






 本文探讨了大数据的四个关键特征:数量庞大、多样性、高速性和价值性,介绍了结构化和非结构化数据的区别,并详细解析了Hadoop的HDFS架构,包括NameNode、DataNode和读取流程。
本文探讨了大数据的四个关键特征:数量庞大、多样性、高速性和价值性,介绍了结构化和非结构化数据的区别,并详细解析了Hadoop的HDFS架构,包括NameNode、DataNode和读取流程。
一、大数据的特征
1、数量大
大数据的特点之一就是“数量大”,数据量已经达到TB甚至PB级别,无法通过人工处理。例如,淘宝网平常每天的商品交易数据约20TB(1TB=1024GB),全球最大设计平台Facebook的用户,每天产生的日志数据超过了300TB。大数据的数量庞大,包含着大量的规律、知识、模式,对政府决策、生活有巨大的影响。
2、多样性
大数据广泛的数据来源,决定了大数据形式的多样性。大数据大体上可以分为三类,分别是结构化数据、非结构化的数据、半结构化数据。结构化数的特点是数据间因果关系强,比如息管理系统数据、医疗系统数据等;非结构化的数据的特点是数据间没有因果关系,比如音频、图片、视频等;半结构化数据的特点是数据间的因果关系弱。比如网页数据、邮件记录等。
3、高速性
大数据的交换和传播是通过互联网、云计算等方式实现的,远比传统媒介的信息交换和传播速度快捷。大数据与海量数据的重要区别,除了大数据的数据规模更大以外,大数据对处理数据的响应速度有更严格的要求。实时分析而非批量分析,数据输入、处理与丢弃立刻见效,几乎无延迟。数据的增长速度和处理速度是大数据高速性的重要体现。
4、价值性
价值性是大数据的核心特点。现实中大量的数据是无效或者低价值的,大数据最大的价值在于通过从大量不相关的各种类型的数据中,挖掘出对未来趋势与模式预测分析有价值的数据。比如,某宝电商平台每天产生的大量交易数据(大数据),通过一些算法可以分析出具有某些特征的人喜欢什么类型的商品,然后根据客户的特征,给其推荐TA喜欢的商品。
二、结构数据化与非结构数据化
1. 概述不同
结构化数据是指按照固定格式和规则组织的数据,例如表格、数据库等。非结构化数据则是指没有固定格式和规则的数据,例如文本、音频和视频等。
2. 含义不同
结构化数据是按照固定格式和规则组织的数据。例如,电子表格中的数据就是结构化数据,因为它们按照一定的列和行组织,并且每个单元格都有自己的数据类型和格式。
非结构化数据是没有固定格式和规则的数据。例如,一篇文章中的文本就是非结构化数据,因为它没有固定的格式和规则,也没有明确的数据类型和格式。
3.. 组织方式和数据类型不同
结构化数据按照固定格式和规则组织,具有明确的数据类型和格式,而非结构化数据没有固定的格式和规则,也没有明确的数据类型和格式。此外,结构化数据可以方便地进行处理和分析,而非结构化数据则需要进行特殊的处理和分析。
四、Hadoop —— hdfs架构
HDFS的系统角色一共有四种:NameNode(主节点)、SecondaryNameNode(备用节点)、DataNode(从节点)、Client(HDFS客户端)。
NameNode(主节点):里面主要负责管理文件系统的命名空间,维护着整个文件系统的目录树以及目录树中所有的子目录和文件。
SecondaryNameNode(备用节点):NameNode的备用节点,也成为从元数据节点,主要用于定期合并FsImage和Edit Log。SecondaryNameNode的主要作用是辅助NameNode合并FsImage和Edit Log。
DataNode (从节点):也称为数据节点,上面也提到过,一份数据文件在放入hdfs的时候,它会被分成多个数据块(block),而这些数据块就会被存储到多个DataNode节点上的特定位置,块的名称为blk_blkID。
下面是它的架构图:

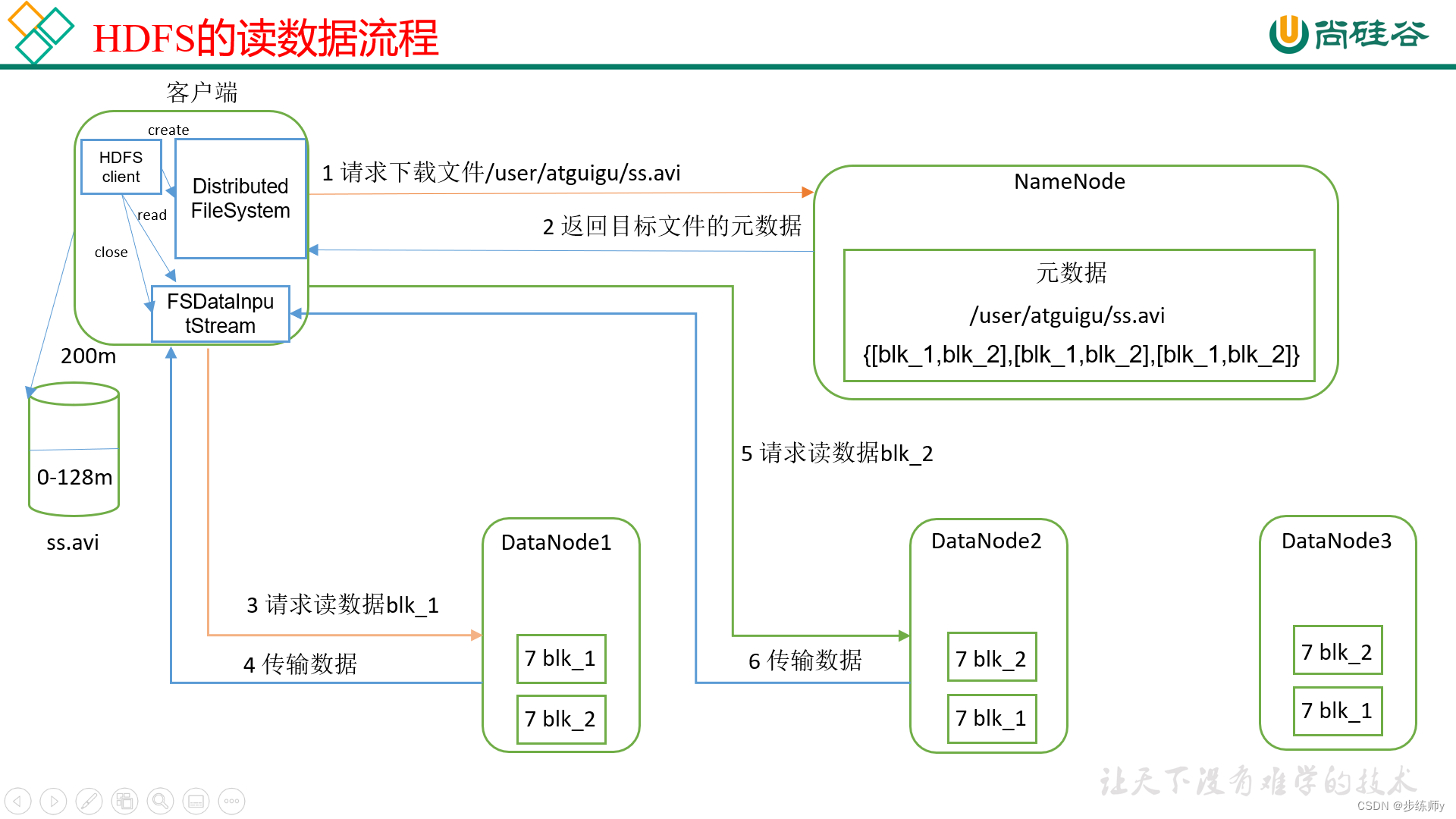
五、HDFS读的流程
1、客户端通过分布式文件系统向NameNode请求下载文件,请求包括要读取的路径和偏移量。
2、NameNode通过查询元数据,找到文件所在的DataNode地址,响应文件是否存在,并返回目标文件的元数据。
3、客户端通过就近原则选一台DataNode服务器请求读取数据。
4、DataNode开始传输给客户端,从磁盘里读取数据,以packet为单位作校验。
5、客户端以Packet为单位接收,先在本地缓存,然后合并写入目标文件。















 5430
5430











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









