






整体思路:
①先获取csdn首页源码,在源码中找到具体文章对应的链接
②根据链接再进行文章页面的源码获取
③获取文章内容
④对文章内容进行处理和拆分
⑤统计各词汇的出现频率,筛选出前20个高频词汇
⑥绘制云图
一、获取csdn首页源码
from selenium.webdriver.edge.options import Options
from selenium import webdriver
# 隐藏浏览器界面
options = Options()
options.add_argument('headless')
# 创建浏览器对象
edge = webdriver.Edge(options=options)
# 获取指定url的页面
edge.get('https://www.csdn.net/')
# 获取网页源码
source = edge.page_source
# 把网页源码存入到本地的csdn.html文件中
with open('csdn.html', 'w', encoding='utf-8') as fp:
fp.write(source)这里创建Options()对象的目的是隐藏浏览器窗口(默认情况下在进行爬取时会弹出浏览器窗口)
然后添加一个'headless'参数,并在创建浏览器对象的时候作为参数传入
二、获取文章页源码
这里以这一篇文章为例
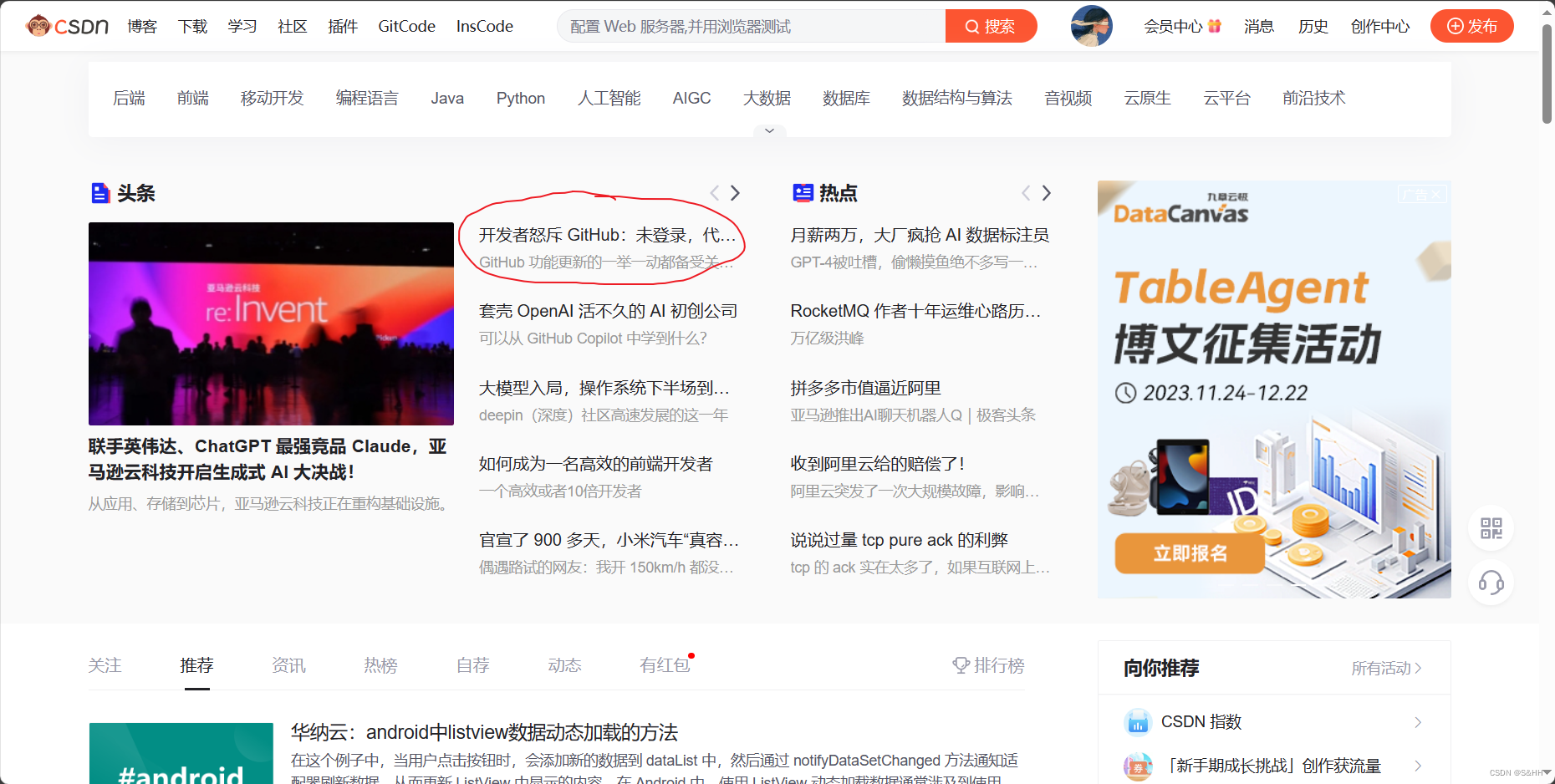
①对网页元素进行捕获,可以看到文章对应的链接

②根据xpath路径来获取文章链接
可以自己根据标签的结构进行分析,也可以右击标签内容直接进行复制
from lxml import etree
# 创建一个etree对象,把首页的源码传入
tree = etree.HTML(source)
# 得到的是一个列表
essay_url = tree.xpath('//*[@id="floor-www-index_558"]/div/div[3]/div[1]/div[2]/div[1]/div[2]/div/div[1]/a[1]/@href')[0]
# 打开文章对应的的url
edge.get(essay_url)
# 获取文章页源码
essay = edge.page_source
三、获取文章内容
对文章源码进行分析,可以看到部分内容直接存放在p标签下,另一部分存放在p下的a标签中,要同时对这些内容进行获取
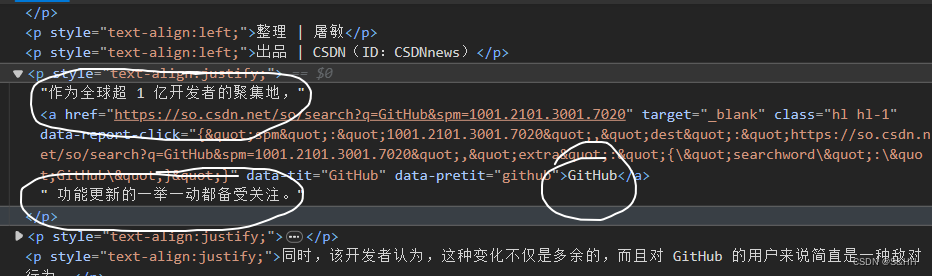
# 创建etree对象,并将文章网页源码传入
tree_essay = etree.HTML(essay)
# 获取p标签下的文本内容和p标签下的a标签中的文本内容
# 中间用|连接要获取的两个标签内容,表示 或
essay_list = tree_essay.xpath('//*[@id="js_content"]/p/text() | //*[@id="js_content"]/p/a/text()')
# 把获取到的文本存入本地
with open('essay.txt', 'w', encoding='utf-8') as fp:
for i in essay_list:
fp.write(i + '\n')上面在向文件中写入的时候加入一个换行符是为了让结果显示的更加直观
获取到的文本内容
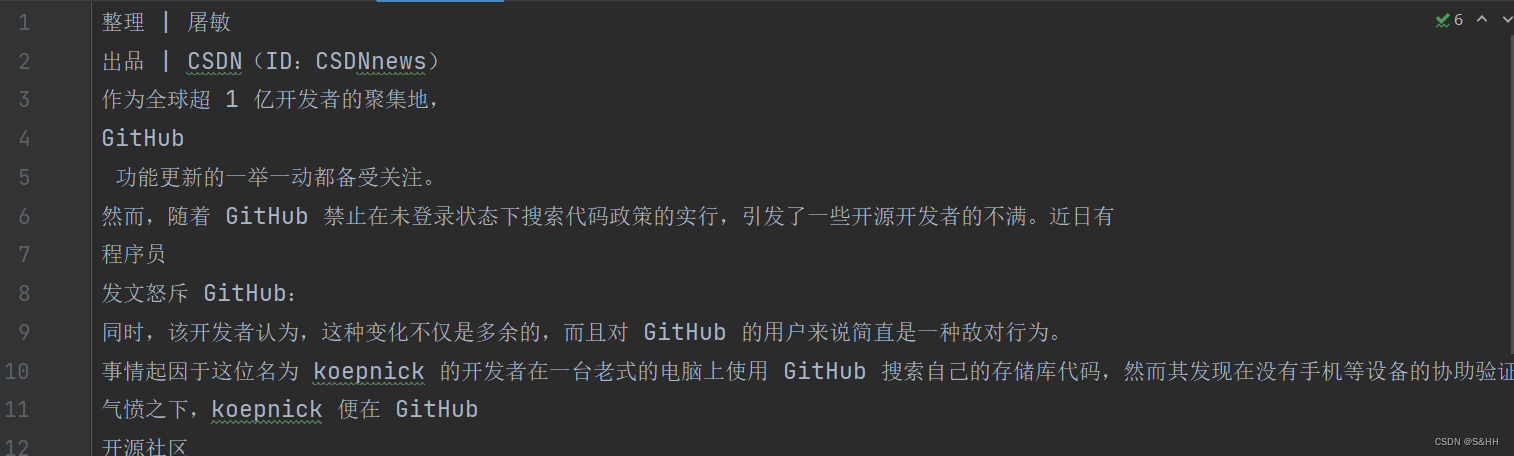
四、对文章内容进行处理
(在统计高频词汇时只保留汉字,英文字母和数字)
re.sub()方法中是根据正则表达式对text中的内容进行匹配,把匹配到的字符串转换为空,即''
返回的是替换后的新字符串
import re
text = ''
with open('essay.txt', 'r', encoding='utf-8') as fp:
text += fp.read()
# 对文本进行处理,只保留汉字,字母,数字
new_text = re.sub('[^\u4e00-\u9fa5a-zA-Z0-9]', '', text)对替换后的文本进行分词处理,需要用到jieba模块
import jieba
# 进行分词
words = jieba.cut(new_text)
# 进行数量统计
# 返回值为一个字典,包含了所有词汇和出现的次数
words_counts = Counter(words)
# 获取前20个高频词
top_words = words_counts.most_common(20)
# 循环获取词汇,并添加到新列表中
text_list = []
for i in top_words:
text_list.append(i[0])
# 将列表中个元素拼接起来,中间用空格隔开
res = ' '.join(text_list)
得到的top_words是一个嵌套列表,要把词汇从列表中分离出来,所以创建了一个text_list来接收词汇,在进行云图绘制前要把各个词汇之间用空格隔开,用' '.join(text_list)来完成这个功能
五、绘制云图
(只介绍了云图的基本用法)
WordCloud()的第一个参数是本地文件中的字体样式,可以从C盘Windows中的Fonts中复制到项目中,第2,3,4个参数分别为宽,高,背景色,最后一个参数为云图的形状,也可以不添加参数,使用默认形式
from wordcloud import WordCloud
import cv2
import numpy as np
# 云图形状参数
mask = np.array(cv2.imread('img.png'))
# 创建 WordCloud 对象
# 设置字体路径,宽高,背景色,词云形状
word_cloud = WordCloud(font_path='msyh.ttc', width=800, height=400, background_color="black", mask=mask).generate(res)
# 绘制词云图
plt.imshow(word_cloud)
# 关闭坐标轴
plt.axis("off")
# 云图展示
plt.show()云图形状设置
例:云图的形状为五角星,在本地准备一个五角星的图像,背景颜色随意

用cv2模块读取图像,存储形式为矩阵(cv2是一个图像处理模块)
cv2.imread('img.png')把读取到的内容再转换为数组,得到WordCloud()方法中云图形状的参数
np.array(cv2.imread('img.png'))再通过generate()方法,把文本传入
background_color="black", mask=mask).generate(res)六、结果展示

七、完整代码
import re
from selenium import webdriver
from selenium.webdriver.edge.options import Options
from lxml import etree
import jieba
from collections import Counter
from wordcloud import WordCloud
import matplotlib.pyplot as plt
import cv2
import numpy as np
# 隐藏浏览器界面
options = Options()
options.add_argument('headless')
edge = webdriver.Edge(options=options)
# 获取指定url的页面
edge.get('https://www.csdn.net/')
source = edge.page_source
with open('csdn.html', 'w', encoding='utf-8') as fp:
fp.write(source)
# 得到超链接内的url
tree = etree.HTML(source)
# 得到的是一个列表
essay_url = tree.xpath('//*[@id="floor-www-index_558"]/div/div[3]/div[1]/div[2]/div[1]/div[2]/div/div[1]/a[1]/@href')[0]
# 打开文章对应的的url
edge.get(essay_url)
essay = edge.page_source
tree_essay = etree.HTML(essay)
essay_list = tree_essay.xpath('//*[@id="js_content"]/p/text() | //*[@id="js_content"]/p/a/text()')
with open('essay.txt', 'w', encoding='utf-8') as fp:
for i in essay_list:
fp.write(i + '\n')
# 统计高频词汇
text = ''
with open('essay.txt', 'r', encoding='utf-8') as fp:
text += fp.read()
# 对文本进行处理,只保留汉字,字母,数字
new_text = re.sub('[^\u4e00-\u9fa5a-zA-Z0-9]', '', text)
# 进行分词
words = jieba.cut(new_text)
# 进行数量统计
# 返回值为一个字典,包含了所有词汇和出现的次数
words_counts = Counter(words)
# 获取前20个高频词
top_words = words_counts.most_common(20)
print(top_words)
text_list = []
for i in top_words:
text_list.append(i[0])
# 将列表中个元素拼接起来,中间用空格隔开
res = ' '.join(text_list)
# 获取图像并且将图像转换为数组,得到mask属性
mask = np.array(cv2.imread('img.png'))
# 创建 WordCloud 对象
# 设置字体路径,宽高,背景色,词云形状
word_cloud = WordCloud(font_path='msyh.ttc', width=800, height=400, background_color="black", mask=mask).generate(res)
# 绘制词云图
plt.imshow(word_cloud)
# 关闭坐标轴
plt.axis("off")
# 云图展示
plt.show()















 1436
1436











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









