







一、线性模型的好处
权重反映了各属性的重要程度,可解释性强
二、一句话描述最小二乘法
试图找一条直线,使所有样本到直线的欧式距离最小
三、为什么加入正则化项且这是避免过拟合的重要手段
当可解出多个w都能使误差最小时,选择哪一个解作为输出,将由学习算法的归纳偏好(奥卡姆剃刀原则)决定,常见做法是引入正则化项。而选择更简单的模型,其实就是避免过拟合的手段。
四、Sigmoid函数及对数几率函数(logistic function)
Sigmoid函数:形似S的函数,其中对数几率函数是重要代表
为什么logistic function叫对数几率函数:
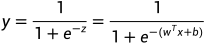
可以改写为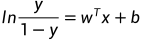
若将y视为样本x作为正例的可能性,则1−y是其反例可能性,两者的比值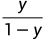 称为“几率”,反映了x作为正例的相对可能性。“对几率取对数则得到“对数几率”(log odds,亦称logit)
称为“几率”,反映了x作为正例的相对可能性。“对几率取对数则得到“对数几率”(log odds,亦称logit)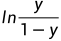
五、为什么线性判别分析(LDA)可视为一种经典的监督降维技术
LDA的思想:给定训练样例集,设法将样例投影到一条直线上,使得同类样例的投影点尽可能接近、异类样例的投影点尽可能远离;在对新样本进行分类时,将其投影到同样的这条直线上,再根据投影点的位置来确定新样本的类别。
若将W视为一个投影矩阵,则多分类LDA将样本投影到d′维空间,d′通常远小于数据原有的属性数d。于是,可通过这个投影来减小样本点的维数,且投影过程中使用了类别信息。
PS:本文大部分公式和图片都来自于周志华老师的《机器学习》,有理解不对的地方,欢迎指正















 3393
3393











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









