






目录
往期推荐
- ETAS工具链自动化实战指南<一>
- ETAS工具链自动化实战指南<二>
- ETAS工具链自动化实战指南<三>
- AUTOSAR工程师必读:Artop的核心功能
- Vector工具链自动化实战指南<一>
- isolar高手秘籍| ECU Configuration三分钟速成!
- 掌握核心步骤:RTA-BSW以太网配置全解析
- 一文详解TC399 CAN MCAL 配置
- LSL常见应用场景及示例<一>
- LSL常见应用场景及示例<二>
- LSL常见应用场景及示例<三>
- 为什么Autosar钟情arxml而非json?大揭秘!
MEMMAP 文件(Memory Map File)是嵌入式软件开发中的一种文件,主要用于定义和管理内存分配和布局。它在汽车电子、嵌入式系统和AUTOSAR开发中非常重要,以下是对MEMMAP文件的详细介绍,包括其定义、必要性和使用方法。
什么是 MEMMAP 文件?
在资源受限的环境中,如嵌入式控制单元(ECU),最大限度地挖掘硬件资源的潜力并高效利用它们是至关重要的。特别是在内存方面,虽然我们渴望拥有无限的内存空间,但这样的成本是难以承受的。随着安全需求的不断增长,Autosar 开发人员必须严格控制内存分配。正是在这样的背景下,MemMap 应运而生,为解决这一挑战提供了创新的解决方案。
MEMMAP 文件是一个文本文件,包含有关内存区域和内存分配的信息。它通常定义了不同类型的内存(如RAM、ROM、Flash等)的分区,描述变量、函数和数据结构在内存中的具体位置。这些信息对于编译器和链接器至关重要,确保软件能够正确地映射到可用的内存空间。
MEMMAP文件通常包含以下几类信息:
-
内存布局:
-
描述不同内存区域(如RAM、ROM、Flash等)的分配情况,包括每个区域的起始地址和大小。
-
-
段信息:
-
定义特定功能模块或数据结构的内存段,例如代码段、数据段和堆栈段。
-
-
符号定义:
-
提供内存中使用的符号的名称和地址,便于编译器和链接器识别。
-
-
配置参数:
-
包括与内存相关的配置参数,如对齐要求、访问权限等。
-
为什么需要 MEMMAP 文件?
MEMMAP 文件的必要性体现在以下几个方面:
-
内存管理:提供明确的内存布局,帮助开发者高效管理内存资源,避免内存冲突和重叠。
-
性能优化:通过指定代码和数据在内存中的确切位置,优化程序访问速度,提高系统性能。
-
模块化设计:支持模块化软件架构,使得不同模块可以独立开发和集成,简化系统的复杂性。
-
兼容性:确保在不同硬件平台和不同版本之间的代码兼容性,促进软件的移植性。
-
安全性:通过定义内存区域,可以为敏感数据和功能提供保护,增强系统安全性。
MEMMAP应用阶段
MEMMAP文件通常在以下阶段使用:
-
设计阶段:
-
在系统架构设计时,开发团队可以定义内存映射,以确保不同组件和模块的内存布局合理。
-
-
编译阶段:
-
编译器和链接器使用MEMMAP文件中的信息来生成可执行文件,确保代码和数据按照定义的内存布局存放。
-
-
测试阶段:
-
在进行HIL(硬件在环)测试或其他类型的测试时,MEMMAP文件可以帮助验证系统的内存使用情况,确保在实际硬件上运行时的表现符合预期。
-
-
维护和优化阶段:
-
在软件维护和优化时,开发者可以参考MEMMAP文件来识别和解决内存使用效率的问题。
-
如何使用 MEMMAP 文件?

使用 MEMMAP 文件的步骤通常包括以下几个方面:
-
创建 MEMMAP 文件:
-
开发者根据系统需求定义内存布局,创建一个MEMMAP文件,指定内存区域的起始地址、大小以及各个变量和函数的分配。
-
-
集成到开发环境:
-
将 MEMMAP 文件集成到开发环境中,确保编译器和链接器能够读取和使用这些信息。通常,开发者会在项目配置中指定 MEMMAP 文件的路径。
-
-
编译和链接:
-
在编译和链接过程中,编译器和链接器会根据 MEMMAP 文件中的定义,将代码和数据正确地映射到指定的内存区域,生成可执行文件。
-
-
测试和验证:
-
在测试阶段,可以使用 MEMMAP 文件的信息来验证内存的使用情况,确保在实际硬件上运行时系统的行为符合预期。
-
-
维护和优化:
-
在软件维护和优化过程中,开发者可以参考 MEMMAP 文件来识别内存使用效率的问题,调整内存布局以提高性能。
-
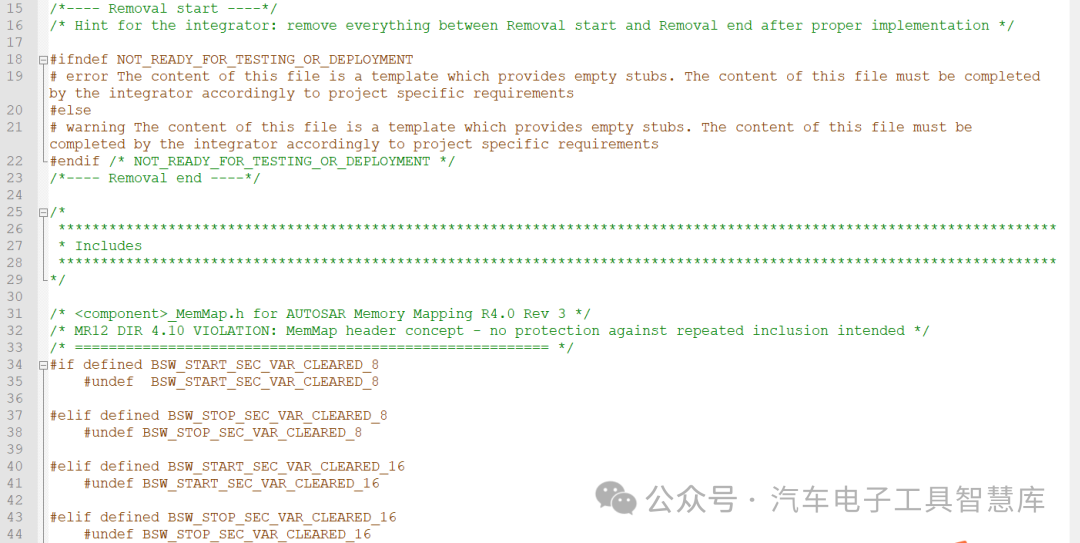
MEMMAP 语法及关键字
为了充分利用 ECU 的内存布局,Autosar 包含 MemMap(内存映射)模块,它 是一个 BSW 模块,参与了进入 ECU 的所有代码(无论是否生成)。其主要目的是将代码和数据映射到特定的内存部分。
首先,让我们看一下语法,部分通常定义如下:
<MODULE>_<START/STOP>_SEC_<TYPE>[_<INIT_POLICY>][_<ALIGNMENT>]上述结构可能会有一些细微的变化。例如,在某些类型中,我们可以指定 ASIL(安全)级别或核心范围。
MODULE
- Autosar 模块的名称,Autosar 代码生成器会从提供的 Arxml 文件中获取该名称。其中还应包含代码使用的所有部分,因为这些部分是为每个模块的 _memmap.h 文件生成的。
START/STOP
-所有 START_SECTION 后面都必须跟着 STOP_SECTION。否则,可能会出现未定义的错误,可能会导致无数小时的调试,所以要小心。
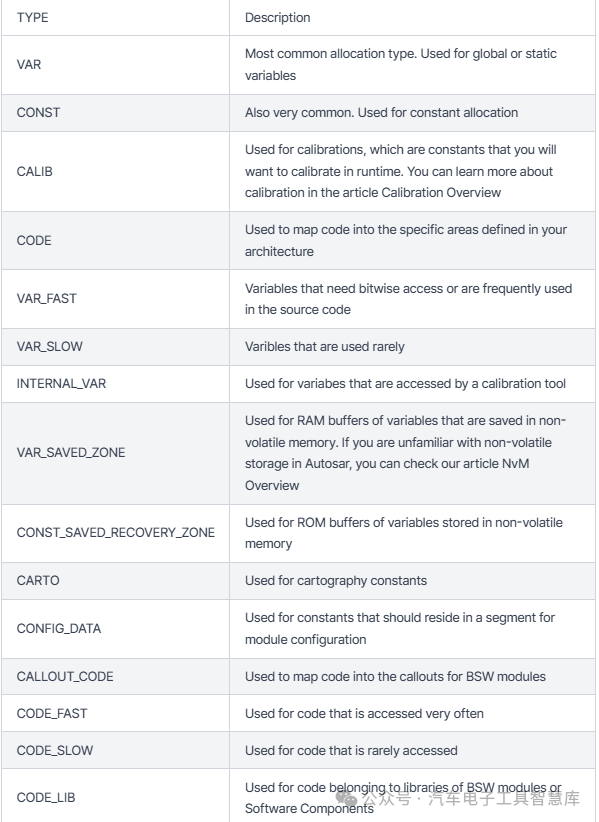
TYPE
-根据在 MemMap 中定义的 TYPE(以及必须考虑的类型限定符,因为它们在链接器决定将变量分配到何处时提供了变量应放置位置的微妙提示 - const、restrict、volatile 等),变量将被放入特定部分。Autosar 分层架构中定义的 TYPE 如下,但也可以根据内存布局和应用程序需求创建自己的自定义 TYPE:
INIT_POLICY
-虽然是可选的,但此参数可以将变量变成更安全、更可预测的东西。建议谨慎使用初始化策略,并且只有在确切知道需要它的原因时才使用。尽管如此,初始化策略可以被视为功能安全的一部分,因为它的使用通常旨在每次打开 ECU 时使其范围内的变量处于可预测和安全的状态。可用的 INIT_POLICYes 有:

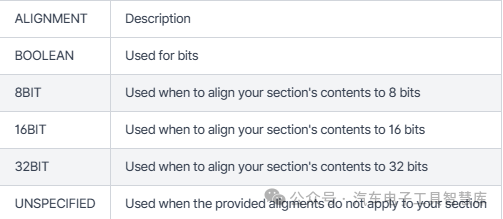
ALIGNMENT
-最后,我们有可选的对齐。如果内存不足,这很有用,因为可以优化内存空间中的那些片段并将所有相同大小的变量放在一起。因此,我们可以确保高效使用内存,而不会浪费任何资源来填充空白字节。可能的对齐方式包括:
示例
#define MEMMAP_ERROR
#ifdef EEP_START_SEC_VAR_16BIT
#undef EEP_START_SEC_VAR_16BIT
#define START_SEC_DATA_16BIT
#elif
#ifdef START_SEC_DATA_16BIT
#pragma section data "sect_data16"
#undef START_SEC_DATA_16BIT
#undef MEMMAP_ERROR
#endif
#ifdef STOP_SEC_VAR_16BIT
#undef STOP_SEC_VAR_16BIT
#undef MEMMAP_ERROR
#elif
#ifdef STOP_SEC_DATA_16BIT
#pragma section data "sect_data16" restore
#undef STOP_SEC_DATA_16BIT
#undef MEMMAP_ERROR
#elif
#ifdef MEMMAP_ERROR
#error "MemMap.h, wrong pragma command or section does not exist"
#endif 总结
MEMMAP 文件在嵌入式软件开发中至关重要,提供了清晰的内存分配和结构定义,帮助开发团队高效管理内存资源。通过合理使用 MEMMAP 文件,开发者能够优化软件性能,确保系统的可靠性和安全性。


















 2566
2566

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









