




作者@小郭
4. awk 使用手册
awk 介绍
awk 是一个强大的文本分析工具。
awk 更像一门编程语言,他可以自定义变量,有条件语句,有循环,有数组,有正则,有函数等。
awk 按行读取数据,根据给出的条件进行查找,并在找出来的行中进行操作。
awk 有三种形势,awk,gawk,nawk,平时所说的awk其实就是gawk。
awk 是其取了三位创始人 Alfred Aho,Peter Weinberger, 和 Brian Kernighan 的 Family Name 的首字符。
使用 awk 可以完成无数的任务,我们简单的罗列几条:
- 文本处理
- 生成格式化的文本报告
- 运行一些简单的算术操作
- 执行一些常见的字符串操作
awk 命令
awk 命令格式
awk [options] 'script' file(s)
awk [options] -f scriptfile file(s)
script,定义如何处理数据。file,是 awk 处理的数据来源,awk 也可以来自其它命令的输出。-f scriptfile从脚本文件中读取awk命令,每行都是一个独立的script。
script 格式如下:
BEGIN { action }
pattern { action }
END { action }
脚本通常是被单引号或双引号包住,一个awk脚本通常由四部分组成:
-
BEGIN { action }语句块,awk 执行pattern { action }前要执行的脚本。 -
pattern { action }语句块,决定动作语句何时触发,可以是以下任意一种:- 正则表达式:使用通配符的扩展集。
- 关系表达式:使用运算符进行操作,可以是字符串或数字的比较测试。
- 模式匹配表达式:使用运算符
~(匹配)和~!(不匹配)。
-
END { action }语句块,awk 执行pattern { action }后要执行的脚本。 -
action部分,决定对数据如何处理,由一个或多个命令、函数、表达式组成,之间由换行符或分号隔开,并位于大刮号内。常见的action包括:变量或数组赋值、输出命令、内置函数、控制流语句。
BEGIN { action }、pattern { action }、END { action }都是可选项目。
awk 工作流
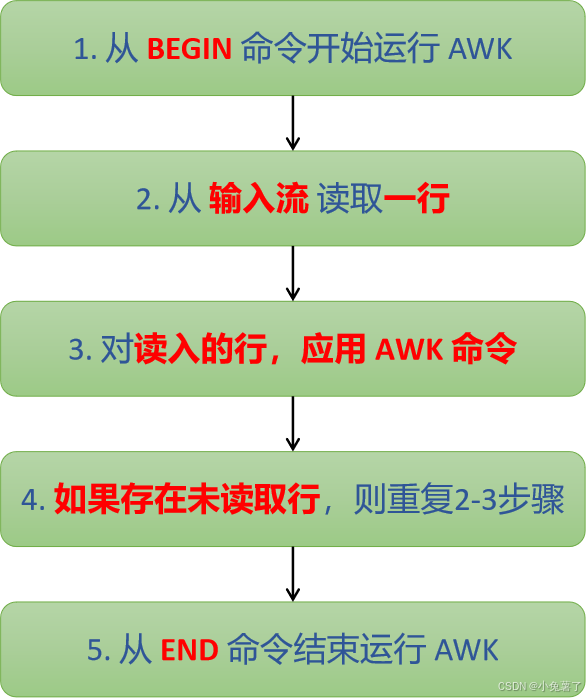
-
第一步: 执行
BEGIN { commands }语句块中的语句。在awk从输入输出流中读取行之前执行,通常在BEGIN语句块中执行如变量初始化,打印输出表头等操作。
-
第二步:**从文件或标准输入中读取一行,然后执行
pattern { commands }语句块。**它逐行读取数据,从第一行到最后一行重复这个过程,直到读取完所有行。pattern语句块中的通用命令是最重要的部分,它也是可选的。如果没有提供pattern语句块,则默认执行{ print },即打印每一个读取到的行。
{}类似一个循环体,会对文件中的每一行进行迭代,通常将变量初始化语句放在BEGIN语句块中,将打印结果等语句放在END语句块中。 -
第三步:当读至输入流末尾时,执行
END { command }语句块。在awk从输入流中读取完所有的行之后执行,比如打印所有行的分析结果,它也是一个可选语句块。
awk 示例
示例文件
[root@server ~ 16:42:06]# cat << 'EOF' > employee.txt
1) 张三 技术部 23
2) 李四 人力部 22
3) 王五 行政部 23
4) 赵六 技术部 24
5) 朱七 客服部 23
EOF
示例1: 打印雇员信息。
[root@server ~ 16:43:25]# awk '{ print }' employee.txt
1) 张三 技术部 23
2) 李四 人力部 22
3) 王五 行政部 23
4) 赵六 技术部 24
5) 朱七 客服部 23
示例2: 通过读取awk脚本,打印雇员信息。
[root@server ~ 16:43:57]# vim commands.awk
[root@server ~ 16:44:33]# cat commands.awk
{print}
[root@server ~ 16:44:37]# awk -f commands.awk employee.txt
1) 张三 技术部 23
2) 李四 人力部 22
3) 王五 行政部 23
4) 赵六 技术部 24
5) 朱七 客服部 23
示例3: 输出特定隔行。
[root@server ~ 16:44:49]# awk '/张三/ {print}' employee.txt
1) 张三 技术部 23
# 等同于
[root@server ~ 16:45:45]# awk '/张三/' employee.txt
1) 张三 技术部 23
$0,代表整行记录。
示例4: 统计满足特定条件的记录数。
AWK 中的所有变量都不需要初始化,并且会自动初始化为
0。
[root@server ~ 16:48:42]# awk '
/术/ { count=count+1 }
END { print "Count="count }' employee.txt
运行以上代码,输出结果如下:
Count=2
示例5: 输出总长度大于 10 的行。
AWK 提供了一个内建的函数 **length(arg)∗∗用于返回字符串‘arg)** 用于返回字符串 `arg)∗∗用于返回字符串‘arg` 的总长度。
如果要获取某行的总长度,可以使用下面的语法:
length($0)。同样的,如果要获取某列/字段的总长度,可以使用语法:
length($n)。如果要判断某行的字符是否大于/小于/等于 N ,可以使用下面的语法:
length($0) > N。
[root@server ~ 16:48:50]# awk 'length($0)>10 { print $0 }' employee.txt
因为所有的行的总长度都大于 18,因此输出结果如下:
1) 张三 技术部 23
2) 李四 人力部 22
3) 王五 行政部 23
4) 赵六 技术部 24
5) 朱七 客服部 23
awk 综合示例
雇员信息表如下:
[root@server ~ 16:49:55]# cat employee.txt
1) 张三 技术部 23
2) 李四 人力部 22
3) 王五 行政部 23
4) 赵六 技术部 24
5) 朱七 客服部 23
示例文件结构:
- 每个雇员独占一行
- 每个雇员都包括以下字段:序号,名字,部门,年龄
- 每一行的多个字段之间使用空白作为分隔符,空白分隔符一般是空格 ( ) 或者制表符
\t
问题
我们想要获得以下输入结果
序号 姓名 部门 年龄
-------------------
1) 张三 技术部 23
2) 李四 人力部 22
3) 王五 行政部 23
4) 赵六 技术部 24
5) 朱七 客服部 23
-------------------
分析
从上面的结果中可以看出,整个输出结果分为三大部分
-
表头
序号 姓名 部门 年龄 ------------------- -
数据
每个雇员一样,且有着以下的结构
1) 张三 技术部 23 2) 李四 人力部 22 3) 王五 行政部 23 4) 赵六 技术部 24 5) 朱七 客服部 23 -
表尾
-------------------
根据我们刚刚学到的知识,AWK 程序结构分为三大部分,BEGIN 和 END 只会执行一次,看起来刚好可以用来输出表头,而 AWK 主体代码,是针对每一行执行的,因此,刚好可以用来输出数据。
解答
表头
为了输入表头,我们可以使用下面的 Shell 语句
[root@server ~ 16:49:55]# awk '
BEGIN { printf "序号\t名字\t部门\t年龄\n-------------------\n" }'
因为表头部分不需要处理输入文件,也不需要处理输入文件中的每一行,所以 AWK 主体代码都是可以忽略的,甚至包括输入文件都是可以忽略的。
运行以上代码,输出结果如下:
序号 名字 部门 年龄
-------------------
数据
对比想要的结果和输入的文件,可以看出输出结果并并没有对每一行做特殊处理,直接显示就好
因此,只需要在 BEGIN 块后面直接添加 { print } ,添加完代码如下:
[root@server ~ 16:49:55]# cat employee.txt | awk '
BEGIN { printf "序号\t名字\t部门\t年龄\n-------------------\n" }
{ print }
END {printf "-------------------\n"}'
运行以上代码,输出结果如下:
序号 名字 部门 年龄
-------------------
1) 张三 技术部 23
2) 李四 人力部 22
3) 王五 行政部 23
4) 赵六 技术部 24
5) 朱七 客服部 23
-------------------
如果把 命令写入到脚本文件中,也可以这样执行:
[root@server ~ 16:49:55]# vim commands.awk
BEGIN { printf "序号\t名字\t部门\t年龄\n-------------------\n" }
{ print }
END {printf "-------------------\n"}
[root@server ~ 16:49:55]# awk -f commands.awk employee.txt
表尾
最后,从想要的结果中可以看出,整个结果最后还有一行虚线,这个,我们可以通过 END 语句来实现。
END 语句和 BEGIN 语句类似,我们就直接给结果了。
[root@server ~ 16:49:55]# cat employee.txt | awk '
BEGIN { printf "序号\t名字\t部门\t年龄\n-------------------\n" }
{ print }
END { printf "-------------------\n" }'
运行以上代码,输出结果如下:
序号 名字 部门 年龄
-------------------
1) 张三 技术部 23
2) 李四 人力部 22
3) 王五 行政部 23
4) 赵六 技术部 24
5) 朱七 客服部 23
-------------------
如果把 命令写入到脚本文件中,也可以这样执行:
[root@server ~ 16:49:55]# vim commands.awk
BEGIN { printf "序号\t名字\t部门\t年龄\n-------------------\n" }
{ print }
END { printf "-------------------\n" }
[root@server ~ 16:49:55]# awk -f commands.awk employee.txt
awk 命令选项
–help 选项
用于输出 awk 命令的帮助信息。
[laoma@shell ~]$ awk --help
Usage: awk [POSIX or GNU style options] -f progfile [--] file ...
Usage: awk [POSIX or GNU style options] [--] 'program' file ...
POSIX options: GNU long options: (standard)
-f progfile --file=progfile
-F fs --field-separator=fs
-v var=val --assign=var=val
Short options: GNU long options: (extensions)
-b --characters-as-bytes
-c --traditional
-C --copyright
-d[file] --dump-variables[=file]
-D[file] --debug[=file]
-e 'program-text' --source='program-text'
-E file --exec=file
-g --gen-pot
-h --help
-i includefile --include=includefile
-l library --load=library
-L[fatal|invalid|no-ext] --lint[=fatal|invalid|no-ext]
-M --bignum
-N --use-lc-numeric
-n --non-decimal-data
-o[file] --pretty-print[=file]
-O --optimize
-p[file] --profile[=file]
-P --posix
-r --re-interval
-s --no-optimize
-S --sandbox
-t --lint-old
-V --version
To report bugs, see node `Bugs' in `gawk.info'
which is section `Reporting Problems and Bugs' in the
printed version. This same information may be found at
https://www.gnu.org/software/gawk/manual/html_node/Bugs.html.
PLEASE do NOT try to report bugs by posting in comp.lang.awk,
or by using a web forum such as Stack Overflow.
gawk is a pattern scanning and processing language.
By default it reads standard input and writes standard output.
Examples:
awk '{ sum += $1 }; END { print sum }' file
awk -F: '{ print $1 }' /etc/passwd
-F 选项
**作用:**用于定义awk程序的分隔符。awk程序的分隔符,是用于分割同一行数据的分割符号。默认分隔符是:空格。
语法:-F fs 或者 --field-separator=fs
**示例:**打印用户名和家目录
[root@server ~ 16:52:51]# head -n1 /etc/passwd
root:x:0:0:root:/root:/bin/bash
[root@server ~ 16:52:51]# head -n1 /etc/passwd | awk -F : '{ print $1" "$6 }'
root /root
-v 选项
**作用:**用于预定义一些变量。这些预定义变量会在执行AWK 程序之前就定义好,准确的说,在 BEGIN 语句之前就已经定义。
示例:
-
通过
awk的-v参数,将 Shell 变量VAR的值传递到awk脚本中并使用[root@server ~ 16:54:42]# VAR=10000 [root@server ~ 16:54:42]# echo | awk -v VARIABLE=$VAR '{ print VARIABLE }' 10000 #echo |:通过 echo 输出一个空行,作为 awk 的输入(因为 awk 默认需要读取输入才能执行 {...} 中的逻辑,空行不影响变量输出,仅触发 awk 执行) #$VAR:取 Shell 变量 VAR 的值(即 10000),通过 -v 传递给 awk 的 VARIABLE 变量 -
定义内部变量接收外部变量。
[root@server ~ 16:56:24]# var1="aaa" [root@server ~ 16:56:24]# var2="bbb" [root@server ~ 16:56:24]# echo | awk '{ print v1,v2 }' v1=$var1 v2=$var2 aaa bbb # 输入来自文件时 [root@server ~ 16:56:24]# awk '{ print v1,v2 }' v1=$var1 v2=$var2 /etc/hostname aaa bbb
补充:后面为什么要加上文件?
直接原因:让 awk 有 “触发执行的输入”,避免脚本 “没机会运行”。
- awk 的执行规则(关键!)
awk 的脚本逻辑(比如 {print v1,v2}),默认会 对每一行输入执行一次:
如果不给 awk 传输入(既没文件,也没管道),它会一直等待终端输入(敲回车才执行),非常不实用;
如果给 awk 传文件(比如 /etc/hostname),awk 会自动读取文件的每一行,每读一行就执行一次脚本,执行完后自动退出。
-p 选项
**作用:**用于将当前的 awk 程序代码格式化并且输出到 file 文件中。
格式:--profile[=file] 或者 -p[file]
awk默认导出的 awk 程序代码格式化代码到 awkvars 文件中。
示例:
[root@server ~ 17:03:52]# awk --profile '
BEGIN { printf"---|Header|--\n" }
{ print }
END { printf"---|Footer|---\n" }' employee.txt > /dev/null
运行上面的 awk 程序,awkprof.out 内容如下:
# gawk profile, created Wed Aug 20 11:36:46 2025
# BEGIN block(s)
BEGIN {
printf "---|Header|--\n"
}
# Rule(s)
{
print $0
}
# END block(s)
END {
printf "---|Footer|---\n"
}
awk 内置变量
NR行号
NF 行中列个数
$N 第几个区域,$0整行
FS 域分隔符
示例:
[root@server ~ 15:37:22]# echo 0. : $(top -b -n1 |awk 'NR==1 {print $(NF-2),$(NF-1),$NF}')
0. : 0.99, 0.97, 0.79
[root@server ~ 15:41:20]# echo 1. CPU : $( cat top.out | awk 'NR==3 {print 100-$8}')
1. CPU : 33.3
[root@server ~ 15:43:10]# echo 2. Mem :$( cat top.out |awk 'NR==4 {print $8/$4}')
2. Mem :0.0407917
[root@server ~ 15:43:54]# echo 3.user :$(cat top.out |awk 'NR==1 {print $6 ,$7}')
3.user :2 users,
[root@server ~ 15:44:05]# echo 4. : $(cat top.out |awk 'NR==2 {print $(NF-1) ,$NF }')
4. : 0 zombie
示例:
[root@server ~ 09:16:30]# df -h | grep -e '^/dev' -e Filesystem
Filesystem Size Used Avail Use% Mounted on
/dev/mapper/centos-root 50G 1.6G 49G 4% /
/dev/sda1 1014M 139M 876M 14% /boot
/dev/mapper/centos-home 146G 33M 146G 1% /home
[root@server ~ 10:23:30]# df -h | grep -e '^/dev' -e Filesystem | awk '{print $1"\t" $(NF-1)"\t" $NF}' | sed 's/Mounted/Use/'
Filesystem Use on
/dev/mapper/centos-root 4% /
/dev/sda1 14% /boot
/dev/mapper/centos-home 1% /home
[root@server ~ 10:24:18]# df -h | grep -e '^/dev' -e Filesystem | awk '{print $1"\t" $(NF-1)"\t" $NF}' | sed -e 's/Mounted/Use/' -e 's/on/ Mounted/'
Filesystem Use Mounted
/dev/mapper/centos-root 4% /
/dev/sda1 14% /boot
/dev/mapper/centos-home 1% /home
[root@server ~ 10:25:07]# df -h | grep -e '^/dev' -e Filesystem | awk '{print $1"\t" $(NF-1)"\t" $NF}' | sed -e 's/Mounted/Use/' -e 's/on/Mounted on/'
Filesystem Use Mounted on
/dev/mapper/centos-root 4% /
/dev/sda1 14% /boot
/dev/mapper/centos-home 1% /home
awk 运算符
| 运算符 | 描述 |
|---|---|
| =、+=、-=、*=、/=、%=、^=、**= | **赋值运算符:**直接赋值、加赋值、减赋值、乘赋值、除赋值、求余赋值、求幂赋值 |
| +、-、*、/、%、^、 | **算数运算符:**加、减、乘、除、求余、求幂 |
| ++、– | **自增和自减运算符:**自增1、自减1,作为前缀或后缀 |
| +、- | **一元运算符:**一元加、一元减 |
| <、<=、>、>=、==、!= | **关系运算符:**小于、小于等于、大于、大于等于、等于、不等于 |
| ~、!~ | **正则表达式运算符:**匹配和不匹配 |
| &&、||、! | **逻辑运算符:**逻辑与、逻辑或、逻辑非 |
正则表达式运算符
AWK 支持正则表达式,而且为正则表达式提供了两种匹配方式。
匹配运算符 ~
语法:"string" ~ "patten"
AWK 使用一个 波浪线 ( ~ ) 作为正则表达式匹配运算。
匹配运算符用于在给定的字符串中查找要匹配的字符串,如果找到,则返回 true;否则返回 false。
例如下面的 awk 命令,在每一行中查找字符串 四 ,如果找到则输出当前行。
[root@server ~ 17:03:52]# awk '$0 ~ "四"' employee.txt
运行上面的 awk 命令,输出结果如下
2) 李四 人力部 22
不匹配运算符 !~
语法:"string" !~ "patten"
AWK 使用一个 感叹号 和波浪线 ( ~ ) 作为正则表达式不匹配运算符 ( !~ ) 。
不匹配运算符用于在给定的字符串中查找要匹配的字符串,如果没有找到,则返回 true;否则返回 false。
例如下面的 awk 命令,在每一行中查找字符串 四 ,如果没有发现则输出当前行。
[root@server ~ 17:03:52]# awk '$0 !~ "四"' employee.txt
运行上面的 awk 命令,输出结果如下
1) 张三 技术部 23
3) 王五 行政部 23
4) 赵六 技术部 24
5) 朱七 客服部 23
正则表达式
AWK 早早的就支持正则表达式了。
虽然支持的模式并没有 Perl 或 Python 那么强大,但是,作为行处理器,也足够使用了。
正则表达式最重要的作用,就是可以使用简单的语句完成复杂的任务。
| 字符 | 描述 |
|---|---|
| […] | 匹配 […] 中的任意一个字符 |
| [^…] | 匹配除了 […] 中字符的所有字符 |
| [a-z] | 匹配所有小写字母。 |
| [A-Z] | 匹配所有大写字母。 |
| [0-9] | 匹配所有数字。 |
| . | 匹配除换行符(\n、\r)之外的任何单个字符,相等于 [\^\n\r]。 |
| \ | 将下一个字符标记为或特殊字符、或原义字符、或向后引用、或八进制转义符。例如, ‘n’ 匹配字符 ‘n’。‘\n’ 匹配换行符。序列 ‘\’ 匹配 “”,而 ‘(’ 则匹配 “(”。 |
| | | 指明两项之间的一个选择。要匹配 |,请使用 |。 |
字符集
| 选项 | 描述 |
|---|---|
| [[:digit:]] | 数字: 0 1 2 3 4 5 6 7 8 9 等同于[0-9] |
| [[:xdigit:]] | 十六进制数字: 0 1 2 3 4 5 6 7 8 9 A B C D E F a b c d e f |
| [[:lower:]] | 小写字母:在 C 语言环境和ASCII字符编码中,对应于**[a-z]** |
| [[:upper:]] | 大写字母:在 C 语言环境和ASCII字符编码中,对应于[A-Z] |
| [[:alpha:]] | 字母字符:[[:lower:]和[[:upper:]];在C语言环境和ASCII字符编码中,等同于**[A-Za-z]** |
| [[:alnum:]] | 字母数字字符:[:alpha:]和[:digit:];在C语言环境和ASCII字符编码中,等同于**[0-9A-Za-z]** |
| [[:blank:]]或者[[:space:]] | 空白字符:在 C 语言环境中,它对应于制表符、换行符、垂直制表符、换页符、回车符和空格。 |
| [[:punct:]] | 标点符号:在C语言环境和ASCII字符编码中,它对应于!" # $ % &'()*+,-./:;<=>?@[]^_`{|}~ |
| [[:print:]]或者 [[:graph:]] | 可打印字符: [[:alnum:]]、[[:punct:]]。 |
| [[:cntrl:]] | 控制字符。在 ASCII中, 这些字符对应八进制代码000到037和 177 (DEL)。 |
转义字符
| 字符 | 描述 |
|---|---|
| \cx | 匹配由x指明的控制字符。例如, \cM 匹配一个 Control-M 或回车符。x的值必须为 A-Z 或 a-z 之一。否则,将 c 视为一个原义的 ‘c’ 字符。 |
| \f | 匹配一个换页符。等价于 \x0c 和 \cL。 |
| \n | 匹配一个换行符。等价于 \x0a 和 \cJ。 |
| \r | 匹配一个回车符。等价于 \x0d 和 \cM。 |
| \s | 匹配任何空白字符,包括空格、制表符、换页符等等。等价于 [ \f\n\r\t\v]。注意 Unicode 正则表达式会匹配全角空格符。 |
| \S | 匹配任何非空白字符。等价于 [^ \f\n\r\t\v]。 |
| \w | 匹配字母、数字、下划线。等价于 [A-Za-z0-9_] |
| \W | 匹配任何非单词字符。等价于[^A-Za-z0-9_] |
| \t | 匹配一个制表符。等价于 \x09 和 \cI。 |
| \v | 匹配一个垂直制表符。等价于 \x0b 和 \cK。 |
限定次数
| 字符 | 描述 |
|---|---|
| * | 匹配前面的子表达式零次或多次。例如,zo*能匹配"z"以及"zoo"。 |
| + | 匹配前面的子表达式一次或多次。例如,'zo+'能匹配"zo"以及"zoo"。 |
| ? | 匹配前面的子表达式零次或一次。例如,"do(es)?“可以匹配"do”、“does"中的"does”、“doxy"中的"do”。?等价于{0,1}。 |
| {n} | n是一个非负整数。匹配确定的n次。例如,'o{2}‘不能匹配"Bob"中的’o’,但是能匹配"food"中的两个o。 |
| {n,} | n是一个非负整数。**至少匹配n次。*例如,'o{2,}‘不能匹配"Bob"中的’o’,但能匹配"foooood"中的所有o。'o{1,}‘等价于’o+’。'o{0,}'则等价于’o’。 |
| {,m} | m是一个非负整数。**最多匹配m次。**例如,'o{,2}‘不能匹配"Booob"中的’o’,但能匹配"food"中的所有o。'o{,2}‘等价于’o{0,2}’。 |
| {n,m} | m和n均为非负整数,其中n<=m。**最少匹配n次且最多匹配m次。**例如,"o{1,3}"将匹配"fooooood"中的前三个o。'o{0,1}‘等价于’o?’。请注意在逗号和两个数之间不能有空格。 |
| () | 标记一个子表达式的开始和结束位置。**子表达式可以获取供以后使用。**要匹配这些字符,请使用 ( 和 )。 |
定位符,使您能够匹配行首或行尾,单词内、单词开头或者单词结尾。
| 字符 | 描述 |
|---|---|
| ^ | **匹配行首位置。**例如,^laoma,匹配以laoma开头的行。 |
| $ | **匹配行末位置。**例如,laoma$,匹配以laoma结尾的行。 |
| \b | 匹配一个单词边界,即字与空格间的位置。 |
| \B | 非单词边界匹配。 |
| < | 匹配一个单词左边界。 |
| > | 匹配一个单词右边界。 |
示例:
-
.点号。[root@server ~ 17:09:41]# echo -e "cat\nbat\nfun\nfin\nfan" # 输出结果如下 cat bat fun fin fan [root@server ~ 17:10:08]# echo -e "cat\nbat\nfun\nfin\nfan" | awk '/f.n/' # 输出结果如下 fun fin fan -
^行首和$行位[root@server ~ 17:10:08]# echo -e "cat\nbat\nfun\nfin\nfan" | awk '/^fin/' # 输出结果如下 fin [root@server ~ 17:10:08]# echo -e "cat\nbat\nfun\nfin\nfan" | awk '/fin$/' # 输出结果如下 fin -
[]和[^][root@server ~ 17:10:08]# echo -e "cat\nbat\nfun\nfin\nfan" | awk '/f[ai]n/' # 输出结果如下 fin fan [root@server ~ 17:10:08]# echo -e "cat\nbat\nfun\nfin\nfan" | awk '/f[^ai]n/' # 输出结果如下 fun -
|多选1[root@server ~ 17:10:08]# echo -e "cat\nbat\nfun\nfin\nfan" | awk '/fan|cat/' # 输出结果如下 cat fan -
?0 次或 1 次[root@server ~ 17:10:08]# echo -e "Colour\nColor" | awk '/Colou?r/' # 输出结果如下 Colour Color -
*任意次数[root@server ~ 17:10:08]# echo -e "ca\ncat\ncatt" | awk '/cat*/' # 输出结果如下 ca cat catt -
+1 次以上[root@server ~ 17:10:08]# echo -e "111\n22\n123\n234\n456\n222" | awk '/2+/' # 输出结果如下 22 123 234 222 -
()子串[root@server ~ 17:10:08]# echo -e "Apple Juice\nApple Pie\nApple Tart\nApple Cake" | awk '/Apple (Juice|Cake)/' # 输出结果如下 Apple Juice Apple Cake
逻辑运算符
逻辑运算符包括 逻辑与( && )、逻辑或( || )、逻辑非 ( ! )
逻辑与( && )
逻辑与运算符使用两个 & 表示。
语法:expr1 && expr2。
逻辑与( && )运算符的计算结果遵循以下规则:
- 如果 expr1 和 expr2 的计算结果都为 true,则结果为 true; 否则返回 false。
- 当且仅当 expr1 的计算结果为 true 时,才会计算 expr2。
[root@server ~ 17:10:08]# awk '
BEGIN {
num=5
if (num>=0 && num<=7)
{ print "0<="num"<=7" }
}'
运行上面的 awk 命令,输出结果为
0<=5<=7
逻辑或( || )
逻辑或运算符使用 || 表示。
语法:expr1 || expr2。
逻辑或( || )运算符的计算结果遵循以下规则
- 如果 expr1 和 expr2 的计算结果只要有一个为 true,则结果为 true; 否则返回 false
- 当且仅当 expr1 的计算结果为 false 时,才会计算 expr2
[root@server ~ 17:10:08]# awk '
BEGIN {
ch="\n"
if (ch==" " || ch=="\t" || ch=="\n")
{ print "Current character is whitespace." }
}'
运行上面的 awk 命令,输出结果如下:
Current character is whitespace
逻辑非 ( ! )
逻辑非运算符使用 感叹号( !) 表示。
语法:! expr1。
逻辑非运算符返回 expr1 的逻辑补语,也就是说如果 expr1 的计算结果为 true,则返回 0; 否则返回 1。
例如下面的 AWK 命令,因为 name 为空字符串,所以 length(name) 的结果为 0,对 0 执行逻辑非运算,则为 true。
[root@server ~ 17:10:08]# awk '
BEGIN {
site = ""
if (! length(site))
{ print "site is empty string." }
}'
运行上面的 awk 命令,输出结果如下:
site is empty string.
awk 数组
AWK 中的数组,既可以是普通数组,也可以是关联数组。也就是说,数组的索引/下标不必是连续的数字。
AWK 中的数组不用事先声明数组的大小,在运行时动态的增长。
创建和访问数组
AWK 中创建数组的语法很简单,创建数组和给数组添加/修改元素的方式语法一样。
语法:array_name[index] = value
array_name是数组的名字。index是数组的索引。value是分配给index下标/索引的值。
访问数组元素,也是通过下标。
语法:array_name[index]
**示例1:**以水果作为键,以水果颜色作为值。
[root@server ~ 17:10:08]# awk '
BEGIN {
colour["芒果"] = "橘色";
colour["橘子"] = "黄色";
colour["苹果"] = "红色";
print colour["芒果"],colour["橘子"],colour["苹果"]
}'
运行以上 awk 命令,输出结果如下:
橘色 黄色 红色
从上面的代码中可以看出,访问数组的方式也很简单,就是使用 array_name[index]。
打印数组所有元素
**示例1:**使用无序下标循环输出。
[root@server ~ 17:10:08]# awk 'BEGIN {
colour["芒果"] = "橘色"
colour["橘子"] = "黄色"
colour["苹果"] = "红色"
for (i in colour)
{ print i": "colour[i]}
}'
运行以上 awk 命令,输出结果如下:
苹果: 红色
芒果: 橘色
橘子: 黄色
**示例2:**使用有序下标循环输出。
[root@server ~ 17:10:08]# awk 'BEGIN {
colour[0] = "橘色"
colour[1] = "黄色"
colour[2] = "红色"
lens=length(colour)
for (i=0;i<lens;i++)
{ print i": "colour[i]}
}'
说明: 版本够高的awk可以直接使用方法length()得到数组长度。如果传给length的变量是一个字符串,那么length返回的则字符串的长度。
运行以上 awk 命令,输出结果如下:
0: 橘色
1: 黄色
2: 红色
示例3: 统计文件/etc/profile中出现频率最高的10个单词,并显示对应数量。
#方法一
[root@server ~ 17:10:08]# cat commands.awk
{
for (i=1;i<=NF;i++){
count[$i]++
}
}
END {
for (i in count){
print i" "count[i]
}
}
#
[root@server ~ 19:03:15]# for num in 1 2 3 4 5
> do echo $num
> done
1
2
3
4
5
#“提取 /etc/profile 关键词→统计出现次数→按次数降序→过滤纯标点单词→取前 10 条”
[root@server ~ 17:10:08]# cat /etc/profile | awk -f commands.awk | sort -nr -k2 | awk '$1 !~ "^[[:punct:]]+"'| head
then 8
if 8
fi 8
pathmunge 6
in 6
to 5
for 5
else 5
umask 3
export 3
#正则 ^[[:punct:]]+:^ 行首、[[:punct:]] 匹配所有标点、+ 一个或多个;$1 !~ 正则:第 1 列(单词)不匹配 “以标点开头”,才保留该行
分步解释:
cat /etc/profile
- 作用:读取
/etc/profile文件的内容并输出到标准输出(控制台)。/etc/profile是系统级的环境变量配置文件,包含环境变量、别名等系统初始化设置。awk -f commands.awk
- 作用:调用
awk工具,执行commands.awk脚本文件中的处理逻辑。commands.awk是一个自定义的awk脚本(需提前创建),通常功能未知,但通常用于:
- 提取文件中的特定字段(如单词、关键字);
- 统计数据(如出现次数);
- 按格式输出内容(例如
单词 次数的两列格式)。sort -nr -k2
- 作用:对前一步输出的内容进行排序。
- 选项解析:
-n:按数字大小排序(而非字符串字典序);-r:逆序排序(从大到小);-k2:以第 2 列作为排序依据。- 假设
commands.awk输出格式为字段1 数字,这一步会按第 2 列的数字从大到小排序。awk '$1 !~ "^[[:punct:]]+"'
- 作用:过滤掉第一列以标点符号开头的行。
- 正则解析:
$1:表示当前行的第 1 列;!~:表示 “不匹配”;^[[:punct:]]+:匹配 “以一个或多个标点符号开头” 的字符串([:punct:]是正则中表示标点符号的字符类)。- 目的:排除无效数据(如纯符号、以符号开头的干扰项)。
head
- 作用:默认显示前 10 行结果(可通过
-n选项指定行数,如head -n 5显示前 5 行)。
#方法二:
[root@server ~ 13:47:32]# cat /etc/profile |sed -nr 's/[[:punct:]]+/ /gp'| sed -nr 's/\s+/\n/gp' | sed '/^$/d' |sort -n |uniq -c |sort -nr|head
12 usr
8 then
8 if
7 bin
6 pathmunge
6 in
6 id
5 to
5 PATH
5 i
length 函数
作用: 用于返回一个字符串的总字节数。。
语法: length(str)
语法说明: str,要统计的字符串。
示例1: 英文字符串
[root@server ~ 15:51:27]# awk 'BEGIN {
str="Hello, World !"
print "\""str"\"", "的长度为:", length(str)
}'
运行以上 awk 命令,输出结果如下:
"Hello, World !" 的长度为: 14
示例2: 中文字符串
[root@server ~ 18:59:41]# awk 'BEGIN {
str="你好!"
print "\""str"\"", "的长度为:", length(str)
}'
运行以上 awk 命令,输出结果如下:
"你好!" 的长度为: 3

















 779
779

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









