







code:没发布
https://anonymous.4open.science/r/MaskUnet-736B.
Abstract
在机器人、增强现实和大规模场景理解等现实应用中,低分辨率图像分割是至关重要的,在这些应用中,由于计算限制,通常无法获得高分辨率数据。为了解决这一挑战,我们提出了MaskAttn-UNet,这是一个新的分割框架,通过掩码注意机制增强了传统的UNet架构。我们的模型选择性地强调重要的区域,同时抑制不相关的背景,从而提高了在杂乱和复杂场景下的分割精度。与传统的U-Net变体不同,MaskAttn-UNet有效地平衡了局部特征提取与更广泛的上下文感知,使其特别适合低分辨率输入。我们在三个基准数据集上评估了我们的方法,输入图像被重新缩放为128×128,并在语义、实例和全景分割任务上展示了具有竞争力的性能。我们的研究结果表明,MaskAttn-UNet达到了与最先进的方法相当的精度,且计算成本明显低于基于变压器的模型,使其成为资源受限情况下低分辨率分割的有效且可扩展的解决方案。
Introduction
像U-Net[52]这样的编码器-解码器架构已经被证明在通过多尺度架构提取局部特征和精细细节方面是有效的。然而,当多个对象或类共存于一张图像中时,它们往往难以捕获远程依赖关系[15,68],从而导致复杂场景中的模糊性[51,58]。相反,transformer-based vision模型通过自注意力机制机制将全局环境纳入其中,使其能够模拟像素或区域之间的长期关系[55,66]。这种全局表示是以大量内存和计算开销为代价的,这是由于自注意力机制的二次复杂度,这使得这种模型对于嵌入式或实时系统来说不切实际[14,22]。此外,由于视觉变换缺乏cnn固有的归纳偏差(尤其是局部偏差),完全注意力驱动的模型可能会忽略区分小物体或重叠物体所需的细粒度细节[6,50,65]。这些限制突出表明,需要一种分割方法来平衡局部特征精度、全局上下文捕获和计算效率。
本文介绍了MaskAttn-UNet,这是U-Net框架的一个创新扩展,它集成了一个新颖的掩码注意力模块来解决上述挑战。MaskAttn-UNet架构通过其跳过连接保留了U-Net在捕获精细局部细节方面的优势,而掩码注意模块选择性地强调特征图中的突出区域以注入更广泛的上下文信息。通过将注意力集中在相关区域(而不是全局关注所有像素),本方法可以更有效地捕获远程依赖关系,并减轻通常与transformer相关的内存负担。专门为低分辨率(128 × 128图像)设计了网络,这大大减少了计算需求,同时仍然允许模型学习丰富的表示。这种设计选择反映了具有有限图像分辨率的实际用例,并确保MaskAttn-UNet仍然适用于资源受限的方案。
本混合方法有效地结合了卷积归纳偏置和有针对性的自注意力机制的优点,在不同和复杂的场景中产生鲁棒的的多类分割。
贡献:
1.提出了MaskAttn-UNet,这是一个自注意力机制U-Net变体,它集成了一个新颖的掩模注意模块,可以有效地捕获本地细节和远程依赖关系。
2.我们设计了使用128 × 128输入的低分辨率分割架构,减少了计算需求,同时保持了鲁棒的的性能。
3.在多个数据集上验证了我们的方法,证明了与ransformer-based的方法相比,分割指标的改进和更低的内存消耗。
Related Work
U-Net
它的设计包括一个使用连续卷积和池化操作来提取多尺度特征的收缩路径和一个使用上采样层来恢复空间分辨率的扩展路径。编码器和解码器中相应层之间的跳过连接允许网络将深度语义信息与高分辨率空间细节合并。这种结构已被证明在生物医学分割等应用中是有效的,其中精确定位是至关重要的。
但标准卷积层固有的固定接受域限制了U-Net捕获远程依赖关系的能力。在具有多个相互作用对象或重叠结构的场景中,这可能导致不同区域的错误分类或合并。
Swin Transformers
Swin Transformers[37]通过采用分层架构代表了该领域的重大发展。该模型将输入图像分割成不重叠的小块,并在局部窗口内计算自注意力机制。一个关键的创新是在连续层之间引入了移位窗口,这使得跨窗口交互能够有效地扩展感受野,而不会产生全局注意力的高计算成本。这种分层设计促进了多尺度特征学习,使Swin能够处理高分辨率图像,同时平衡局部细节和全局背景。
然而,这些好处是以大量的计算成本为代价的。内存需求和处理需求的增加,特别是在更深的配置或更大的输入大小中,可能会阻碍在资源受限的硬件上进行实时推理或部署
Mask2Former
Mask2Former[17]基于MaskFormer[16]建立的框架,将分割问题重新表述为集合预测问题。在MaskFormer中,分割是通过为每个对象分配一个唯一的掩码来实现的,从而统一了“事物”和“东西”的处理。Mask2Former通过引入自适应地聚焦于相关图像区域的动态注意力蒙版来改进这种方法。该机制使模型能够有效地分离重叠对象,并生成高质量的实例和全视分割输出。
Mask2Former中的动态掩码生成有助于捕获全局上下文信息,同时保持描述对象边界的灵活性。然而,仅仅依赖注意机制可能会导致失去细粒度的局部细节,而这些细节对于精确的边界描绘至关重要,特别是在具有小物体或复杂纹理的场景中。
Methods
本方法处理输入图像以产生逐像素的分类掩码,其中每个像素被分配一个语义标签。为了扩展方法的功能,还结合了利用共享特征表示和专门损失函数的实例和全景分割分支。首先概述了模型的总体架构,然后解释了训练目标和优化过程。
Architecture Overview
MaskAttn-UNet网络遵循一个编码器和一个解码器,在多个尺度上集成了掩码注意模块。编码器通过连续的卷积块提取分层特征,逐步降低空间分辨率。在每个尺度上,特征通过一个掩模注意模块进行细化,该模块生成一个可学习的二元掩模来抑制无信息区域并强调突出结构。跳过连接连接相应的编码器和解码器层,这有助于解码器在分割输出中恢复高分辨率的细节。解码器逐渐提升样本并融合特征(通过跳过连接增强)以产生最终预测。
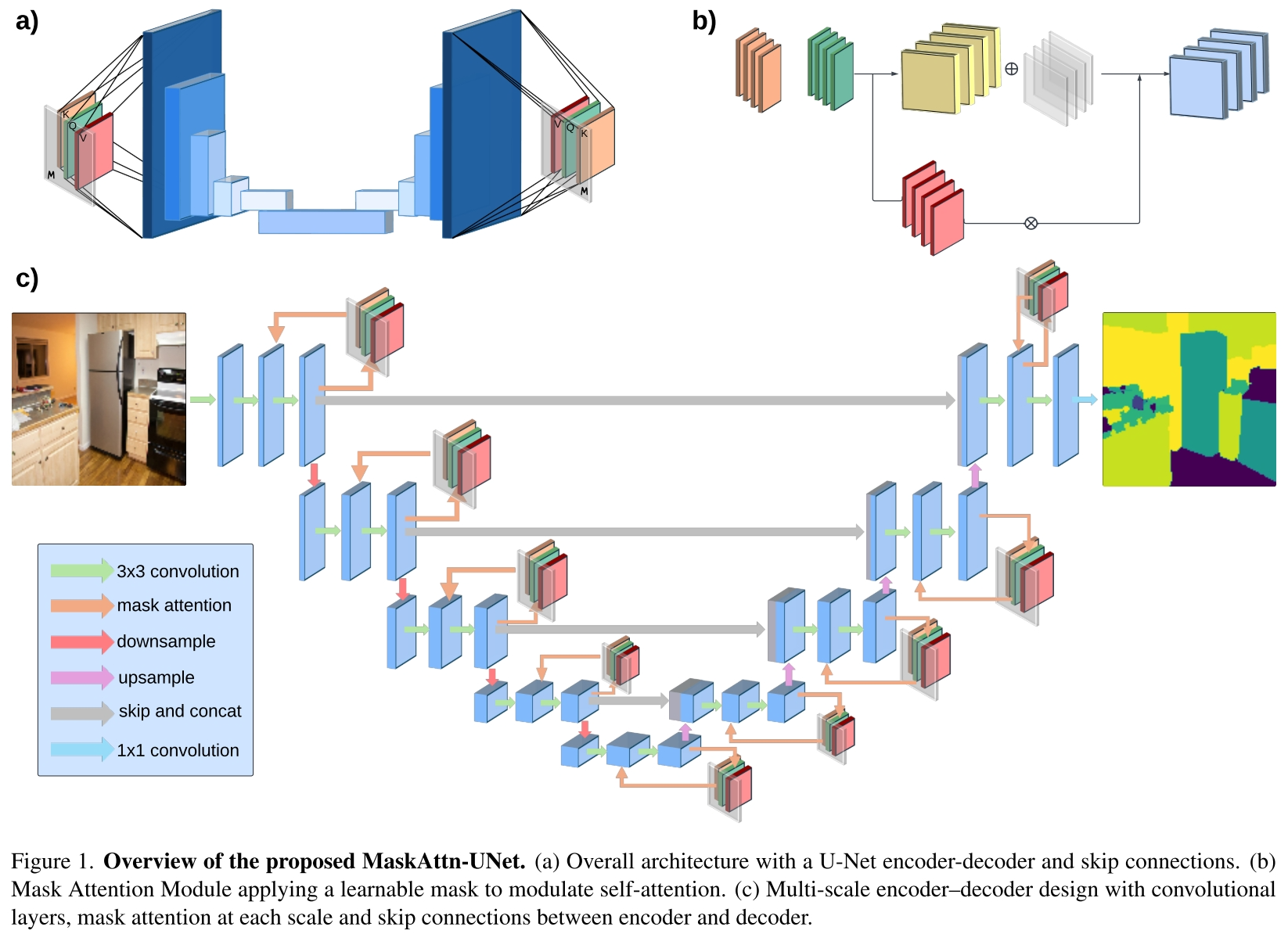
Mask Attention Module
每个面具注意力模块的灵感来自多头自我注意,并有一个额外的可学习面具来调节注意力权重。给定来自编码器或解码器的输入特征映射X,我们首先将其重塑为X '∈RB×H×W×C,其中B是批处理大小,H×W是空间维度,C是通道数。然后我们应用多头蒙面自注意力机制(在我们的实现中使用四个头)。注意权重的计算使用缩放的点积注意机制,并添加掩模矩阵M:
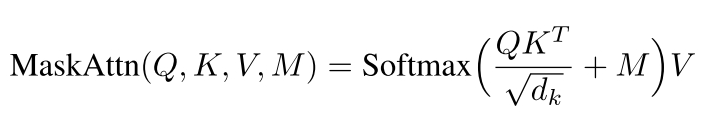
其中Q = X 'WQ, K = X 'WK, V = X 'WV, dk是查询和键向量的维数。这里,M是一个可学习的(或动态计算的)掩码,它抑制了注意力矩阵中无信息区域的贡献。直观上,M会使注意力偏向于相关的空间位置。
然后将给定头部的注意力操作的输出组合到所有头部(如多头注意力),并通过剩余连接添加到原始输入中。设A表示掩蔽多头注意的结果(合并头后)。我们通过具有GELU非线性的两层前馈网络(FFN)馈送A,并在最后添加残差A:
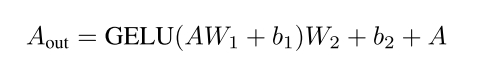
其中W1,W2是权重矩阵,b1, b2是FFN的偏差。这将产生掩码注意力模块的最终输出。隐藏自注意力机制与残差FFN的结合通过整合全局上下文增强了特征表示,同时保留了通过跳过连接传递的原始信息。
Segmentation Loss
使用复合损失函数来优化网络,该函数结合了语义分割损失和实例级对比损失。平衡这些目标允许模型学习像素级的类区别和特定于实例的可分离性。
Semantic Segmentation Loss.
对于语义分割,其中每个像素属于一个C类,使用标准的交叉熵损失。设yij为像素(i, j)的ground-truth class label,设pij(c)为像素(i, j)属于c类的预测概率。损失为:
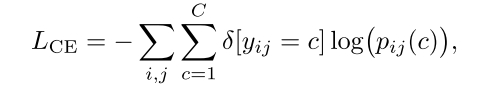
其中δ[·]是克罗内克函数(当参数为真时为1,否则为0)。这种逐像素交叉熵鼓励对每个像素进行正确的类预测。
真实值与预测值的损失
Instance Contrastive Loss.
对于实例分割(以及全视分割的实例组件),采用对比嵌入损失,鼓励相同对象实例的像素具有相似的特征嵌入,同时将来自不同实例的像素嵌入分开。设eij表示网络产生的像素(i, j)的嵌入向量。对于给定的像素(i, j),将Pij定义为正的像素索引集(与(i, j)属于同一个真实值实例),将Nij定义为负的像素索引集(属于不同的实例)。首先对(i, j)的所有考虑对计算一个归一化器Dij:
-
Pij 是与像素 (i,j) 属于同一实例的像素索引集合(正样本)。
-
Nij 是与像素 (i,j)属于不同实例的像素索引集合(负样本)。
-
Dij 是归一化因子,计算所有考虑的正负样本对的指数相似度之和:
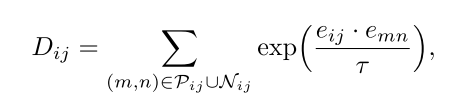
其中 ττ 是温度参数,控制对比分布的锐度。对于正对(i, j)和(k, l)∈Pij(即来自同一实例的两个像素),每对对比损失为:
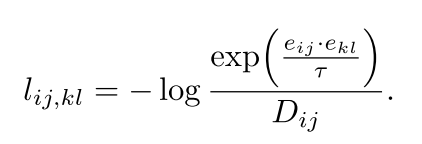
该损失函数通过最大化正样本对的相似度与所有样本对相似度的比值,来优化嵌入空间。
这种损失函数有助于网络学习区分不同实例的像素,从而提高实例分割的准确性。
如果嵌入eij和ekl与所有其他对(分母)相比,彼此之间(分子)的距离不明显更近,则会惩罚模型。像素(i, j)的实例对比损失通过对其所有正伙伴(k, l)∈Pij取平均lij,kl,然后对所有像素取平均来计算:
-
对于像素 (i,j),其对比损失 Lij,kl 是针对其所有正样本对 (k,l)∈Pij计算的。
-
实例对比损 LIC是所有像素 (i,j)的对比损失的平均值:
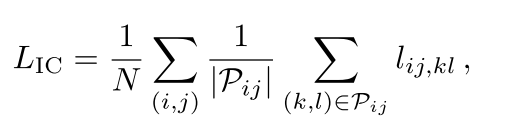
N是考虑的像素总数(为了效率,可以是所有像素对的一个采样子集)。
∣Pij∣是像素(i,j) 的正样本对数量。
LIC鼓励来自同一实例的嵌入在特征空间中聚类在一起,而不同实例的嵌入保持分离。最终的分割损失 Lseg是交叉熵损失LCE和实例对比损失LIC的加权和:
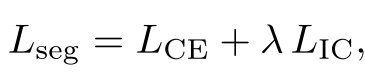
-
LCE 是标准的交叉熵损失,用于分类任务。
-
λ是一个超参数,用于平衡两种损失的贡献。
其中λ控制语义分割损失和实例对比损失之间的平衡。
公式解析
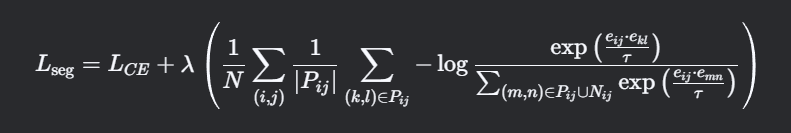
-
λ 是超参数,用于平衡交叉熵损失和实例对比损失
-
N是考虑的像素总数
-
∣Pij∣是像素 (i,j) 的正样本对数量
-
(i,j)是所有像素的遍历单位
-
(k,l)是正样本对中的遍历单位
-
(m,n)是正样本对和负样本对集合中的遍历单位
-
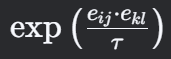 计算正样本对的相似度
计算正样本对的相似度 -
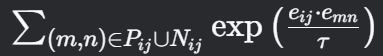 是归一化因子,计算所有正负样本对的相似度之和
是归一化因子,计算所有正负样本对的相似度之和



















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











