






一.引出索引
前面一章我们说出了数据页的结构,但是如果我们要查找某一条记录的话,怎么办呢?
我们前面知道页与页之间是一个双向链表实现的,我们要找的话,是不是要按照这个链表一个一个找下去,然后找到,可行吗?确实可行,但是如果这个表有一亿个数据的话,那就太慢了!
所以就又有人提出建议了,说我们可以先找到那条记录所在页,然后找到那条记录~
那么问题来了怎么找到那条记录所在的页,怎么找到那条记录?
那么我们的索引就出现了
二.索引
我们在这里就正式提出索引这个概念了!那么在此之前我们继续一个小插曲
还记得我们之前说的那个COMPACT格式是不是有一个record_type next_record

我们回想一下他们有什么作用来这?
record_type:这个就是表示记录得类型,0表示普通记录,2表示Infimum记录,3表示Supermum记录,1表是就是目录项记录
next_record:这个表示的就是从当前记录的真实数据到下一条记录的真实数据的距离
一个比较简单的索引方案
当我们为了要快速定位记录的数据页的时候,我们就要创建这个目录
1.下一个数据页中用户记录的主键值必须要大于上一个数据页中用户记录的主键值
2.给所有页建立一个目录项
页的用户记录中最小的主键就用key来表示,页号我们用page_no表示
 对了我们刚刚是不是一点索引没提,这个目录有个别名就叫做索引~
对了我们刚刚是不是一点索引没提,这个目录有个别名就叫做索引~
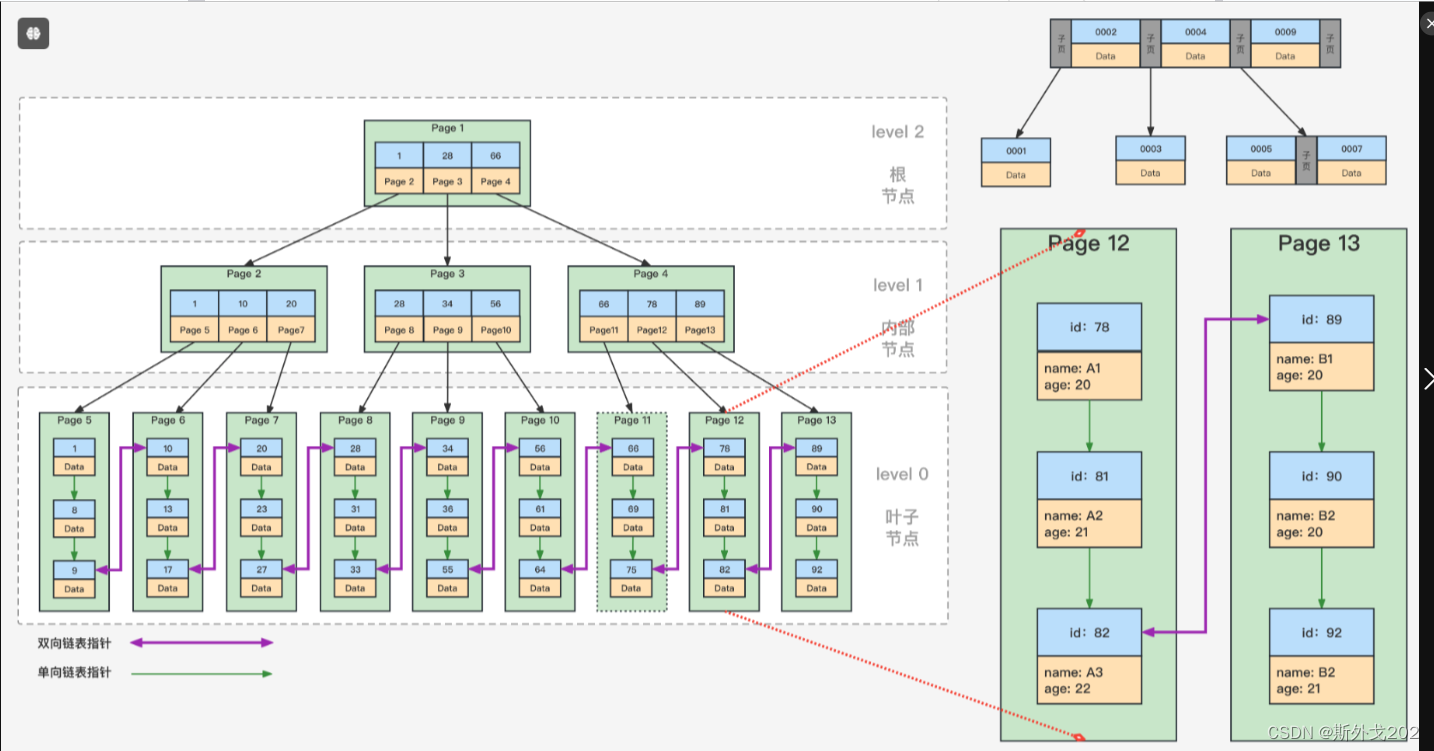
InnoDB的索引方案
InnoDB中的索引使用的数据结构是B+树?学过数据结构的小伙伴肯定有疑问为什么不使用二叉树,为什么不使用红黑树?等等我们现在来解释一下
B+树是多叉树,平衡二叉树、红黑树是二叉树,在同等数据量下,平衡二叉树、红黑树高度更高,磁盘O次数更多,性能更差,而且它们会频繁执行再平衡过程,来保证树形结构平衡。
跳表和B+树相比,跳表在极端情况下会退化为链表,平衡性差,而数据库查询需
要一个可预期的查询时间,并且跳表需要更多的内存。
B树和B+树相比,B树的数据存储在全部节点中,对范围查询不友好。非叶子节点存储了数据,导致内存中难以放下全部非叶子节点。如果内存放不下非叶子节点,那么就意味着查询非叶子节点的时候都需要磁盘IO。
然后我们来说一下B+树的结构~
最上面的节点叫做根节点,然后最下面的叫做叶子节点,中间的叫做非叶子节点
非叶子节点储存这存放着目录项的数据页
叶子节点储存这存放这个用户记录的数据页
他分为两种索引形式
1,聚簇索引
他的特点是是按照主键进行排序的,然后叶子节点中存放的数据是所有列的值
2,二级索引
他的特点是按照自己定义的进行排序,然后叶子节点中存放的数据是索引列+主键
但是他如果想要完整的值的是需要回表,然后进行聚簇索引进行查找的
InnoDB的索引注意事项
1.根节点万年不动
2.非叶子节点目录项记录的唯一性
目录项记录其实是由:
- 索引列的值
- 主键值
- 页号
3.一个页面至少储存两条记录















 1186
1186

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









