






索引概念
索引是一种特殊的文件,包含着对数据里所有数据的引用的指针。可以对表中的一列或多列创建索引,并指定索引的类型,各类索引有各自的数据结构实现。
索引作用
- 数据库中的表、数据、索引之间的关系,类似于书架上的图书、书籍内容和书籍目录的关系
- 索引所起的作用类似书籍目录,可以用来快速定位、检索数据。
- 索引对于提高数据库的性能有很大的帮助。

使用场景
要考虑对数据库表的某列或者某几列创建索引,需要考虑一下几点:
- 数据量较大,且经常对这些列进行条件查询。
- 该数据库表的插入操作,及对这些列的修改操作频率较低。
- 索引会占用额外的磁盘空间。
满足以上的条件时候,我们优先考虑创建索引,以用来提高查询效率。
反之,如果非条件查询列,或者经常做插入、修改操作,或磁盘空间不足时候,不考虑创建索引。
我们要明白,索引的出现是为了提高MySQL中的查询语句也就是select的效率的,但是的创建是需要牺牲一定的硬盘存储空间。硬盘需要额外为你多开辟一块存储空间存放索引,但是现如今硬盘也不贵,大不了就多加点钱,用来扩充硬盘空间就行。
索引的引入确实能提升日常工作的效率,因为数据库中我们大部分用到的查询语句居多,可是面对 增、删、改 的效率可能会使其更慢!也可能会没有太大的变化。例如:我们通过条件判断的方式来删除delete from student where id = 5;在此语句的背后就有“查找”操作,就可以用到索引。但是,删除之后,还需要同步更新维护索引,就类似于移动数组(索引不是通过数组这一个数据结构来存储的,这里只是举个例子)。
总的来说,索引有利也有弊,但是即使如此我们实际开发中,还是比较鼓励使用索引的。
1.硬盘往往不是主要矛盾
2.对于增删改也不一定都是负面影响,也可能会出发一些正面效果,另一方面,很多业务场景,查询的频率往往比增删改要高很多
索引的使用
创建主键约束(PRIMARY KEY)、唯一约束(UNIQUE)、外键约束(FOREIGN KEY)时,会自动创建对应的索引。
- 查看索引
show index from 表名;
案例:查看学生表已有的索引
学生表结构如下:
含有id、sn、name、qq_mail、classes_id字段,其中id作为student表的主键约束,sn是唯一约束,classes_id是其他表的一个外键约束。
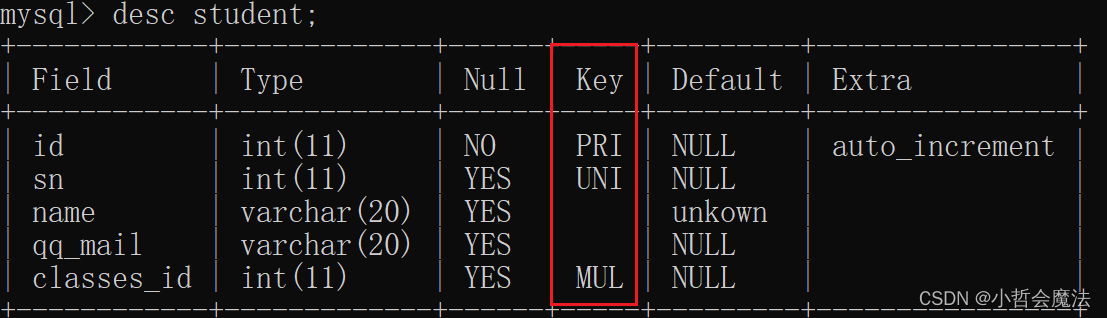
使用show index from 表名;查询语句

看到id、sn、classes_id 都创建了自己的索引。 - 创建索引
对于非主键、非唯一约束、非外键的字段,可以创建普通索引
create index 索引名 on 表名(字段名);
案例:创建学生表中,name字段的索引

使用show index from student;查看索引

- 删除索引
drop index 索引名 on 表名;
案例:删除学生表中name字段的索引

使用show index from student;查看索引

需要注意的是:
1.索引是根据某一列进行创建的,当你需要使用的时候,必须要选中这一列作为条件才能生效,就例如,id这一列已经自动生成了索引,这个时候我下如下语句都是可以生效的
select * from student id=xxx;
select * from student id<xxx;
select * from student id between xx and xx;
name是没有生成索引的,当你写如下语句是无法生效
select * from student name=xxx;
select * from student name<xxx;
2.删除索引,只能删除自己创建的索引,无法删除自动生成的索引。

索引底层数据结构(B+树)
我们学过二叉搜索树和哈希表,但是很遗憾的是这两个都不适合 数据库 做索引。
1)二叉搜索树,最大的问题在于“二叉”当要保存的元素多的时候,就会使整个树的结构高度比较高。一旦高度高了,比较的次数就会变多,硬盘上每次比较都是很伤的,会大大影响查询的速度。
2)哈希表,最大的问题在于只能进行“相等”查询,无法进行>、<这样的“范围查询”。也无法进行like模糊查询。
针对以上问题,我们MySQL索引用的是B+
树
B 树
了解B+树之前,我们要先了解什么是B树,我们学过二叉树,二叉树的特点是“二叉”,而B+树是一个N叉搜索树,每个节点有多个子树(树的高度是N)这样一来,就可以大大降低树的高度,并且每个节点上就不是存储一个key值,而是存储多个!
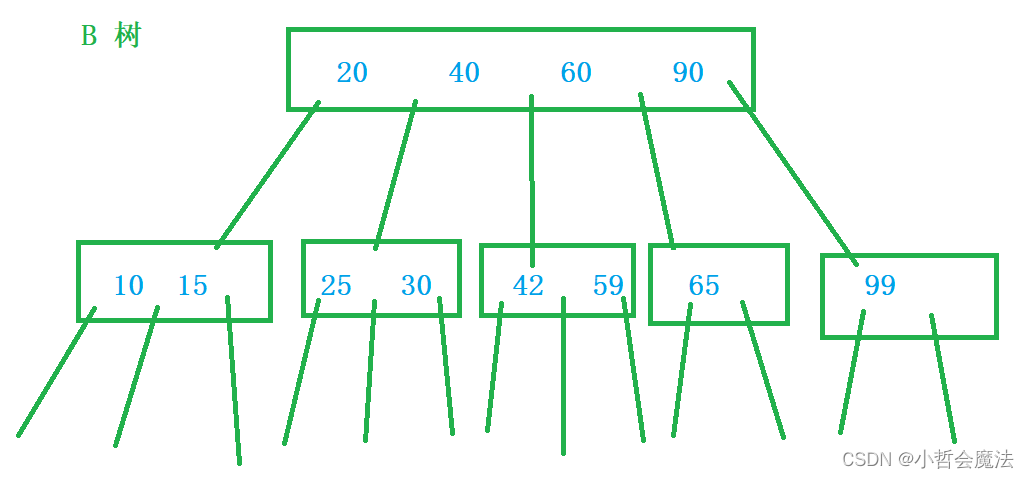
某个节点上保存了N个key就能延伸出N+1个子树,此时进行查询的时候,针对每个节点都需要比较多次,才能确定下一步走到哪个区间。
虽然高度降低了,但是每个节点的比较次数变多了,真的能比二叉树有优势吗?注意:其实优势还是很大的!!每个节点,访问的时候是一次硬盘IO,和每个节点进行比较的时候,是先经过依次硬盘IO,把所有的这个节点上的内容都读取出来,接下来的比较都是在内存中进行,这里主要目的不是为了减少比较的次数而是要减少硬盘IO的次数!
B+ 树
B+ 树是针对B 树做出的进一步的改进,B+树也是N叉搜索树

1)不同于B树,B树有N个key,划分成N+1个区间,B+树是有N个key,划分出N个区间
2)父节点中的key的值,会在下面的子节点中再次出现(以子节点中的最大值的身份)
3)B+树把叶子节点,像一个链表一样进行收尾相连了,此时查询范围就会非常方便!
B+树的优势:
1.N叉搜索树,高度比较低,此时硬盘IO次数就会比较少。
2.叶子节点是全集,并且用链表结构相连,非常便于范围查询
3.B+树,所有的查询都是要落到叶子节点上完成的,任何一次查询经历的IO次数和比较次数都是差不多的,查询的开销稳定。
4.由于B+树叶子是全集,非叶子节点上不必存储真实的“数据行”,只要存储索引的key即可,是的非叶子节点开销的空间比较少。















 10万+
10万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









