







信息概要
🙋面向对象:入门深度学习、数据清洗综合复习或入门学习者
✍️笔记日期:2024.08.07
💫所需基础:确保已安装pandas、numpy、os库
👀文章内容参考资料与总结
- 基于《动手学深度学习-Pytorch版(2.0.0)》 (Aston Zhang, Zachary C. Lipton etc.) 总结笔记,包括os库使用、文件数据的创建、读取数据集、缺失值处理、numpy转换为张量
- 基于 GitHub课本源码 进行修改、拓展,添加必要注释
- 基于Python机器学习入门到高级:数据清洗(含详细代码)_数据清洗python算法-CSDN博客提供的数据形式总结基于pandas库的基础数据清洗与分析方法、应用
- 包含了练习所需的几份数据的生成代码与方法(主要来自以上三个参考资料),确保代码可复现
- 注:运行代码块时,需确保已导入以下包且代码块之间,前后具有相关关系
- import pandas as pd
- import numpy as np
- import os
正文
✍️os库的使用
- os库常用于创建文件夹、文件,文中主要用来创建所需处理的数据文件
- 创建文件夹:os.makedirs()
- 连接路径:os.path.join()
- 打开文件:with open() 方法,as f表示打开datafile后用f来表示
- 写入数据:f.write()
import os
print('1. os库:创建文件路径')
# 创建文件夹,exist_ok=True表示如果文件夹已存在,则不会报错;此处表示创建 ../data/ 文件夹(在上级目录创建data文件夹)
os.makedirs(os.path.join('..', 'data'), exist_ok=True)
# 创建文件,逐级创建文件路径,最后一个表明文件名为house_tiny.csv:生成../data/house_tiny.csv文件
datafile = os.path.join('..', 'data', 'house_tiny.csv')
with open(datafile, 'w') as f:
# 往文件中写数据,\n来区分每一行,NA表示为空值
f.write('NumRooms,Alley,Price\n') # 列名
f.write('NA,Pave,127500\n') # 第1行的值
f.write('2,NA,106000\n') # 第2行的值
f.write('4,NA,178100\n') # 第3行的值
f.write('NA,NA,140000\n') # 第4行的值
✍️读取数据
- 使用pandas库来读取文件:csv文件用pd.read_csv()方法,xls文件用pd.read_excel()方法
- 按索引定位文件:用iloc[]方法来定位数据,与上一节tensor-索引与切片操作类似。可以自由地实现只读取前几行、前几列等;在进行监督学习任务时,通常需要获取特征列与标签列,可以用iloc语法实现
- 只查看前几行:用head()语法,参数为空时默认是只查看前5行,若不为空可以指定具体行数
- 查看对应形状:通过shape 属性获取
[ 在后面基于pandas的应用对此部分内容进行拓展 ]
import numpy as np
data = pd.read_csv(datafile) # 可以看到原始表格中的空值NA被识别成了NaN
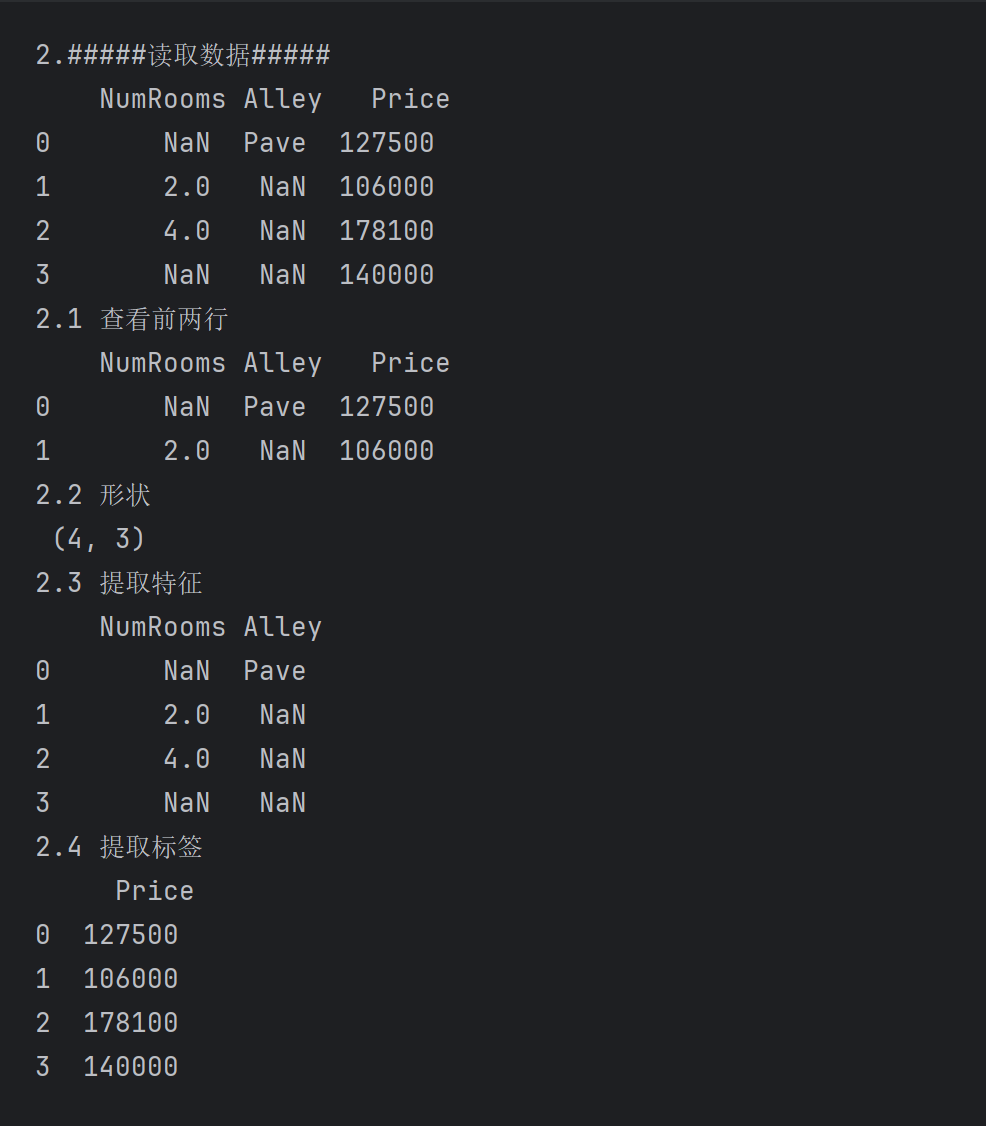
print('2.#####读取数据#####\n', data)
# iloc:根据索引位置获得数据
# .iloc[:, 0: -1]表示从0开始,:表示所有行,0:-1,表示获取从第0列到最后一列(不包括最后一列)
# .iloc[:, -1:] 表示从0开始,:表示所有行,-1:表示获取最后一列
inputs, outputs = data.iloc[:, 0: -1], data.iloc[:, -1:]
print("2.1 查看前两行\n",data.head(2))
print("2.2 形状\n",data.shape)
print('2.3 提取特征\n', inputs)
print('2.4 提取标签\n', outputs)
✍️处理缺失值
- 判断缺失值的方法: ① 用isnull()方法来返回对应具体存在缺失值的行 ② 用isnull().any()方法来判断是否存在具有缺失值的列,返回True / False (True表示存在缺失值)
- 将某个位置处理为缺失值:用np.nan表示缺失值(replace语法后面扩展)
- 处理缺失值的方法:① 填充 fillna()方法② 将缺失数据处理为独热编码即get_dummies()方法
- 填充缺失值的方法(此处创建新的dataframe对象来实践该过程)
- 用均值填充
- 常数统一填充
- 设计字典按列填充
- 向前or向后填充,默认是按最其前面行或者后面行的非缺失数值进行填充,axis=1表示按列进行填充
- 指定位置进行填充
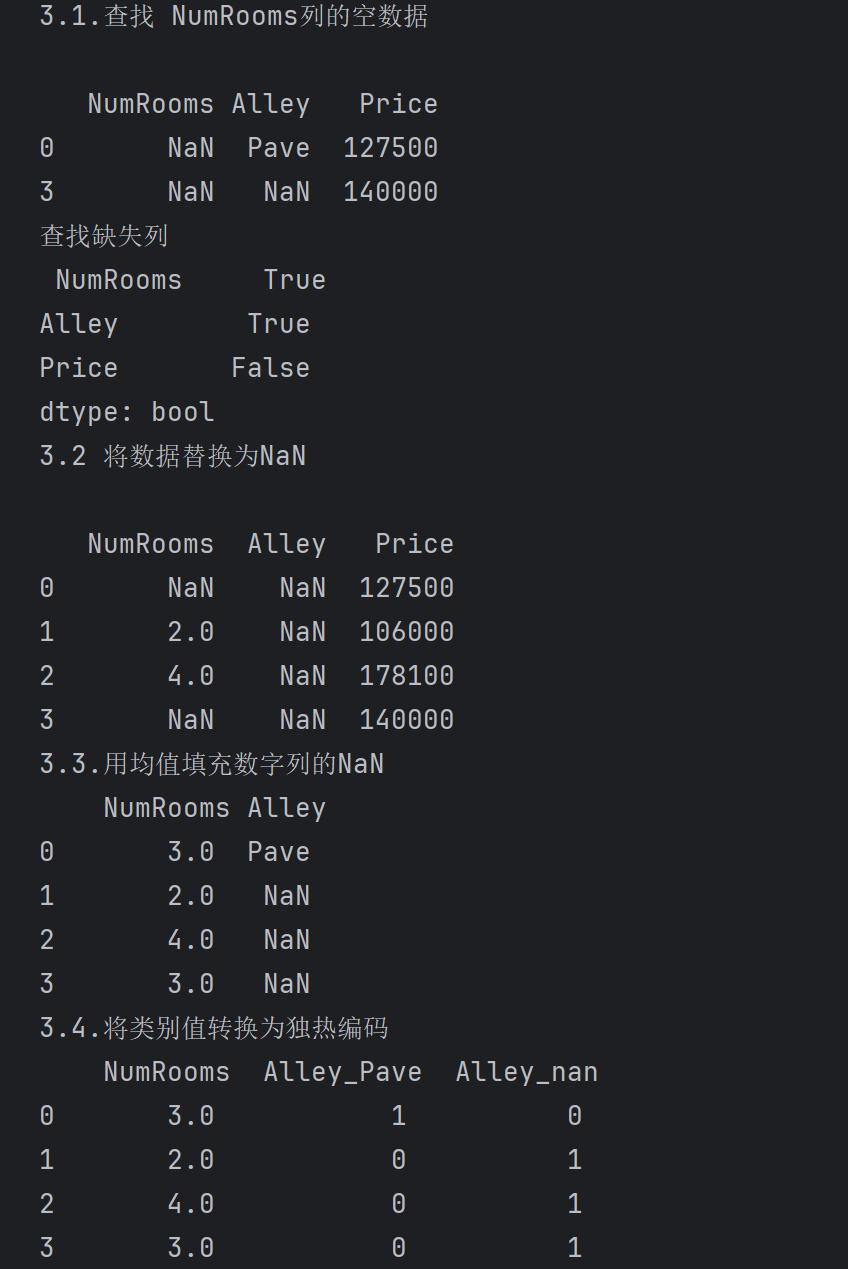
print('3.#####处理缺失值#####')
print('3.1.查找 NumRooms列的空数据\n')
# 查找空数据NaN,表示查找文件中的NumRooms列中空数据NaN的行
print(data[data['NumRooms'].isnull()])
# isnull.any(),True表示存在缺失值,False表示不存在缺失值
print('查找缺失列\n', data.isnull().any())
print('3.2 将数据替换为NaN\n')
# 使用numpy语法,将该列的Pave替换为NaN
data['Alley'] = data['Alley'].replace('Pave',np.nan)
print(data)
# 用均值填充NaN,用fillna()方法进行缺失值替换
### inplace=True直接修改原对象,默认不修改原对象
inputs.fillna(inputs.mean(),inplace=True)
print('3.3.用均值填充数字列的NaN\n', inputs )
# get_dummies() 是 pandas 中用于执行独热编码的函数,对于类别值或离散值,我们将 “NaN” 视为一个类别
# 由于只存在NaN与Pave两种类别,将分类变量转换为一组新的二进制特征1,0
inputs = pd.get_dummies(inputs, dummy_na=True)
print('3.4.将类别值转换为独热编码\n', inputs)
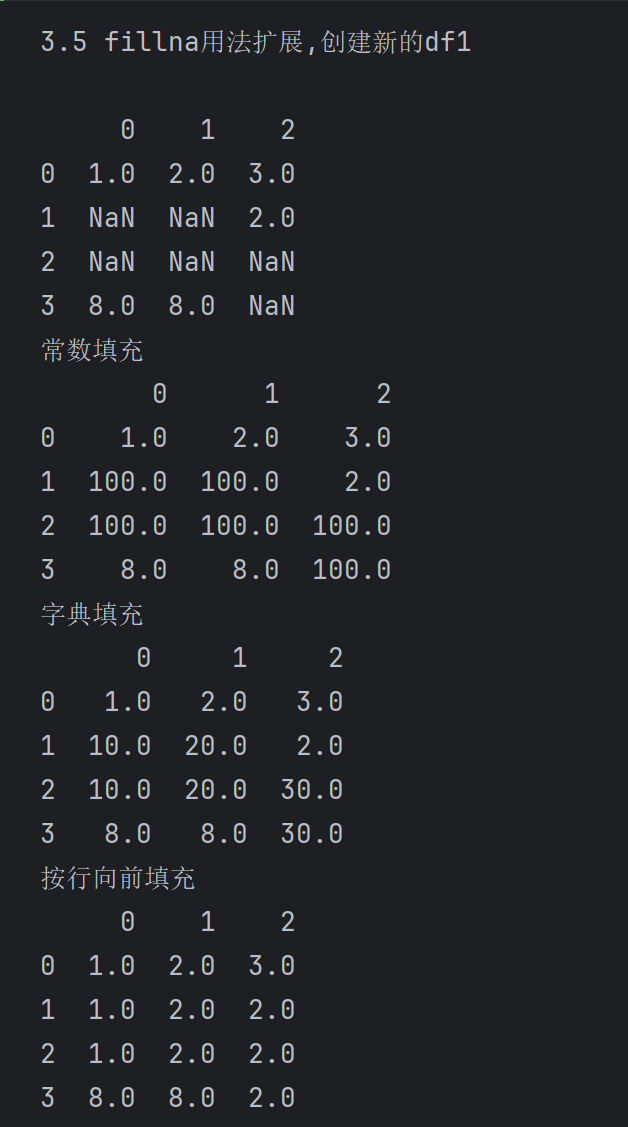
print('3.5 fillna用法扩展,创建新的df1\n')
df1 = pd.DataFrame([[1, 2, 3], [NaN, NaN, 2], [NaN, NaN, NaN], [8, 8, NaN]]) # 创建初始数据
# df2 = pd.DataFrame(np.random.randint(0, 10, (5, 5))) # 随机创建一个5*5
print(df1)
# 用常数填充NaN,inplace= True直接修改原对象,默认不修改原对象,因此打印出来的结果并没有修改在原来的df1上
print('常数填充')
print(df1.fillna(100))
# 基于字典填充NaN,0列用10填充,1列用20填充,2列用30填充
print('字典填充')
print(df1.fillna({0: 10, 1: 20, 2: 30}))
print('按行向前填充')
print(df1.fillna(method='ffill')) # 向前填充的方法:默认表示用前一行的数值来填充
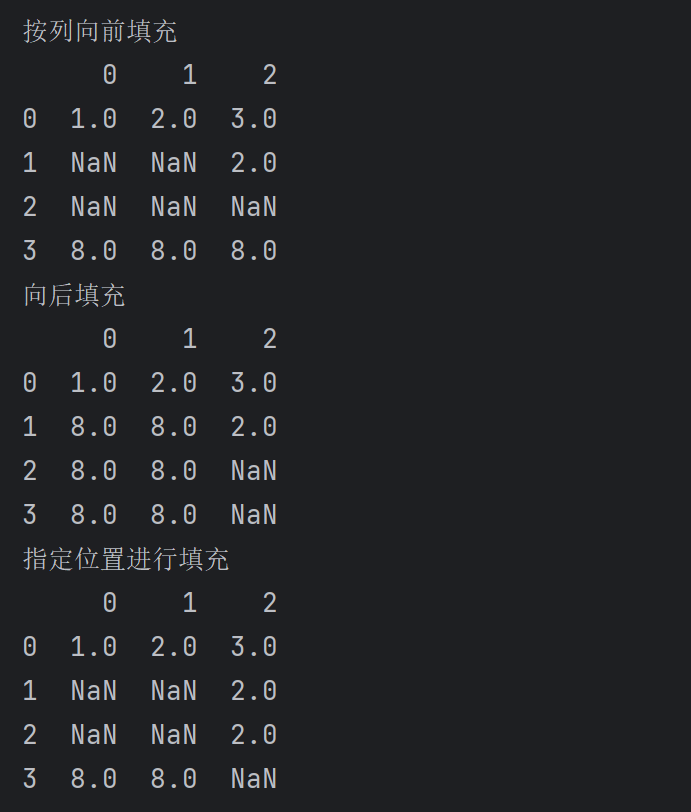
print('按列向前填充')
# 限制填充个数与按列填充,axis=1,用前一列的数值来填充,若最前列也缺失,则无法填充
print(df1.fillna(method='ffill', limit=1,axis=1))
# print(df1.fillna(0, inplace=True))
print('向后填充')
# 向后填充的方法:表示用后一行的数值来填充,可以观察若最后一行缺失则无法填充
print(df1.fillna(method='bfill'))
print('指定位置进行填充')
df1.iloc[2, 2] = 2 # 第三行第三列赋值,直接在原来的df1上修改
print(df1)
✍️Numpy转换为张量
- 用torch.tensor()方法将前面读取数值获得的标签进行转换为张量
注:inputs.values是numpy.ndarray类型
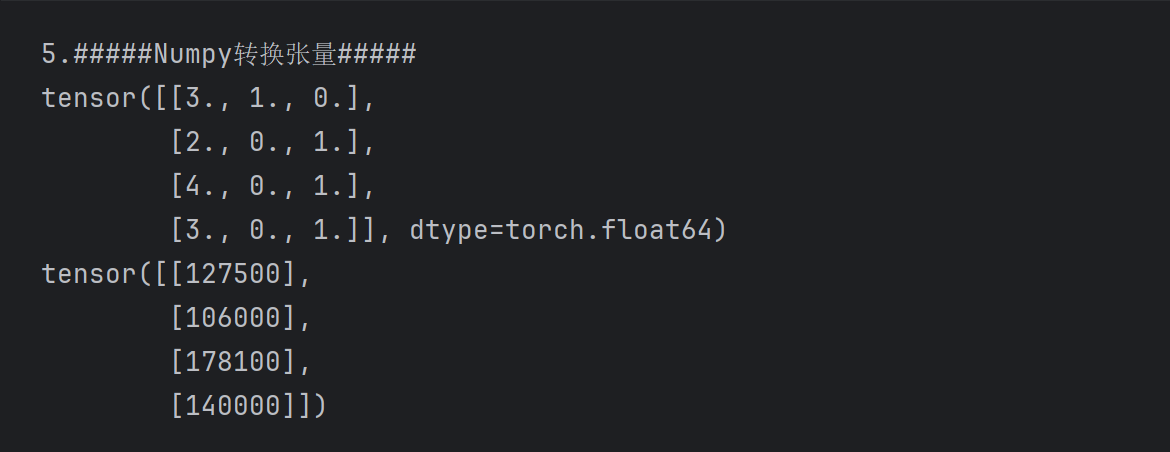
print('5.#####Numpy转换张量#####')
# print(type(inputs.values)) # <class 'numpy.ndarray'>
# 其它类型转换为torch.Tensor类型(复习上一节-张量关于Python间对象转换知识点)
x, y = torch.tensor(inputs.values), torch.tensor(outputs.values)
print(x)
print(y)
✍️拓展:基于pandas的数据清洗应用
- 参考链接:Python机器学习入门到高级:数据清洗(含详细代码)_数据清洗python算法-CSDN博客
- 练习数据:将上面链接中提供的结果数据复制到excel表格作为练习数据(如下),另存为.xls文件(用五行数据也可以练习🤣)
注意:当保存为xlsx文件,用pandas库进行读取时可能报错,进行另存.xls后缀文件即可读取
| PassengerId | Survived | Pclass | Name | Sex | Age | SibSp | Parch | Ticket | Fare | Cabin | Embarked |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 0 | 3 | Braund, Mr. Owen Harris | male | 22 | 1 | 0 | A/5 21171 | 7.25 | NaN | S |
| 2 | 1 | 1 | Cumings, Mrs. John Bradley (Florence Briggs Th… | female | 38 | 1 | 0 | PC 17599 | 71.2833 | C85 | C |
| 3 | 1 | 3 | Heikkinen, Miss. Laina | female | 26 | 0 | 0 | STON/O2. 3101282 | 7.925 | NaN | S |
| 4 | 1 | 1 | Futrelle, Mrs. Jacques Heath (Lily May Peel) | female | 35 | 1 | 0 | 113803 | 53.1 | C123 | S |
| 5 | 0 | 3 | Allen, Mr. William Henry | male | 35 | 0 | 0 | 373450 | 8.05 | NaN | S |
⏩ 读取数据
- 读取前x行:.head()
- 读取后x行:.tail()
- 读取前几列or后几列:用iloc()方法结合切片操作
- 读取大写字母形式的字符串:str.upper()方法
import pandas as pd
import xlrd
print('6.#####pandas库的性质#####')
# 当.xlsx文件读取报错时,将xlsx文件另存为.xls文件即可
df2 = pd.read_excel('practice_data.xls',header=0)
print('#####6.1读取数据#####\n')
print('读取前五行\n',df2.head(5))
print('读取后五行\n',df2.tail(5))
print('读取前两列\n',df2.iloc[:,0:2])
print('读取后两列\n',df2.iloc[:, -2:])
print('用大写字母读取Name列\n',df2['Name'].str.upper()) # Name中的字母用大写字母来读取,注意用的是 .str.upper()方法
⏩ 分析数据
- 属性包括:形状(shape)、数据类型(dtypes)、数据列名(columns)、行属性(index)
- 数据信息与描述方法区别:
- 用info()方法,可以得到其行数、列数,每列的缺失情况和数据类型,内存使用情况
- 用describe()方法:可以得到每列的均值、总数量、方差、最小值最大值等信息
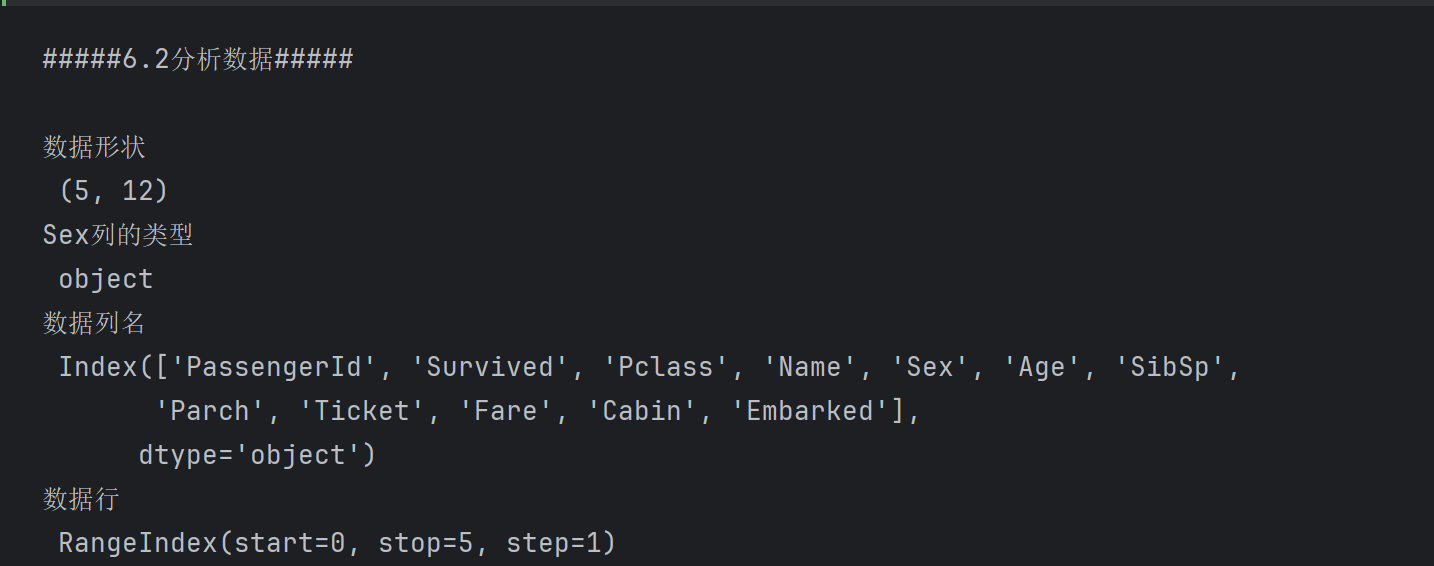
print('#####6.2分析数据#####\n')
print('数据形状\n',df2.shape)
print('Sex列的类型\n',df2.dtypes['Sex']) # 不加上['Sex']返回全部列的数据类型
print('数据列名\n',df2.columns)
print('数据行\n',df2.index) # RangeIndex(start=0, stop=5, step=1),表示从0开始,到5结束,步长为1
print('数据信息\n')
# RangIndex表示行数,entries表示索引范围,Data columns计算总列数和每列的名称以及每列的非空个数
# dtypes表示数据类型,memory_usage表示内存使用情况
print(df2.info())
print('数据描述\n',df2.describe()) # 包含每列的count、mean、std、min、25%、50%、75%、max
数据信息
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 5 entries, 0 to 4
Data columns (total 12 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 PassengerId 5 non-null int64
1 Survived 5 non-null int64
2 Pclass 5 non-null int64
3 Name 5 non-null object
4 Sex 5 non-null object
5 Age 5 non-null int64
6 SibSp 5 non-null int64
7 Parch 5 non-null int64
8 Ticket 5 non-null object
9 Fare 5 non-null float64
10 Cabin 2 non-null object
11 Embarked 5 non-null object
dtypes: float64(1), int64(6), object(5)
memory usage: 608.0+ bytes
None
数据描述
PassengerId Survived Pclass Age SibSp Parch Fare
count 5.000000 5.000000 5.000000 5.00000 5.000000 5.0 5.000000
mean 3.000000 0.600000 2.200000 31.20000 0.600000 0.0 29.521660
std 1.581139 0.547723 1.095445 6.83374 0.547723 0.0 30.510029
min 1.000000 0.000000 1.000000 22.00000 0.000000 0.0 7.250000
25% 2.000000 0.000000 1.000000 26.00000 0.000000 0.0 7.925000
50% 3.000000 1.000000 3.000000 35.00000 1.000000 0.0 8.050000
75% 4.000000 1.000000 3.000000 35.00000 1.000000 0.0 53.100000
max 5.000000 1.000000 3.000000 38.00000 1.000000 0.0 71.283300
⏩ 筛选与分组数据
- 筛选数据可以类比一个查询过程,用pandas语法对数据实现查找
- 为方便展示查询结果:在代码运行结果展示会时一般只展示相关列,表明查询正确
- 查询条件设计:结合了逻辑运算符,比较运算符等,可以对查询结果进行求均值、切片操作等
- 数据的类别信息
- 获取某列存在的类别数量:nunique()方法
- 获取类别名称: unique()方法
- 获取每个类别的数量:values_counts(),可以结合plot方法进行可视化,可以对获取的数量进行归一化处理
- 按照该列对整体数据直接分类(分类、求均值、排序、计数):用groupby()方法,结合mean()方法对获得分类后全部列的均值、可以进一步用sort_values()方法进行排序、用count()方法获取每个类别的数量
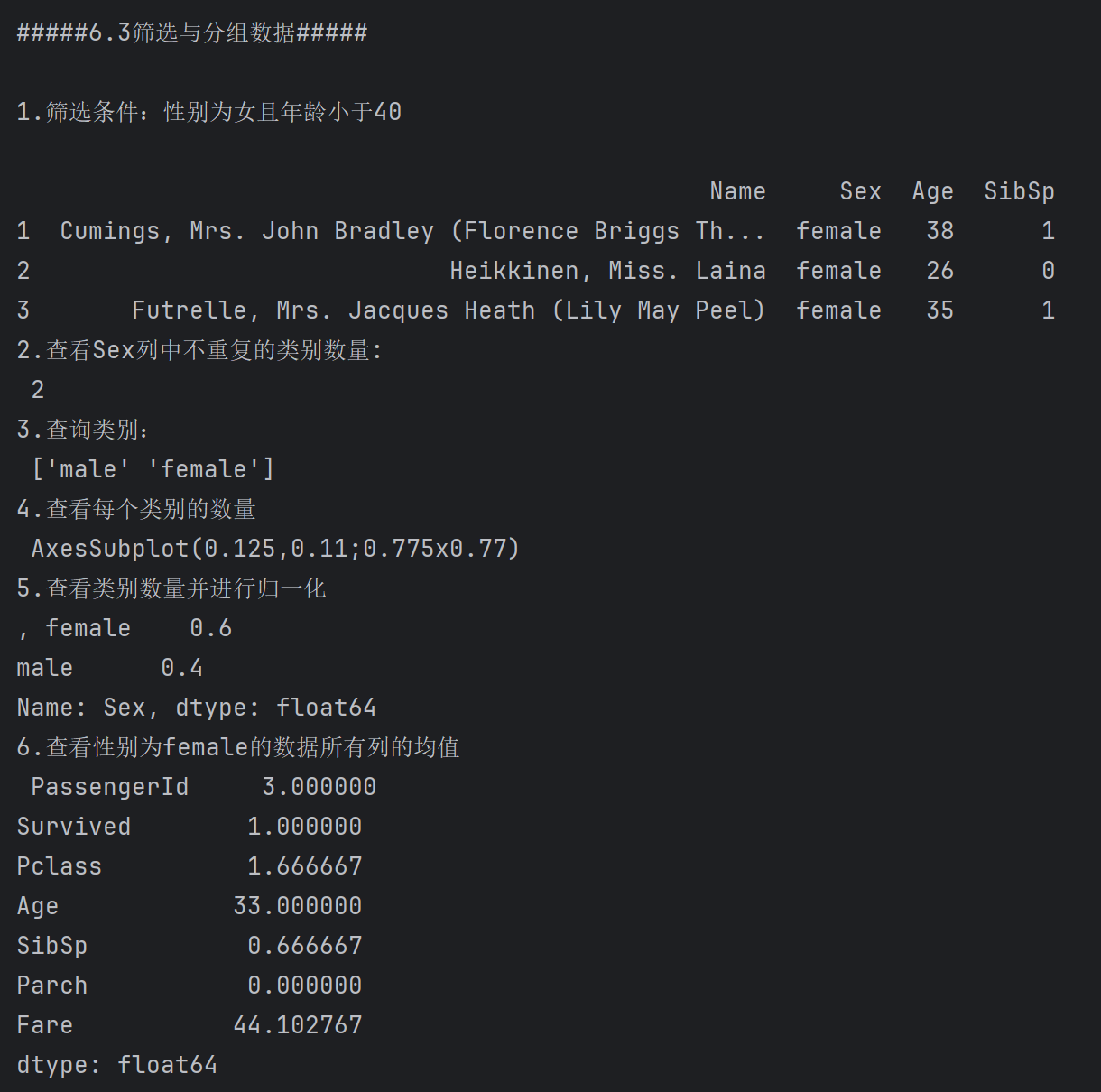
print('#####6.3筛选与分组数据#####\n')
print('1.筛选条件:性别为女且年龄小于40\n')
# 筛选条件:性别为女且年龄小于40 ,df2作为最外层,用括号将条件括起来,用&连接条件
print(df2[(df2['Sex']=='female')&(df2['Age']<40)].iloc[:,3:7])
print('2.查看Sex列中不重复的类别数量:\n', df2['Sex'].nunique()) # 查看Sex列中不重复的类别数量
print('3.查询类别:\n',df2['Sex'].unique()) # 查看Sex列中所有不重复的值,可以理解为得到里面的不重复类别的列表
# 查看Sex列中每个类别的数量并绘图
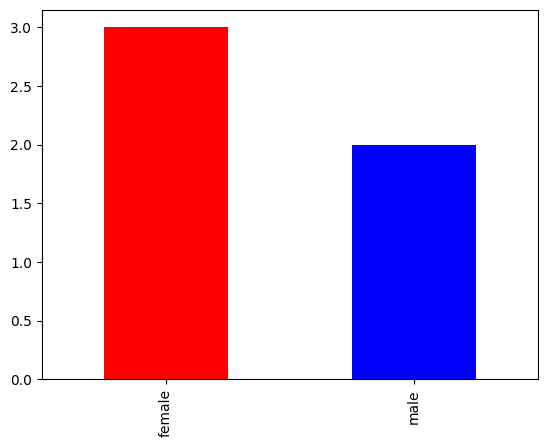
print('4.查看每个类别的数量\n',df2['Sex'].value_counts().plot(kind='bar',color={'blue','red'}))
# 查看Sex列中每个类别的数量,并归一化
print('5.查看类别数量并进行归一化\n,',df2['Sex'].value_counts(normalize=True))
# 查看性别为女的数据所有列的均值
print('6.查看性别为female的数据所有列的均值\n',df2[df2['Sex']=='female'].mean())
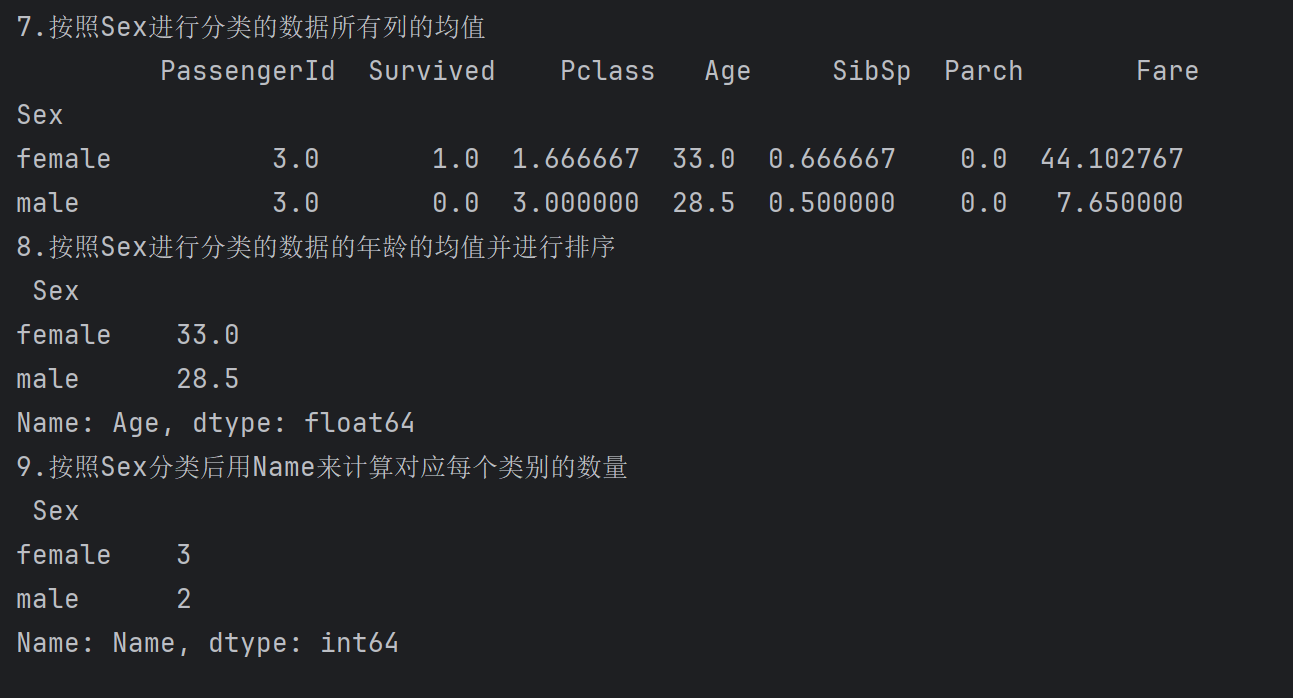
# 按照Sex进行分类的数据所有列的均值
print('7.按照Sex进行分类的数据所有列的均值\n',df2.groupby('Sex').mean())
print('8.按照Sex进行分类的数据的年龄的均值并进行排序\n',df2.groupby('Sex').mean()['Age'].sort_values(ascending=False)) # 表示升序排序
# 查看性别为female的数据所有列的个数
print('9.按照Sex分类后用Name来计算对应每个类别的数量\n',df2.groupby('Sex')['Name'].count())
⏩ 修改数据
- 修改数据方法:replace()方法
注意:需要在左侧也将对应列[‘Sex’]写上,才能实现在原来的dataframe上进行修改
- 修改列名:ename()方法
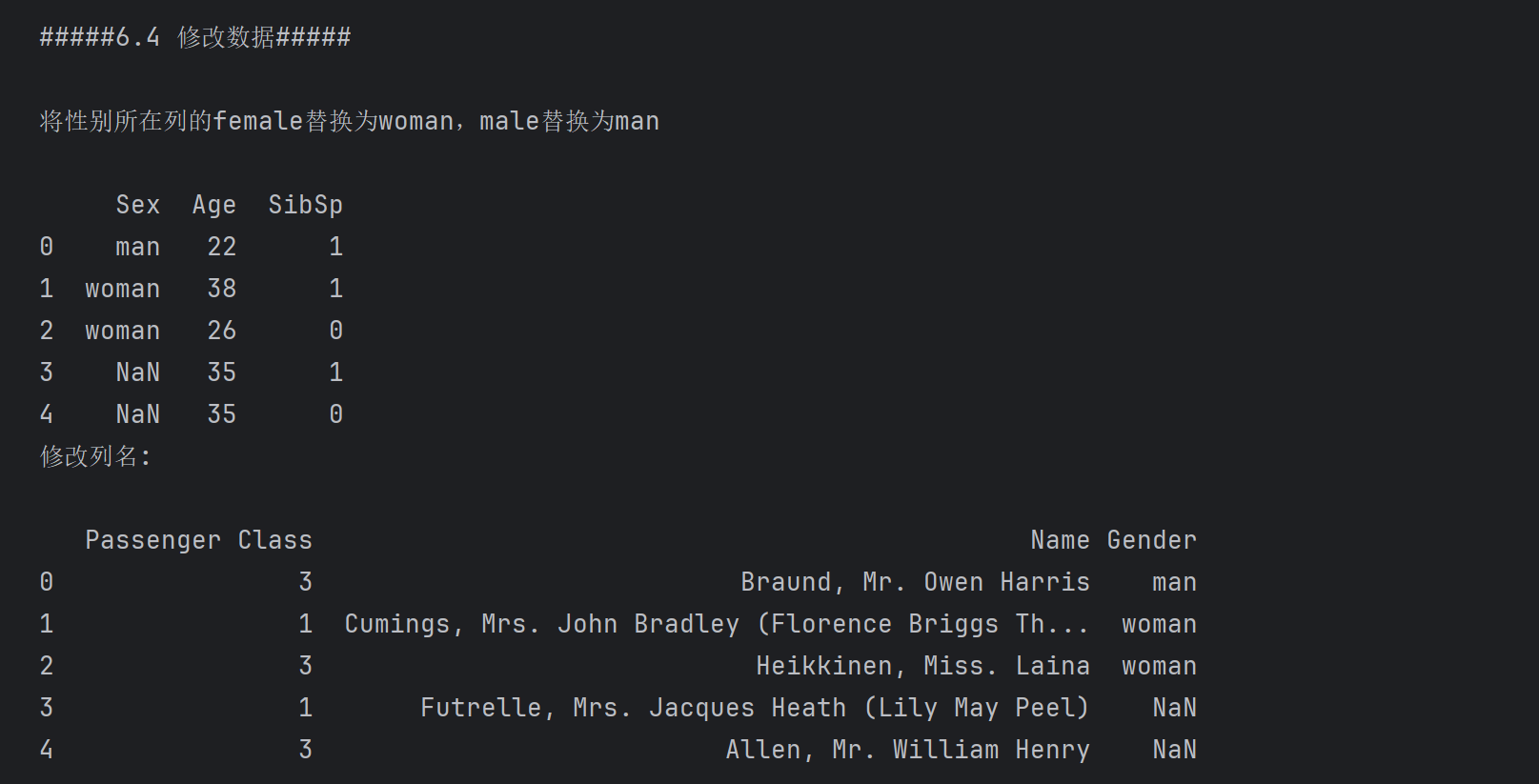
print('#####6.4 修改数据#####\n')
print('将性别所在列的female替换为woman,male替换为man\n')
#### 注意: 修改时,需要df2['Sex'] 在左侧,才能修改原来的结果;head(3)表示修改前三行的数据,其它行的对应值变成NaN
df2['Sex'] = df2['Sex'].replace(['female','male'],['woman','man']).head(3)
print(df2.iloc[:,4:7])
# 指定inplace=True,不需要将结果赋给df2,df2进行了修改
print('修改列名:\n')
df2.rename(columns={'Pclass':'Passenger Class','Sex':'Gender'},inplace=True)
print(df2.iloc[:,2:5])
⏩ 删除数据
- 删除方法:用drop()方法实现,axis=1表示按列删除;第一个参数可以是列名,也可以是数字(没有指定时表示删除索引为1的行)
- 删除重复行:subset指定按照哪个列的重复值进行删除,此处示例的是Gender行,按照前面替换列的数据处理结果,Gender存在man、woman、NaN三种,因此剩下三列
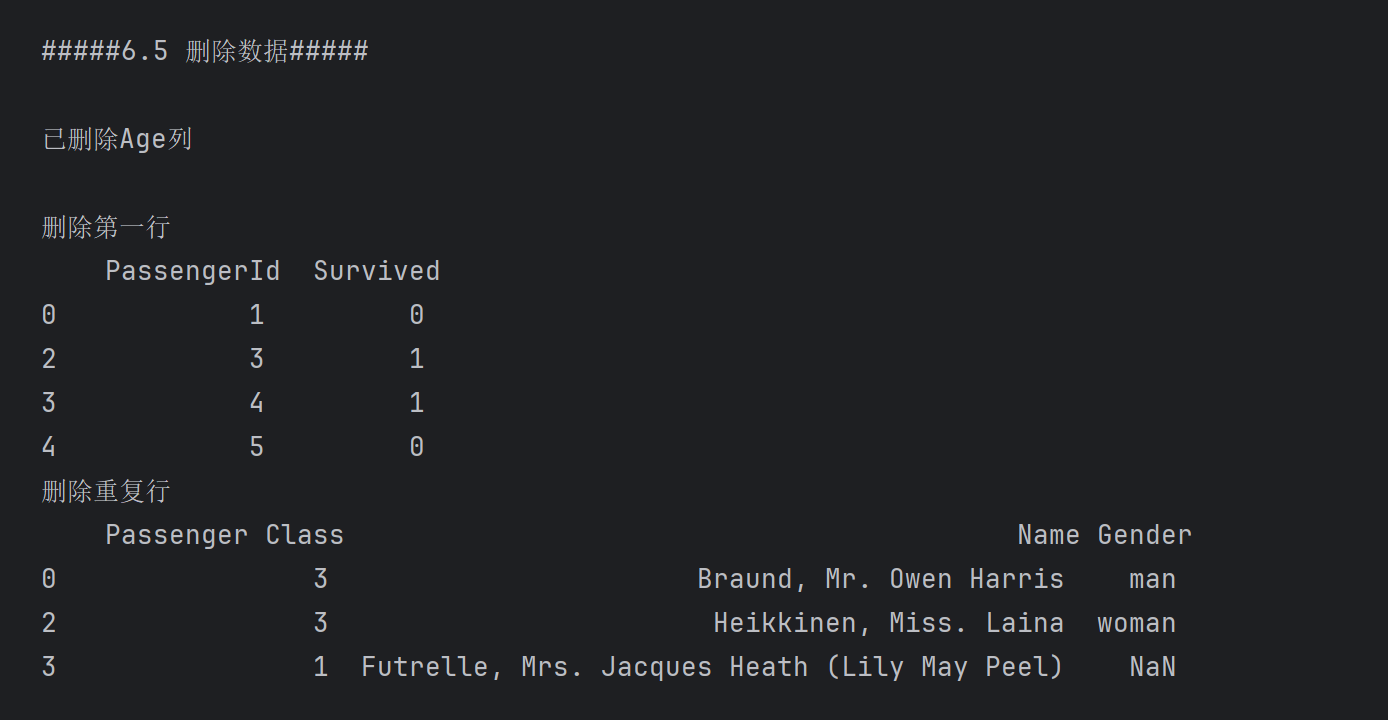
print('#####6.5 删除数据#####\n')
df2.drop('Age',axis=1,inplace=True)
print('已删除Age列\n' if 'Age' not in df2.columns else 'Age存在') # 删除Age列,axis=1表示删除列
df2.drop(1,inplace=True) # 删除索引为1的行
print('删除第一行\n',df2.iloc[:,0:2])
df2.drop_duplicates(subset='Gender',inplace=True)# 删除重复行,subset='Sex'表示只考虑Sex列,默认考虑所有列
print('删除重复行\n',df2.iloc[:,2:5])
⏩ 添加与合并数据
- 创建时间序列数据:date_range方法用于创建时间序列,可以指定开始时间、生成个数、时间间隔
- 创建随机数据:用np.random.seed()方法可以指定随机种子,使得后面用np.random.randint()方法生成的随机数字相同可复现
- 创建dataframe:pd.DataFrame方法,可以指定index索引和columns列名
- 若以时间序列作为index:则可实现按照一定的频率进行求和、个数、均值求解
- 合并DataFrame:用pd.concat语法,指定axis=0按行合并 或者 axis=1 按列合并;append方法也可以实现添加到对应的行并重新构成新的dataframe,
print('#####6.6 添加与合并数据#####\n')
np.random.seed(4) # 设定随机种子,可以使得生成的随机数字相同
# 创建一个时间序列,从06/06/2017开始,每一个月1M or 五天5D 为一个时间点,periods指定个数
# time_index = pd.date_range('06/06/2017', periods=10, freq='1M')
time_index = pd.date_range('06/06/2017', periods=10, freq='5D')
df3 = pd.DataFrame(index=time_index, columns=['Sale_Amount'])# 用time_index来创建df对象并指定列名
df3['Sale_Amount'] = np.random.randint(1, 20,10) # 对Sale_Amount列进行赋值,随机生成10个1-20之间的整数
# resample 参数,按周对行分组(根据time_index),计算每一周的总和
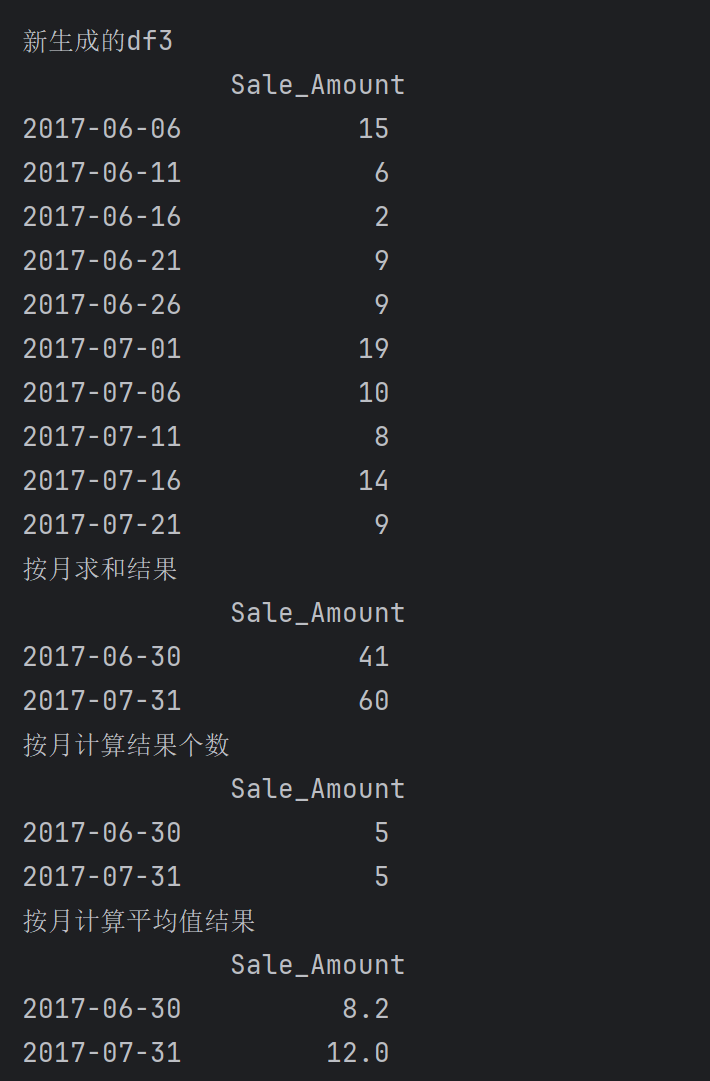
print('新生成的df3\n',df3)
print('按月求和结果\n',df3.resample('M').sum())
print('按月计算结果个数\n',df3.resample('M').count())
print('按月计算平均值结果\n',df3.resample('M').mean()) # sum除以count
# 用字典的形式创建列表,形成dataframe形式
data_a = {'id':['1', '2', '3'],
'first': ['Alex', 'Amy', 'Allen'],
'last': ['Anderson', 'Ackerman', 'Ali']}
dataframe_a = pd.DataFrame(data_a, columns=['id','first', 'last'])
data_b = {'id':['4', '5', '6'],
'first': ['Billy', 'Brian', 'Bran'],
'last': ['Bonder', 'Black', 'Balwner']}
dataframe_b = pd.DataFrame(data_b, columns=['id','first', 'last'])
### 由于id、First、last是原来没有的列,因此会自动在df2后面添加这三列,原来的样本(行)对应这些列的值都为NaN
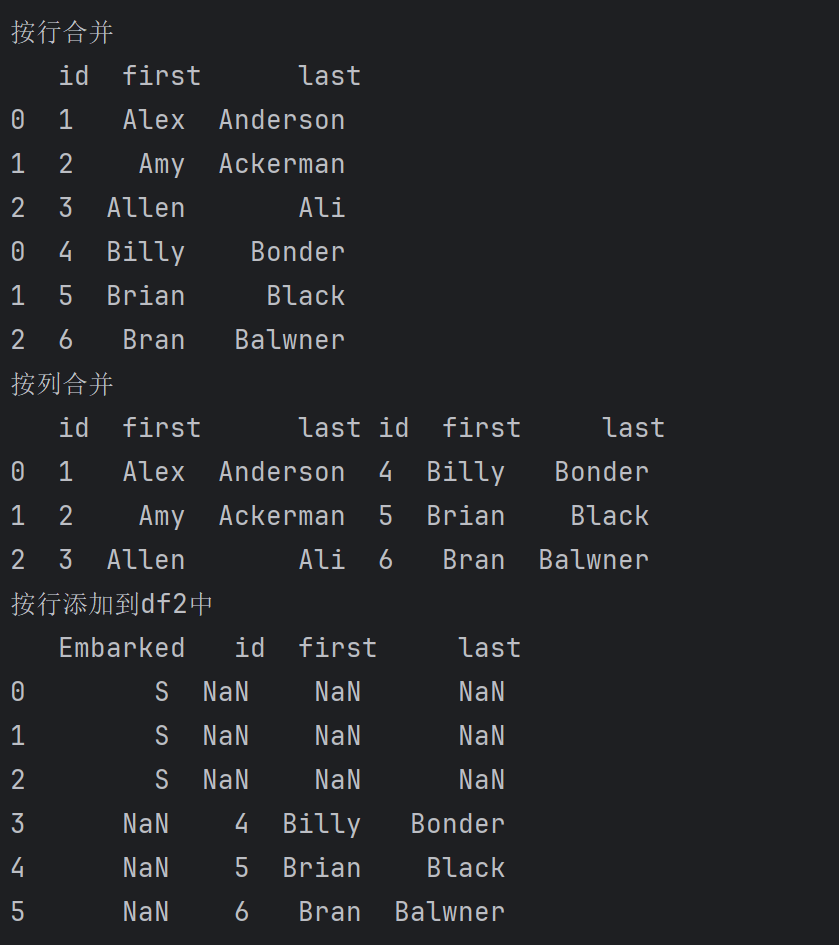
print('按行合并\n', pd.concat([dataframe_a,dataframe_b],axis=0))
print('按列合并\n', pd.concat([dataframe_a,dataframe_b],axis=1))
# append表示将dataframe_b添加到df2中(作为新行),ignore_index=True表示不保留原来的索引,重新生成索引
print('按行添加到df2中\n',df2.append(dataframe_b, ignore_index=True).iloc[:,-4:])















 6万+
6万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









