






在这篇博客中,我将向大家分享一个我最近开发的 Python 程序,它可以将存储在 Markdown 文件中的记账记录自动添加到 Excel 文件中。这个程序非常实用,尤其适合像我这样想要简单管理个人财务记录的新手。
实现思路:
1.整体功能
我们的程序主要由三个函数组成:
read_markdown(file_path):读取 Markdown 文件并解析其中的记账记录。add_records_to_excel(records, excel_file_path):将解析出来的记账记录添加到 Excel 文件中。main():主函数,调用上述两个函数完成整个流程。
2.函数详解
read_markdown(file_path) 函数
import re
import pandas as pd
from datetime import datetime
def read_markdown(file_path):
records = []
with open(file_path, 'r', encoding='utf-8') as file:
for line in file:
# 使用正则表达式匹配 Markdown 中的记账记录
match = re.match(r'^(.*?)\s+(.*?)\s+([-+]?\d+(?:\.\d+)?)\s+(.*)$', line.strip())
if match:
category, description, amount_str, payment_method = match.groups()
amount = float(amount_str)
# 使用当前日期作为记录日期
date = datetime.now().strftime('%Y-%m-%d')
records.append([date, category, description, amount, payment_method])
return records在这个函数中,我们首先使用 open() 函数打开指定路径的 Markdown 文件,并逐行读取文件内容。对于每一行,我们使用 re.match() 函数结合正则表达式 ^(.*?)\s+(.*?)\s+([-+]?\d+(?:\.\d+)?)\s+(.*)$ 进行匹配,该正则表达式的解释如下:
^(.*?)\s+:匹配行首的任意字符,直到遇到第一个空格。(.*?)\s+:匹配第一个空格后的任意字符,直到遇到第二个空格。([-+]?\d+(?:\.\d+)?)\s+:匹配可能带有正负号的数字(可以是整数或小数),直到遇到第三个空格。(.*)$:匹配最后剩下的部分,直到行尾。
如果一行能成功匹配上述正则表达式,我们提取出类别(category)、描述(description)、金额(amount_str)和支付方式(payment_method),将金额转换为浮点数,并使用 datetime.now().strftime('%Y-%m-%d') 为这条记录添加当前日期。最后将这些信息作为一个列表添加到 records 列表中。
add_records_to_excel(records, excel_file_path) 函数
def add_records_to_excel(records, excel_file_path):
try:
# 尝试读取已有的 Excel 文件
df = pd.read_excel(excel_file_path)
except FileNotFoundError:
# 如果文件不存在,创建一个新的 DataFrame
df = pd.DataFrame(columns=['Date', 'Category', 'Description', 'Amount', 'Payment Method'])
# 将新记录转换为 DataFrame
new_records_df = pd.DataFrame(records, columns=['Date', 'Category', 'Description', 'Amount', 'Payment Method'])
# 将新的 DataFrame 与已有的 DataFrame 拼接
df = pd.concat([df, new_records_df], ignore_index=True)
# 将更新后的 DataFrame 写回 Excel 文件
df.to_excel(excel_file_path, index=False)在这个函数中,我们首先尝试使用 pd.read_excel() 函数读取已有的 Excel 文件。如果文件不存在,我们会创建一个新的 DataFrame,其列名为 ['Date', 'Category', 'Description', 'Amount', 'Payment Method']。然后,将解析得到的新记录 records 转换为一个新的 DataFrame,并使用 pd.concat() 函数将其与原有的 DataFrame 拼接。最后,使用 to_excel() 函数将更新后的 DataFrame 写回 Excel 文件,并设置 index=False 以避免存储行索引。
main() 函数
def main():
markdown_file_path = 'expenses.md'
excel_file_path = 'expenses.xlsx'
records = read_markdown(markdown_file_path)
add_records_to_excel(records, excel_file_path)
print("记录已成功添加到 Excel 文件中。")这个函数主要是设置 Markdown 文件和 Excel 文件的路径,注意:在这里两个文件都和我的源代码文件在同级目录下。调用 read_markdown() 函数读取记录,并将读取到的记录通过 add_records_to_excel() 函数添加到 Excel 文件中。最后输出一个成功的消息。
如何使用:
1.准备文件
首先,你需要准备一个MarkDown文件,文件格式如下:

注意:每一列之间只有一个空格符号,否则代码报错。
MarkDown文件中不用编写列名,在代码中的
add_records_to_excel(records, excel_file_path)函数中为我们创造出5个列名,分别是
| Date | Category | Description | Amount | Payment Method |
其中的date列在
read_markdown(file_path)函数中为我们创建好了,其格式是2025-1-18(具体日期以你运行代码的那天为准),你只需要按照“类别->描述->金额->支付方式”的顺序输入MarkDown文件中即可。
2.运行代码
运行之后,你会发现 expenses.xlsx 文件中已经包含了 expenses.md 中的记账记录,并且每次运行程序都会将新的记录添加到文件中。注意每次上传的MarkDown文件都要把旧的数据删除,否则Excel中有重复的数据。
3.样例展示
MarkDown文件:

Excel示例:
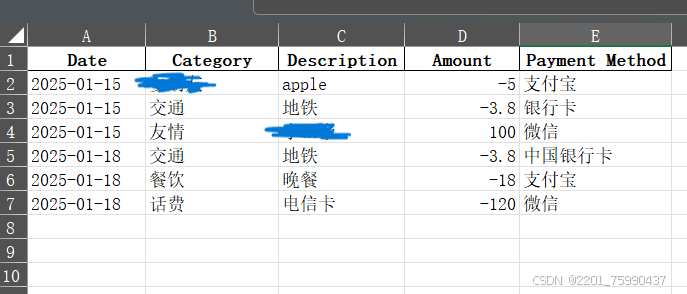
前3列是之前添加的数据,这次只运行了后3列。
总结
通过这个简单的 Python 程序,我们可以方便地将 Markdown 中的记账记录添加到 Excel 文件中,这样可以方便我们对财务数据进行更好的管理和分析。希望这篇博客对你有所帮助,如果你有任何问题或建议,欢迎在评论区留言!
以上博客通过详细解释代码的功能和使用方法,为你提供了一篇完整的 CSDN 博客内容。你可以根据自己的理解和体验,在博客中加入一些自己的代码编写过程中的感悟和遇到的问题及解决方法,这样可以让你的博客更加生动,对其他读者更有帮助。同时,你可以添加一些代码运行结果的截图,让你的博客更具说服力。你觉得怎么样呢 如果你对博客的内容或结构还有其他要求,可以告诉我,我可以为你提供更多帮助。

















 1668
1668

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









