






1 MapReduce概述
1.1 定义
MapReduce是一个分布式运算程序的编程框架,是用户开发“基于Hadoop的数据分析应用”的核心框架。
MapReduce核心功能是将用户编写的业务逻辑代码和自带默认组件整合成一个完整的分布式运算程序,并发运行在一个Hadoop集群上。
1.2 特点
优点:
- 易于编程
- 良好的扩展性
- 高容错性
- 适合PB级以上海量数据的离线处理
缺点:
- 不擅长实时计算(MySQL)
- 不擅长流式计算:输入数据集是静态的,不能动态变化
- 不擅长DAG(有向无环图)计算,MR结果输出到 磁盘,造成大量磁盘IO,性能低下
1.3 核心思想
-
分布式的运算程序至少两个阶段
-
MapTask并发实例,完全并行运行,互不相干
-
ReduceTask并发实例互不相干,但是他们的数据依赖于上一个阶段的所有MapTask并发实例的输出
-
MapReduce编程模型只能包含一个Map阶段和一个Reduce阶段
-
可以多个MapReduce程序,串行运行,解决复杂的业务逻辑
1.4 进程
- MrAppMaster:负责整个程序(任务/job/mr)的过程调度及状态协调,是yarn中的APPMaster的子进程
- MapTask(yarnchild,yarn的子进程)
- ReduceTask(yarnchild,yarn的子进程)
1.5 MapReduce编程规范
-
Mapper阶段
1)继承Mapper类
2)输入数据默认是KV对:key偏移量,value:一行的内容
3)将业务逻辑写在map()中
4)map()方法对每一个<k,v>(每行)调用一次
-
Reducer阶段
1)继承Reducer类
2)输入数据类型即Mapper的输出数据类型
3)业务逻辑写在reduce()中
4)对每一组相同k的<k,v的集合>调用一次reduce()
-
Driver阶段
YARN集群的客户端,提交整个程序到YARN集群,提交的是封装了MR程序相关运行参数的Job对象
1.6 测试
流程:windows环境下搭建hadoop环境–>编写代码–>本地测试–>打包上传–>执行命令,多jar包,使用任务调度器阿兹卡班,使用脚本执行命令,
2 Hadoop序列化
2.1 概念
序列化就是把内存中的对象,转换成字节序列(或其他数据传输协议)以便于存储到磁盘(持久化)和网络传输。
反序列化就是将收到字节序列(或其他数据传输协议)或者是磁盘的持久化数据,转换成内存中的对象。
2.2 意义
-
为什么要序列化?
序列化可以实现在传输数据时,保留数据的值和数据类型
对象只生存在内存中,且由本地进程使用,序列化可以将对象发送到远程计算机
一台服务器资源有限,mapTask和reduceTask可能不在一台服务器,服务器之间传输对象就需要实现序列化
-
为什么不用java的序列化?
java的序列化太重(Serializable),其序列化后附带(各种校验信息,Header,继承体系等),导致传输效率低下
Hadoop自己开发了一套序列化机制(Writable):特点
紧凑,快速,互操作
2.3 注意事项
- 自定义bean对象实现序列化步骤和java的序列化基本相同,但需要在自定义类中重写序列化和反序列化(所有字段)的方法
- 注意反序列化的顺序和序列化的顺序完全一致
- 重写toString()
- 如果需要将自定义的bean放在key中传输,则还需要实现Comparable接口,因为MapReduce框中的Shuffle过程要求对key必须能排序
3 MapReduce框架原理
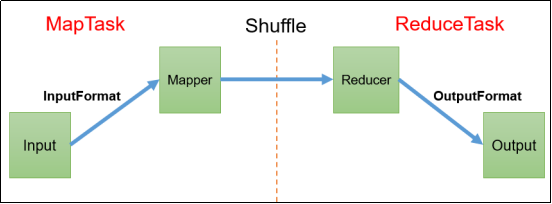
3.1 InputFormat数据输入
思考:理论上MapTask个数越多,集群并发处理能力越高,所以是否意味着MapTask并行任务越多越好?MapTask并行度又由什么决定?
3.1.1 切片与MapTask并行度决定机制
-
数据块:Block是HDFS物理上把数据分成一块一块。数据块是HDFS存储数据单位。
-
数据切片:数据切片只是在逻辑上对输入进行分片,并不会在磁盘上将其切分成片进行存储。
数据切片是MapReduce程序计算输入数据的单位,一个切片会对应启动一个MapTask。
针对每一个文件单独切片.
图解:
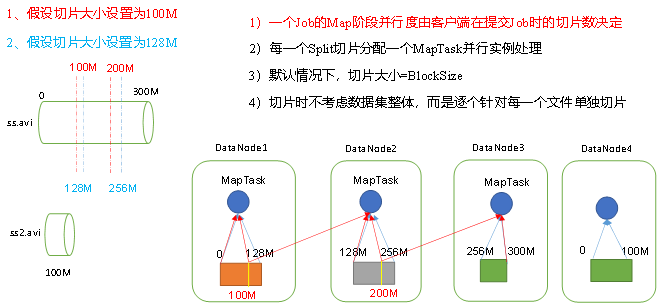
为什么默认设为切片大小等于块大小:
若设置切片大小为100M,导致同一切片里的数据在不同块block上,因此 MapTask想获取自己的切片数据除了从本地获取部分,还需要跨服务器通讯获取另一部分,导致效率下降
3.1.2 Job提交流程
job提交的过程中(Job.submit)生成三个重要文件:
- Job.spilt:获取切片规划
- xxx.jar:如果是集群环境下,将Job的jar包拷贝到集群
- Job.xml:将Job相关参数写到该文件
Job提交完毕即删除本地的三个文件

3.1.3 FileInputFormat切片机制
-
简单地按照文件的内容长度进行切片
-
切片大小,默认等于Block大小
-
切片时不考虑数据集整体,而是逐个针对每一个文件单独切片
计算切片大小?
Math.max(minSize, Math.min(maxSize, blockSize));
其中:
mapreduce.input.fileinputformat.split.minsize=1 默认值为1
mapreduce.input.fileinputformat.split.maxsize= Long.MAXValue 默认值Long.MAXValue
因此,默认情况下,切片大小=blocksize。
说明:
-
FileInputFormat常见的接口实现类包括:TextInputFormat、KeyValueTextInputFormat、NLineInputFormat、CombineTextInputFormat和自定义InputFormat等。
其中,TextInputFormat是默认的FileInputFormat实现类。按行读取每条记录。key是偏移量,value是一行内容
-
对于不支持切片的压缩文件,FileInputFormat无法对其切片并使用实现类读取
3.1.4 CombineTextInputFormat切片机制
思考小文件问题:
框架默认的TextInputFormat切片机制是对任务按文件规划切片,不管文件多小,都会是一个单独的切片,都会交给一个MapTask,这样如果有大量小文件,就会产生大量的MapTask,处理效率极其低下。
应用场景:
CombineTextInputFormat用于小文件过多的场景,它可以将多个小文件从逻辑上规划到一个切片中,这样,多个小文件就可以交给一个MapTask处理。
切片机制:
生成切片过程包括:虚拟存储过程和切片过程二部分。
怎么确定哪些虚拟 存储的文件合并成 一个切片?
切片的顺序是基于字典序:将虚拟存储的文件排序 后 切片(单独切片/进行合并)
3.2 MapReduce工作流程
-
准备待处理的输入文件
-
客户端submit前切片分析
-
提交三样(Job.spilt,wc.jar,Job.xml)到Yarn集群
-
Yarn开启Mrappmaster,读取Job.spilt切片信息开启对应个数MapTask
-
默认的TextInputFormat使用RecorderReader方法按行读取
-
读的一行数据给MapTask,进行用户自定义逻辑运算(对切片反复读取一行并运算)
-
MapTask的输出溢写到环形缓冲区
outputCollector:环形缓冲区
又叫输出收集器,可视为内存:大小默认100M,一半存储<k,v>结构数据,一半存储对应的Meta索引,其中索引就是元数据,包含index|partition|keystart|valstart
缓冲区溢写到80%开始反向溢写?
80%开始向磁盘溢写,不用等待内存满100%时溢写到磁盘的过程,高效处理数据,另外:反向溢写的线程如果追上磁盘溢写的线程,前者会等待后者以防止数据覆写丢失
-
还在内存中:标记分区的数据进入到不同分区(对应不同ReduceTask),分区内快排(不改动数据位置,对key的索引按字典序排序)[可选combiner聚集操作]
-
将环形缓冲区数据(不同分区的数据,仍在一个文件里)溢写到磁盘,可能会溢出多个临时文件(每个文件内数据分区且区内有序)
-
溢出完毕,将磁盘中大量的溢写文件以分区为单位合并,归并排序,直到最终得到一个大文件
-
Combiner合并,预聚合
-
MrappMaster观察到所有的MapTask任务完成后,启动相应数量的ReduceTask,并行处理分区内数据
-
ReduceTask根据自己的分区号,去各个MapTask机器上将自己分区内数据下载到内存或溢写到本地磁盘,合并文件,归并排序(到此为止,Shuffle混洗过程结束)
-
分组:将相同key的value放入集合中
-
一次读取一组(相同key),执行业务逻辑运算
-
默认的TextOutputFormat调用RecordWriter写出数据到分区文件
3.3 Shuffle机制
map方法的输出getpartition()标记数据是哪个分区–>进入环形缓冲区–>对分区的数据快排–>多次溢出(Combiner聚合可以减小数据传输量,提高效率),生成多个溢写文件–>归并排序,合并成一个大文件,文件内数据分区且区内有序–>(Combiner聚合)–>(压缩)–>写入到磁盘–>reduce端拷贝所有map输出数据中自己分区的数据到本地内存缓冲(内存不够溢出到磁盘)–>归并排序–>按照相同key分组–>一组数据进入reduce方法
3.4 分区
-
默认按key的hashCode控制key存储到哪个区
-
自定义分区数n:
job.setNumReduceTasks(1):只产生一个输出文件,代码不走自定义分区,走hashpartitioner分区(内部类)
job.setNumReduceTasks(<n):某些分区数据未处理,报异常
job.setNumReduceTasks(>n):产生空文件,且浪费资源
3.5 排序
将map阶段输出的key实现了WritableComparable接口,重写比较规则
3.6 Combiner合并
- 对每一个MapTask的输出进行局部汇总,以减小网络传输量[如下图],其在MapTask所在节点运行
- Combiner能够应用的前提是不能影响最终的业务逻辑,而且,Combiner的输出kv应该跟Reducer的输入kv类型要对应起来。可以预聚合累加,但不能预聚合求平均值.
1)未设置自定义合并,传输量为10

2)开启预聚合,传输量为7

3.7 OutputFormat数据输出
-
默认输出格式TextOutputFormat(k+"\t"+v)
-
自定义OutputFormat:
自定义RecordWriter的继承类,
重写write()方法修改输出内容,
通过Job的配置信息创建文件系统–>创建输出流修改data文件和检验和文件的输出路径,标志文件路径仍是OutputFormat设置的原路径
3.8 ReduceTask并行度决定机制
- ReduceTask默认值是1,输出文件数为1
- 数据分布不均reduce阶段数据倾斜
- 设置个数按需求和集群性能:最终一个文件就1个reducetask
- 按分区需求手动设置ReduceTask个数,一个task对应一个文件,对应一个分区
- 手动设置多个reducetask,数据将按默认的hashCode计算方法分配到不同分区,输出文件数量激增
- 分区不是1,但reduceTask是1,不执行分区过程,只生成一个文件
4 Join
4.1 Reduce Join
Map端主要工作:
setup()方法中获取切片信息(表名),打标签以区别不同表的记录,并以连接字段作为key输出
Reduce端主要工作:
以value的标记区分记录的来源并分开保存(先将元素复制,再保存),再进行合并
缺点:
这种方式中,合并的操作是在Reduce阶段完成,Reduce端的处理压力太大,Map节点的运算负载则很低,资源利用率不高,且在Reduce阶段极易产生数据倾斜。
4.2 Map Join
适用于一张表十分小、一张表很大的场景。
具体操作:
采用DistributedCache
(1)在Mapper的setup阶段,将文件读取到缓存集合中。
(2)在Driver驱动类中加载缓存。
//缓存普通文件到Task运行节点。 job.addCacheFile(new URI("file:///e:/cache/pd.txt")); //如果是集群运行,需要设置HDFS路径 job.addCacheFile(new URI("h dfs://hadoop102:8020/cache/pd.txt"));
- 1
- 2
- 3
- 4
问题:
- reduce Join中相同key的集合元素无法直接添加到临时集合,需要临时中间变量过渡
- map Join中小表第一行记录存入集合中取出value为空
5 压缩
















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









