







CODE:
Plug-and-Play Diffusion Features for Text-Driven Image-to-Image Translation
Abstract
大规模文本到图像生成模型是生成式人工智能发展过程中的一个革命性突破,它可以合成具有高度复杂视觉概念的各种图像。然而,利用这些模型进行现实世界内容创建的一个关键挑战是如何让用户控制生成的内容。在本文中,我们提出了一个新的框架,将文本到图像的合成提升到图像到图像的翻译领域--给定一个引导图像和一个目标文本提示作为输入,我们的方法利用预先训练好的文本到图像扩散模型的力量,生成一个符合目标文本的新图像,同时保留引导图像的语义布局。具体来说,我们通过观察和经验证明,对生成结构的细粒度控制可以通过在模型内部操纵空间特征及其自我关注来实现。这就产生了一种简单而有效的方法,即从引导图像中提取的特征直接注入翻译图像的生成过程,无需训练或微调。我们在多种文本引导图像翻译任务中展示了高质量的结果,包括将草图、粗略绘图和动画翻译成逼真的图像,改变给定图像中物体的类别和外观,以及修改光照和颜色等全局质量。
Introduction
提升用户可控性,本文重点实现对生成场景结构和语义布局的控制,T2I -> I2I

实现布局控制需要引入额外指导信号,我们的方法不需要任何训练或微调,而是利用预先训练好的固定文本到图像扩散模型 [37]。
我们提出的基本问题是,结构信息如何在这种模型中进行内部编码。我们深入研究了生成过程中形成的中间空间特征,对其进行了经验分析,并设计了一个新的框架,通过对模型内部空间特征的简单操作,实现对生成结构的精细控制。具体来说,空间特征及其自我关注点是从引导图像中提取的,并直接注入到目标图像的文本引导生成过程中。我们证明,我们的方法不仅适用于引导图像由文本生成的情况,也适用于倒置到模型中的真实世界图像。
贡献:
(i) 我们提供了关于扩散过程中形成的内部空间特征的新经验见解。
(ii) 我们引入了一个有效的框架,利用预训练和固定引导扩散的力量,无需任何训练或微调即可执行高质量的文本引导 I2I 翻译。
(iii) 我们从定量和定性两方面表明,我们的方法优于现有的最先进基线,在保留引导布局和偏离其外观之间实现了更好的平衡。
Related Work
Image-to-image translation 图像到图像(I2I)翻译的目的是估计图像从源域到目标域的映射,同时保留输入图像的域不变特性,如物体结构或场景布局。
Text-guided image manipulation. SDEdit[28]使用自由文本提示编辑用户提供的图像,方法是将引导图像降噪到中间扩散步骤,然后根据输入提示对其进行降噪。这种简单的方法产生了令人印象深刻的结果,但在保留指导布局和实现目标文本之间表现出权衡。几种并发方法已经在控制生成内容的不同属性方面迈出了第一步[14,21,39,48,50]。DreamBooth[39]和Textual Inversion[14]在给定一些用户提供的图像的情况下,个性化了预训练的文本到图像扩散模型。
我们在扩散特征空间中操作的方法与提示到提示(P2P)[17]有关,该[17]最近观察到,通过操纵交叉注意层,可以控制图像的空间布局与文本中每个单词之间的关系。直观地说,由于交叉注意是由空间特征与单词的关联形成的,因此它可以捕获对象级别的粗略区域,以及源文本提示符中未表达的局部空间信息。
几个关键优势:
(i) 可对生成的形状和布局进行精细控制;
(ii) 允许使用任意文本词组来表达目标翻译;而 P2P 则需要在源文本和目标文本提示之间进行逐字对齐;
(iii) 在真实世界的引导图像中表现出卓越的性能。
Preliminary
Diffusion models![]()

Method
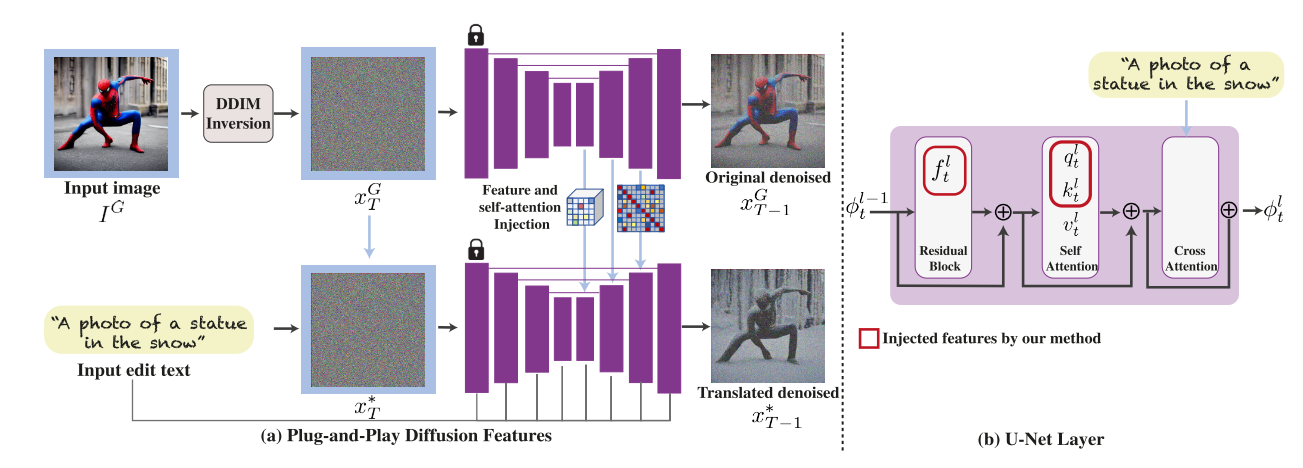
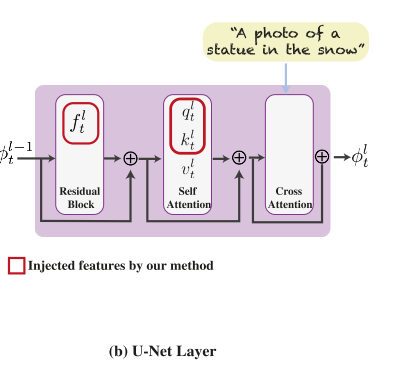
图2。即插即用扩散功能。(a)我们的框架以一个引导图像和一个描述期望翻译的文本提示作为输入;制导图像被反转为初始噪声xgt,然后使用DDIM采样逐步去噪。在此过程中,我们从解码器层及其自注意力机制中提取(fl t, ql t, kl t)空间特征,如(b)所示。为了生成文本引导的翻译图像,我们固定x∗t = xgt,并在某些层注入引导特征(fl t, ql t, kl t),如第4节所讨论的。
给定一个输入引导图像IG和一个目标提示P,我们的目标是生成一个符合P并保留IG的结构和语义布局的新图像I *。我们考虑StableDiffusion[37],这是一种最先进的预训练和固定文本到图像的LDM模型,用ϵθ(xt, P, t)表示。该模型基于U-Net架构
可以通过在生成过程中操纵模型内部的空间特征来实现对生成结构的细粒度控制。
(i)从中间解码器层提取的空间特征编码了局部语义信息,受外观信息的影响较小;
(ii)自注意力机制;代表空间特征之间的联系,允许保留精细的布局和形状细节。
Spatial features.
在不同的初始噪声xT下,从同一提示生成的图像中,确切的场景布局、物体的形状及其细粒度姿势往往会有很大的不同。这表明扩散过程本身和由此产生的空间特征在形成这种细粒度空间信息方面发挥了作用。[6]验证了这一假设,表明在无条件扩散模型中,语义部分片段可以从空间特征中估计出来。
PCA分析,使我们能够推断出ϵθ中主导高维特征的视觉属性。 对于每张图像,我们在每个时间步长t从解码器的每一层提取特征fl,如图图(b)所示。然后,我们对所有图像应用PCA。

图3。可视化扩散特征。我们使用了一组20张人形图像(真实的和生成的),并在大约50%的采样过程(t = 540)下从不同的解码器层提取空间特征。对于每个块,我们对所有图像中提取的特征应用PCA,并将前三个主要成分可视化。中间特征(第4层)揭示了在物体外观和图像域变化很大的情况下,所有图像共享的语义区域(例如,腿或躯干)。更深的特征捕获了更多的高频信息,这些信息最终形成了模型预测的噪声。请参阅SM以获得其他可视化效果。
图 3 显示了不同图层和单个时间步长的代表性图像子集的前三个主成分。从图中可以看出,最粗和最浅的一层主要是前景-背景分离,只描绘了前景物体位置上的一个粗略的圆球。有趣的是,我们可以观察到中间特征(第 4 层)编码了来自不同领域的物体在显著外观变化下共享的局部语义信息--在所有图像中,相似的物体部分(如腿部、躯干、头部)以相似的颜色描绘(图 3 中第 4 层一行)。随着网络的深入,特征逐渐捕捉到更多的高频低层次信息,最终形成网络预测的噪声。
Feature injection.

Feature injection.在后向过程的每一步 t,我们从去噪步骤中提取引导特征 {fl t}
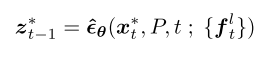
图 5(a) 显示了在层数 l 增加时注入空间特征 fl t 的效果。当我们在更深的层注入特征时,结构得到了较好的保留,但外观信息会泄露到生成的图像中(例如,红色 T 恤和蓝色牛仔裤的色调在第 4-11 层中很明显)。为了在保留 IG 结构和偏离其外观之间取得更好的平衡,我们没有修改深层的空间特征,而是利用了下文讨论的自我注意层。

消融特征和注意力注入。(a) 从引导图像(左)中提取的特征被注入到翻译图像的生成过程中(由给定的文本提示引导)。虽然中间层(第 4 层)的特征显示了局部语义信息(图 3),但仅仅注入这些特征还不足以保留引导结构。注入更深(和更高分辨率)的特征可以更好地保留结构,但会导致从引导图像到生成图像(第 4-11 层)的外观泄漏。(b) 仅在第 4 层注入特征,在更高分辨率层注入自注意贴图,可以缓解这一问题。(c) 仅注入自我注意图限制了特征之间的亲和力,但引导特征和生成特征之间没有语义关联,从而导致结构错位。我们最终配置的结果以橙色标出。
Self-attention.
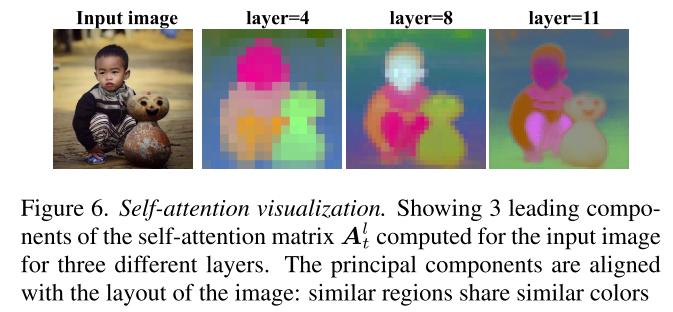
图 6 显示了给定图像的矩阵 Al t 的前导主成分。可以看出,在早期层中,注意力与图像的语义布局保持一致,根据语义部分对区域进行分组。逐渐地,高频信息被捕捉到。
实际上,注入自我关注矩阵是通过替换公式 2 中的矩阵 Al t 来完成的。直观地说,这一操作会根据 Al t 中编码的亲和力将特征拉近:
![]()
Negative-prompting. 为了增加与引导图像内容的偏差,我们使用了负面提示[26],提示 Pn 描述了引导图像。此外,我们使用参数 α∈[0, 1] 来平衡中性提示和负面提示。
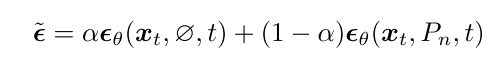




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











