






目录
2.基本python环境的准备。(python解释器的版本,推荐最新的版本)
一.关于Yolov5的介绍:
1.YOLO的基础概念:
Yolo算法采用一个单独的CNN模型实现end-to-end的目标检测,核心思想就是利用整张图作为网络的输入,直接在输出层回归 bounding box(边界框) 的位置及其所属的类别,整个系统如下图所示:
首先将输入图片resize到448x448,然后送入CNN网络,最后处理网络预测结果得到检测的目标。相比R-CNN算法,其是一个统一的框架,其速度更快。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-W7Rgq5YO-1646276606891)(笔记图片/image-20200915144129736.png)]](https://img-blog.csdnimg.cn/99eaad6ff3024b51aaa06538b355bc83.png?x-oss-process=image/watermark,type_d3F5LXplbmhlaQ,shadow_50,text_Q1NETiBA5pyA55m944Gu55m96I-c,size_20,color_FFFFFF,t_70,g_se,x_16)
2.YOLO算法的思维方式:
在介绍Yolo算法之前,我们回忆下RCNN模型,RCNN模型提出了候选区(Region Proposals)的方法,先从图片中搜索出一些可能存在对象的候选区(Selective Search),大概2000个左右,然后对每个候选区进行对象识别,但处理速度较慢。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-uIVmkMmT-1646276606892)(笔记图片/image-20200915150333995.png)]](https://img-blog.csdnimg.cn/644f586f3460443da571ed376141d332.png?x-oss-process=image/watermark,type_d3F5LXplbmhlaQ,shadow_50,text_Q1NETiBA5pyA55m944Gu55m96I-c,size_20,color_FFFFFF,t_70,g_se,x_16)
YOLO其字面含义就是You only look once, 它并没有真正的去掉候选区域,而是创造性的将候选区和目标分类合二为一,看一眼图片就能知道有哪些对象以及它们的位置。
Yolo模型采用预定义预测区域的方法来完成目标检测,具体而言是将原始图像划分为 7x7=49 个网格(grid),每个网格允许预测出2个边框(bounding box,包含某个对象的矩形框),总共 49x2=98 个bounding box。我们将其理解为98个预测区,很粗略的覆盖了图片的整个区域,就在这98个预测区中进行目标检测。

在得到这98个区域的目标分类和回归结果后,再进行NMS就可以得到最终的目标检测结果。那具体实现过程如下。
YOLO 的网络结构:
YOLO的结构非常简单,就是单纯的卷积、池化最后加了两层全连接,从网络结构上看,与前面介绍的CNN分类网络没有本质的区别,最大的差异是输出层用线性函数做激活函数,因为需要预测bounding box的位置(数值型),而不仅仅是对象的概率。所以粗略来说,YOLO的整个结构就是输入图片经过神经网络的变换得到一个输出的张量,如下图所示:
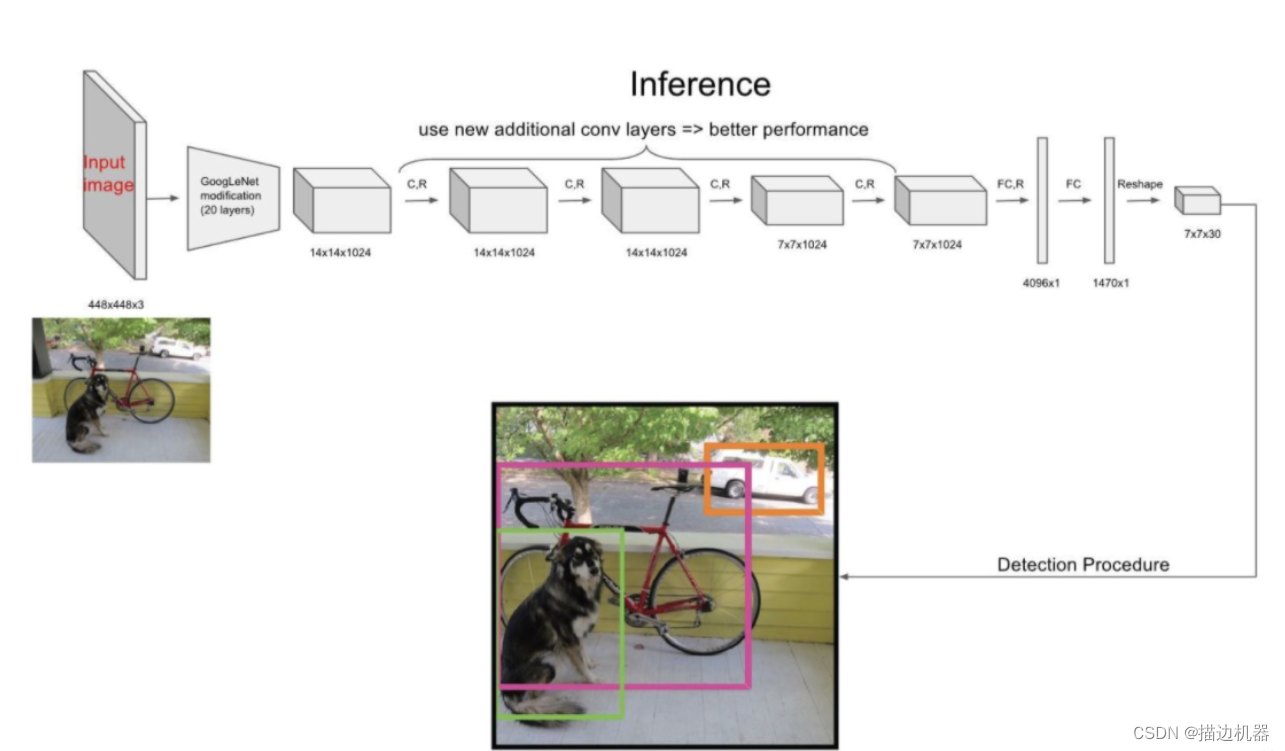
网络结构相对而言比较简单易于理解,最主要的还是理解网络输入和输出之间的关系。
网络输入:
网络的输入是原始图像,唯一的要求是缩放到448x448的大小。主要是因为Yolo的网络中,卷积层最后接了两个全连接层,全连接层是要求固定大小的向量作为输入,所以Yolo的输入图像的大小固定为448x448。
网络输出:
网络的输出就是一个7x7x30 的张量(tensor)。(如何理解是关键!!!)
7X7网格:
根据YOLO的设计,输入图像被划分为 7x7 的网格,输出张量中的 7x7 就对应着输入图像的 7x7 网格。或者我们把 7x7x30 的张量看作 7x7=49个30维的向量,也就是输入图像中的每个网格对应输出一个30维的向量。如下图所示,比如输入图像左上角的网格对应到输出张量中左上角的向量。

二.YOLO的使用范围和应用场景
目标检测的任务是从图片中找出物体并给出其类别和位置,对于单张图片,输出为图片中包含的N个物体的每个物体的中心位置(x,y)、宽(w)、高(h)以及其类别。
Yolo的预测基于整个图片,一次性输出所有检测到的目标信号,包括其类别和位置。Yolo首先将图片分割为sxs个相同大小的grid。
三.YOLO的使用
1.关于YOLOv5的配置条件:
# YOLOv5 requirements
# Usage: pip install -r requirements.txt# Base ----------------------------------------
matplotlib>=3.2.2
numpy>=1.18.5
opencv-python>=4.1.1
Pillow>=7.1.2
PyYAML>=5.3.1
requests>=2.23.0
scipy>=1.4.1 # Google Colab version
torch>=1.7.0
torchvision>=0.8.1
tqdm>=4.41.0
protobuf<4.21.3 # https://github.com/ultralytics/yolov5/issues/8012# Logging -------------------------------------
tensorboard>=2.4.1
# wandb# Plotting ------------------------------------
pandas>=1.1.4
seaborn>=0.11.0# Export --------------------------------------
# coremltools>=4.1 # CoreML export
# onnx>=1.9.0 # ONNX export
# onnx-simplifier>=0.3.6 # ONNX simplifier
# scikit-learn==0.19.2 # CoreML quantization
# tensorflow>=2.4.1 # TFLite export
# tensorflowjs>=3.9.0 # TF.js export
# openvino-dev # OpenVINO export# Extras --------------------------------------
ipython # interactive notebook
psutil # system utilization
thop # FLOPs computation
# albumentations>=1.0.3
# pycocotools>=2.0 # COCO mAP
# roboflow
2.YOLOv5的准备:
1.YOLOv5相关文件的下载:
GitHub - ultralytics/yolov5: YOLOv5 🚀 in PyTorch > ONNX > CoreML > TFLite
下载好后最好将其放置在空间比较大的区域(因为后期进行数据集训练,数据集的占用空间是很庞大的)
2.基本python环境的准备。(python解释器的版本,推荐最新的版本)
如何查看自己的python版本:(可以使用命令控制窗口进行查看)

这里最好的是是直接使用Anaconda进行相关操作,因为Anaconda安装好后里面会自动配置需要使用的python环境.
具体安装过程可以参考一下博客进行学习:
3.使用anaconda创建YOLOv5使用的环境。
这里需要在前期安装好的YOLOv5路径下进行配置环境,因为你所创建的环境是只为YOLO算法的运行所提供的环境。
这里需要在YOLOv5的路径下进行环境搭建,需要使用命令符“conda -n create yolov5 python=3.10"。(这里具体你需要创建的python环境根据对应使用YOLO的python版本确定,我个人推荐的是越新越好)。
四.结语。
以上只是关于YOLO算法的简单介绍,写下这篇博客更多的目的是为未来的复习和回顾打基础,文章仍然还有很多缺漏,还望各位客官老爷在评论区指出,感谢各位的观看。














 7万+
7万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









