax=True)
describe(y_output)
Type: torch.FloatTensor
Shape/size: torch.Size([2, 4])
Values:
tensor([[0.2087, 0.2868, 0.3127, 0.1919],
[0.1832, 0.2824, 0.3649, 0.1696]], grad_fn=<SoftmaxBackward>)
上述代码运行结果:
Type: torch.FloatTensor
Shape/size: torch.Size([2, 4])
Values:
tensor([[0.2915, 0.2541, 0.2277, 0.2267],
[0.2740, 0.2735, 0.2189, 0.2336]], grad_fn=<SoftmaxBackward>)综上所述,mlp是将张量映射到其他张量的线性层。在每一对线性层之间使用非线性来打破线性关系,并允许模型扭曲向量空间。在分类设置中,这种扭曲应该导致类之间的线性可分性。另外,可以使用softmax函数将MLP输出解释为概率,但是不应该将softmax与特定的损失函数一起使用,因为底层实现可以利用高级数学/计算捷径。
五、实验小结
1.总结
- 前馈神经网络在处理自然语言文本方面具有较强的学习能力,可以通过增加网络深度和宽度来提高模型性能。但是,过深的网络结构可能导致过拟合现象的发生,因此需要在设计模型时关注模型的泛化能力。
- 正则化技术是防止过拟合的有效手段之一。在本次实验中,Dropout技术被证明是一种有效的正则化方法,能够显著提高模型的泛化能力。
- 优化技术对于提高模型训练速度和稳定性具有重要作用。在本次实验中,批处理标准化技术被证明是一种有效的优化方法,能够显著缩短模型训练时间并使模型在训练过程中更加稳定。
2.实验意义与展望
本次实验通过构建和训练前馈神经网络模型,探索了其在自然语言处理任务中的应用效果,并深入理解了FNN的工作原理和优化方法。实验结果表明,前馈神经网络在处理自然语言文本方面具有较强的学习能力,并可以通过正则化和优化技术来提高模型的泛化能力和训练效率。这为后续研究提供了有益的参考和启示。
展望未来,我们可以进一步探索其他类型的神经网络在自然语言处理任务中的应用,如循环神经网络(RNN)、卷积神经网络(CNN)和Transformer等。同时,我们也可以关注多模态数据融合等研究方向,以进一步提高自然语言处理任务的性能和效果。















 661
661











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









