






目录
思路2: 在加载(建表)json文件的时候, 直接解析json字符串. 简单说: 存储时, 直接解.
一、高阶函数--列转行
列转行需要用到 explode()函数, 爆炸函数, 它属于UDTF(表生成函数), 即: 一进多出. 只能处理 数组或者字典.
select `array`(11, 22, 33);
select explode(array(11, 22, 33)); -- 一进多出, 列转行
select explode(map(11, 22, 33)); -- 报错, map是键值对类型, 元素个数必须成对出现.
炸裂后的数据, 无法直接和原表查询, 因为对应的关联信息不精准(炸裂后的每一行, 具体对应的是炸裂前的哪一行数据, 对不上)
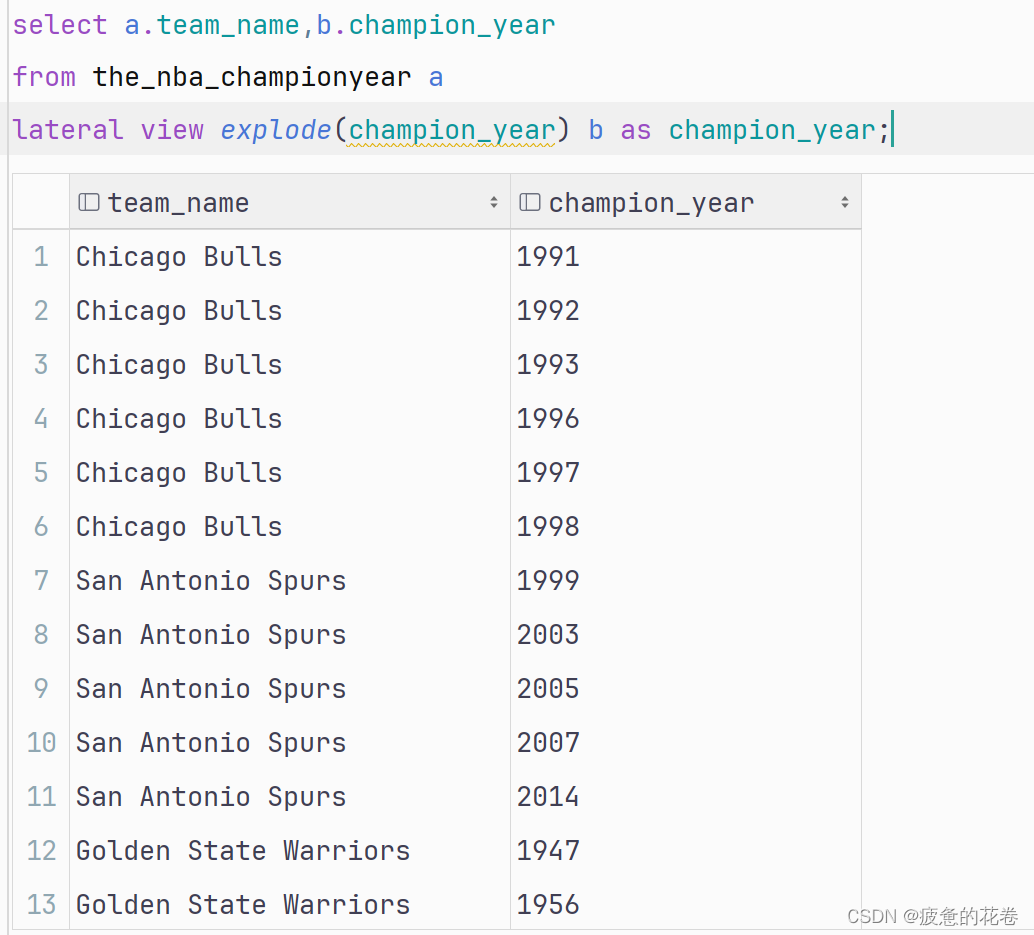
-- 解决方案: 通过侧视图(lateral view)实现, 它是Hive提供的一种专门用来记录 炸裂前后, 数据对应关系的函数.
-- 侧视图格式: lateral view 炸裂函数 侧视图的名字 as 炸裂后数据的列名
1.建表
create table the_nba_championyear(
team_name string comment '队名',
champion_year array<string> comment '夺冠年份'
)
row format delimited fields terminated by ','
collection items terminated by '|';
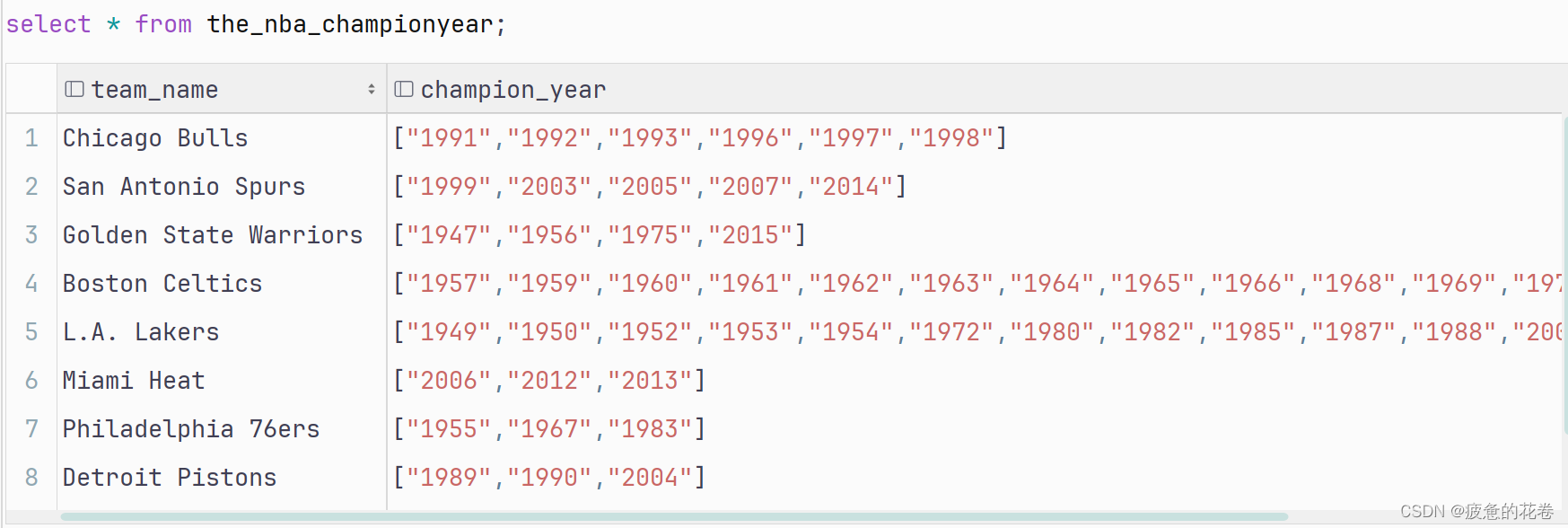
第一次切割后, 数据为: "Chicago Bulls", "1991|1992|1993|1996|1997|1998"
第二次切割后, 数据为: "Chicago Bulls", ["1991", "1992", "1993", "1996", "1997", "1998"]上传数据

查看数据信息
列转行查询数据
将查询到的数据转换为新表

二、高阶函数--行转列
采集函数:
collect_list() 采集, 不去重, 有序(不是排序, 而是元素的存取顺序).
collect_set() 采集, 去重, 无序.
拼接函数:
concat() 默认拼接符 ''
concat_ws() 可以指定拼接符.
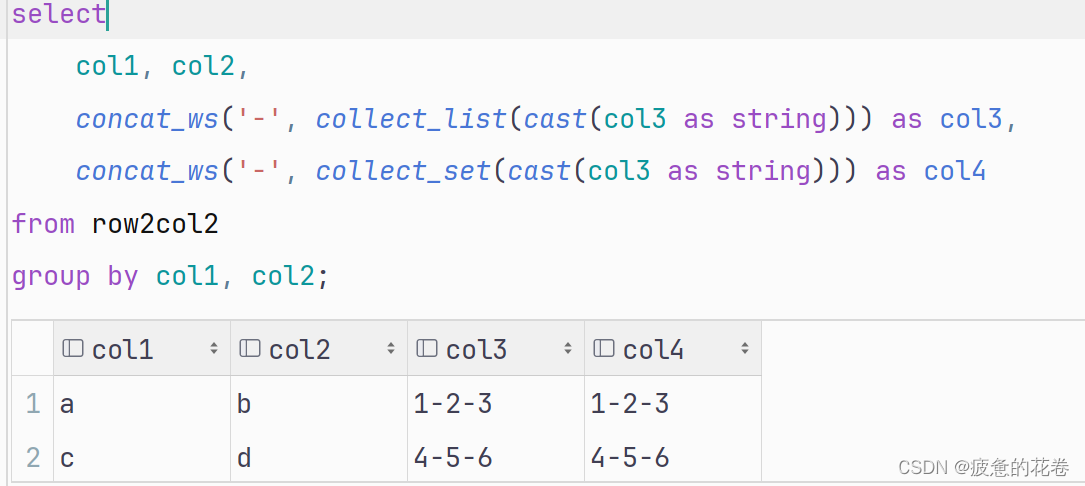
1.建表
create table row2col2(
col1 string,
col2 string,
col3 int
)row format delimited fields terminated by '\t';初步演示collect函数
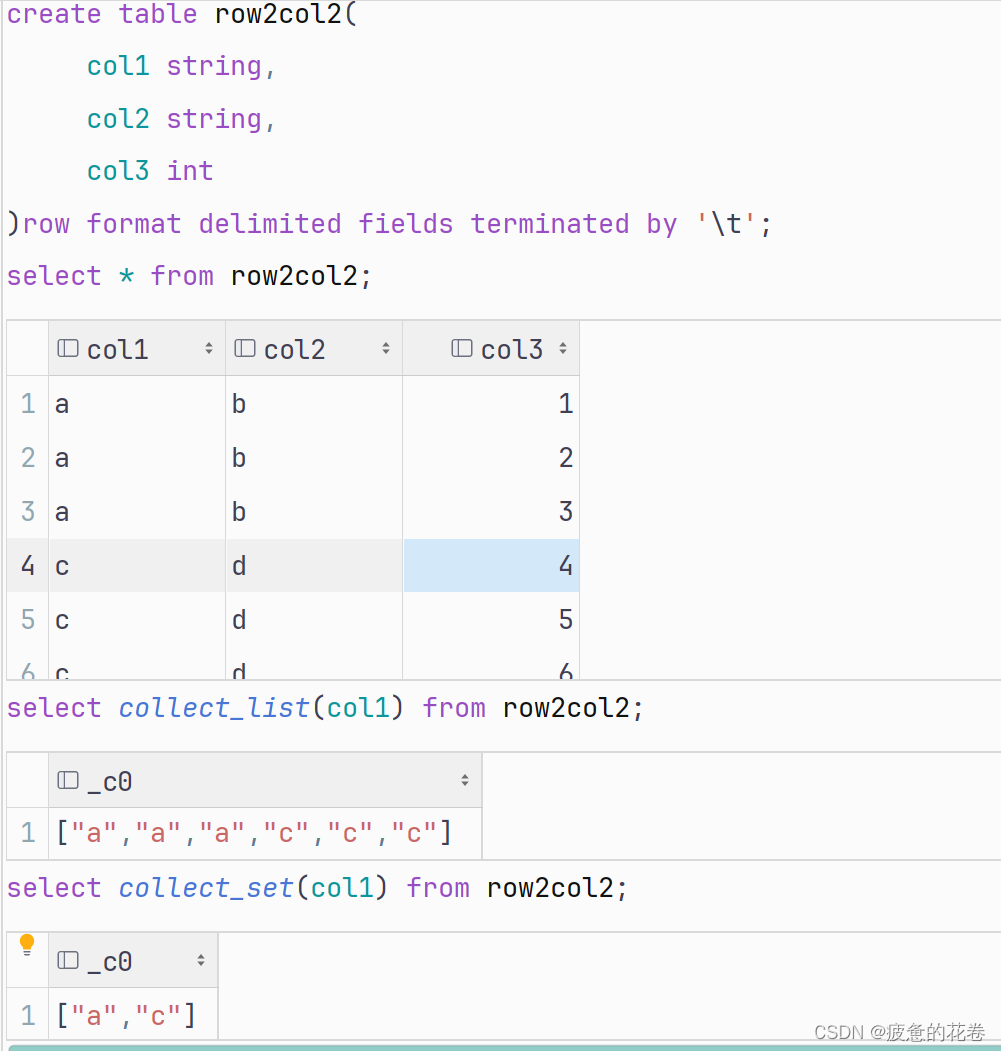
查询行转列数据
三、高阶函数--处理json字符串
特殊规则的字符串, 由键值对组成. 需要用双引号包裹.格式: {"键":"值", "键":"值"}
json字符串也有数组形式: [{"键":"值", "键":"值"}, {"键":"值", "键":"值"}...]
Hive中处理Json字符串主要有两种思路
思路1: 以普通字符串的形式存储json字符串, 然后解析. 简单说: 先存储, 再解析.
方式1: get_json_object() 逐个解析.
方式2: json_tuple() 批量解析.思路2: 在加载(建表)json文件的时候, 直接解析json字符串. 简单说: 存储时, 直接解.
思路1.以普通字符串的形式存储json字符串, 然后解析. 简单说: 先存储, 再解析.
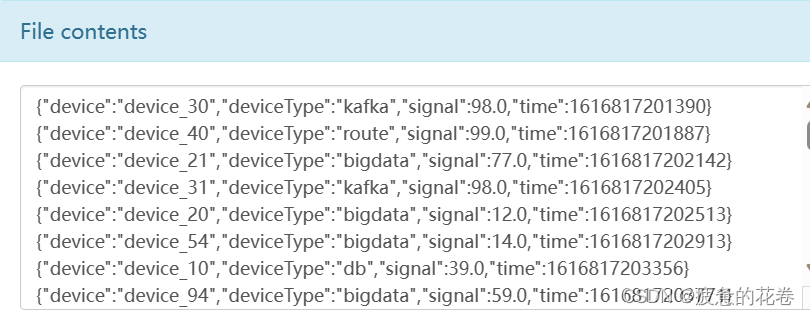
1.建表
create table t_json1(json string);json文件内容
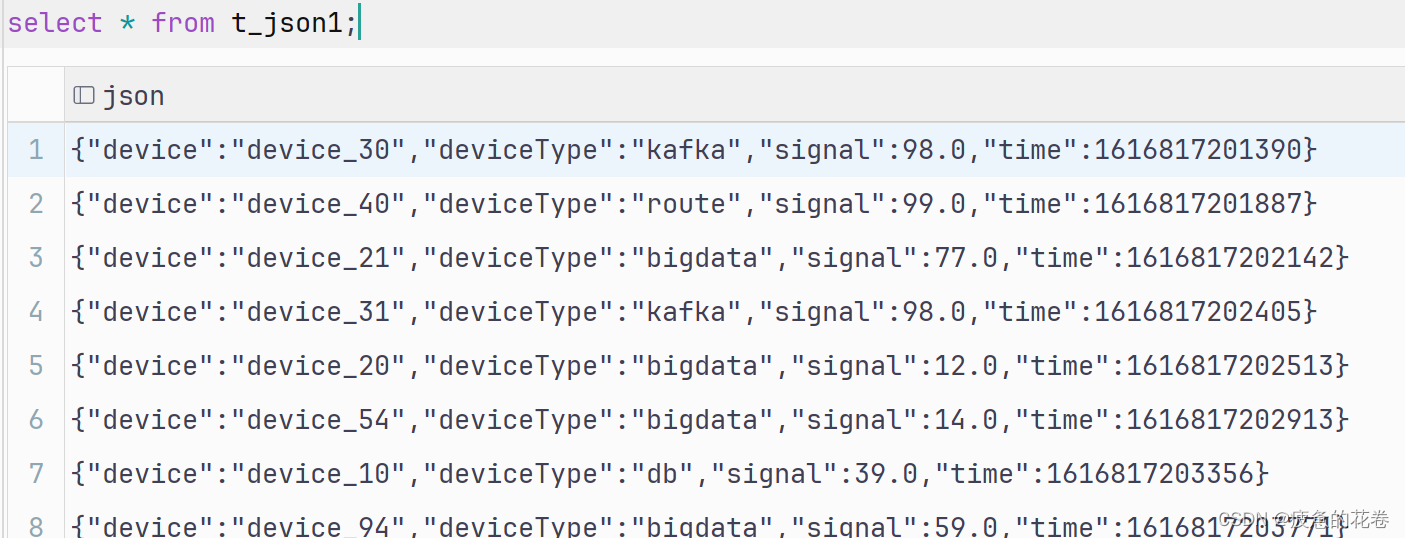
2.解析json字符串:
1.逐个解析
select
get_json_object(字段名,'$.键名1') as 字段别名1,
get_json_object(字段名,'$.键名2') as 字段别名2,
…………
from 表名;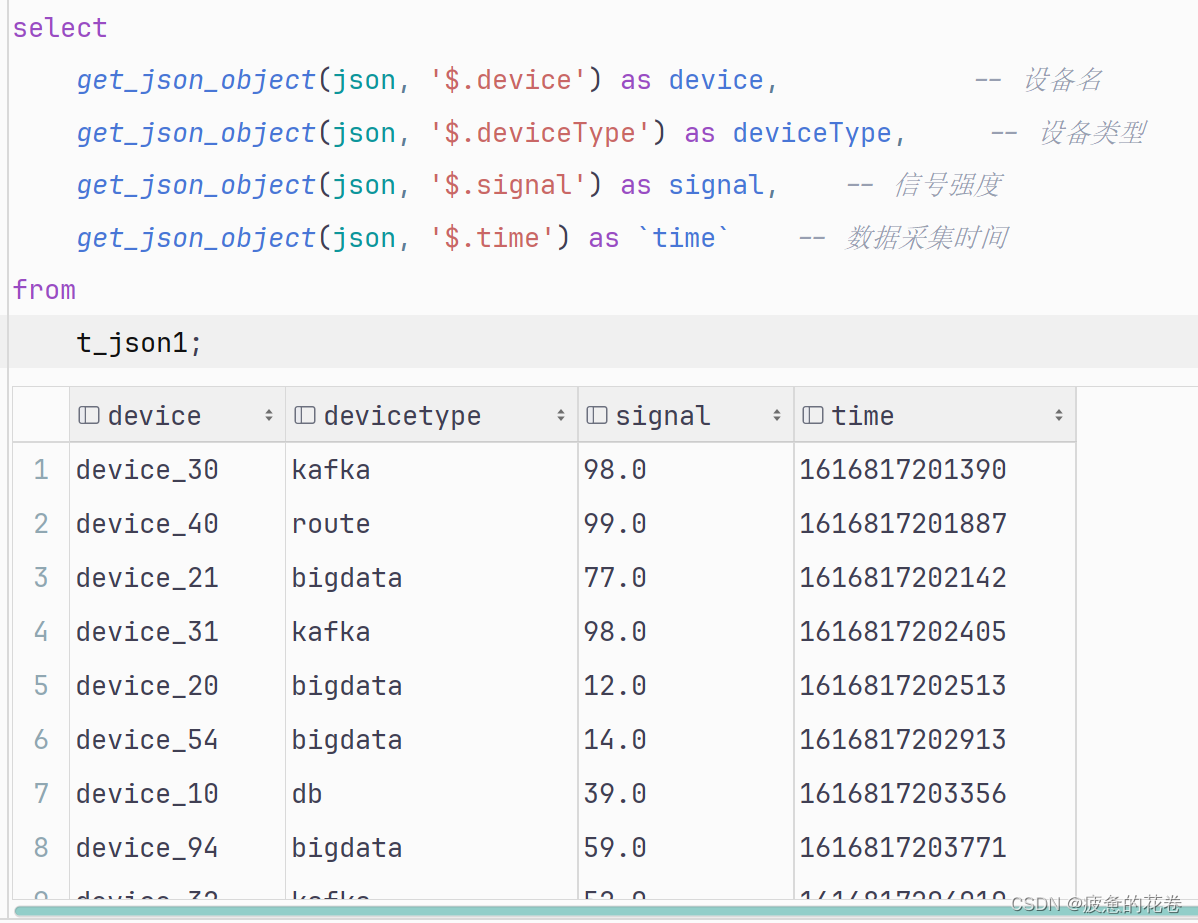
2.批量解析
select json_tuple(列名,'键名1','键名2',……) as (别名1,别名2,……) from 表名;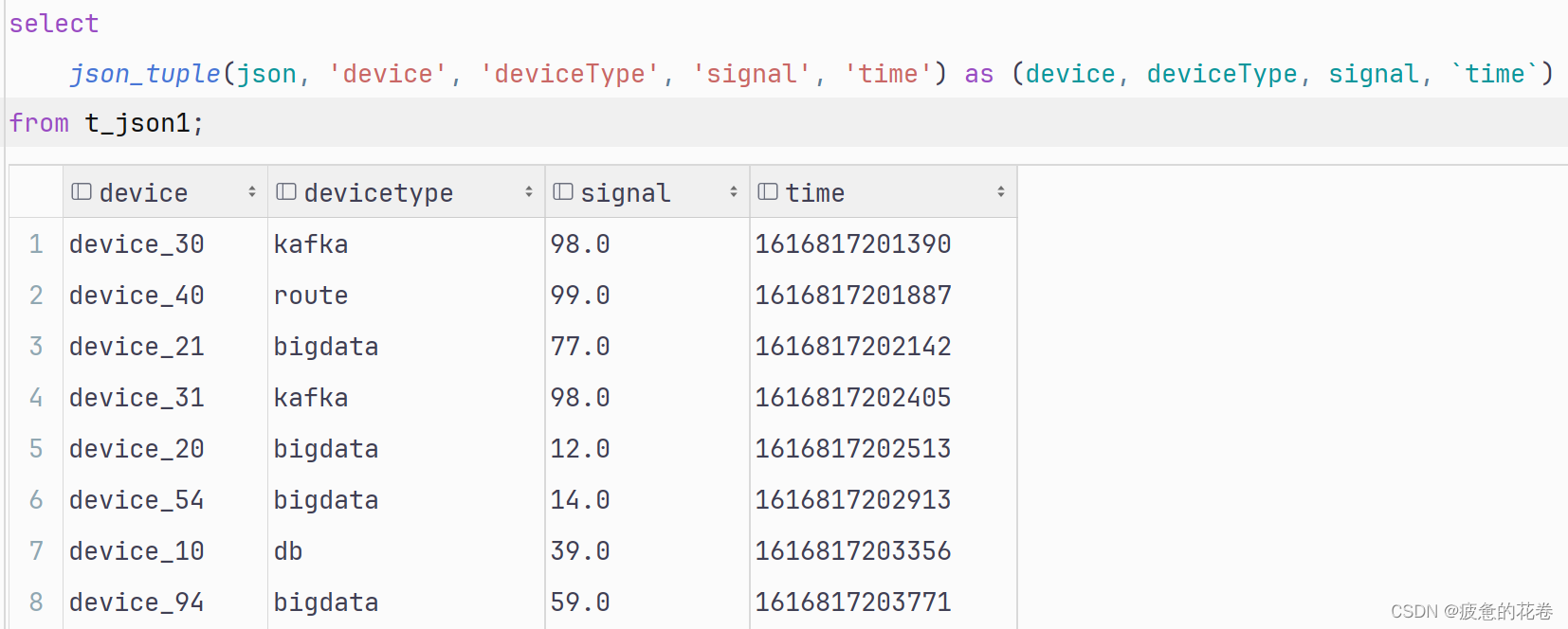
思路2: 在加载(建表)json文件的时候, 直接解析json字符串. 简单说: 存储时, 直接解.
create table t_json2(
device string,
deviceType string,
signal string,
`time` string
)
row format SerDe 'org.apache.hive.hcatalog.data.JsonSerDe';
delimited方式默认用的是LazySimpleSerDe类, 实现不了我们的需求,
所以我们用Hive专门处理Json字符串SerDe类, 即: JsonSerDe类四、高阶函数--窗口函数--结合聚合函数
窗口函数指的是 over()函数, 它可以限定操作数据的范围, 进行局部 或者 全局计算等...
可以结合窗口函数一起用的函数 over(partition by 分组字段 order by 排序字段 asc | desc rows between 起始行 and 结束行)
可以结合窗口函数一起用的函数 over(partition by 分组字段 order by 排序字段 asc | desc rows between 起始行 and 结束行)
可以结合窗口函数一起用的函数 分为3类:
1. 聚合函数.
count(), sum(), max(), min(), avg()
2. 排序函数.
row_number(), rank(), dense_rank(), ntile(n)
3. 其它函数.
lag(), lead(), first_value(), last_value()
细节:
1. 窗口函数相当于给表新增一列, 至于新增的内容是什么, 取决于窗口函数结合什么函数一起使用.
2. 如果不写partition by, 默认是全局统计, 如果写了, 则只统计组内的数据(局部统计).
3. 如果不写order by, 默认是统计组内所有数据, 如果写了, 则统计组内第一行至当前行的数据.
4. 通过rows between可以限定操作数据的范围, 常用关键字如下:
unbounded preceding 起始行(第一行)
n preceding 向上n行
current row 当前行
n following 向下n行
unbounded following 结束行(最后1行)
5. ntile(n)是几分之几的意思, 表示把数据分成几份, 优先参考最小分区.
例如: 7条数据, 分成3份, 则是: 1,1,1 2,2 3,3
6. 常用的 可以结合窗口函数一起用的函数 主要有: count(), sum(), row_number(), rank(), lag()
1.建表
样例
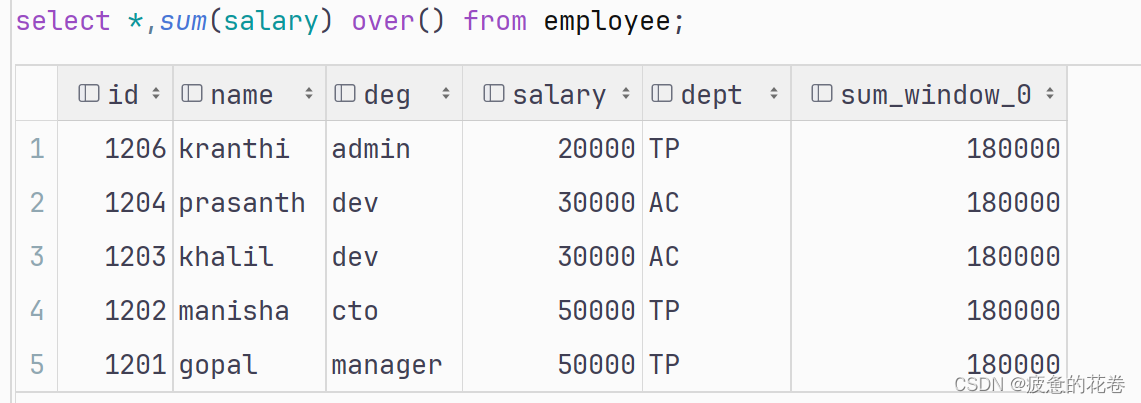
需求: 求出每个用户总pv数
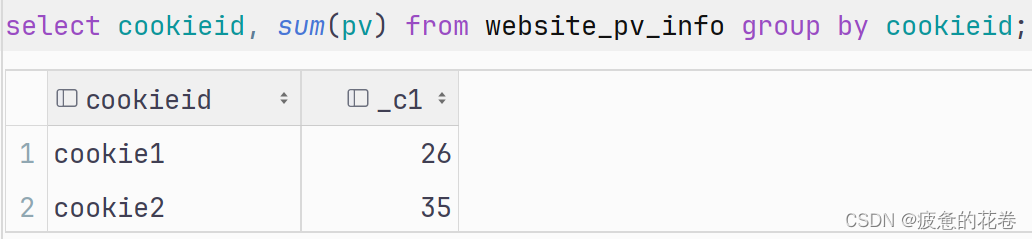
方式1: sum() + group by 一起使用.
select cookieid, sum(pv) as total_pv from website_pv_info group by cookieid;方式2: 聚合函数 + 窗口函数一起使用.
细节: 如果写了partition by(表示分组): 则默认操作 组内所有的数据.
select *, sum(pv) over(partition by cookieid) as total_pv from website_pv_info;细节: 如果写了order by(表示排序): 则默认操作 组内第一行 至 当前行的数据.
select *, sum(pv) over(partition by cookieid order by createtime) as total_pv from website_pv_info;上述的代码, 等价于如下的内容:
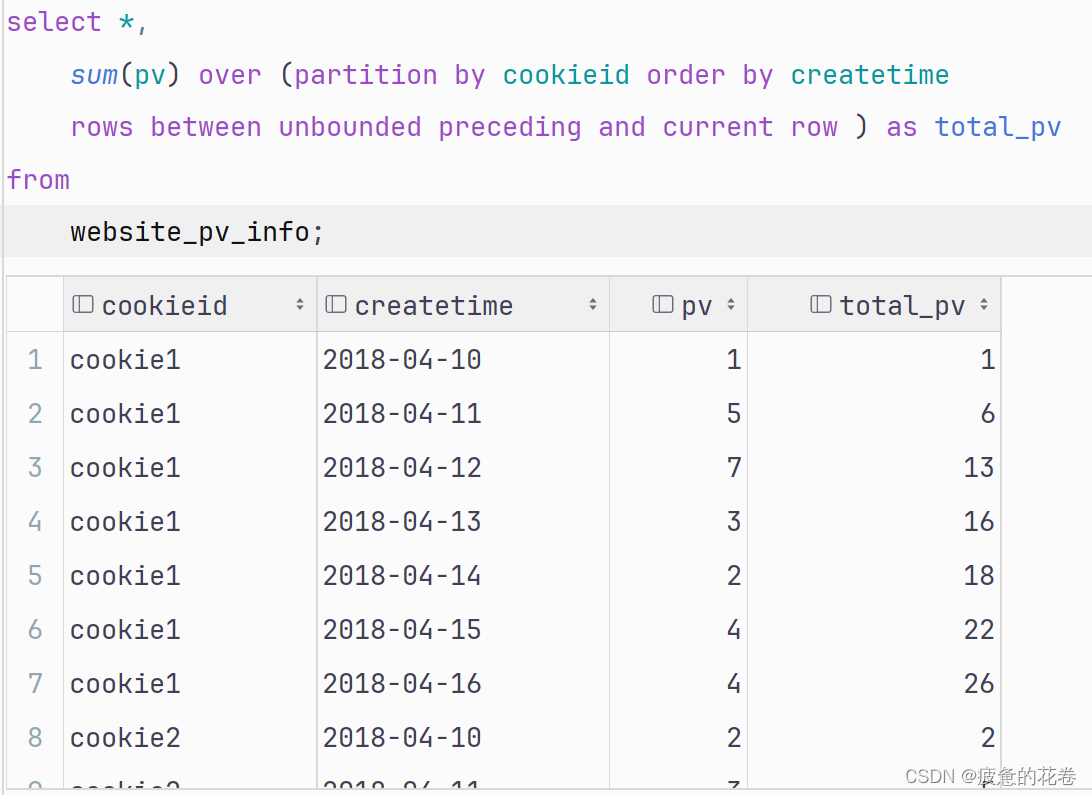
select *, -- 第1行 至 当前行
sum(pv) over (partition by cookieid order by createtime rows between unbounded preceding and current row ) as total_pv
from
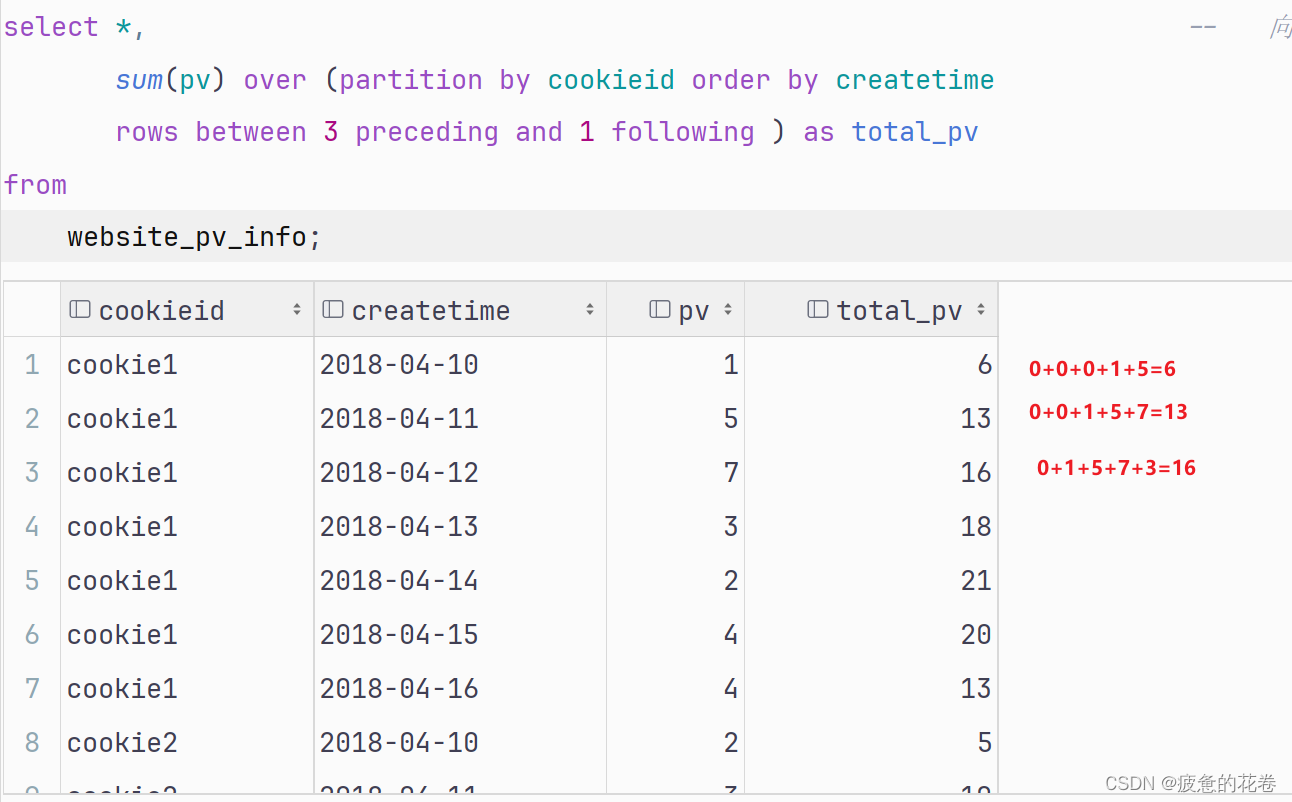
website_pv_info;需求: 统计每个cookieID的pv(访问量), 只统计: 当前行及 向前3行 向后1行
select *, -- 向前3行 至 向后1行
sum(pv) over (partition by cookieid order by createtime rows between 3 preceding and 1 following ) as total_pv
from
website_pv_info;五、高阶函数--窗口函数
窗口函数相当于给表新增一列, 至于新增的内容是什么, 取决于窗口函数结合什么函数一起使用.
窗口函数指的是 over()函数, 它可以限定操作数据的范围, 进行局部 或者 全局计算等...
格式:
可以结合窗口函数一起用的函数 over(partition by 分组字段 order by 排序字段 asc | desc rows between 起始行 and 结束行)
可以结合窗口函数一起用的函数 分为3类:
1. 聚合函数.
count(), sum(), max(), min(), avg()
2. 排序函数.
row_number(), rank(), dense_rank(), ntile(n)
3. 其它函数.
lag(), lead(), first_value(), last_value()
细节:
1. 窗口函数相当于给表新增一列, 至于新增的内容是什么, 取决于窗口函数结合什么函数一起使用.
2. 如果不写partition by, 默认是全局统计, 如果写了, 则只统计组内的数据(局部统计).
3. 如果不写order by, 默认是统计组内所有数据, 如果写了, 则统计组内第一行至当前行的数据.
4. 通过rows between可以限定操作数据的范围, 常用关键字如下:
unbounded preceding 起始行(第一行)
n preceding 向上n行
current row 当前行
n following 向下n行
unbounded following 结束行(最后1行)
5. ntile(n)是几分之几的意思, 表示把数据分成几份, 优先参考最小分区.
例如: 7条数据, 分成3份, 则是: 1,1,1 2,2 3,3
6. 常用的 可以结合窗口函数一起用的函数 主要有: count(), sum(), row_number(), rank(), lag()
1.窗口函数体验准备
建表
员工表
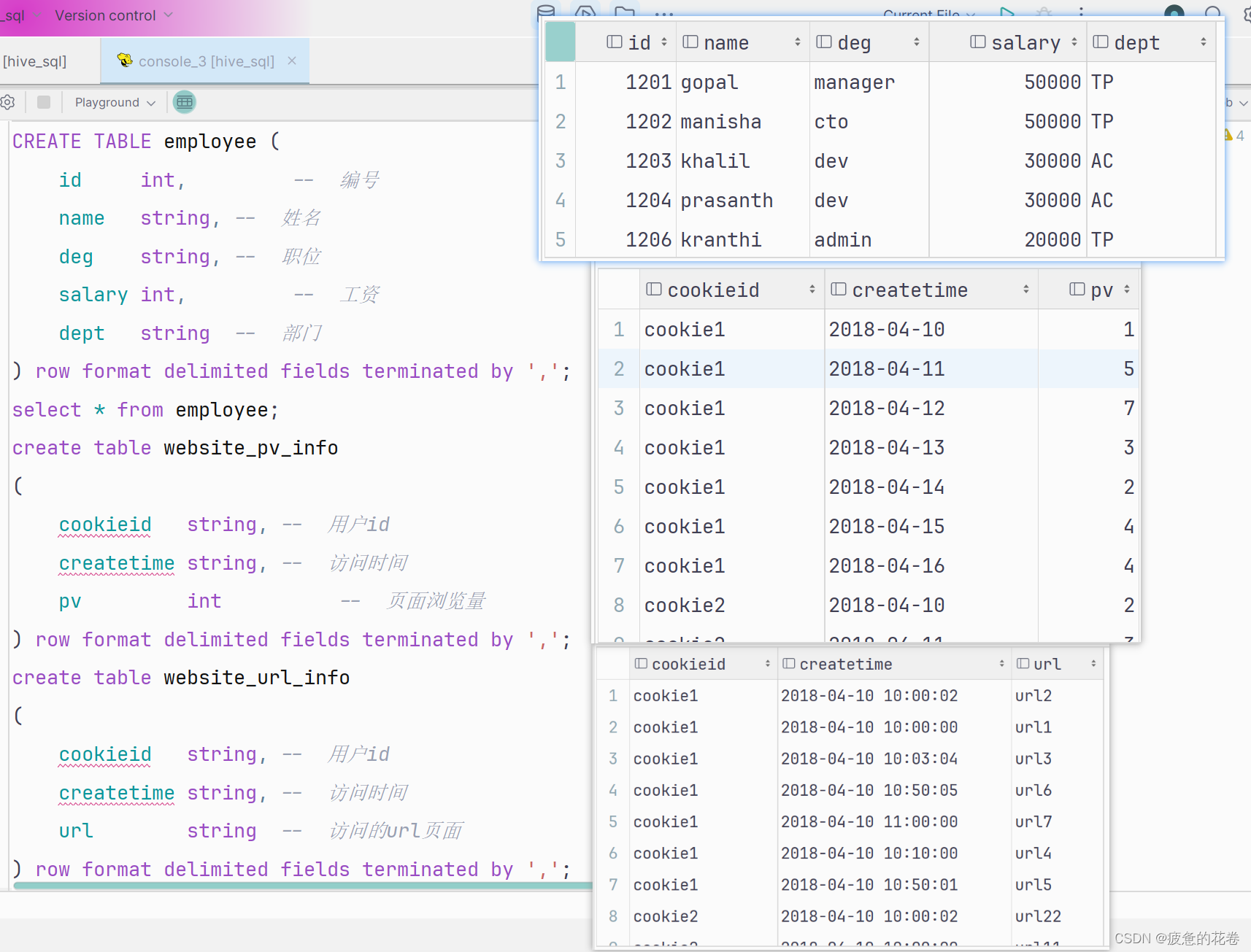
CREATE TABLE employee (
id int, 编号
name string, 姓名
deg string, 职位
salary int, 工资
dept string -- 部门
) row format delimited fields terminated by ',';
网站点击量表
create table website_pv_info
(
cookieid string, 用户id
createtime string, 访问时间
pv int 页面浏览量
) row format delimited fields terminated by ',';
网站访问记录表
create table website_url_info
(
cookieid string, 用户id
createtime string, 访问时间
url string 访问的url页面
) row format delimited fields terminated by ',';表数据
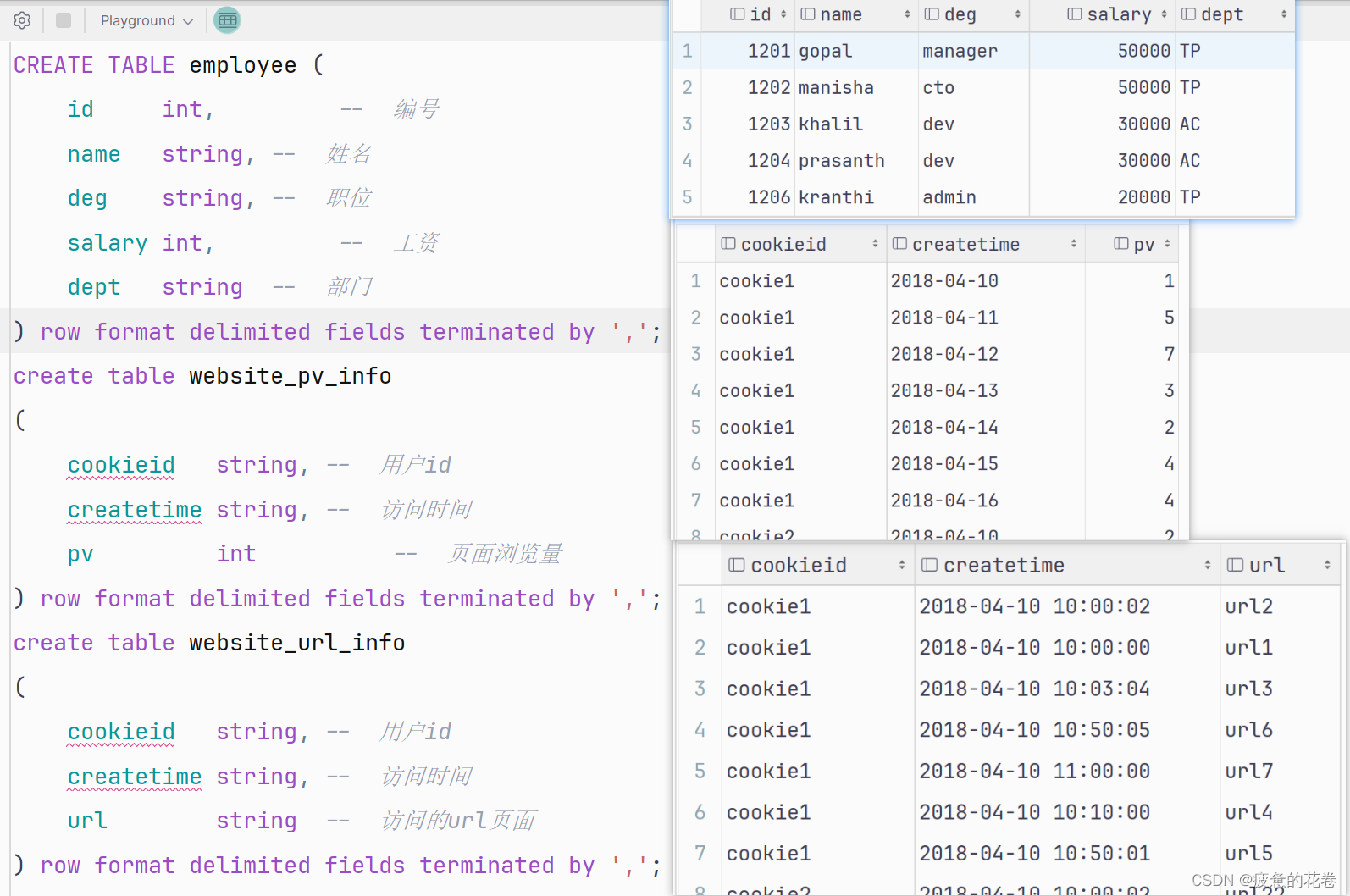
初体验

六、高阶函数--窗口函数--结合聚合函数
需求: 求出每个用户总pv数
方式1:sum() + group by 用户
方式2:聚合函数 + 窗口函数(partition by 用户)

如果写了order by(表示排序): 则默认操作 组内第一行 至 当前行的数据然后再排序。
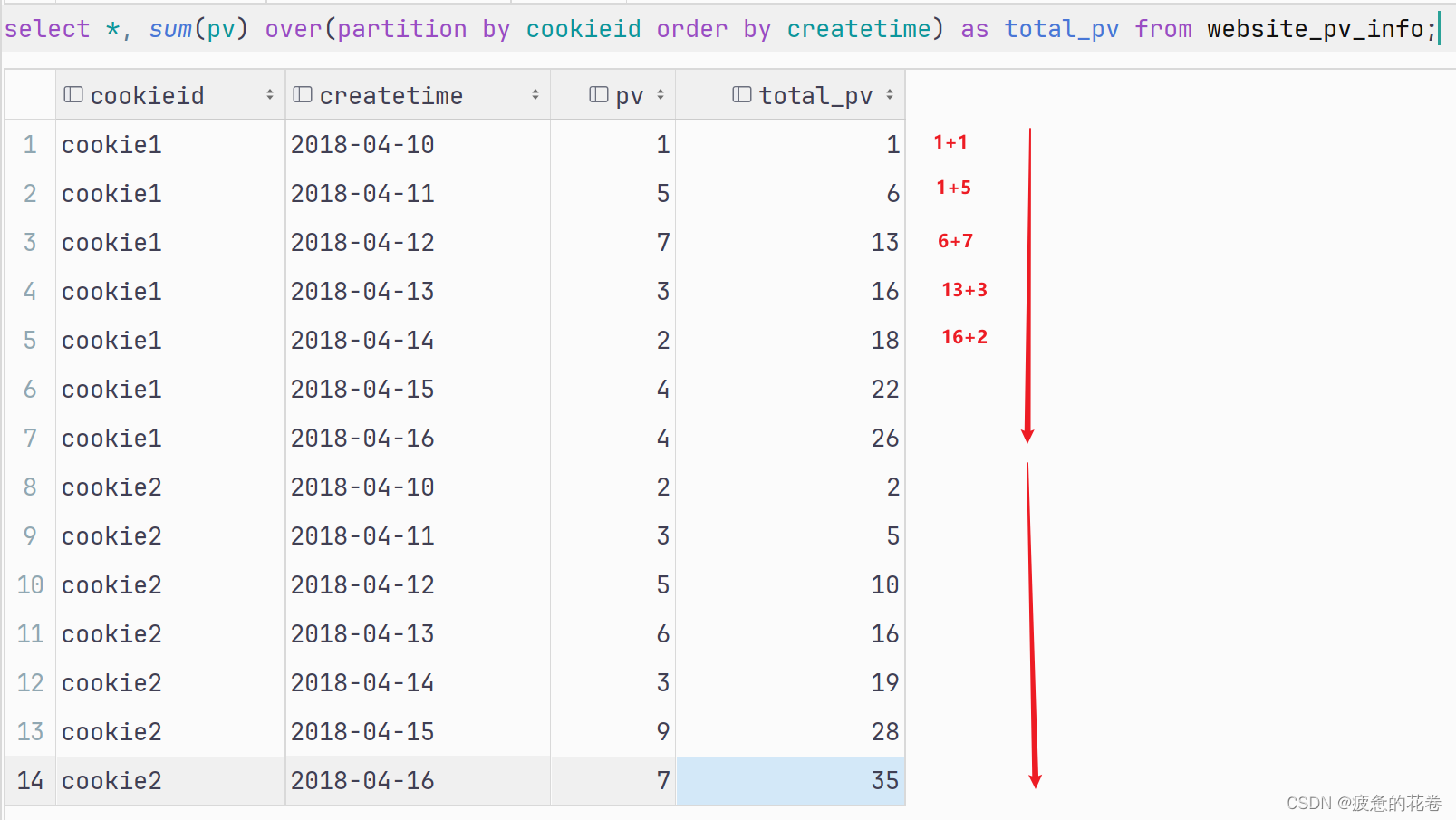
上述的代码, 等价于如下的内容:
-- 第1行 至 当前行
统计每个cookieID的pv(访问量), 只统计: 当前行及 向前3行 向后1行
数字(3,1)可以更改
七、高阶函数--窗口函数--结合排序函数
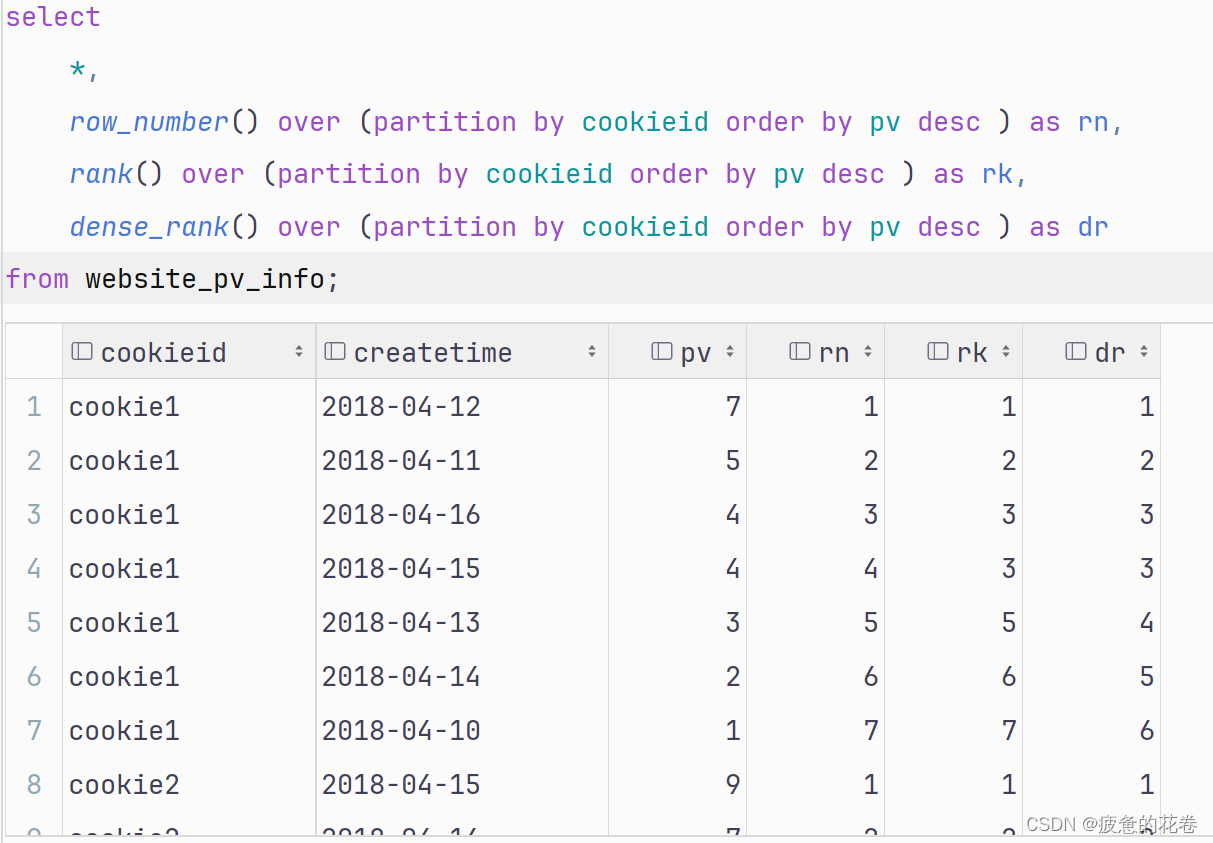
这里的排序函数指的是: row_number(), rank(), dense_rank(), 它们都可以做排名, 不同的是, 对相同值的处理结果.
-- 例如: 数据是100, 90, 90, 60, 则:row_number是: 1, 2, 3, 4
rank: 1, 2, 2, 4
dense_rank: 1, 2, 2, 3
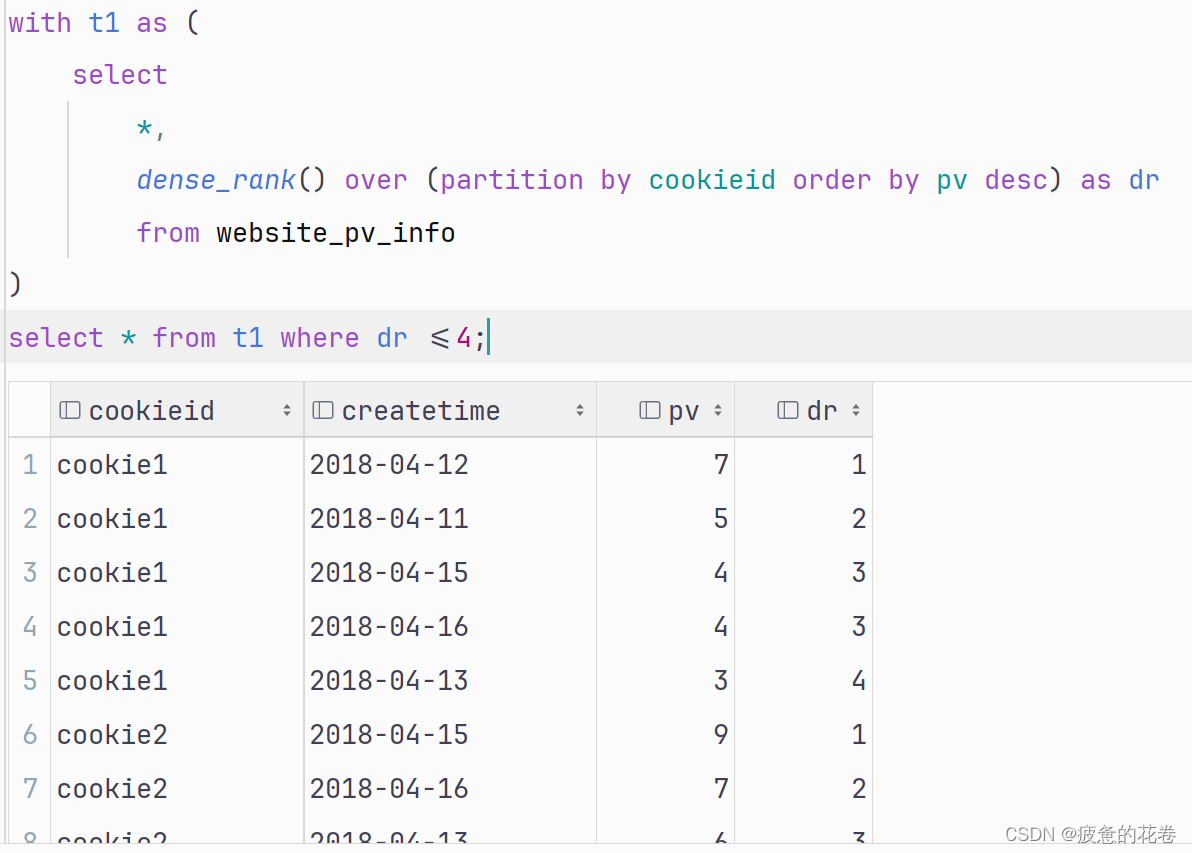
需求: 根据cookieID进行分组, 获取每组点击量最高的前4名数据, 这个就是经典的案例: 分组求TopN
Step1: 根据cookieID进行分组, 根据点击量进行排名.
select *,dense_rank() over (partition by cookieid order by pv desc ) as dr
from website_pv_info
where dr<=4;
-- 报错, 思路没有问题, 但是: where只能筛选表中已经有的列(数据)
-- 细节: where只能筛选表中已经有的列(数据)Step2: 把上述的查询结果当做一张表, 然后从中获取我们要的数据即可.
ntile(数字,表示分成几份) 采用均分策略, 每份之间的差值不超过1, 优先参考最小的那个部分, 即: 7分成3份, 则是: 3, 2, 2

需求: 按照cookieid分组, 按照点击量降序排列, 只要每组前三分之一的数据.
















 1171
1171











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









