







前言
本文将介绍如何使用聆思CSK6大模型开发套件部署模型。之前发的文章介绍了通过模型修改和裁剪,得到适合csk6芯片运行的模型,并通过图像预处理脚本获得图片的二进制文件,将其输入test_thinker,最终获得引擎仿真推理出的图像分类结果。今天我们将进一步介绍如何在csk6多模态芯片上运行这个算法模型。
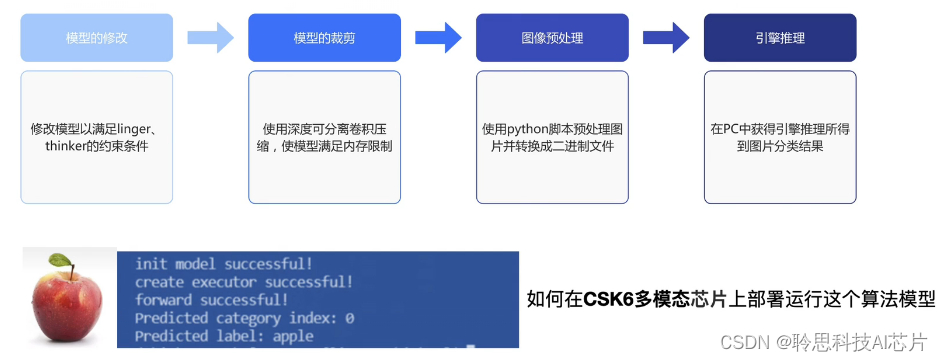
算法模型部署方案介绍
通过本次操作您将掌握如何部署pythorch-cifar100示例工程,以及如何替换使用您自己的模型,并了解到推理接口的相关信息。
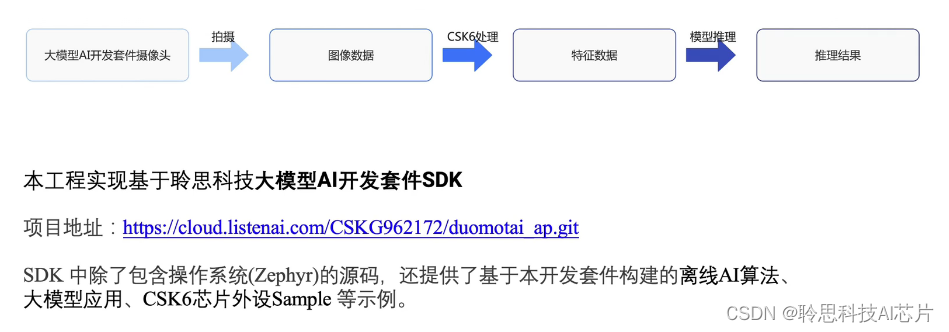
项目整体流程是这样的:大模型AI开发套件摄像头采集图像,在csk6芯片上提取特征,通过调用Think API进行模型推理,最终获得推理结果。本次实践基于聆思维护与发布的大模型AI开发套件SDK。为方便大家跟随实践,所有必须的模型文件和集成的图像与处理与推理脚本都已经包含在项目中。pytorch-cifar100项目位于apps中的resnet目录下,模型文件存放于resources/images中,集成的图像的预处理和推理脚本位于src目录下的resnet18.c。
硬件介绍
首先确保您已经准备好CSK6的大模型AI开发套件,包括摄像头、调试USB口、触摸显示屏以及相关功能按键。

获取开发环境与SDK
目前我们需要进行准备工作,获取开发环境与SDK,针对命令行工具的安装,不同操作系统有不同的操作指令,请您根据文档自行安装。
安装命令行工具
请参照 https://docs2.listenai.com/x/xfI6rkpCKmW 完成 lisa zep 命令行工具的安装
安装后可以通过Lisa info zep检查当前开发环境,确保没有工具缺失。
获取SDK
命令行工具安装完成后执行一下命令:
git clone--branch v1.6.0
https://cloud.listenai.com/CSKG962172/duomotai ap.git
初始化SDK
进入到 duomotai_ap目录下,分别执行以下命令,使用 lisa 对项目进行初始化:
lisa zep init-app
lisa zep update编译示例固件
- SDK初始化完成后,在 duomotai_ap 目录下,执行以下指令进行代码编译:
lisa zep build -b csk6_duomotai_devkit -s apps/resnet18 -p -- -DCONFIG_APLICATION_PACK_IMAGES=y
注:"DCONFIG_APLICATION_PACK_IMAGES=y"表示将所有相关运行资源打包在一个bin文件里,适合初次烧录使用。在平时的开发调试中,如果希望仅烧录程序本身可以将y改为n,节省烧录耗时。
2. 最后开发套件的调试USB接口,打开开关,并使用这个命令进行烧录。
lisa zep exec cskburn -s PORT -C 60x000000 --verify-all ./build/zephyr/zephyr.bin -b1500000
其中的 PORT 代表开发套件连接到 PC上对应的串口号。例如:/dev/ttyUSB0。
效果测试
在执行以上步骤之后算法模型已经成功烧录到开发套件上。接下来我们可以测试实际运行效果。将开发板上的摄像头对准键盘,屏幕上会显示摄像头采集的图像并进行拍照。由图可以看到此时模型已经给出正确推理结果:Keyboard.

模型的替换
掌握如何编译上路现有资源之后,在开发过程中可以尝试将其替换成自己的模型进行推理。
- 打包成二进制之后的模型文件位于 resources/images/model.bin,您可以将它替换为自己的模型。其偏移值和长度在 boards/csk6 duomotai devkit.overlay 中定义
res_thinker_model_partition:partition@300000 {
label = "thinker_model";
reg = <0x00300000 2932416>;
};注:更新配置文件csk6 _duomotai_devkit.overlay 的res_thinker_model_partition部分中的reg属性,偏移值0X00300000保持不变。除非特殊情况,例如新增硬件组件、更改硬件布局以适应新组件或者软件需求等。你需要将旧模型的大小2932416替换为新模型的大小,以字节为单位。
更换模型之后可以使用前述方法收入整个bin文件,也可以指定CONFIG_APLICATION_PACK _IMAGES=n ,使用cskburn单独上路模型文件:
lisa zep exec cskburn -C 6-b 1500000 -s PORT 0x300000 resources/images/model.bin
注意:其中 PORT 代表开发板在电脑上的串口号
推理接口介绍
Thinker 是聆思 LNN 工具链 在 CSK6 芯片上的执行器。Thinker 执行器本体在芯片的 CP 上运行,通过 Thinker 服务暴露给 AP 远程调用。
Thinker服务使用流程如下,包括初始化、启动、获取数据、加载模型、推理停止和您初始化等步骤。

当使用Thinker 服务时,首先需要初始化Thinker 服务,通过调用think_service_gcs_init()的函数完成服务的初始化工作。运行Thinker ,通过调用think service gcs start函数服务开始执行任务。当服务开始运行时,我们需要获取外部数据。例如使用摄像头采集图像,一旦获得所需数据,我们可以调用think_service_gcs_forward函数加载模型,并获取该模型的内存使用状况。这个函数负责加载适当模型,并将其应用于输入数据进行推理。在模型加载完成后,我可以输出推理结果,根据加载模型对获取的数据进行推理,并将结果输出到指定位置。如果有更多数据需要处理,我们可以回到获取数据的步骤,继续获取外部数据,这样我可以循环处理多个数据样本。
最后当我们完成所有数据处理任务后,我们需要停止运行think服务。通过调用thinker_service_gcs_stop函数,服务将停止执行任务。
最后一步是逆初始化Thinker 服务,通过调用thinker_ service gcs_deinit()函数,我可以进行逆初始化操作,释放服务所使用的资源。
这些API参考的具体内容可以参考文末的资料链接,这里只介绍相对比较关键的模型推理函数。

如图所示,服务的标准输入和输出数据类型为 tData。服务提供了一个thinker_service_gcs_forward(inputs,input_cnt,*outputs,*output_cnt)接口,可以传入一个或同时传入多个 input,等待引擎推理,并返回一个或多个 output。输入和输出的张亮个数由当前所加载的模型决定。
在函数中第一个参数input表示输入张量,第二个参数表示input_cnt输入张量的个数,第三个参数outputs为指向输出张量的指针,即为该次推理的结果。第四个参数output_cnt位置向输出张量个数的指针,会被赋值为模型的output数。
在实践中,首先创建输入数据结构体input,设置其数据类型、缩放因子和形状信息,并将输入数据的指针赋值给input.dptr,声明输出结果的指针output和输出数量变量output_cnt。最后调用thinker_service_gcs_fourworks,函数执行推理操作将结果存储在output中。
以上为算法模型部署到大模型开发板的相关讲解,可以结合实操视频理解:
 https://www.bilibili.com/video/BV1Tu4m1M7ha?vd_source=5bc4be50ddf65370d8b5cadb25a6e836
https://www.bilibili.com/video/BV1Tu4m1M7ha?vd_source=5bc4be50ddf65370d8b5cadb25a6e836实例中使用的聆思大模型开发板的详细信息可以从官方开发文档了解:套件简介 | 聆思文档中心

















 877
877

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









