







这里写目录标题
1、RabbitMQ 干啥的?
RabbitMQ:一种异步调用技术、解决同步调用的拓展性差、性能下降、级联失败等问题
异步调用有别于同步调用。
异步调用方式其实就是基于消息通知的方式,一般包含三个角色:
- 消息发送者:投递消息的人,就是原来的调用方。
- 消息Broker:管理、暂存、转发消息,你可以把它理解成微信服务器。
- 消息接收者:接收和处理消息的人,就是原来的服务提供方。
异步调用的优势包括:
- 耦合度更低
- 性能更好
- 业务拓展性强
- 故障隔离,避免级联失败
缺点:
- 完全依赖于 Broker 的可靠性、安全性和性能
- 架构复杂,后期维护和调试麻烦
RabbitMQ是国内使用最多的消息队列框架
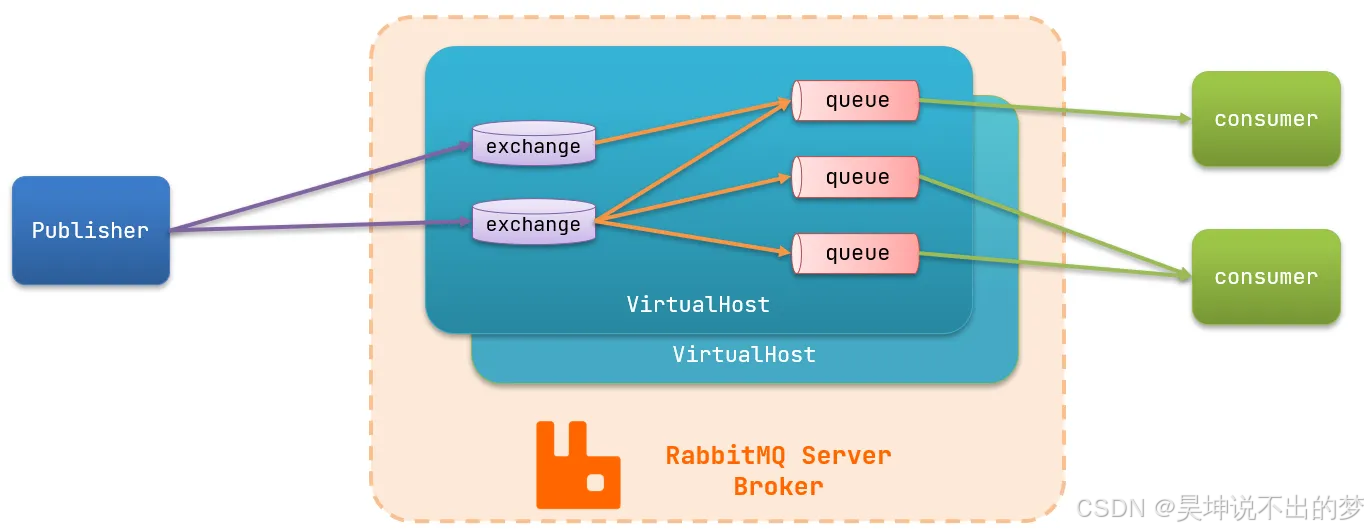
其核心概念:
- publisher:生产者,也就是发送消息的一方
- consumer:消费者,也就是消费消息的一方
- queue:队列,存储消息。生产者投递的消息会暂存在消息队列中,等待消费者处理
- exchange:交换机,负责消息路由。生产者发送的消息由交换机决定投递到哪个队列。
- virtual host:虚拟主机,起到数据隔离的作用。每个虚拟主机相互独立,有各自的exchange、queue
2、RabbitMQ 基本概念
2.1 管理页
用户管理页
可以通关配置不同用户管理不同的Virtual Hosts,达到数据隔离
队列页
交换机页
具体的页面内的操作需要自行熟悉(多摸索就熟悉了~)
2.2 交换机类型
Fanout 交换机
Fanout:广播,将消息交给所有绑定到交换机的队列。我们最早在控制台使用的正是Fanout交换机
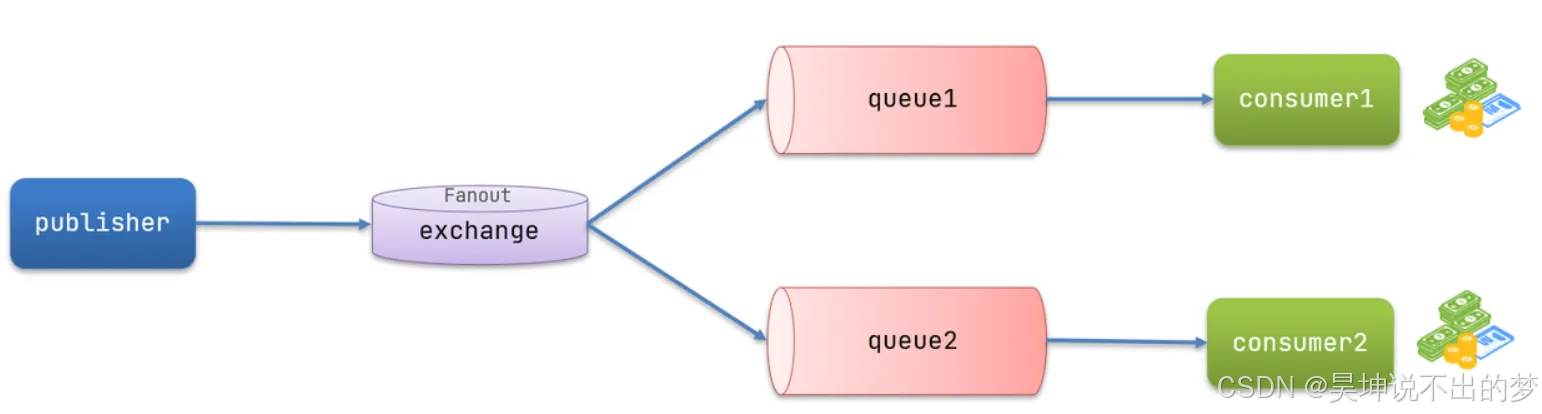
Fanout 特点:
-
可以有多个队列
-
每个队列都要绑定到 Exchange(交换机)
-
生产者发送的消息,只能发送到交换机
-
交换机把消息发送给绑定过的所有队列
-
订阅队列的消费者都能拿到消息
Direct 交换机
Direct:订阅,基于RoutingKey(路由key)发送给订阅了消息的队列
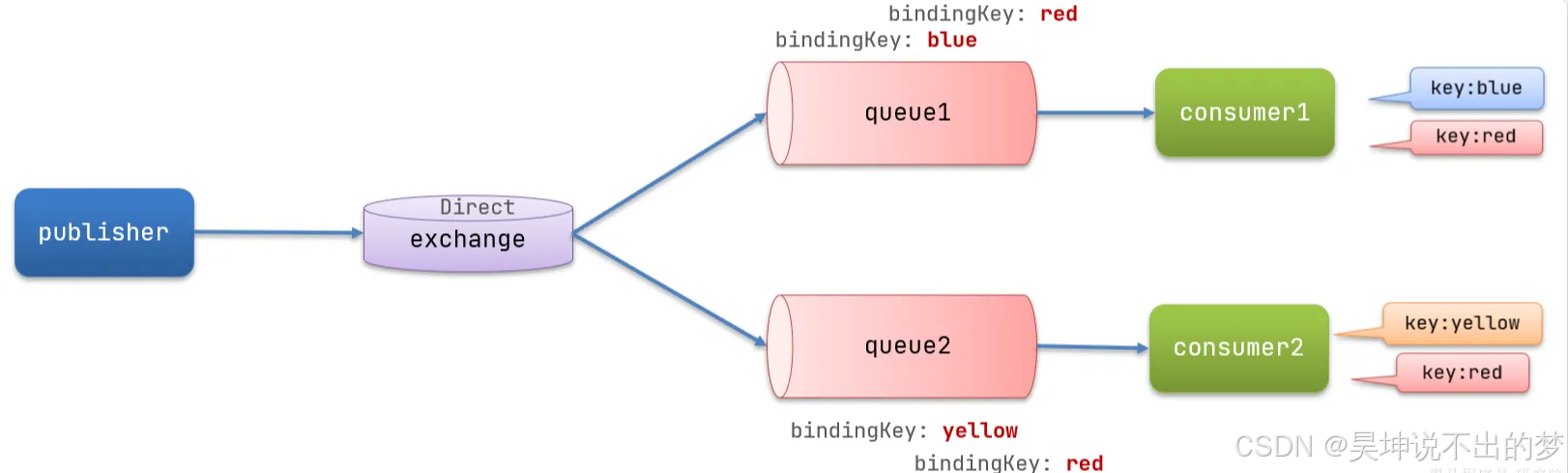
Direct 特点:
-
队列与交换机的绑定,不能是任意绑定了,而是要指定一个 RoutingKey(路由key)
-
消息的发送方在 向 Exchange 发送消息时,也必须指定消息的 RoutingKey。
-
Exchange 不再把消息交给每一个绑定的队列,而是根据消息的 Routing Key 进行判断,只有队列的 Routingkey 与消息的 Routing key 完全一致,才会接收到消息
Topic 交换机
Topic:通配符订阅,与Direct类似,只不过RoutingKey可以使用通配符
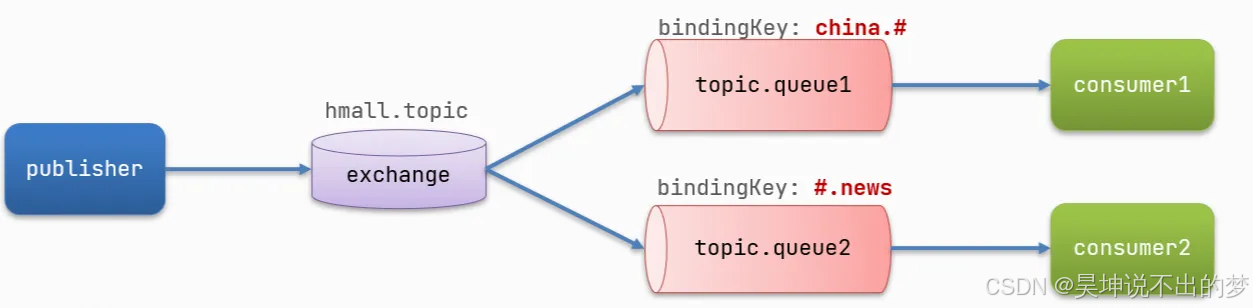
Topic 特点:
- Exchange 可以让队列在绑定 BindingKey 的时候使用通配符
通配符规则:
- #:匹配一个或多个词,eg:
item.#:能够匹配item.spu.insert 或者 item.spu - *:匹配不多不少恰好1个词,eg:
item.*:只能匹配item.spu
Headers 交换机
Headers:头匹配,基于MQ的消息头匹配,用的较少。
…
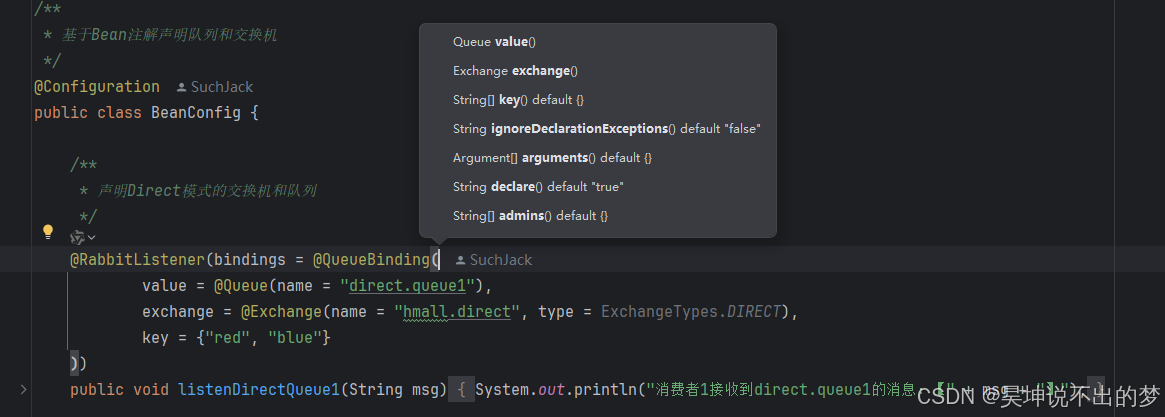
2.3 声明队列和交换机
提示:本小节可以先安装配置完MQ再阅读
编程式声明交换机和队列及绑定关系,如果控制台中不存在则
自动创建,用代码代替了手动创建
演示最简单的基于注解声明,基于API声明的见文档:黑马微服务
如图,IDE快捷键在方法括号内使用快捷键Ctrl+P可以查看方法的参数
2.4 消息转换器
提示:本小节可以先安装配置完MQ再阅读
原因:Spring序列化默认使用JDK序列化,而JDK序列化存在
体积过大、有安全漏洞、可读性差等问题
测试如下:
@Configuration // 消费者配置
public class MessageConfig {
/**
* 创建一个队列
*/
@Bean
public Queue objectQueue() {
return new Queue("object.queue");
}
}
@Test // 发送者发送
public void testSendMap() throws InterruptedException {
// 准备消息
Map<String,Object> msg = new HashMap<>();
msg.put("name", "柳岩");
msg.put("age", 21);
// 发送消息
rabbitTemplate.convertAndSend("object.queue", msg);
}
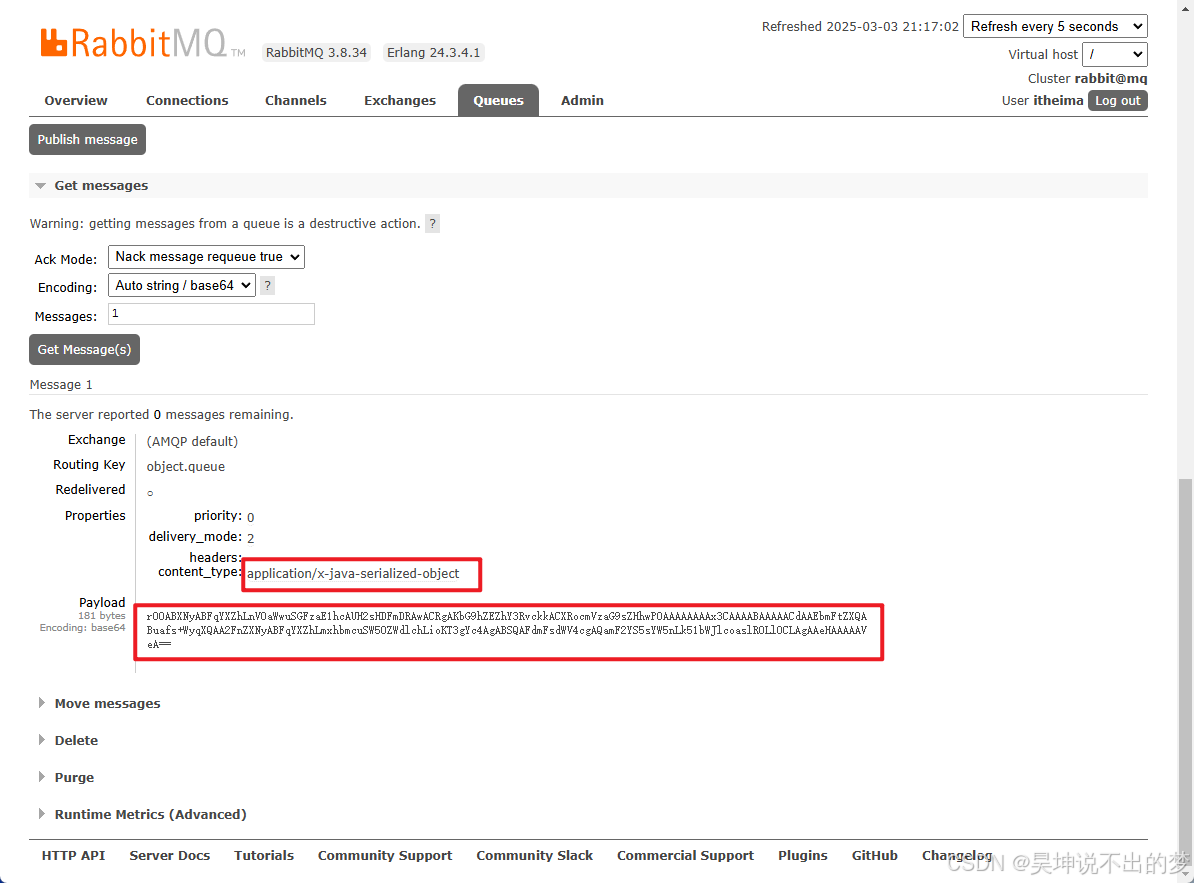
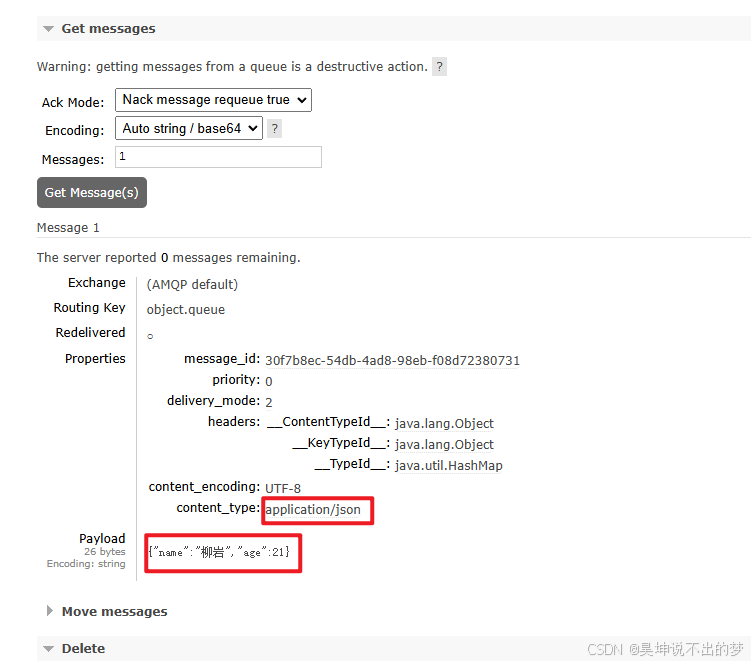
因此需要配置JSON序列化来做序列化和反序列化(消费者和发送者都需要配置)
若项目中含
sping-boot-starter-web依赖,直接注册bean即可,无需再引入下述依赖
<dependency>
<groupId>com.fasterxml.jackson.dataformat</groupId>
<artifactId>jackson-dataformat-xml</artifactId>
<version>2.9.10</version>
</dependency>
在消费者和发送者两个服务启动类添加配置bean
/**
* 定义消息转换器
*/
@Bean
public MessageConverter messageConverter(){
// 1.定义消息转换器
Jackson2JsonMessageConverter jackson2JsonMessageConverter = new Jackson2JsonMessageConverter();
// 2.配置自动创建消息id,用于识别不同消息,也可以在业务中基于ID判断是否是重复消息
jackson2JsonMessageConverter.setCreateMessageIds(true);
return jackson2JsonMessageConverter;
}
删掉旧的队列,重启发布者和消费者后,配置生效
PS:如果在管理面板没看到消息的话,可能是已经被消费者给消费掉了;关闭消费者,再用发布者再发布一条就可以看到了
3、RabbitMQ 安装
基于Docker安装
docker run \
-e RABBITMQ_DEFAULT_USER=itheima \
-e RABBITMQ_DEFAULT_PASS=123321 \
-v mq-plugins:/plugins \
--name mq \
--hostname mq \
-p 15672:15672 \
-p 5672:5672 \
--network hm-net\
-d \
rabbitmq:3.8-management
启动控制台
登录 http://部署的IP:15672 访问
(注意端口放行)
4、RabbitMQ 编程式开发
开发环境:Java11、Springboot 2.7.x
真实生成环境不会使用控制台手动发送,而是编程式开发;
而RabbitMQ采用了AMQP协议,具有跨语言特性,只要遵循协议收发消息,都可以与RabbitMQ交互;
故在Spring环境下选择SpringAMQP。
SpringAMQP优势:
- 自动声明队列、交换机及其绑定关系
- 基于注解的监听器模式,异步接收消息
- 封装了RabbitTemplate工具,用于发送消息
4.1 添加依赖
<!--消息发送-->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-amqp</artifactId>
</dependency>
4.2 配置MQ地址
spring:
rabbitmq:
host: 192.168.150.101 # 你的虚拟机IP
port: 5672 # 端口
virtual-host: /hmall # 虚拟主机
username: hmall # 用户名
password: 123 # 密码
4.3 MQ 拓展配置
能者多劳
问题:默认消息是平均分配给每个消费者的,而每个消费者的消费能力不一样,导致快的要等慢的。
解决:每个人每次只能拿1条消息,无论快慢,快的消费完后可以继续拿,慢的也是消费完后继续拿,这样就不用互相等对方。
因此,"能者多劳"充分利用了每一个消费者的处理能力,可以有效避免消息积压问题。
注意:能者多劳是消费者的配置,不是发送者的配置
spring:
rabbitmq:
host: 192.168.150.101 # 你的虚拟机IP
port: 5672 # 端口
virtual-host: /hmall # 虚拟主机
username: hmall # 用户名
password: 123 # 密码
listener:
simple:
prefetch: 1 # 每次只能获取一条消息,处理完成才能获取下一个消息(即能者多劳)

















 1725
1725

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









