







2409
Abstract
本文综述了从文本生成图像的扩散模型的研究进展,即文本到图像的扩散模型。作为一项独立的工作,本调查首先简要介绍了扩散模型如何用于图像合成,然后介绍了文本条件图像合成的背景。在此基础上,我们有组织地回顾了文本到图像生成的前沿方法及其改进。我们进一步总结了图像生成以外的应用,例如用于各种模式(如视频)的文本引导生成和文本引导图像编辑。除了迄今取得的进展,我们还讨论了现有的挑战和有希望的未来方向。
Introduction
一幅图胜过千言万语。图片通常比文字更有效地传达故事。从文本中可视化的能力增强了人类的理解和享受。因此,创建一个从文本描述生成逼真图像的系统,即文本到图像(tt2i)任务,是实现类人或通用人工智能的重要一步。随着深度学习的发展,文本到图像任务已经成为计算机视觉中最令人印象深刻的应用之一[2,1]。我们在图2中总结了文本到图像生成的代表性研究的时间轴。AlignDRAW[3]标志着从自然语言创建图像的重要一步,尽管具有有限的真实感。文本条件GAN[4]是第一个完全端到端差分架构,从字符级输入扩展到像素级输出,但总是在小规模数据上进行训练。自回归方法进一步利用大规模训练数据进行文本到图像的生成,例如来自OpenAI的DALLE[5]。然而,由于这些方法具有自回归的性质[5,6,7,8],计算成本高,误差序列累积。
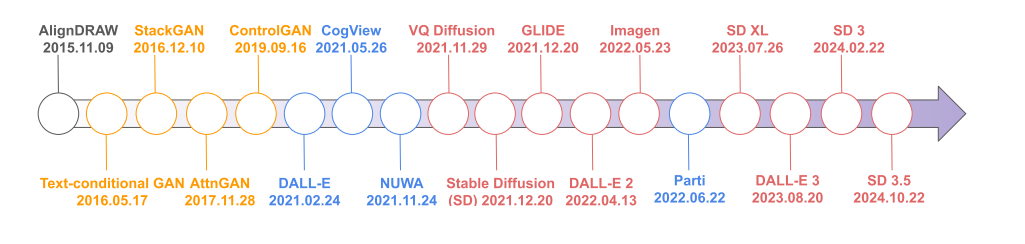
图2:随时间变化的文本到图像任务的代表性作品。基于gan的方法、自回归方法和基于扩散的方法分别用黄色、蓝色和红色表示。为简洁起见,我们在图中将稳定扩散简称为SD。由于基于扩散的模型在图像生成方面取得了前所未有的成功,本工作主要讨论了使用扩散模型进行文本到图像生成的开创性研究。
最近,扩散模型(DMs)已经成为文本到图像生成的主要方法[9,1]。图1显示了由开创性的文本到图像扩散模型DALL-E2[1]生成的示例图像,展示了非凡的保真度和想象力。然而,该领域的大量研究使得读者在没有全面调查的情况下很难了解关键突破。现有调查的一个分支[10,11,12]回顾了扩散模型在所有领域的进展,特别对文本到图像的合成提供了有限的介绍。其他研究[13,11,14]主要关注文本到图像的任务,使用基于gan的方法,缺乏引入基于扩散的方法。
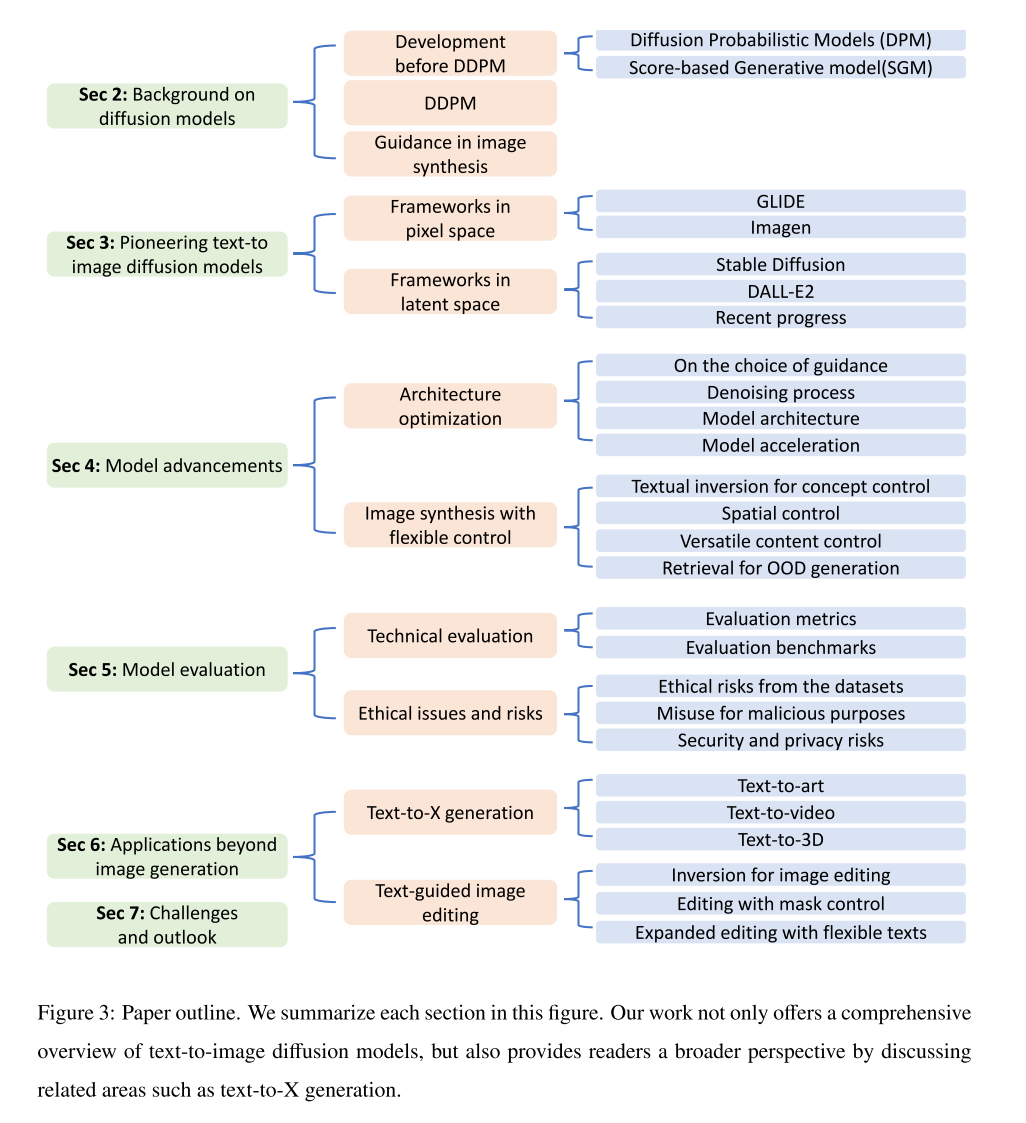
据我们所知,这是第一个回顾基于扩散的文本到图像生成进展的调查。本文的其余部分组织如下。我们还在图3中总结了论文大纲。第2节介绍了扩散模型的背景。第3节涵盖文本到图像扩散模型的开创性研究,而第4节讨论后续进展。第5节从技术和伦理的角度讨论了文本到图像扩散模型的评价。第6节探讨了文本到图像生成之外的任务。,例如视频生成和3D对象生成。最后,我们讨论了文本到图像生成任务的挑战和未来机遇。
Background on diffusion models
扩散模型(Diffusion models, DMs),也被广泛地称为扩散概率模型[15],是一类用变分推理[16]训练的马尔可夫链生成的模型。DM的学习目标是为样本生成保留一个用噪声扰动数据的过程,即扩散过程[15,16]。作为一项里程碑式的工作,去噪扩散概率模型(DDPM)[16]于2020年发表,随后引发了对生成模型社区的指数级增长的兴趣。在这里,我们通过涵盖DDPM之前最相关的进展以及无条件DDPM如何以图像合成为具体示例,提供了对DDPM的独立介绍。此外,我们总结了引导在条件数据挖掘中的作用,这是理解文本到图像的文本-条件数据挖掘的重要基础。
Development before DDPM
DDPM[16]的出现主要归功于两个早期的尝试:2019年研究的基于分数的生成模型(SGM)[17]和早在2015年出现的扩散概率模型(DPM)[15]。因此,在介绍DPM之前,有必要重新审视DPM和SGM的工作机制。
Diffusion Probabilistic Models (DPM) DPM[15]是第一个通过估计将数据映射到一个简单分布的马尔可夫扩散链的反转来建模概率分布的作品。具体来说,DPM定义了一个前向(推理)过程,该过程将复杂的数据分布转换为更简单的数据分布,然后通过逆转该扩散过程来学习映射。在多个数据集上的实验结果表明,dpm在估计复杂数据分布时是有效的。DPM可以被看作是DDPM b[16]的基础,而DDPM通过改进的实现来优化DPM。
Score-based Generative model(SGM). 改进基于分数的生成模型的技术也在[17]中进行了研究。SGM[17]提出用不同大小的随机高斯噪声对数据进行扰动。SGM以对数概率密度梯度作为评分函数,生成噪声水平降低的样本,并通过估计噪声数据分布的评分函数来训练模型。尽管动机不同,但SGM在训练过程中与DDPM有着相似的优化目标,[16]中也讨论了在一定参数化条件下的DDPM在训练过程中与SGM等价。
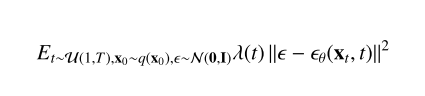
How does DDPM work for image synthesis?
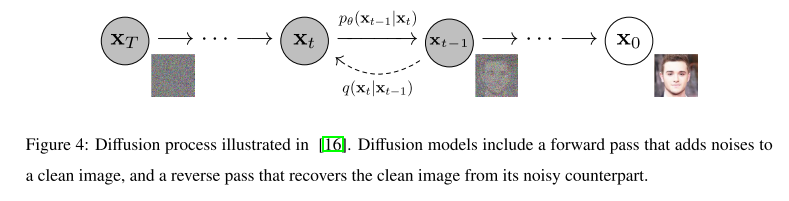
消噪扩散概率模型被定义为参数化的马尔可夫链,它在推理过程中在有限的过渡时间内从噪声中生成图像。在训练过程中,用噪声扰动自然图像的反方向学习过渡核,每一步将噪声加入到数据中,并估计为优化目标。扩散过程如图4所示。
Forward pass. 在前向传递中,DDPM是一个马尔可夫链,每一步都向数据中添加高斯噪声,直到图像被破坏。给定数据分布x0 ~ q(x0), DDPM依次生成q(xT | xT−1)[16]的xT:
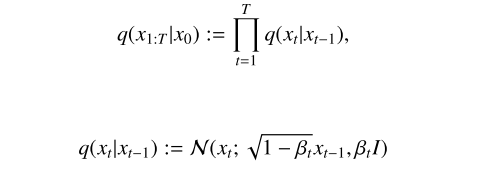
其中T和βt分别是扩散步骤和超参数。为了简单起见,我们只讨论高斯噪声作为过渡核的情况,在方程 3中表示为N。αt:= 1−βt,![]() ,我们可以得到任意步长t的噪声图像[18]:
,我们可以得到任意步长t的噪声图像[18]:
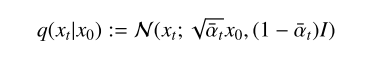
Reverse pass. 使用上面定义的正向传递,我们可以用反向过程训练转换核。从pθ(T)开始,我们希望生成的pθ(x0)能够遵循真实的数据分布q(x0)。因此,模型的优化目标如下(引自[18]):
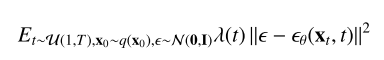
考虑到DDPM和SGM优化目标的相似性,从随机微分方程的角度将它们统一在[19]中,允许更灵活的采样方法。
Guidance in diffusion-based image synthesis
Labels improve image synthesis. 生成对抗模型(GAN)的早期研究表明,类标签可以通过提供条件输入或通过辅助分类器指导图像合成来提高生成图像的质量。这些实践也被引入到扩散模型中:
Conditional diffusion model:条件扩散模型通过将附加信息(例如,类和文本)作为模型输入来学习。
Guided diffusion model:在引导扩散模型的训练过程中,分类诱导梯度(例如通过辅助分类器)涉及到采样过程。
Classifier-free guidance. 与引导扩散模型不同,[20]发现生成模型本身无需分类器即可获得制导,称为无分类器制导。具体来说,无分类器引导联合训练一个具有无条件分数估计器ϵθ(x)和条件分数估计器ϵθ(x, c)的单一模型,其中c表示类标号。在无条件部分放置空token∅作为类标号,即ϵθ(x) = ϵθ(x,∅)。[20]的实验结果表明,无分类器制导实现了与分类器制导相似的质量和多样性之间的权衡。在不使用分类器的情况下,无分类器的扩散促进了更多的模式,例如,文本到图像的文本作为指导。
Pioneering text-to-image diffusion models
在本节中,我们将介绍基于扩散模型的文本到图像的开创性工作,根据扩散过程的进行位置,即像素空间或潜在空间,可以将其大致分类。第一类方法直接从高维像素级生成图像,包括GLIDE[9]和Imagen[21]。另一种方法是先将图像压缩到一个低维空间,然后在这个潜在空间上训练扩散模型。潜在空间类的代表性方法有Stable Diffusion[2]和dall - e2[1]。
Frameworks in pixel space
GLIDE: the first T2I work on DM. 从本质上讲,文本到图像是文本条件下的图像合成。因此,用文本代替类条件DM中的类标签,使采样生成以文本为条件是很直观的。如第2.3节所述,引导扩散提高了条件DM中样本的真实感,其无分类器变体[20]有助于处理自由格式提示。受此启发,GLIDE[9]在T2I中采用无分类器引导,将原有的类标签替换为文本。GLIDE[9]也研究了CLIP指导,但在样本真实感和标题相似性方面,人类评估者不太喜欢无分类器指导。作为其框架中的重要组成部分,文本编码器被设置为具有24个剩余块的变压器,宽度为2048(大约1.2亿个参数)。实验结果表明,GLIDE[9]在FID和人体评估中都优于DALL-E[5]。
Imagen: encoding text with pretrained language model. 继GLIDE[9]之后,Imagen[21]采用无分类器引导生成图像。GLIDE和Imagen的核心区别在于它们对文本编码器的选择。其中,GLIDE使用配对的图像-文本数据与扩散先验一起训练文本编码器,Imagen[21]采用预训练和冻结的大型语言模型作为文本编码器。由于纯文本语料库明显大于成对的图像-文本数据,例如T5[22]中使用的800GB,因此预训练的大型语言模型暴露于具有丰富和广泛分布的文本。使用不同的T5[22]变体作为文本编码器,[21]表明,在Imagen中,增加语言模型的大小比扩大扩散模型的大小更能提高图像保真度和图像-文本对齐。此外,冻结预训练编码器的权值有利于离线文本嵌入,从而减少了在线训练文本到图像扩散先验的计算负担。
Frameworks in latent space
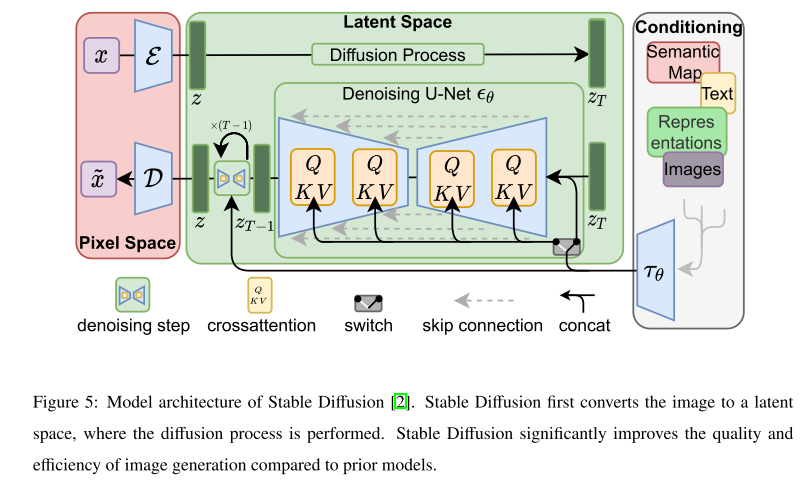
Stable diffusion: a milestone work on latent space 在潜空间上训练扩散模型的代表性框架是Stable diffusion,它是潜扩散模型(latent diffusion Model, LDM)[2]的放大版。继Dall-E[5]采用VQ-VAE学习视觉码本之后,Stable diffusion在第一阶段采用VQ-GAN进行潜在表示。值得注意的是,VQ-GAN通过添加对抗目标来提高合成图像的自然度,从而改进了VQ-VAE。通过预训练的VAE,稳定扩散逆转了用噪声扰动潜在空间的正向扩散过程。稳定扩散还引入了交叉注意作为文本等各种条件信号的通用条件作用。稳定扩散的模型架构如图5所示。[2]的实验结果表明,在潜在空间上进行扩散建模在降低复杂性和保留细节方面明显优于在像素空间上进行扩散建模。在vq扩散中也研究了类似的方法,采用掩模-替换扩散策略。与像素空间方法的发现类似,无分类器制导也显著改善了潜在空间[2]中的文本到图像扩散模型。
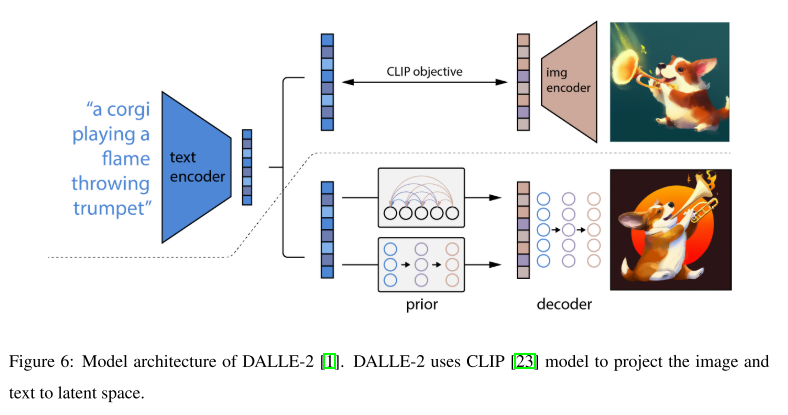
DALL-E2: with multimodal latent space.潜在空间中的另一种文本到图像扩散模型依赖于多模态对比模型[23],其中图像嵌入和文本编码在同一表示空间中匹配。例如,CLIP[23]是一项学习多模态表示的开创性工作,并已广泛应用于众多文本到图像模型[1]。应用CLIP的代表性作品是DALL-E 2,也称为unCLIP[1],它采用CLIP文本编码器,但使用从CLIP潜在空间生成图像的扩散模型对CLIP图像编码器进行反转。这种编码器和解码器的组合类似于LDM中采用的VAE结构,尽管反相解码器是不确定的[1]。因此,剩下的任务是训练一个先验来弥合CLIP文本和图像潜在空间之间的差距,为简洁起见,我们将其称为文本-图像潜在先验。DALLE2[1]发现该先验既可以通过自回归方法学习,也可以通过扩散模型学习,但扩散先验的性能更好。此外,实验结果表明,去除该文本-图像潜在先验会导致性能大幅下降[1],这突出了学习文本-图像潜在先验的重要性。我们在图1中展示了由dale -2生成的图像示例。
Recent progress of Stable Diffusion and DALL-E family. 自从Stable Diffusion[2]发布以来,已经发布了多个版本的模型,包括Stable Diffusion 1.4、1.5、2.0、2.1、XL和3。从Stable Diffusion 2.0[24]开始,一个值得注意的特性是负面提示,它允许用户指定他们不希望在输出图像中生成的内容。Stable Diffusion XL[25]通过整合更大的Unet架构,增强了以前版本的功能,从而提高了人脸生成、更丰富的视觉效果和更令人印象深刻的美学等功能。Stable Diffusion 3建立在diffusion transformer架构[26]上,并使用两组独立的权重来建模文本和图像模态。稳定扩散3提高整体理解和排版生成的图像。另一方面,DALL-E模型的演变已经从自回归的DALL-E[5],到基于扩散的DALL-E2[1],以及最近的dall -3[27]。集成到GPT-4 API中,dale -3在捕获复杂的细微差别和细节方面展示了卓越的性能。
Model advancements
许多作品试图改进文本到图像的扩散模型,我们大致将其分类为架构优化和通用。
Architecture optimization
On the choice of guidance. 除了无分类器引导之外,一些作品[9]还探索了CLIP的跨模态引导。具体来说,GLIDE[9]发现clip -制导不如无分类器制导。相比之下,另一篇文章UPainting[28]指出,由于缺乏大规模的转换语言模型,这些具有CLIP指导的模型难以编码文本提示并生成具有细节的复杂场景。UPainting[28]通过结合大语言模型和跨模态匹配模型,显著提高了生成图像的样本保真度和图像-文本对齐。通用的图像合成能力使UPainting[28]能够在简单和复杂的场景中生成图像。
Denoising process. 默认情况下,推理期间的DM在相同的去噪模型上重复去噪过程,这对于无条件图像合成是有意义的,因为目标只是获得高保真图像。在文本到图像的合成任务中,生成的图像也需要与文本对齐,这意味着去噪模型必须在这两个目标之间做出权衡。具体而言,最近的两篇论文[29,30]指出了一种现象:早期采样阶段强烈依赖文本提示来实现与标题对齐的目标,而后期则侧重于提高图像质量,而几乎忽略了文本引导。因此,他们放弃了在去噪过程中共享模型参数的做法,提出采用多个专门针对不同生成阶段的去噪模型。具体来说,ERNIE-ViLG 2.0[29]还通过文本解析器和对象检测器的指导减轻了对象属性的问题,改进了细粒度的语义控制。
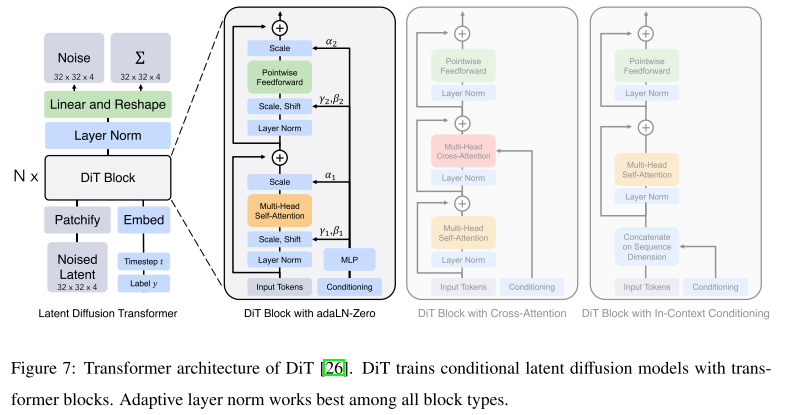
Model architecture. 一个研究分支通过改进去噪模型来增强文本到图像的生成。例如,Free-U[31]策略性地重新加权来自U-Net的跳过连接和骨干特征图的贡献,这提高了图像生成质量,而无需额外的训练或微调。开创性的工作DiT[26]提出了一种扩散变压器架构作为扩散模型的去噪模型;取代了常用的U-Net骨干网(见图7)。Pixart-α[32]是一项开创性的工作,采用基于变压器的骨干网,支持1024 × 1024分辨率的高分辨率图像合成,训练成本低。
Model acceleration. 扩散模型在图像生成方面取得了巨大的成功,优于GAN。然而,扩散模型的一个缺点是采样过程缓慢,需要数百或数千次迭代才能生成图像。V-prediction[33]在不影响生成质量的前提下,将N步DDIM采样器预训练扩散模型提取为N/2步采样的新模型,从而提高了采样速度。流匹配(FM)[34]发现,使用具有扩散路径的FM可以为训练扩散模型提供更鲁棒的和稳定的替代方案。最近的一篇论文《REPresentation Alignment (REPA)[35]》强调了表征在训练大规模扩散模型中的关键作用,并将自监督模型(DINO v2[36])的表征引入到DiT[26]和SiT[37]等扩散模型的训练中。REPA[35]通过加速SiT[37]训练达到显著的加速效果,超过17.5倍。
[35] Representation alignment for generation: Training diffusion transformers is easier than you think
[36] Dinov2: Learning robust visual features without supervision
[26] Scalable diffusion models with transformers
[37] Sit: Exploring flow and diffusion-based generative models with scalable interpolant transformers
Image synthesis with flexible control
Textual inversion for concept control.文本到图像生成的开创性工作[9,21,2,1]依靠自然语言来描述生成图像的内容和风格。然而,在某些情况下,文本不能准确地描述用户想要的语义,例如,生成一个新的主题。为了合成具有特定概念或主题的新颖场景,[39,38]引入若干具有所需概念的参考图像,然后将参考图像反转为文本描述。具体来说,[39]将几个参考图像中的共享概念倒置到文本(嵌入)空间中,即“伪词”。生成的“伪词”可用于个性化生成。DreamBooth[38]采用了类似的技术,主要区别在于微调(而不是冻结)预训练DM模型,以保留受试者身份的关键视觉特征。对于已学习的主题,DreamBooth[38]允许用户通过在输入提示符中指定来控制生成图像中主题的状态。图8显示了DreamBooth生成的图像,其中包含狗的图像以及作为模型输入的提示符。文本反转也被应用于其他应用中,例如[40]中的空间关系控制。

Spatial control. 尽管它们具有前所未有的高图像保真度和标题相似性,但大多数文本到图像的dm(如Imagen[21]和DALL-E2[1])不提供细粒度的空间布局控制。为此,SpaText[41]引入了空间文本(ST)表示,该表示可以通过调整其解码器来微调SOTA DM。具体来说,新的编码器同时满足本地ST和现有全局文本的条件。因此,SpaText[41]的核心在于ST,其中分别训练了扩散先验,将CLIP中的图像嵌入转换为其文本嵌入。在训练过程中,使用CLIP图像编码器将分割后的图像对象作为输入,直接生成ST。一个并行工作[42]提出通过一个简单的草图图像来实现细粒度的局部控制。他们方法的核心是一个潜在制导预测器(LGP),它是一个逐像素的MLP,将噪声图像的潜在特征映射到相应的草图输入。经过训练后(参见[42]了解更多训练细节),LGP可以部署到预训练的文本到图像DM中,而无需进行微调。其他关于空间控制的代表性研究包括BoxDiff[43],它使用提供的box或scribble来控制生成图像的布局,如图9所示。
[42] Sketch-guided text-to-image diffusion models

Versatile content control. ControlNet[44]由于其在大型预训练模型中添加各种条件控制的强大能力而受到广泛关注。ControlNet[44]重用预训练的编码层作为强骨干,并提出了零卷积架构,以确保没有有害噪声影响微调。ControlNet[44]通过各种调节信号(如边缘、深度和分割)实现了出色的效果。图10显示了[44]中的一个示例,该示例使用canny edge和human作为条件来控制Stable Diffusion模型的图像生成。还有其他广泛使用的方法将各种信号统一在一个模型中进行内容控制,如twi -adapter[45]、Uni-ControlNet[46]、GLIGEN[47]和Composer[48]。HumanSD[49]和HyperHuman[50]侧重于以人体骨骼作为模型输入生成人体图像。

Retrieval for out-of-distribution generation. 最先进的文本到图像模型假定充分暴露于来自训练的常见实体和样式的描述。这种假设在罕见的实体或非常不同的风格下就会失效,从而导致性能下降。为了解决这个问题,一些研究[51,52,53,54]使用外部数据库进行检索,采用了一种由自然语言处理[55,56]和GAN-based synthesis[57]改编的半参数方法。检索-增强扩散模型(rdm)[51]使用基于CLIP距离的k近邻(KNN)来增强扩散引导,而KNN-扩散模型[52]通过添加文本嵌入来提高质量。ReImagen[54]使用单阶段框架对其进行了改进,在潜在空间中检索图像和文本,在COCO基准上优于KNN-diffusion。
Model evaluation
Technical evaluation
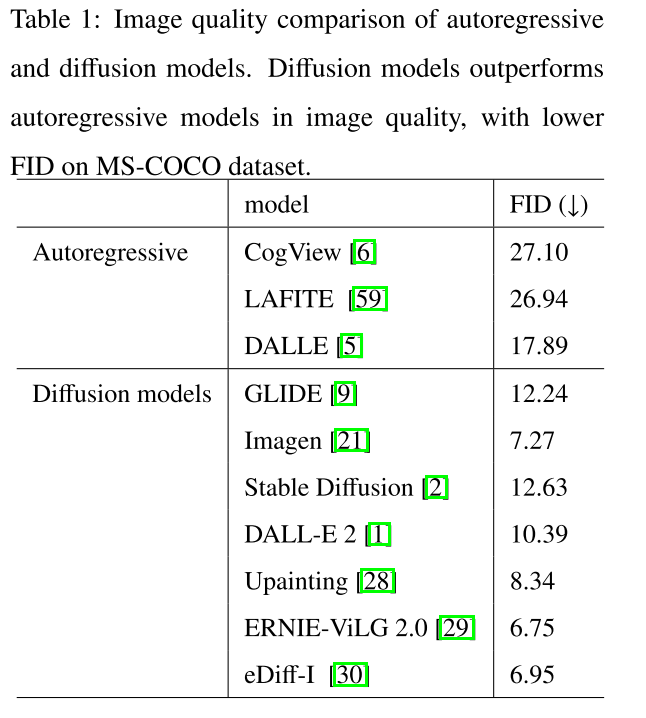
Evaluation metrics. 定量评估图像质量的一个常用指标是初始化距离(FID),它测量合成图像和真实图像之间的初始化距离(也称为Wasserstein-2距离)。我们总结了MS-COCO数据集上代表性方法的评价结果,如表1所示,供参考。FID越小,图像保真度越高。为了测量文本对齐,CLIP分数被广泛应用,这与FID相抵消。还有其他用于文本到图像评估的度量标准,包括用于图像质量的Inception score (IS)[58]和用于文本到图像生成的R-precision。
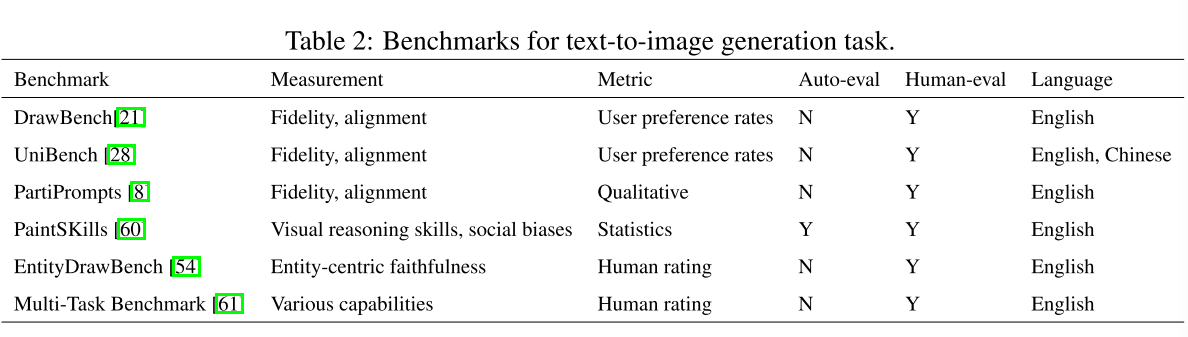
Evaluation benchmarks. 除了上面讨论的自动度量外,许多作品还涉及人工评估,并提出了新的评估基准[60 Dall-eval,21 Photorealistic text-to-image diffusion models with deep language understanding,8 Scaling autoregressive models for content-rich text-to-image generation,28 Upainting,61 Human evaluation of text-to-image models on a multi-task benchmark,54 Re-imagen,62 The artbench dataset: Benchmarking generative models with artworks]。我们在表2中总结了代表性的基准测试。为了更好地评估保真度和文本对齐,DrawBench[21], PartiPropts[8]和UniBench[28]要求人类评分者比较来自不同模型的生成图像。具体来说,UniBench[28]提出在简单和复杂场景下对模型进行评估,并包括中文和英文提示。partiprots[8]引入了1600多个(英语)提示,并提出了一个挑战维度,突出了这个提示的困难之处。为了从各个方面评估模型,PaintSKills[60]除了评估图像质量和文本图像对齐之外,还评估了视觉推理技能和社会偏见。然而,PaintSKills[60]只关注看不见的物体颜色和物体形状场景[28]。EntityDrawBench[54]使用不同场景中各种不常见的实体进一步评估模型。与具有不同难度提示的PartiPropts[8]相比,Multi-Task Benchmark[61]提出了32个评估不同能力的任务,并将每个任务分为三个难度级别。
Ethical issues and risks
Ethical risks from the datasets. 文本到图像的生成是一项高度数据驱动的任务,因此在大规模未经过滤的数据上训练的模型甚至可能受到数据集中的偏见的影响,从而导致伦理风险。[63]通过Stable diffusion[2]在生成的图像中发现了大量不合适的内容(如攻击性、侮辱性或威胁性信息),并首先建立了新的测试平台对其进行评估。此外,它提出了安全潜在扩散,它成功地删除和抑制不适当的内容与额外的指导。另一个伦理问题是社会群体的公平性,[64,65]对此进行了研究。具体而言,[64]发现文本描述中简单的同音异义替换会导致模型产生文化偏差,即产生来自不同文化的图像。[65]引入了文本到图像生成中的伦理自然语言干预(ENTIGEN)基准数据集,该数据集可以通过性别、肤色和文化三个轴来评估伦理干预后生成图像的变化。通过介入文本提示,[65]从社会多样性的角度改进了扩散模型(例如,稳定扩散[2])。Fair Diffusion[66]评估了扩散模型的公平性问题,并在扩散模型的部署阶段缓解了这一问题。具体来说,Fair Diffusion[66]通过文本指导来指导关于公平性的扩散模型。另一项研究[67]发现,文本到图像扩散模型的广泛提示可能会产生刻板印象,例如简单地提到特征、描述符、职业或对象。
Misuse for malicious purposes. 文本到图像扩散模型在生成高质量图像方面已经显示出其强大的能力。然而,这也引起了人们的极大关注,即生成的图像可能被用于恶意目的,例如伪造电子证据[68]。DE-FAKE[68]是第一个对文本到图像扩散模型的视觉伪造进行系统研究的,其目的是将生成的图像与真实图像区分开来,并进一步跟踪每个伪造图像的源模型。为了实现这两个目标,DE-FAKE[68]从视觉模态角度进行了分析,发现不同扩散模型生成的图像具有共同的特征,同时也呈现出独特的模型智能指纹。同时进行的两项研究[69,70]通过评估现有的对扩散模型生成的图像的检测方法,以及分析GAN和扩散模型图像的频率差异来处理伪造图像的检测。[69,70]发现,与GAN相比,现有的检测方法在扩散模型生成的图像上的性能明显下降。此外,[69]将现有方法的失败归因于扩散模型和GAN生成的图像之间的高频不匹配。另一篇作品[71]从艺术家的角度探讨了对艺术形象生成的关注。虽然同意艺术形象生成可能是艺术发展的一种有前途的方式,但[71]指出,如果使用不当,艺术形象生成可能会导致剽窃和利润转移(艺术市场的利润从艺术家向模特所有者转移)问题。
Security and privacy risks. 虽然文本到图像的扩散模型引起了人们的广泛关注,但迄今为止,安全性和隐私风险被忽视了。两个开创性的著作[72,73]分别讨论了后门攻击和隐私问题。受到[64]中发现的简单的单词替换可以将文化偏见转化为模型的启发,Rickrolling the Artist[72]提出将后门注入预训练的文本编码器中,如果文本提示中存在触发器,则将强制生成的图像遵循特定的描述或包含某些属性。[73]首次分析了文本到图像生成模型中的隶属度泄漏问题,即推断是否使用某一图像来训练目标文本到图像模型。具体而言,[73]提出了对隶属信息的三种直觉和四种攻击方法。实验表明,所有的攻击方法都取得了令人印象深刻的效果,突出了成员泄漏的威胁。
[72] Rickrolling the artist: Injecting invisible backdoors into text-guided image generation models
[73] Membership inference attacks against text-to-image generation models
Applications beyond image generation
扩散模型的进步激发了图像生成之外的各种应用,例如文本到X,其中X指的是视频等模式,以及文本引导的图像编辑。我们将创业工作介绍如下。
Text-to-X generation
Text-to-art
艺术绘画是一个有趣而富有想象力的领域,它受益于生成模型的成功。尽管基于GAN的绘画取得了进展[75],但它们受到GAN带来的不稳定训练和模型崩溃问题的困扰。最近,多部作品展示了基于扩散模型的令人印象深刻的绘画图像,研究了改进的提示和不同的场景。多模态引导艺术品扩散(Multimodal guided artwork diffusion, MGAD)[76]通过多模态引导(文本和图像)对扩散模型的生成过程进行了细化,在生成的数字艺术品的多样性和质量方面都取得了很好的效果。为了保持输入图像的全局内容,DiffStyler[77]在内容图像的扩散过程中提出了一种具有可学习噪声的可控双扩散模型。在推理过程中,显性内容和抽象美学都可以通过两种扩散模型来学习。实验结果表明,DiffStyler[77]在定量指标和人工评估方面都取得了优异的成绩。为了提高Stable Diffusion模型的创造力,[78]提出了使用Wikiart数据集进行文本条件扩展和模型再训练两个方向,使用户可以要求著名艺术家绘制新的图像。[79]通过自定义一组图像的美学风格来个性化文本到图像的生成,而[80]将生成的图像扩展到用于数字图标或艺术的可缩放矢量图形(svg)。为了提高计算效率,[53]提出了基于检索增强扩散模型生成艺术图像的方法。通过从专门的数据集(例如Wikiart)中检索邻居,[53]获得对图像样式的细粒度控制。为了指定更细粒度的风格特征(如颜色分布和笔触),[81]提出了监督风格指导和自我风格指导方法,可以生成更多样化的风格图像。
Text-to-video

Early studies. 由于视频只是一系列图像,文本到图像的自然应用是使视频以文本输入为条件。从概念上讲,文本到视频的数据复用是文本到图像的数据复用和视频数据复用的交叉点。MakeA-Video[82]采用一种预训练的文本到图像的数据复用到文本到视频,video Imagen[83]将现有的视频数据复用方法扩展到文本到视频。其他代表性的文本到视频扩散模型包括ModelScope[84]、Tune-A-Video[85]和VideoCrafter[86, 87, 88]。文本到视频的成功自然激发了基于文本输入的电影生成的未来方向。与一般的文本到视频任务不同,故事可视化要求模型在每一帧都根据故事的进展来推理是否在帧或场景之间保持演员和背景的一致性[89]。Make-A-Story[89]使用基于自回归扩散的框架和视觉记忆模块来保持帧间演员和背景的一致性,而AR-LDM[90]利用图像标题历史生成连贯的帧。此外,AR-LDM[90]显示了未见角色的一致性,以及在新引入的数据集VIST上合成真实故事的能力[91]。
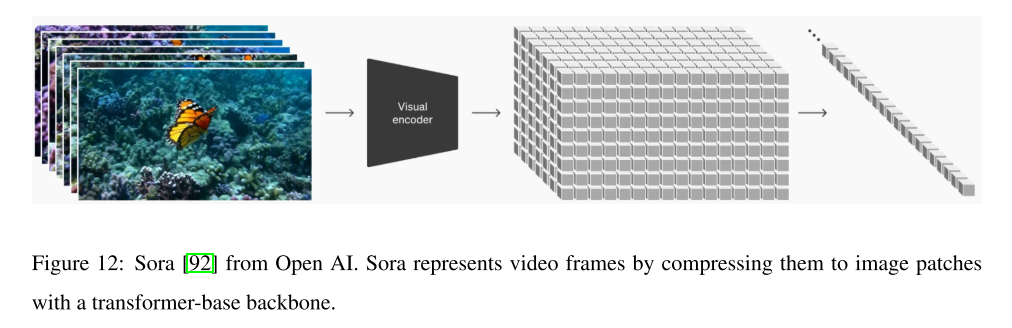
Recent process. 最近,来自Stable AI的Stable Video Diffusion[74]在文本到视频和图像到视频的生成方面实现了显著的性能改进。识别和评估了将扩散模型应用于视频合成的不同训练阶段,并介绍了一个系统的训练过程,包括字幕和过滤策略。OpenAI推出了最先进的视频生成模型Sora[92],能够生成一分钟的高保真视频。Sora[92]受大型语言模型的启发,将不同的数据(如文本和代码)转化为标记,首先将不同类型的视频和图像统一为patch,并将其压缩到一个较低维的潜在空间,如图12所示。然后,Sora将这些表示分解成时空块,并基于变压器主干执行扩散过程。由于Sora[92]尚未开源,一些研究旨在为高级视频生成模型提供开放访问,如open- Sora[93]和open- Sora- plan[94]。
Text-to-3D
三维物体生成显然比二维图像合成复杂得多。DeepFusion[95]是第一个成功将diffustext引导的创意生成模型应用于3D物体合成的作品。受Dream Fields[96]的启发,它将2D图像-文本模型(即CLIP)应用于3D合成,DeepFusion[95]使用预训练的2D扩散模型(即Imagen)的蒸馏训练随机初始化的NeRF[97]。然而,根据Magic3D [98], NeRF的低分辨率图像监督和极其缓慢的优化导致DeepFusion的生成质量低,处理时间长[95]。对于更高分辨率的结果,Magic3D[98]提出了一种从粗到细的优化方法,将粗表示作为初始化的第一步,并使用高分辨率扩散先验优化网格表示。Magic3D[98]也使用稀疏的3D散列网格结构加速生成过程。3DDesigner[99]关注的是3D对象生成的另一个主题,一致性,即跨视图对应。以基于nerf条件模块的低分辨率结果为先验,两流异步扩散模块进一步增强一致性,实现360度一致结果。除了从文本生成3D对象之外,最近的工作Zero-1-to-3[100]通过实现零样本学习新视图合成和单幅图像的3D重建而获得了极大的关注,激发了各种后续研究,如vivid -1-to-3[101]。
Text-guided image editing
扩散模型不仅显著提高了文本到图像合成的质量,而且增强了文本引导下的图像编辑。在DM普及之前,零摄图像编辑一直以GAN反演方法[102,103,104,105,106,107]与CLIP相结合。然而,GAN通常具有有限的反演能力,导致图像内容的意外变化。在本节中,我们将讨论基于扩散模型的图像编辑的开创性研究。
Inversion for image editing. 另一个研究分支是通过对扩散过程中的噪声信号进行修正来编辑图像。SDEdit[108]是一项开创性的工作,它通过随机微分方程(SDE)迭代去噪来编辑图像。在没有任何特定任务的训练的情况下,SDEdit[108]首先在输入中添加噪声(如笔画),然后通过SDE对噪声图像进行降噪,从而提高图像的真实感。DiffusionCLIP[109]通过在反向DDIM[110]过程中微调扩散模型,利用基于clip的损失,进一步在编辑过程中增加了文本控制。由于存在局部线性化假设,DDIM可能会随着误差的传播而导致不正确的图像重建[111]。为了缓解这一问题,精确扩散反演通过耦合变换(precise Diffusion Inversion via Coupled Transformations, EDICT)[111]提出在扩散过程中保持两个耦合的噪声向量,获得比DDIM[110]更高的重建质量。另一项研究[112]通过枢纽反演和null-text优化,介绍了一种用于文本引导编辑的精确反演技术,展示了对各种真实图像的高保真编辑。为了提高编辑效率,LEDITS++[113]提出了一种无需调整和优化的新型反演方法,只需少量扩散步骤即可产生高保真度的结果。
Editing with mask control. 一个分支的工作主要是在局部(遮罩)区域对图像进行操作[114],如图13所示。难点在于如何保证被遮挡区域与背景之间的无缝一致性。为了保证编辑区域与剩余部分之间的无缝连贯,混合扩散[114]在空间上将噪声图像与局部文本引导的扩散潜渐进地混合在一起。在[115]中的混合潜伏扩散模型和[116]中的多阶段变体中,该方法得到了进一步改进。与[114,115,116]需要手工设计掩码不同,DiffEdit[117]提出自动生成掩码来指示要编辑的部分。

Expanded editing with flexible texts. 一些研究通过灵活的文本输入实现了更多类型的图像编辑。Imagic[118]是第一个对单个图像(如姿势或多个对象的组合)执行基于文本的语义编辑的软件。具体来说,Imagic[118]首先获得目标文本的优化嵌入,然后在目标文本嵌入和优化后的嵌入之间进行线性插值。然后将生成的表示发送到微调模型并生成编辑后的图像。为了解决文本提示符的简单修改可能导致输出不同的问题,prompt - To - prompt[119]提出在扩散过程中使用交叉注意图,该图表示文本提示符中每个图像像素与单词之间的关系。InstructPix2Pix[120]的工作任务是编辑与人类书面指令的图像。基于大型模型(GPT-3)和文本到图像模型(Stable diffusion),[120]首先为这个新任务生成了一个数据集,并训练了一个条件扩散模型InstructPix2Pix,该模型可以很好地泛化到真实图像。然而,在[120]中承认它仍然存在一些局限性,例如,生成的数据集的视觉质量限制了模型。

关于图像编辑还有其他有趣的任务。例如,Paint by example[121]提出了一个语义图像合成问题,参考图像在与另一图像混合之前进行语义转换和协调[121]。MagicMix[122]提出了一种名为语义混合的新任务,将两种不同的语义(例如,corgi和coffee machine)混合在一起,创造出一个新的概念(corgi-like coffee machine)。SEGA[123]允许通过指示具有语义控制的扩散模型进行微妙和广泛的图像编辑。具体来说,它与扩散过程相互作用,灵活地引导它沿着语义方向。
Challenges and outlook
Challenges
Challenges on ethical issues and dataset bias. 在大规模未经过滤的数据上训练的文本到图像模型甚至可能会强化训练数据集的偏见,导致产生关于社会群体的不适当(例如,攻击性、侮辱性或威胁性信息)[124]或不公平的内容[64,65]。此外,目前的模型主要采用英语作为输入文本的默认语言。这可能会进一步使那些不懂英语的人处于不利的境地[125,126]。
Challenges on security risks. 随着扩散模型的改进,从真实图像中检测生成图像变得越来越困难。这带来了安全风险,因为生成的图像可能被用于伪造电子证据等恶意目的[68]。此外,扩散模型还存在安全风险,如后门攻击[72]和隐私问题[73]。
Challenges on data and computation. 众所周知,深度学习的成功在很大程度上依赖于规模化的训练数据和庞大的计算资源。在文本到图像的DM环境中,这一点尤其正确。例如,主要的框架,如Stable Diffusion[2]和dall - e2[1],都是用数亿个图像-文本对进行训练的。此外,计算开销如此之大,以至于为大型公司提供了从头开始训练这样一个模型的机会,例如OpenAI[1]和谷歌[21]。尽管在加速扩散模型的训练和推理方面取得了进展,但在以效率为导向的环境(如边缘设备)中有效地采用扩散模型仍然是一个挑战。
Outlook
Safe and fair applications. 随着文本到图像模型的广泛应用,如何降低现有文本到图像模型的伦理问题和安全风险是一项艰巨的任务。可能的方向包括更多样化和平衡的数据集,以缓解种族和性别等问题,检测生成图像的先进方法,以及针对各种攻击的鲁棒的扩散模型。
Unified multi-modality framework. 文本到图像的生成可以看作是多模态学习的一部分。大多数工作都集中在文本到图像生成的单一任务上,但将多个任务统一到一个模型中可能是一个有前途的趋势。例如,UniD3[127]通过单一扩散模型统一了文本到图像的生成和图像字幕。统一的多模态模型可以通过学习每个模态的表示来更好地促进每个任务,并且可以为模型如何理解多模态数据带来更多的启发。
Collaboration with other fields. 在过去的几年里,深度学习在多个领域取得了很大的进展,如多模态GPT-4[128]。先前的研究已经研究了如何将扩散模型与其他领域的模型进行协作,例如最近的工作将扩散模型解构为自动编码器[129],并在InstructPix2Pix[120]中采用GPT-3[130]。也有研究将扩散模型应用于视觉领域,如图像恢复[131]、深度估计[132,133]、图像增强[134]和分类[135]。文本到图像扩散模型与活跃研究领域的最新发现之间的进一步合作是一个值得探索的令人兴奋的话题。



















 3万+
3万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











