






💥💥💞💞欢迎来到本博客❤️❤️💥💥
🏆博主优势:🌞🌞🌞博客内容尽量做到思维缜密,逻辑清晰,为了方便读者。
⛳️座右铭:行百里者,半于九十。
📋📋📋本文目录如下:🎁🎁🎁
目录
基于NSGA-Ⅲ优化算法的梯级水电和火电机组的联合多目标调度研究
💥1 概述
基于NSGA-Ⅲ优化算法的梯级水电和火电机组的联合多目标调度研究
在当代电力系统运营和管理中,梯级水电站与火电机组的联合调度是一个复杂且高度非线性的多目标优化问题。这种调度不仅需要考虑发电成本最小化,还要确保满足电网的稳定运行和环境保护等要求。随着可再生能源的不断发展和电力市场的不断变化,寻求一种有效的调度方法以达到经济、环保和可靠性目标,成为了电力系统领域研究的热点之一。近年来,NSGA-III(非排序遗传算法第三版)作为一种效率高、适用于解决多目标优化问题的算法,已被广泛用于解决电力系统中的优化调度问题。
参考文献:

 目标函数:
目标函数:
成本最小:

污染最小:
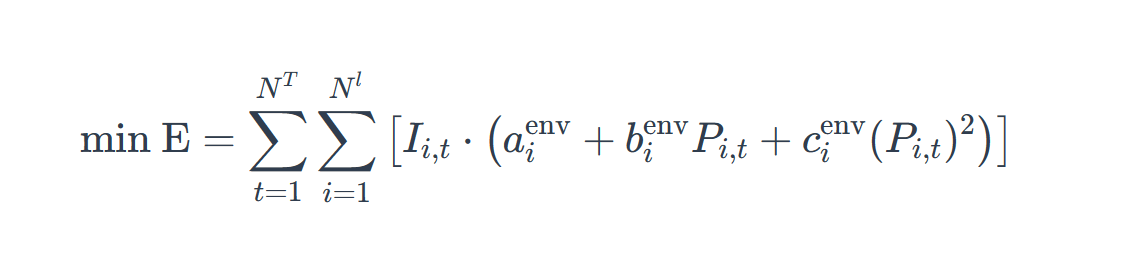 约束条件:
约束条件:
功率平衡、水电站和火电机组约束,详见参考文献
一、NSGA-Ⅲ算法的基本原理与特点
NSGA-Ⅲ(Non-dominated Sorting Genetic Algorithm III)是NSGA-II的改进版本,专为高维多目标优化问题(目标数≥4)设计。其核心在于引入参考点机制和自适应归一化策略,通过非支配排序与参考点关联选择,平衡解的收敛性与多样性。
-
关键流程:
- 参考点生成:通过结构化方法(如Das-Dennis法)在目标空间中均匀分布参考点,确保覆盖所有优化方向。
- 非支配排序:将种群按非支配层级分层,优先保留高等级个体。
- 关联与选择:将个体关联到最近的参考线,优先填充未被覆盖的参考方向,避免局部最优。
- 自适应归一化:动态调整目标函数值范围,解决不同量纲目标的不均衡问题。
-
优势特点:
- 高维优化能力:相较于NSGA-II,在处理4-15个目标的优化问题时表现更优,尤其适用于电力系统多目标调度。
- 无参数特性:除遗传参数(如交叉率、变异率)外,无需额外设置权重或偏好参数。
- 多样性保持:通过参考点引导搜索方向,避免目标空间中的解过度聚集。
二、梯级水电与火电联合调度的多目标模型构建
1. 梯级水电站调度的核心问题
梯级水电站需统筹水力耦合关系、发电效率及多约束条件:
- 优化目标:发电量最大化、蓄能最大化、防洪与生态流量满足。
- 约束条件:
- 水量平衡:上下库容、径流时序关联(如黑河流域模型中的迭代计算)。
- 出力限制:机组振动区、爬坡速率、最小下泄流量。
- 生态约束:生态需水保障、洪峰流量协调。
2. 火电机组调度的关键技术
火电需解决调峰能力与经济性的权衡:
- 优化目标:燃料成本最小化、污染物排放(SO₂、NOx)最小化、调峰深度适应新能源波动。
- 约束条件:
- 运行限制:最小技术出力、启停成本、爬坡速率。
- 经济性补偿:深度调峰导致单位发电成本上升,需权衡补偿收益与运行成本。
3. 联合调度模型的多目标框架
- 目标函数:
- 经济性:总发电成本(火电燃料成本+水电运维成本)最小。
- 环保性:碳排放与污染物排放最小。
- 可靠性:系统备用容量、负荷波动方差最小。
- 资源利用:弃水量最小、新能源消纳最大化。
- 约束整合:
- 电力平衡:水、火电出力总和等于负荷需求。
- 水力-电力耦合:梯级水电站的水流延迟、库容关联。
- 调峰协同:水电承担峰荷,火电维持基荷。
三、NSGA-Ⅲ在联合调度中的优化策略
-
算法适配性改进:
- 复杂约束处理:采用“以水定电”策略强制满足水量平衡等式约束,通过罚函数处理不等式约束。
- 动态参考点调整:根据实时负荷需求调整参考点分布,增强对峰谷差异的响应。
- 多场景优化:结合中长期径流预测与短期负荷波动,分阶段滚动优化。
-
典型应用案例:
- 案例1(光-水-火协调优化) :在改进的IEEE 39节点系统中,NSGA-Ⅲ优化AGC策略,减少水电机组穿越振动区次数,降低频率波动10%-15%。
- 案例2(工业园区多能互补) :通过NSGA-Ⅲ优化电-热-冷-压缩空气系统,实现经济成本降低14.1万元、碳排放减少12.23吨,光伏利用率提升10%。
- 案例3(高比例新能源配电网) :结合静态无功补偿(SOP)与NSGA-Ⅲ,使网络损耗降低2.97%,电压偏差减少20%。
四、多目标权重设定与决策方法
-
权重确定方法:
- 主观赋权法:层次分析法(AHP)结合专家经验,分配经济、环保、可靠性权重。
- 客观赋权法:熵权法根据目标数据离散程度自动分配权重,减少人为偏差。
- 动态权重调整:基于模糊逻辑或市场电价波动实时调整目标优先级。
-
Pareto解集决策:
- 模糊满意度法:通过隶属函数量化各目标满意度,选择综合最优解。
- 数据包络分析(DEA) :评估解集的相对效率,辅助决策者筛选。
五、挑战与未来方向
-
当前挑战:
- 模型复杂度:高维目标与非线性约束导致计算效率低下。
- 不确定性管理:径流预测误差、新能源出力波动影响调度鲁棒性。
- 市场机制缺失:深度调峰补偿标准不足,火电参与意愿低。
-
未来方向:
- 数字孪生技术:构建水文-电力耦合的数字孪生系统,实现实时仿真优化。
- 多算法融合:结合强化学习(RL)与NSGA-Ⅲ,提升动态环境下的自适应能力。
- 碳交易集成:将碳配额成本纳入目标函数,推动低碳调度。
六、结论
NSGA-Ⅲ算法通过参考点机制与自适应归一化,在梯级水电与火电联合调度中展现出显著优势,尤其在处理高维目标(如经济-环保-可靠性权衡)时优于传统算法。未来需进一步融合智能预测技术、完善市场激励机制,以提升系统整体效益与可持续性。实际应用中,建议结合具体场景选择权重设定方法,并通过Pareto解集提供多样化调度方案供决策者选择。
📚2 运行结果
部分代码:
clear
clc
global nHydro nTherm T HydroPowerGenrationCo Load HydroCons Inflow nVar
% 数据来源:An interactive fuzzy satisfying method based on evolutionary
% programming technique for multiobjective short-term hydrothermal scheduling
HydroPowerGenrationCo = [ -0.0042, -0.42, 0.030, 0.90, 10.0, -50 ;
-0.0040, -0.30, 0.015, 1.14, 9.5, -70 ;
-0.0016, -0.30, 0.014, 0.55, 5.5, -40 ;
-0.0030, -0.31, 0.027, 1.44, 14.0, -90 ]; % 水力发电系数
Load =[780,819,735,683,703,840,998,1060,1145,1134,1155,1200,1166,1081,1060,1113,1100,1170,1123.50000000000,1100,950,900,880,840];
% 库容最小值、库容最大值、初始库容、末时段库容、最小下泄、最大下泄、最小出力、最大出力
HydroCons = [ 80, 150, 100, 120, 5, 15, 0, 500 ;
60, 120, 80, 70, 6, 15, 0, 500 ;
100, 240, 170, 170, 10, 30, 0, 500 ;
70, 160, 120, 140, 6, 20, 0, 500 ];
Inflow = [10, 9, 8, 7, 6, 7, 8, 9, 10, 11, 12, 10, 11, 12, 11, 10, 9, 8, 7, 6, 7, 8, 9, 10;
8, 8, 9, 9, 8, 7, 6, 7, 8, 9, 9, 8, 8, 9, 9, 8, 7, 6, 7, 8, 9, 9, 8, 8;
8.1, 8.2, 4, 2, 3, 4, 3, 2, 1, 1, 1, 2, 4, 3, 3, 2, 2, 2, 1, 1, 2, 2, 1, 0 ;
2.8, 2.4, 1.6, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0 ];
lb = [HydroCons(1,5)*ones(1,24),HydroCons(2,5)*ones(1,24),HydroCons(3,5)*ones(1,24), ...
HydroCons(4,5)*ones(1,24),zeros(1,24),zeros(1,24),zeros(1,24),zeros(1,24),zeros(1,24),zeros(1,24),zeros(1,24),zeros(1,24),zeros(1,24),zeros(1,24)];
ub = [HydroCons(1,6)*ones(1,24),HydroCons(2,6)*ones(1,24),HydroCons(3,6)*ones(1,24), ...
HydroCons(4,6)*ones(1,24),ones(1,24),ones(1,24),ones(1,24),ones(1,24),ones(1,24),ones(1,24),ones(1,24),ones(1,24),ones(1,24),ones(1,24)];
% 参数设置
T = 24; % 优化时长-1天24h
nHydro = 4; % 梯级水电数量
nTherm = 10; % 火电机组数量
MaxIt = 40; % Maximum Number of Iterations
nPop = 20; % Population Size
pCrossover = 0.5; % Crossover Percentage
nCrossover=30;
pMutation = 0.01; % Mutation Percentage
nMutation=20;
mu = 0.01; % Mutation Rate
sigma = 0.15*(ub-lb); % Mutation Step Size
nDivision = 10; % 决策变量个数
nObj=2; % 目标函数个数
Zr = GenerateReferencePoints(nObj, nDivision); % 返回一个分区列表
🎉3 参考文献
文章中一些内容引自网络,会注明出处或引用为参考文献,难免有未尽之处,如有不妥,请随时联系删除。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









