









一.安装Linux环境
1.下载VMware虚拟机
下载地址:https://www.vmware.com/products/workstation-pro/workstation-pro-evaluation.html
网盘:https://pan.baidu.com/s/17K8u16SeRQBWhWJMiJjUow
提取码:8888
系统版本:CentOS7
下载地址:官网:https://www.centos.org/download/

基本上就是下一步下一步这种简单的默认安装就好了。在安装界面直接使用光盘映像文件安装

装好后,修改内存,因为不需要图形界面,所以只给个512M内存也没问题。并可以自定义更改网络适配器为VMnet8(NAT)或者和主机共享网络。、
(CentOS和Windows这两台机子通过虚拟网关互联,虚拟网关由VMware workstation生成,在Windows上会生成一个虚拟网卡VMnet8,这个网卡地址和本机的物理网卡没有关系)
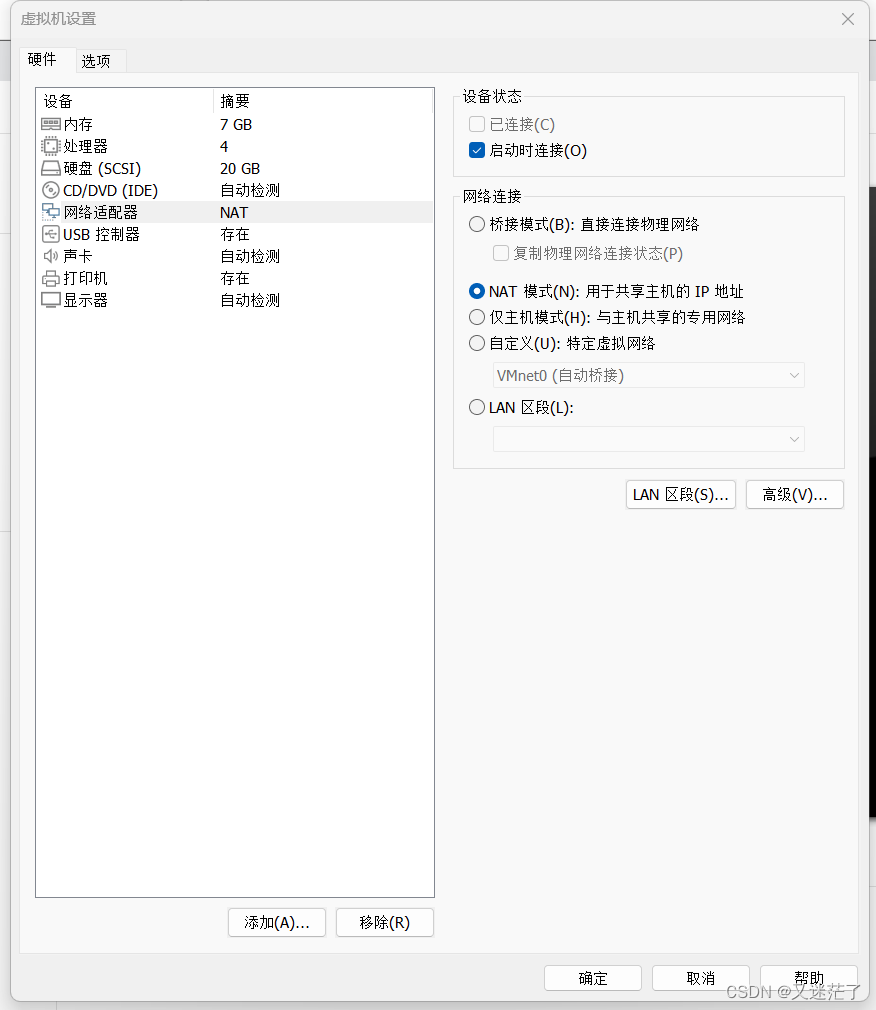
2.网络配置
在VMware workstation的菜单 编辑 -> 虚拟网络编辑器 可以查看和修改虚拟网关地址
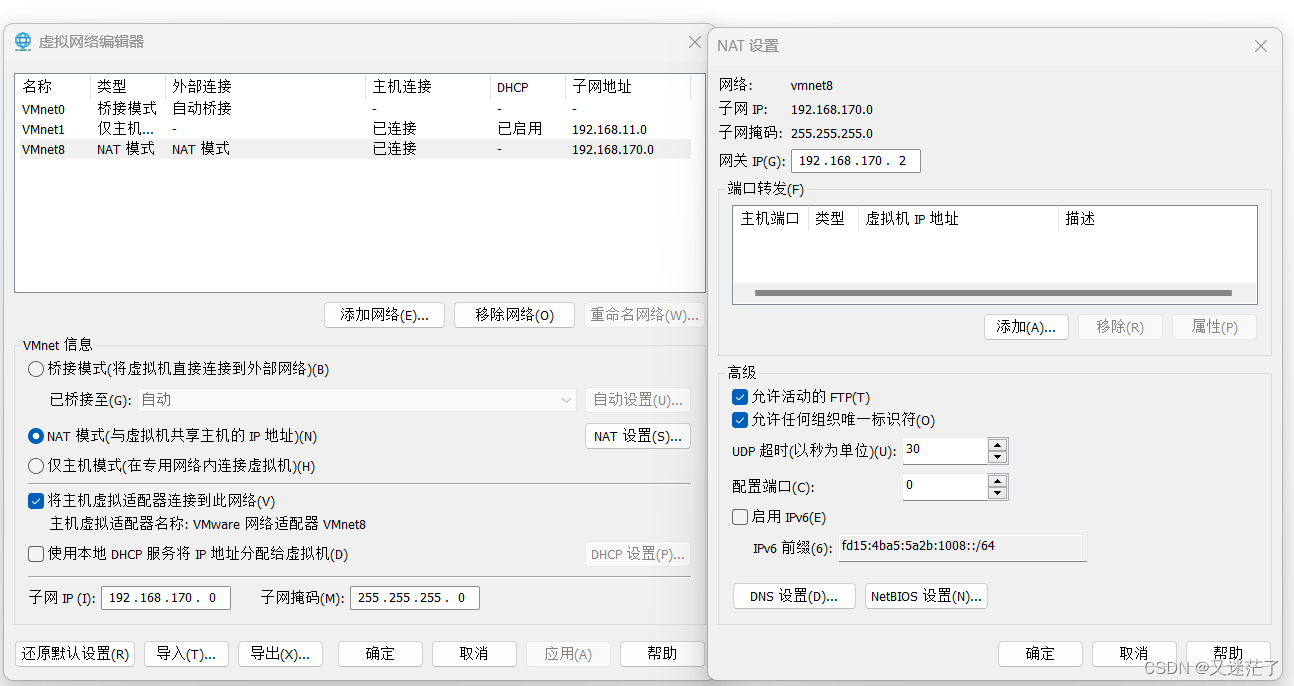
然后打开控制面板的网络连接查看VMnet8的IP地址

运行虚拟机,进行网络配置:
1.输入
ip addr看到我的网卡叫做ens33
2.输入
ls /etc/sysconfig/network-scripts/看到网卡ip信息的配置文件名叫做ifcfg-ens333.输入
vi /etc/sysconfig/network-scripts/ifcfg-ens33,用#将BOOTPROTO=dhcp注释,并输入以下参数,把ip地址固定写为和你电脑网络同一个频段的网络,我的是192.168.170.80
将下面的代码加进去文件后面
IPADDR=192.168.170.80
GATEWAY=192.168.170.2
NETWORK=255.255.255.0
DNS=8.8.8.8
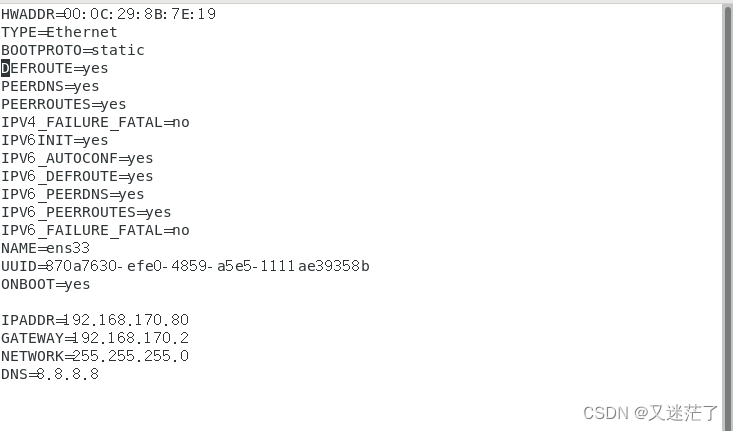
BOOTPROTO=dhcp改为BOOTPROTO=static,以及多配置一行NETMASK=255.255.255.0
4.输入
service network restart重启网络服务
5.输入ip addr确认配置成功

6.PING 连接网络试看看。
ping www.baidu.com
7.现在用windows主机ping一下刚配置好的虚拟机地址,试试看能否ping通,行的话这步就已经完成了

3.修改主机名
(1)在终端上输入:sudo vi /etc/sysconfig/network
名称修改为自己需要的名称,例如:node1,node2
修改完,重启一下。

(2)修改域名解析映射文件使得后续可以直接通过主机名访问,
sudo vi /etc/hosts,添加一行IP地址 主机名

(3) PING一波试试是否已生效
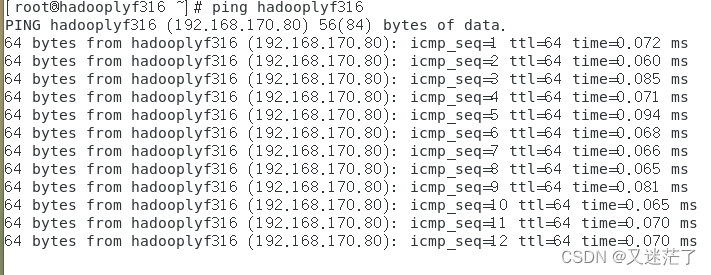
4.共享文件
在window页面新建一个文件夹来作为共享文件
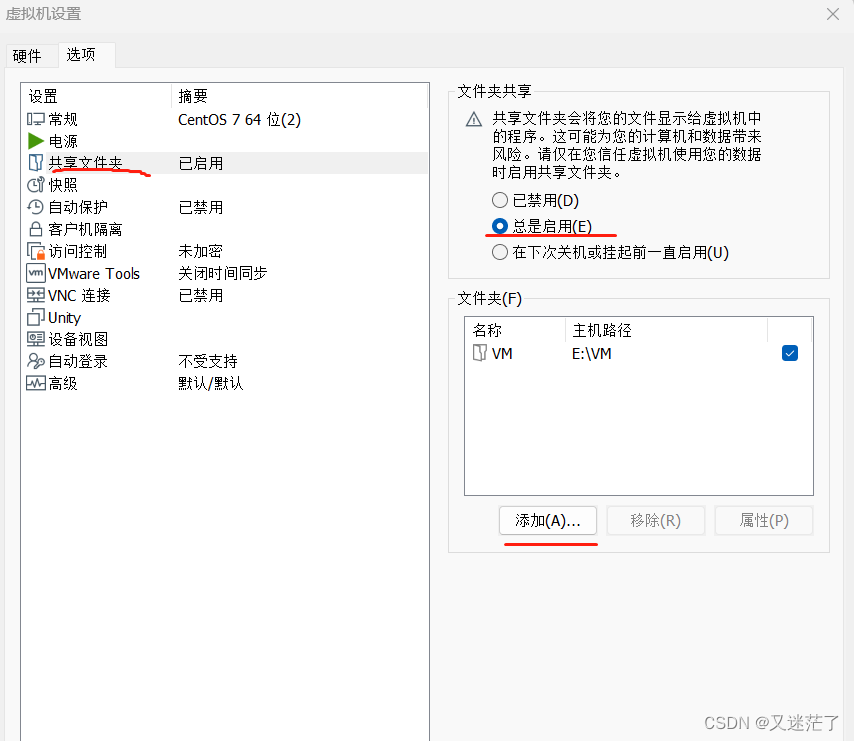
接着打开虚拟机设置-->选项-->共享文件夹
添加文件,选择你新建的文件夹

共享文件我的是在/mnt目录下面
(如果找不到共享文件,可以试看看下面的操作
在源目录路径下面输入:
sudo vmhgfs-fuse .host:/ /mnt -o nonempty -o allow_other)
然后,再次打开就可以看见了

二.安装jdk
1.下载jdk
(1)下载地址:Software Download | Oracle
网盘下载:https://pan.baidu.com/s/1bJeAmg5vnd5OQBbyIFqQ2w
提取码:8888
(2)往下拉,看到Developer Downloads ,点击 java

(3)点击 Java (JDK) for Developers
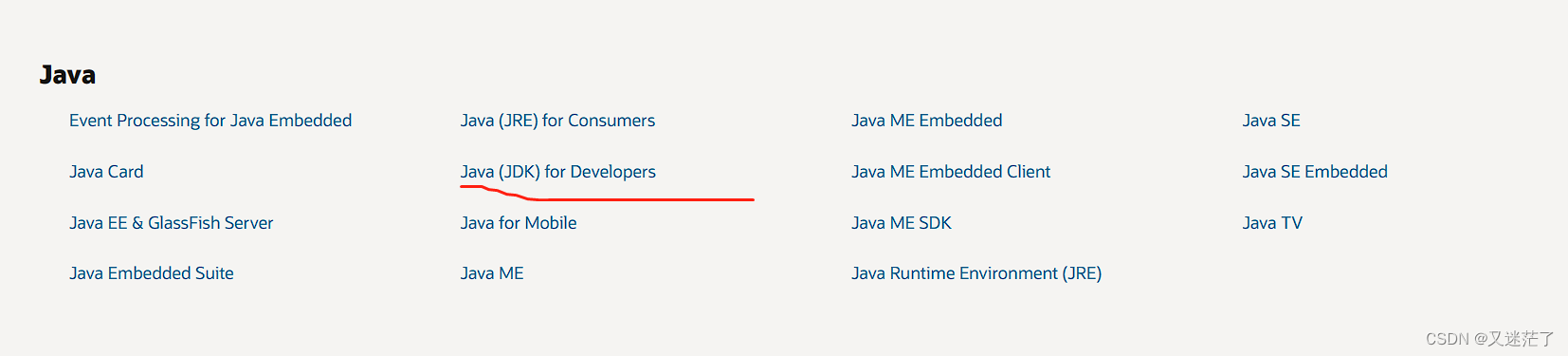
(4)选择你想要下载的jdk版本,我下载的是jdk17,推荐下载jdk8(是Linux版本)

(5)下载在共享文件里面
然后前往虚拟机共享文件里面查看有没有压缩包


2.解压
接着在共享文件目录下面,打开终端(jdk版本自己修改)
输入:tar -zxvf jdk-17.0.8.tar.gz -C/opt
(后面文件位置可以自己选择)

可以在jdk文件内的bin目录下检验是否成功

3.环境配置
1.打开终端输入:
sudo vi /etc/profile
![]()
2.添加配置
在文件最后后面加上这两个语句
export JAVA_HOME=/opt/jdk17.0.8
(具体下载路径根据自己修改)
export PATH=$PATH:$JAVA_HOME/bin
我这里是和Hadoop环境一起配置了,两个都一样
按esc保存,按shift加冒号,之后输入!wq,保存退出

3.检验
输入source /etc/profile使文件修改生效
source /etc/profile
然后,我们查看环境变量是否配置成功,输入:
java -version
和下面截图相同,就是配置成功了

三.安装Hadoop
从hadoop官网下载速度太慢了,下面我们采用清华源下载,或者百度网盘下载。
1.下载地址:
Index of /apache/hadoop/common/hadoop-3.3.1 (tsinghua.edu.cn)

网盘下载:https://pan.baidu.com/s/1O3A26WvT2l3CfTp9XbgxBg
提取码:8888
2.解压
(1)先cd 到压缩包所在的目录下面,将hadoop安装包解压到/usr/local目录下,输入入:
tar -zxvf hadoop-3.1.3.tar.gz -C/usr/local
(2)等待解压好后,切换到/usr/local目录下,查看情况

(3)可以看到已经装好了,重命名一下,方便等一下配置环境,输入:
mv Hadoop-3.1.3/ hadoop

这样就修改好了
3.配置环境变量
(1)输入:
sudo vi /etc/profile
(2)在/etc/profile的文件最后面加上这两行(可以和Java环境一起配置)
export JAVA_HOME=/opt/jdk-17.0.8
export HADOOP_HOME=/usr/local/hadoop
export PATH=.:$HADOOP_HOME/bin:$JAVA_HOME/bin:$PATH

(3)刷新文件
source /etc/profile
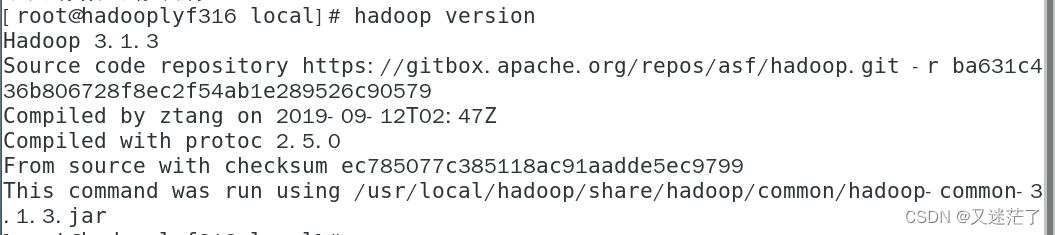
(4)检验变量
输入:hadoop version
4.修改配置文件
1. 修改 hadoop-env.sh
首先,输入:
cd /user/local/hadoop/etc/hadoop
vi hadoop-env.sh
打开文件主要修改java_home的路径
大概在文件的25行 将export JAVA_HOME=${JAVA_HOME}修改成你具体的路径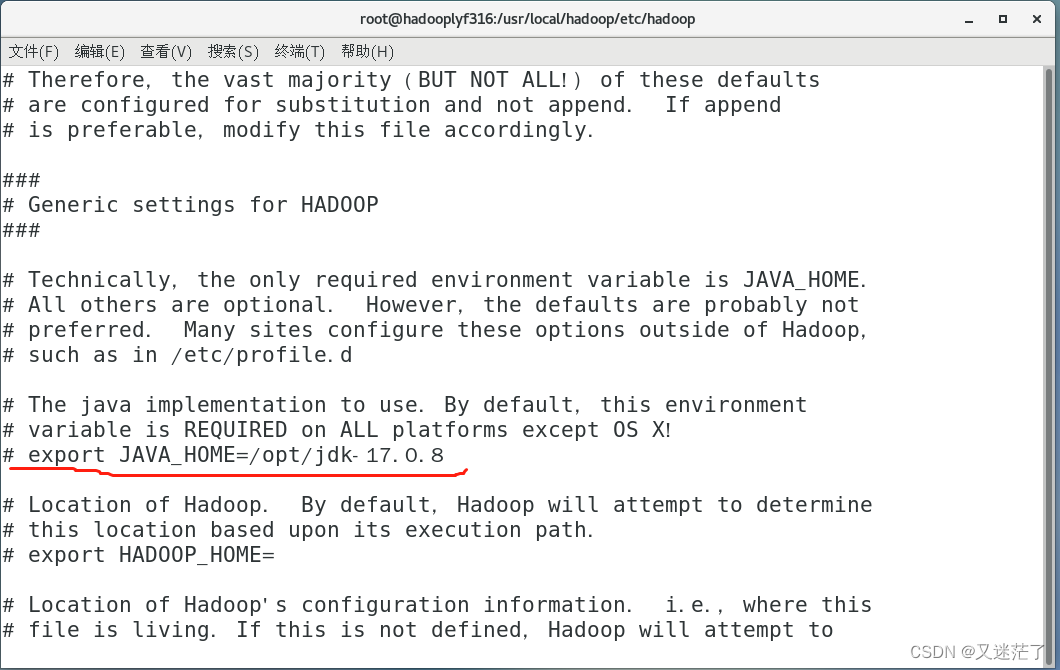
2.修改core-site.xml
在同一个目录下 /user/local/hadoop/etc/hadoop
vim core-site.xml 打开文件
在configuration标签下添加如下配置:
(<value> </value>)标签内填上自己的安装路径,和修改主机名称,
我的主机名是hadooplyf316
你们根据自己的名字进行修改
<configuration>
<property>
<name>hadoop.tmp.dir</name>
<value>file:/usr/local/hadoop/tmp</value>
<description>Abase for other temporary directories.</description>
</property>
<property>
<name>fs.defaultFS</name>
<value>hdfs://hadooplyf316:9000</value>
</property>
</configuration>
然后在/user/local/hadoop/目录下,新建一个文件夹名字叫tmp

3.修改hdfs-site.xml文件
vim hdfs-site.xml 打开配置文件(和上面配置文件方法一样)
图片划红线的要根据自己改
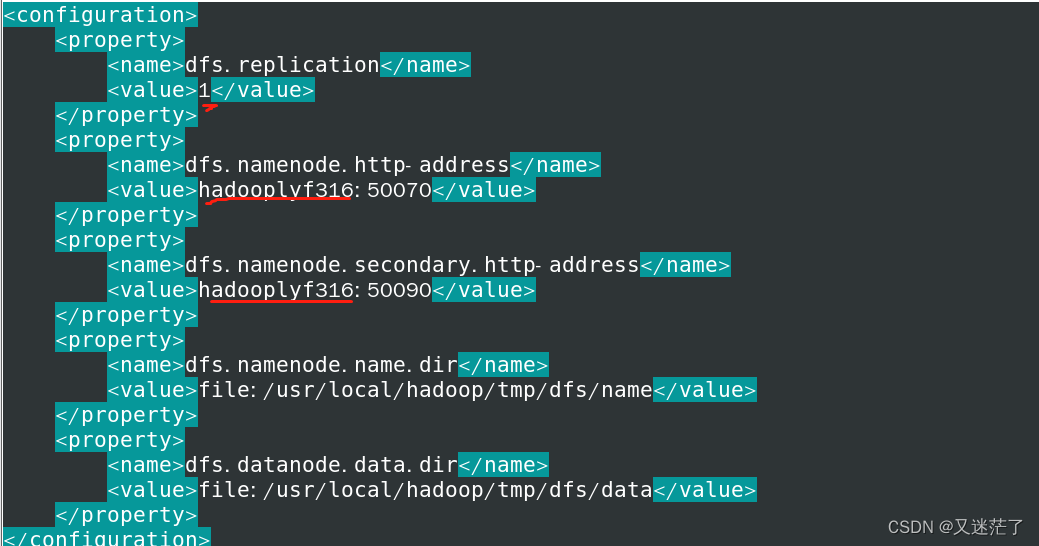
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.namenode.http-address</name>
<value>hadooplyf316:50070</value>
</property>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>hadooplyf316:50090</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/usr/local/hadoop/tmp/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/usr/local/hadoop/tmp/dfs/data</value>
</property>
</configuration>
4.修改mapred-site.xml
vim mapred-site.xml打开文件
(和上面配置文件方法一样)
<configuration>
<property>
<name>mapreduce.admin.user.env</name>
<value>HADOOP_MAPRED_HOME=$HADOOP_COMMON_HOME</value>
</property>
</configuration>5.修改yarn-site.xml(同上)
vim yarm-site.xml
打开配置文件

<configuration>
<property>
<!--指定yarn的老大resourcemanager的地址-->
<name>yarn.resourcemanager.hostname</name>
<value>aliyun01</value>
</property>
<property>
<!--NodeManager获取数据的方式-->
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>四.配置免密登录
1.输入ssh-keygen
一路回车
[root@hadooplyf316 ~]# ssh-keygen
Generating public/private rsa key pair.
Enter file in which to save the key (/root/.ssh/id_rsa):
/root/.ssh/id_rsa already exists.
Overwrite (y/n)? yes
Enter passphrase (empty for no passphrase):
Enter same passphrase again:
Your identification has been saved in /root/.ssh/id_rsa.
Your public key has been saved in /root/.ssh/id_rsa.pub.
The key fingerprint is:
bb:2a:5f:2b:9f:44:ce:68:ab:ae:cf:4d:c5:e6:81:b5 root@hadooplyf316
The key's randomart image is:
+--[ RSA 2048]----+
| |
| |
| . |
| + . |
| . E |
| O o |
| + B |
| ..+.+ + |
| .+=+=+= |
+-----------------+2.将公钥拷贝到远程机器,
$ ssh-copy-id [user]@[host](自己根据自己修改)
结果和下图一样就行
[root@hadooplyf316 ~]# ssh-copy-id root@aliyun01
The authenticity of host 'hadooplyf316 (172.16.41.97)' can't be established.
ECDSA key fingerprint is 7a:57:4b:32:d8:ab:2b:c4:95:f4:67:c6:fd:4b:eb:6d.
Are you sure you want to continue connecting (yes/no)? yes
/usr/bin/ssh-copy-id: INFO: attempting to log in with the new key(s), to filter out any that are already installed
/usr/bin/ssh-copy-id: INFO: 1 key(s) remain to be installed -- if you are prompted now it is to install the new keys
root@hadooplyf316's password:
Number of key(s) added: 1
Now try logging into the machine, with: "ssh 'root@hadooplyf316'"
and check to make sure that only the key(s) you wanted were added.3.检验
ssh 主机名
试试看能否成功免密登录
出现和下面截图相同的,就可以了

五.防火墙
由于hadoop中的程序都是网络服务,需要监听端口,这些端口默认会被linux防火墙挡住。因此要把hadoop中的端口一个个打开,或者把防火墙关掉。由于都是内网,所以关掉就好了。
sudo firewall-cmd --state查看防火墙状态sudo systemctl stop firewalld.service关闭防火墙
sudo systemctl disable firewalld.service关闭开机时防火墙自启
六.启动Hadoop
1.初始化
输入:hadoop namenode -format
2.启动
先进入到sbin目录下(/user/local/hadoop/sbin)
输入:
start-all.sh然后可以输入jps 查看已成功启动的进程
和下图一样的进程出现就行

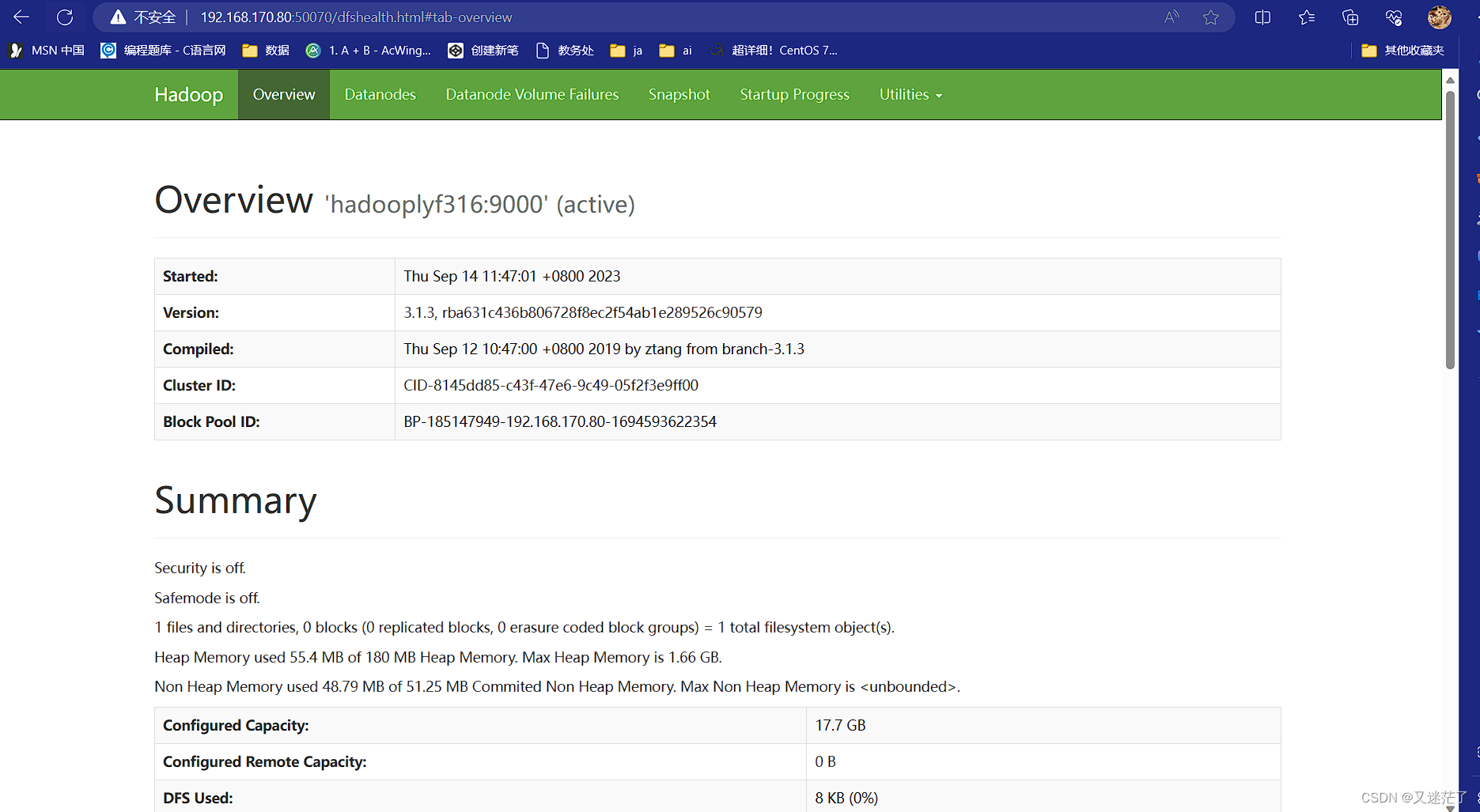
七.通过浏览器访问hadoop
http://[server_ip]:50070访问hadoop
[server_ip]:ky 改为虚拟机地址或者你虚拟机的主机名字
















 3万+
3万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









