






0.1 Numpy介绍
NumPy(Numerical Python)是Python的⼀种开源的数值计算扩展。提供多维数组对象,各种派⽣对象(如掩码数组和矩阵),这种⼯具可⽤来存储和处理⼤型矩阵,⽐Python⾃身的嵌套列表(nested list structure)结构要⾼效的多(该结构也可以⽤来表示矩阵(matrix)),⽀持⼤量的维度数组与矩阵运算,此外也针对数组运算提供⼤量的数学函数库,包括数学、逻辑、形状操作、排序、选择、输⼊输出、离散傅⽴叶变换、基本线性代数,基本统计运算和随机模拟等等。
0.1.1 Numpy的特点
提供了强大N维数组类型NDAarray 可以用来存储任意维度的数据;
集成了统计学、科学计算、线性代数、矩阵运算、矢量处理等算法
提供了成熟的⼴播功能和掩码数组运算
提供了强大的随机数⽣成功能
0.2 Numpy安装
安装 NumPy 最简单的方法就是使用 pip 工具:
pip3 install --user numpy scipy matplotlib
–user 选项可以设置只安装在当前的用户下,而不是写入到系统目录。
默认情况使用国外线路,国外太慢,我们使用清华的镜像就可以:
pip3 install numpy scipy matplotlib -i https://pypi.tuna.tsinghua.edu.cn/simple
Linux 下安装
Ubuntu & Debian
sudo apt-get install python3-numpy python3-scipy python3-matplotlib ipython ipython-notebook python-pandas python-sympy python-nose
CentOS/Fedora
sudo dnf install numpy scipy python-matplotlib ipython python-pandas sympy python-nose atlas-devel
Mac 系统
Mac 系统的 Homebrew 不包含 NumPy 或其他一些科学计算包,所以可以使用以下方式来安装:
pip3 install numpy scipy matplotlib -i https://pypi.tuna.tsinghua.edu.cn/simple
相关链接
NumPy 官网 http://www.numpy.org/
NumPy 源代码:https://github.com/numpy/numpy
SciPy 官网:https://www.scipy.org/
SciPy 源代码:https://github.com/scipy/scipy
Matplotlib 教程:Matplotlib 教程
Matplotlib 官网:https://matplotlib.org/
Matplotlib 源代码:https://github.com/matplotlib/matplotlib
0.2.1安装验证
测试是否安装成功:
import numpy as np
为了使用方便,也为了风格的统一,一般在导入后将 numpy 取一个别名为np
0.3 Numpy数组对象ndarray
0.3.1 ndarray介绍
数组(Array):同类性数据元素按一定顺序有序排列的集合称为
数组
NumPy 最重要的一个特点是其 N 维数组对象 ndarray,它是一系
列数组叠加组成的N维数组;
NumPy最核心的数据类型是N维数组(The N-Dimensional
Array)ndarry。
数组和列表一样,以 0 下标为开始进行索引
ndarray数组示意图:
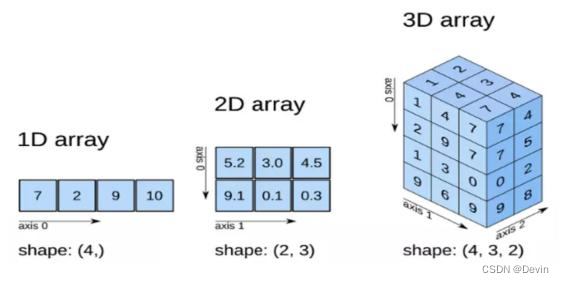
- axis=0,表示沿着第 0 轴进行操作,即对每一列进行操作;axis=1,表示沿着第1轴进行操作,即对每一行进行操作。
在一维数组里axis=0表示x轴;
在二维数组里axis=1表示x轴,axis=0表示y轴;
在三位数组里axis=0表示y轴,axis=1表示x轴,axis=1表示z轴.
即:所见即所得。
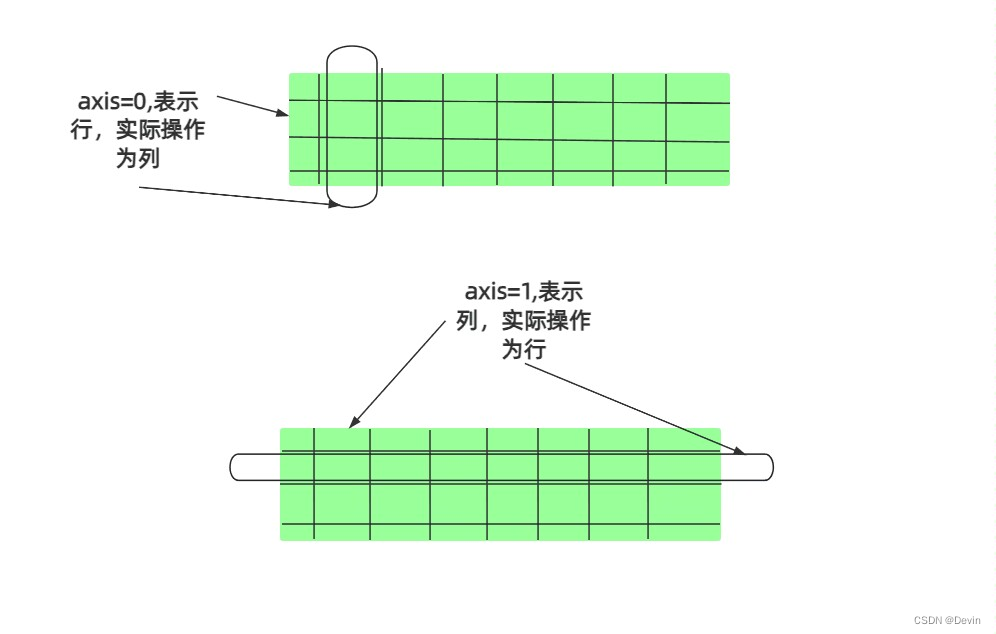
axis=0 表示行(实际操作是列)
axis=1 表示列(实际操作是行)
0.3.2. 一维数组、二维数组、三位数组之间的区别
实例:
假设某比赛分A,B,C三个组。每组有参赛者5名,分别来自15个不同的国家。
*一维数组
对于A组来说,一维数组相当于建立一个姓名列表 name =[‘参赛者A1’,‘参赛者A2’,…,‘参赛者A5’],列表里有5个元素,代表五个参赛者。
*二维数组
接着上面的,对于A组来说,二维数组相当于建立一个 姓名-国籍 数组
输出的(5, 2)表示,5行2列。意思是五个参赛者除了姓名属性外,还有国籍属性。有几个属性就有几列。相当于数据库表里的字段,有几个字段数据库表就有几列。
import numpy as np
nameCountry= np.array([[‘参赛者A1’,‘国籍A1’],
[‘参赛者A2’,‘国籍A2’],
[‘参赛者A3’,‘国籍A3’],
[‘参赛者A4’,‘国籍A4’],
[‘参赛者A5’,‘国籍A5’]])
print(nameCountry)
print(nameCountry.shape)
输出为:
[[‘参赛者A1’ ‘国籍A1’]
[‘参赛者A2’ ‘国籍A2’]
[‘参赛者A3’ ‘国籍A3’]
[‘参赛者A4’ ‘国籍A4’]
[‘参赛者A5’ ‘国籍A5’]]
(5, 2)
*三维数组
在上面两个的基础上。每组参赛者都有姓名-国籍属性,有三组,就形成了三维数组。代码如下:
import numpy as np
nameCountrys = np.array([
[[‘参赛者A1’,‘国籍A1’],[‘参赛者A2’,‘国籍A2’],[‘参赛者A3’,‘国籍A3’],[‘参赛者A4’,‘国籍A4’],[‘参赛者A5’,‘国籍A5’]],
[[‘参赛者B1’,‘国籍B1’],[‘参赛者B2’,‘国籍B2’],[‘参赛者B3’,‘国籍B3’],[‘参赛者B4’,‘国籍B4’],[‘参赛者B5’,‘国籍B5’]],
[[‘参赛者C1’,‘国籍C1’],[‘参赛者C2’,‘国籍C2’],[‘参赛者C3’,‘国籍C3’],[‘参赛者C4’,‘国籍C4’],[‘参赛者C5’,‘国籍C5’]]
])
print(nameCountrys)
print(nameCountrys.shape)
输出为:
[[‘参赛者A1’ ‘国籍A1’]
[‘参赛者A2’ ‘国籍A2’]
[‘参赛者A3’ ‘国籍A3’]
[‘参赛者A4’ ‘国籍A4’]
[‘参赛者A5’ ‘国籍A5’]]
(5, 2)
[[[‘参赛者A1’ ‘国籍A1’]
[‘参赛者A2’ ‘国籍A2’]
[‘参赛者A3’ ‘国籍A3’]
[‘参赛者A4’ ‘国籍A4’]
[‘参赛者A5’ ‘国籍A5’]]
[[‘参赛者B1’ ‘国籍B1’]
[‘参赛者B2’ ‘国籍B2’]
[‘参赛者B3’ ‘国籍B3’]
[‘参赛者B4’ ‘国籍B4’]
[‘参赛者B5’ ‘国籍B5’]]
[[‘参赛者C1’ ‘国籍C1’]
[‘参赛者C2’ ‘国籍C2’]
[‘参赛者C3’ ‘国籍C3’]
[‘参赛者C4’ ‘国籍C4’]
[‘参赛者C5’ ‘国籍C5’]]]
(3, 5, 2)
总结:其实一维就是只有一个属性,一种特征;二维就是有多个属性,多个特征;三维即有多组,每组的属性相同。
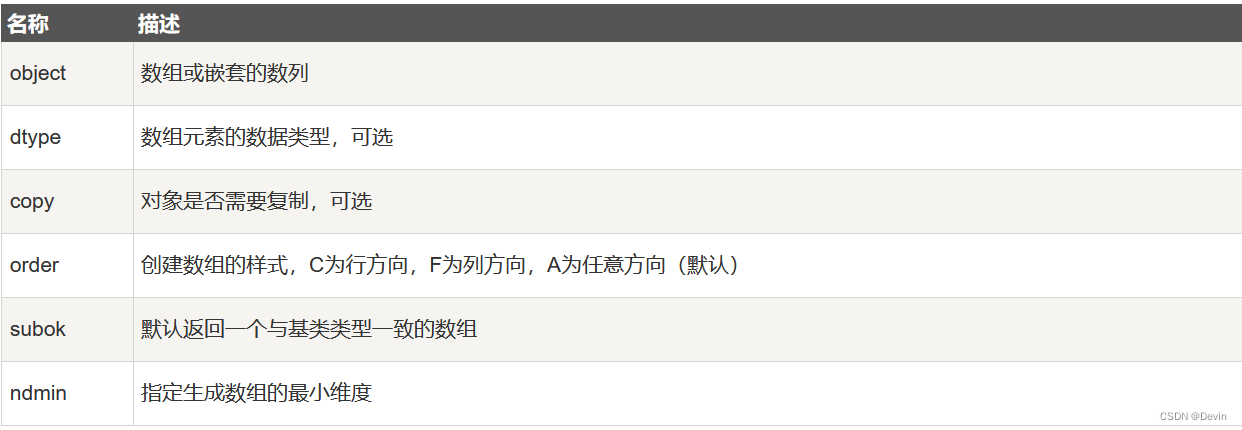
参数说明:
0.4 ndarray的创建
创建一个 ndarray 只需调用 NumPy 的 array 函数即可:
numpy.array(object, dtype = None, copy = True, order = None, subok = False, ndmin = 0)
实例 1
import numpy as np
a = np.array([1,2,3])
print (a)
输出结果如下:
[1 2 3]
实例 2
多一个维度
import numpy as np
a = np.array([[1, 2], [3, 4]])
print (a)
输出结果如下:
[[1 2]
[3 4]]
实例 3
最小维度
import numpy as np
a = np.array([1, 2, 3, 4, 5], ndmin = 2)
print (a)
输出结果如下:
[[1 2 3 4 5]]
实例 4
dtype 参数
import numpy as np
a = np.array([1, 2, 3], dtype = complex)
print (a)
输出结果如下:
[1.+0.j 2.+0.j 3.+0.j]
ndarray 对象由计算机内存的连续一维部分组成,并结合索引模式,将每个元素映射到内存块中的一个位置。内存块以行顺序(C样式)或列顺序(FORTRAN或MatLab风格,即前述的F样式)来保存元素。
0.4.1 python array和list区别
Python中的列表(list)和数组(array)主要有以下区别:
- 数据类型:列表可以包含不同类型的数据,如数字、字符串、其他列表等,而数组通常用于存储单一数据类型的元素。在Python的标准库中,数组是数值型数据的集合,而列表是更通用的数据结构。
- 创建方式:列表是Python的内置数据类型,可以直接使用方括号创建,如a = 。而数组通常需要导入标准库(如NumPy)才能使用,例如import numpy as np后,可以使用np.array()函数创建数组。
- 运算支持:列表不支持数学四则运算。而数组支持数学四则运算,特别适用于科学计算和需要高效数值处理的场景。
- 性能和优化:列表对于一般用途进行了优化,适合存储不同类型的元素,并提供了广泛的内置方法,如append()、remove()、insert()等。数组对数值计算进行了优化,通常在进行大规模数值运算时性能更好,但不像列表那样有丰富的内置方法。数组支持与数值数据相关的额外操作,如数组类型转换。
- 内存占用:列表中的每个元素都是一个独立的Python对象,相对占用更多的内存。而数组占用的内存更少,因为它们仅存储数值数据,并以更紧凑的方式存储。
- 用途:列表适用于多种数据类型和灵活的数据集合操作。数组更适用于进行科学计算或其他需要高效数值处理的任务。在Python中,当你需要高效的数值运算并且所有元素类型都相同时,可以选择使用array。而在需要存储不同类型的数据或者不需要高效数值运算时,使用list会更加灵活。
综上所述,列表和数组在Python中各有特点和应用场景,选择使用哪种数据结构取决于具体的需求和上下文。
实例1:
import numpy as np
L1 = [1, 2, 3.14, 4]
arr = np.array( (1, 2, ‘3.14’, 4) )
print(L1) # 列表可以存储任意的数据类型
print(arr)
输出结果如下:
[1, 2, 3.14, 4]
[‘1’ ‘2’ ‘3.14’ ‘4’]
实例2:
import numpy as np
L1=[11,22,33,44]
L2=[100,200,300,400]
L1+L2 #列表之间用"+"只能拼接,而不能相加
输出结果如下:
[11, 22, 33, 44, 100, 200, 300, 400]
实例3.
如果同一个变量名重复出现,则以最后一个数组输入的值为输出值,之前输入的不再输出
arr2=np.array(L1)
arr2
输出结果如下:
array([11, 22, 33, 44])arr3=np.array(L2)
arr3
输出结果如下:
array([100, 200, 300, 400])
列表不支持数学四则运算,而数组支持数学四则运算arr2+arr3
输出结果如下:array([111, 222, 333, 444]) # 数组支持四则运算
arr2*arr3
输出结果如下:array([ 1100, 4400, 9900, 17600])
arr2/arr3
输出结果如下:
array([0.11, 0.11, 0.11, 0.11])
list与ndarry加法示例:
list与ndarry乘法示例


0.5 NumPy 创建数组
ndarray 数组除了可以使用底层 ndarray 构造器来创建外,也可以通过以下几种方式来创建。
0.5.1 创建相同值的数组
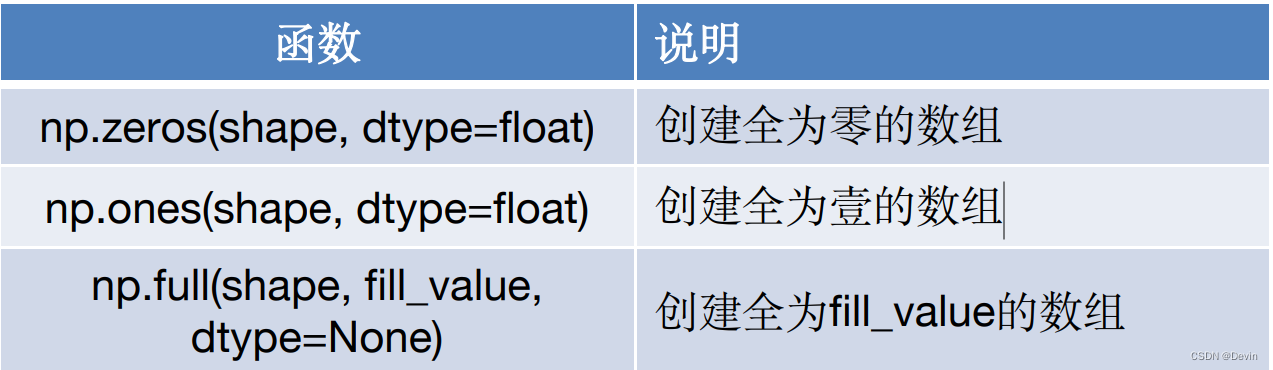
函数:
numpy.zeros_like(a, dtype=None, order=‘K’, subok=True, shape=None)
numpy.ones_like(a, dtype=None, order=‘K’, subok=True, shape=None)
• 参数
– shape: 指定形状,整数或者整数序列
– dtype: 数据类型
1.1 创建指定大小的数组,数组元素以 0 来填充:
numpy.zeros(shape, dtype = float, order = ‘C’)
import numpy as np
默认为浮点数
x = np.zeros(5)
print(x)
设置类型为整数
y = np.zeros((5,), dtype = int)
print(y)
自定义类型
z = np.zeros((2,2), dtype = [(‘x’, ‘i4’), (‘y’, ‘i4’)])
print(z)
输出结果为:
[0. 0. 0. 0. 0.]
[0 0 0 0 0]
[[(0, 0) (0, 0)]
[(0, 0) (0, 0)]]
1.2 np.zeros(10,dtype=int)
输出结果为:
array([0, 0, 0, 0, 0, 0, 0, 0, 0, 0])
np.zeros((2,5),dtype=int)
输出结果为:
array([[0, 0, 0, 0, 0],
[0, 0, 0, 0, 0]])
np.zeros((2,3,4),dtype=int)
输出结果为:
array([[[0, 0, 0, 0],
[0, 0, 0, 0],
[0, 0, 0, 0]],
[[0, 0, 0, 0],
[0, 0, 0, 0],
[0, 0, 0, 0]]])
注:. numpy.zeros_like
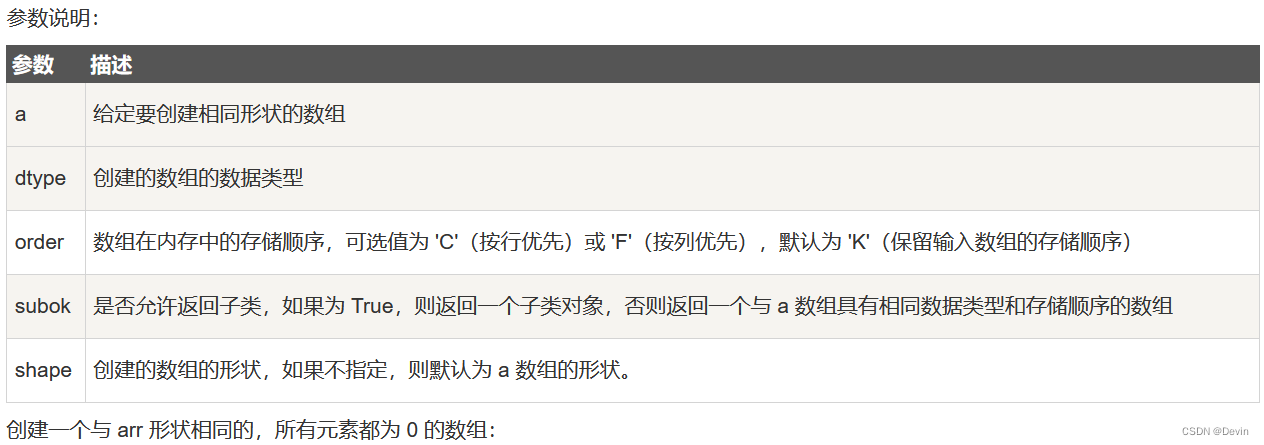
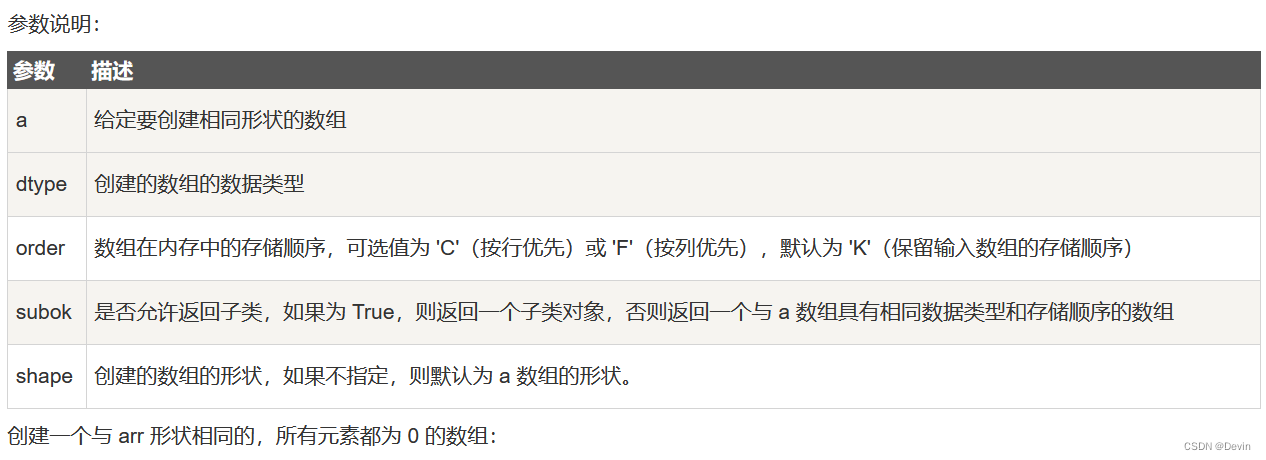
*numpy.zeros_like 用于创建一个与给定数组具有相同形状的数组,数组元素以 0 来填充。
numpy.zeros 和 numpy.zeros_like 都是用于创建一个指定形状的数组,其中所有元素都是 0。
它们之间的区别在于:numpy.zeros 可以直接指定要创建的数组的形状,而 numpy.zeros_like 则是创建一个与给定数组具有相同形状的数组。
numpy.zeros_like(a, dtype=None, order=‘K’, subok=True, shape=None)
import numpy as np
创建一个 3x3 的二维数组
arr = np.array([[1, 2, 3], [4, 5, 6], [7, 8, 9]])
创建一个与 arr 形状相同的,所有元素都为 0 的数组
zeros_arr = np.zeros_like(arr)
print(zeros_arr)
输出结果为:
[[0 0 0]
[0 0 0]
[0 0 0]]
2.1 创建指定形状的数组,数组元素以 1 来填充: numpy.ones(shape, dtype = None, order = ‘C’)
import numpy as np
默认为浮点数
x = np.ones(5)
print(x)
自定义类型
x = np.ones([2,2], dtype = int)
print(x)
输出结果为:
[1. 1. 1. 1. 1.]
[[1 1]
[1 1]]
2.2 使用numpy.ones() 函数,创建全为1的一维数组
np.ones(10)
输出结果为:
array([1., 1., 1., 1., 1., 1., 1., 1., 1., 1.])
创建 2行 5列的二维数组,值是全为 0 的整数
np.ones((2,5),dtype=int)
输出结果为:
array([[1, 1, 1, 1, 1],
[1, 1, 1, 1, 1]])
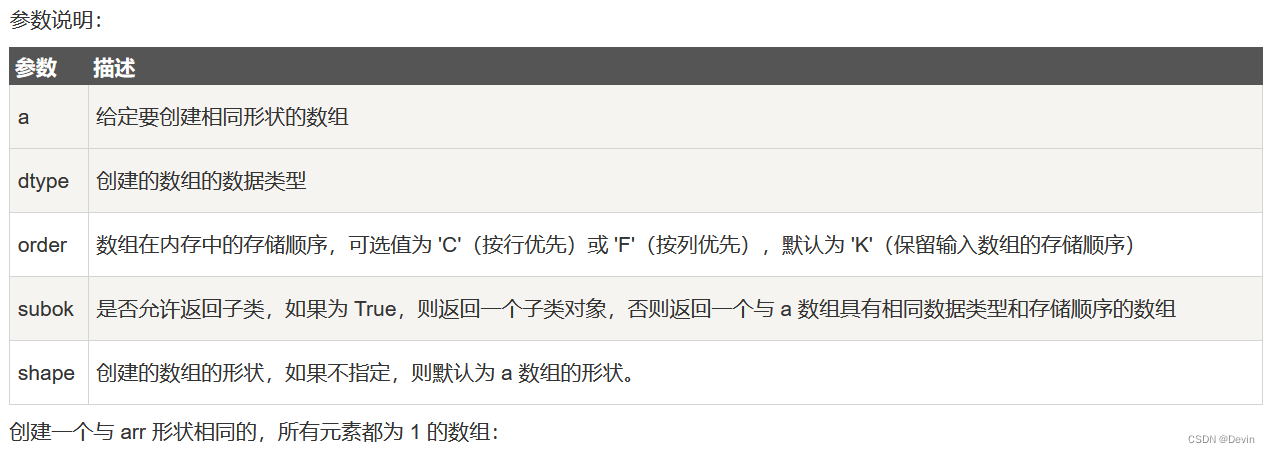
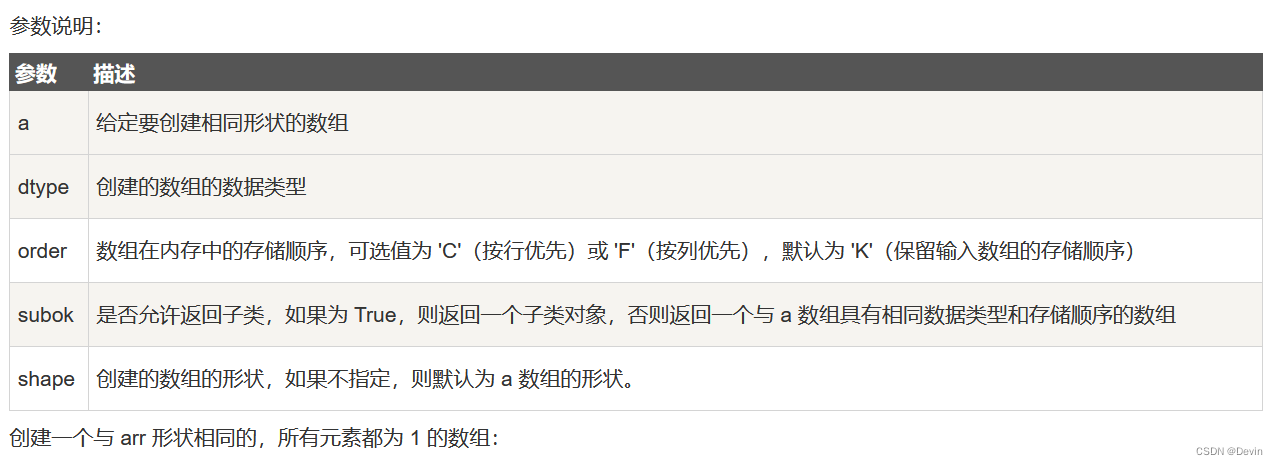
*numpy.ones_like
numpy.ones_like 用于创建一个与给定数组具有相同形状的数组,数组元素以 1 来填充。
numpy.ones 和 numpy.ones_like 都是用于创建一个指定形状的数组,其中所有元素都是 1。
它们之间的区别在于:numpy.ones 可以直接指定要创建的数组的形状,而 numpy.ones_like 则是创建一个与给定数组具有相同形状的数组。
import numpy as np
创建一个 3x3 的二维数组
arr = np.array([[1, 2, 3], [4, 5, 6], [7, 8, 9]])
创建一个与 arr 形状相同的,所有元素都为 1 的数组
ones_arr = np.ones_like(arr)
print(ones_arr)
输出结果为:
[[1 1 1]
[1 1 1]
[1 1 1]]
3.1创建全为fill_value的数组
创建 2行 5列的二维数组,值是全为 5 的整数
np.full((2,5),5,dtype=int)
输出结果为:
array([[5, 5, 5, 5, 5],
[5, 5, 5, 5, 5]])
0.5.2 根据已有数据创建相同维度的数组
函数:
参数
– object: 一个数组或形状类似数组的结构,如列表等
– dtype: 数据类型
L5=([100,200,300],[400,500,600])
arr5=np.array(L5)
arr5
输出结果为:
array([[100, 200, 300],
[400, 500, 600]])

0.5.2 创建等差数列的一维数组
- numpy 包中的使用 arange 函数创建数值范围并返回 ndarray 对象,函数格式如下:
numpy.arange(start, stop, step, dtype)
实例1:
import numpy as np
x = np.arange(5)
print (x)
输出结果如下:
[0 1 2 3 4]
实例2:
设置返回类型位 float:
import numpy as np
设置了 dtype
x = np.arange(5, dtype = float)
print (x)
输出结果如下:
[0. 1. 2. 3. 4.]
实例3:
import numpy as np
x = np.arange(10,20,2)
print (x)
输出结果如下:
[10 12 14 16 18]- numpy.linspace
numpy.linspace 函数用于创建一个一维数组,数组是一个等差数列构成的,格式如下:
np.linspace(start, stop, num=50, endpoint=True, retstep=False, dtype=None)
实例1:
import numpy as np
a = np.linspace(1,10,10)
print(a)
输出结果为:
[ 1. 2. 3. 4. 5. 6. 7. 8. 9. 10.]
实例2:
将 endpoint 设为 false,不包含终止值:
import numpy as np
a = np.linspace(10, 20, 5, endpoint = False)
print(a)
输出结果为:
[10. 12. 14. 16. 18.]
实例3:
如果将 endpoint 设为 true,则会包含 10。
以下实例设置间距。
import numpy as np
a =np.linspace(1,10,10,retstep= True)
print(a)
拓展例子
b =np.linspace(1,10,10).reshape([10,1])
print(b)
输出结果为:
(array([ 1., 2., 3., 4., 5., 6., 7., 8., 9., 10.]), 1.0)
[[ 1.]
[ 2.]
[ 3.]
[ 4.]
[ 5.]
[ 6.]
[ 7.]
[ 8.]
[ 9.]
[10.]]
3. numpy.logspace
numpy.logspace 函数用于创建一个于等比数列。格式如下:
np.logspace(start, stop, num=50, endpoint=True, base=10.0, dtype=None)
实例1:
import numpy as np
默认底数是 10
a = np.logspace(1.0, 2.0, num = 10)
print (a)
输出结果为:
[ 10. 12.91549665 16.68100537 21.5443469 27.82559402
35.93813664 46.41588834 59.94842503 77.42636827 100. ]
实例2:
将对数的底数设置为 2 :
import numpy as np
a = np.logspace(0,9,10,base=2)
print (a)
输出结果为:
[ 1. 2. 4. 8. 16. 32. 64. 128. 256. 512.]
0.5.3 数据类型对象 (dtype)
type(“hello”)
输出结果为:
str
0.5.4 用随机函数创建数组
Python中用于生成随机数的主要库是random。以下是一些常用的随机函数及其使用示
例:
- random.random():返回0到1之间的随机浮点数。
import random
print(random.random()) # 输出类似于 0.3290365574660254
注:若设定特定的随机种子值(即:seed),则多次运行后产生的随机数是一致的;不设置随机种子seed,则多次运行后产生的随机数是不同的。- 生成10 个均匀分布的 0 ~ 1 之间的随机小数
np.random.rand(10)
输出结果为:
array([0.85369998, 0.25445758, 0.82786031, 0.49905511, 0.25214636,
0.60636842, 0.77064648, 0.55058426, 0.18577198, 0.3595078 ])- 生成 10 期望值 u 为 0,标准差为1的十个 正态分布的小数
np.random.randn(10)
输出结果为:
array([-3.43323405e-04, 3.32578014e-01, 2.28620543e-01, -7.99316885e-01,
3.00933059e+00, 8.31727251e-01, -6.51723579e-01, 5.71336440e-01,
3.05262711e-01, 4.26792578e-01])
生成 10 期望值 u 为 0,标准差为1的 2行5列 正态分布的小数
np.random.randn(2,5)
输出结果为:
array([[-1.8159595 , -0.22650128, -0.34401613, 0.19192179, 2.12796067],
[ 0.87400168, -0.33826335, -0.3707549 , -0.65123947, -0.51558185]])- 生成 模拟8次掷骰子的结果
np.random.randint(1,7,8)
输出结果为:
array([6, 5, 6, 2, 5, 4, 2, 1])
生成 5 ~ 10 范围内均匀分布的8个随机小数
np.random.uniform(5,10,8)
输出结果为:
array([7.70652673, 6.55819735, 7.04376205, 7.82413751, 9.86539273,
8.86520164, 5.09117129, 5.20055258])- 模拟生成 10 个人的身高,期望值u是173厘米,标准差是5
np.random.normal(173,5,10)
输出结果为:
array([167.57184698, 177.98672723, 174.41489249, 165.46852643,
170.10699874, 181.25718269, 160.86660378, 170.85543686,
179.32968129, 168.66629799])
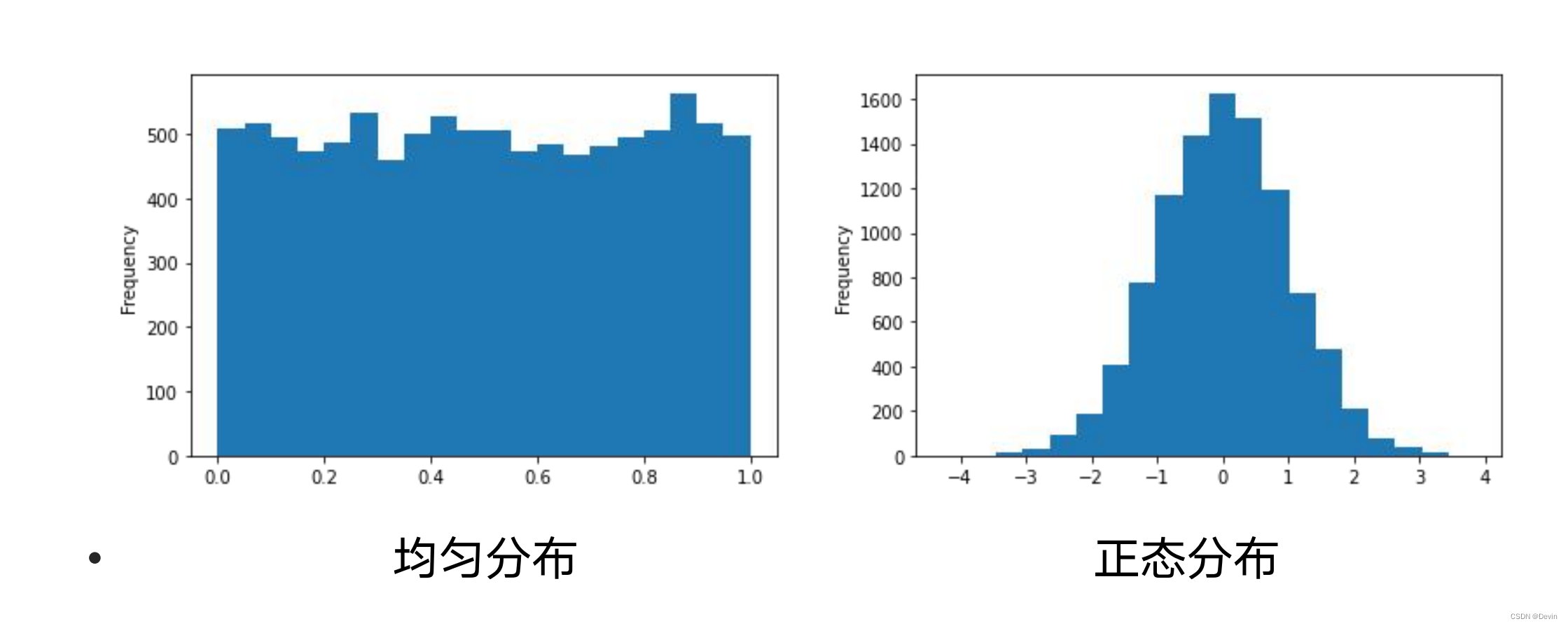
均匀分布和正态分布:
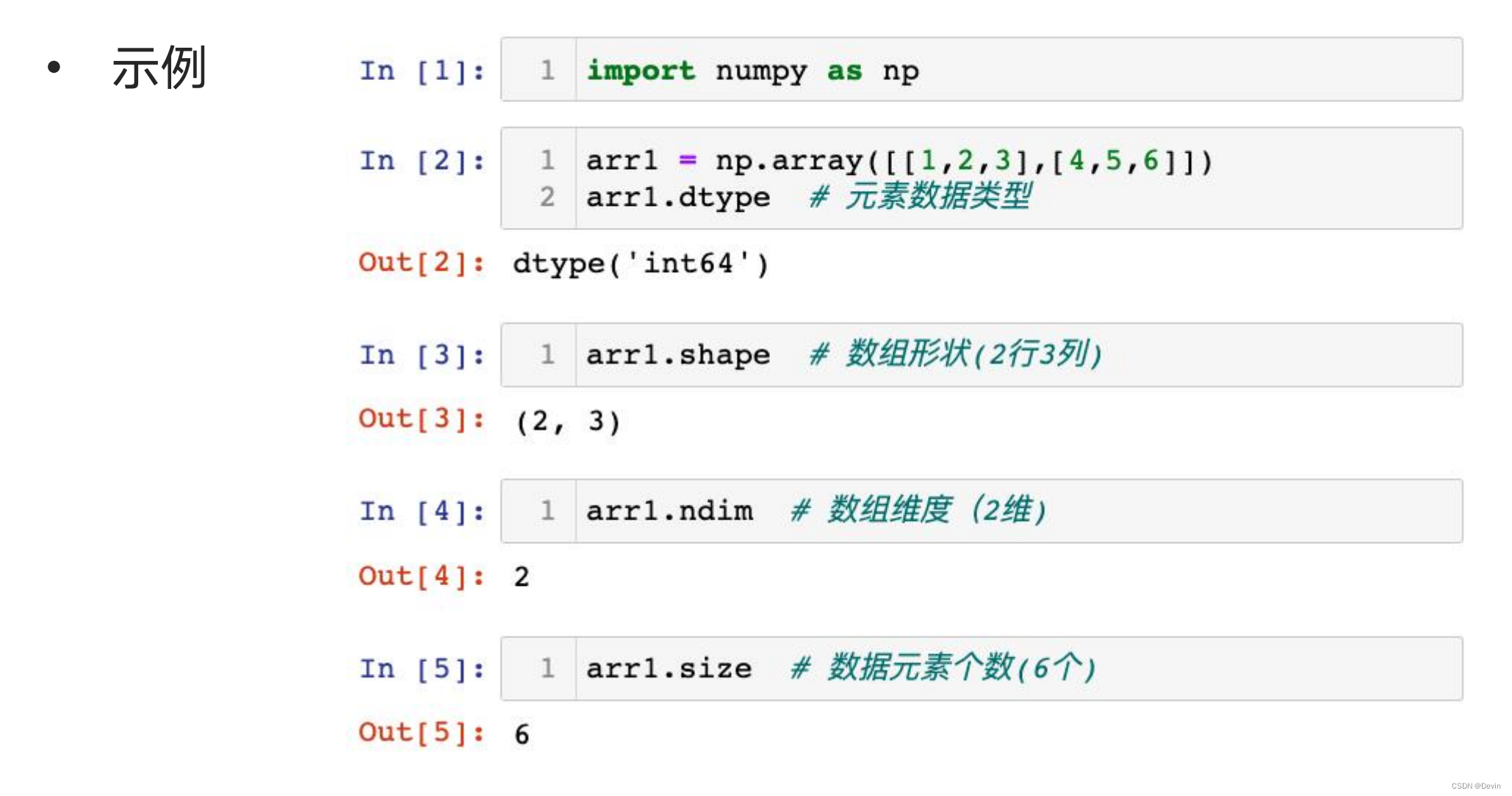
0.5.5 ndarray数组属性
ndarray.dtype 元素类型
ndarray.ndim 数组维度
ndarray.shape 数组形状
ndarray.size 元素个数 等价于 len(list)
ndarray数组属性示例:
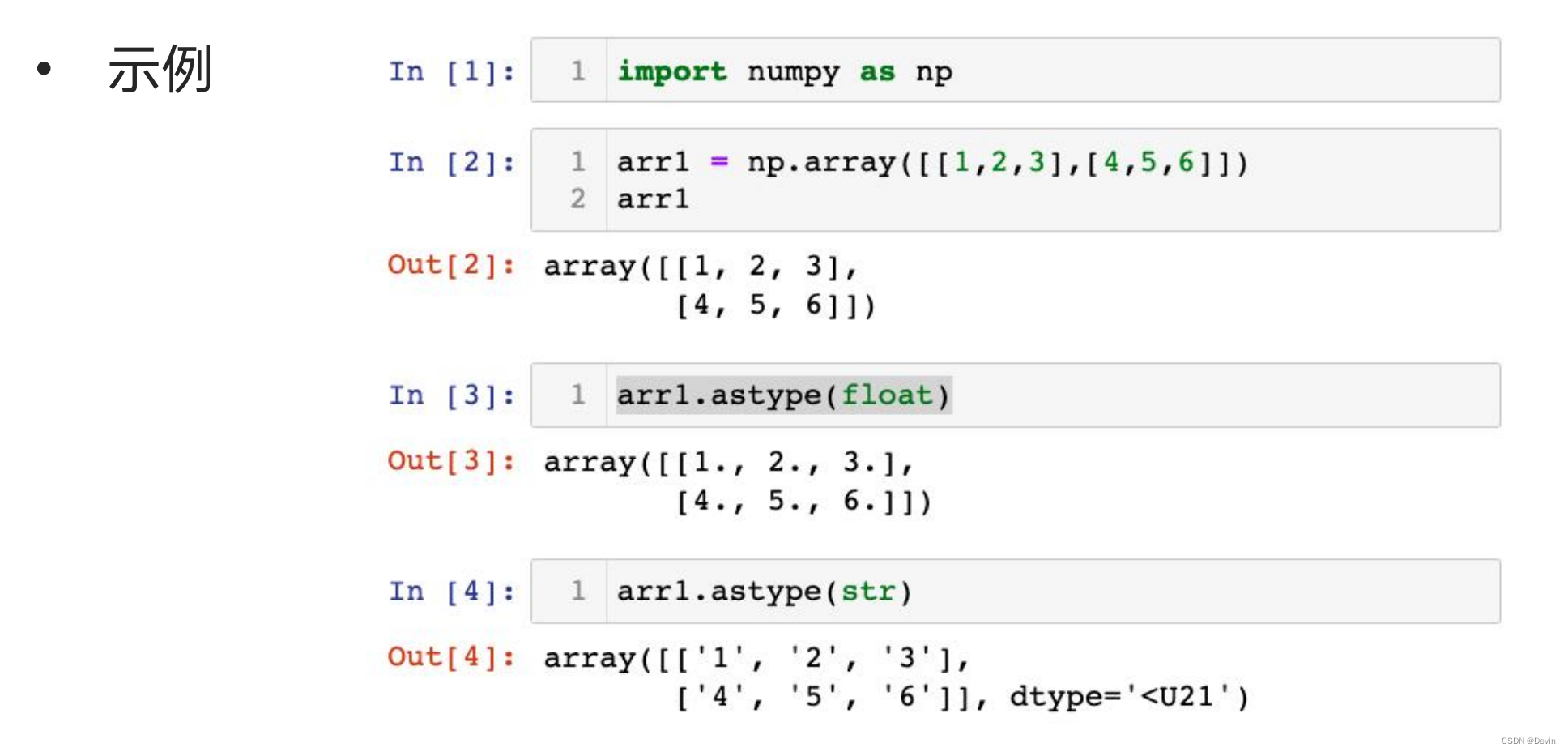
0.5.6 修改数组类型

修改数组类型示例
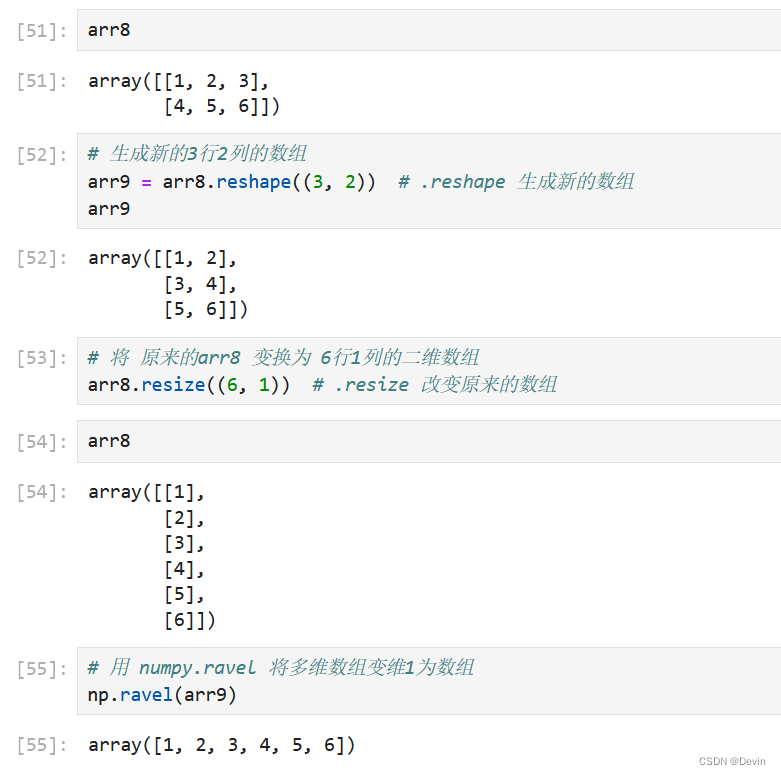
0.5.7 修改数组维度
arr.reshape(shape) 生成新形状的数组并返回
arr.resize(shape) 不复制,改变当前数组形状
numpy.ravel(ndarray) 展开数组,变成1维数组
参数
– shape: 指定形状,整数或者整数序列
– ndarray: ndarray 数组
0.5.8 ndarray的运算

数组对应位置可以互相进行四则运算
运算符:+ - * / // % **
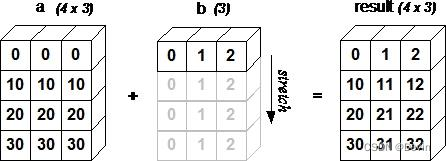
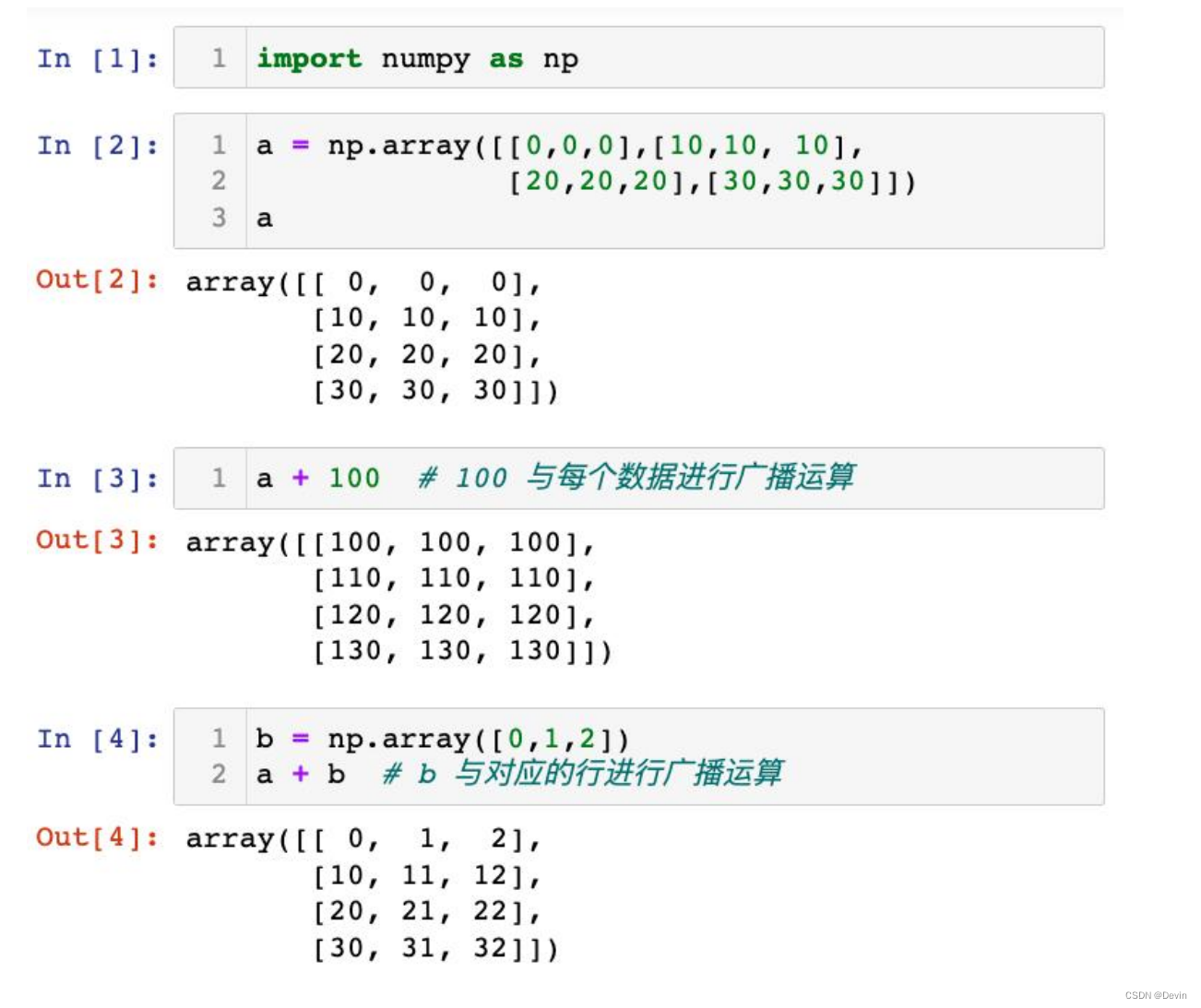
0.5.9 ndarray的广播运算
当一个数组a与另外一个数组b 的维度不相同时。默认进行广播运算
(broadcast)
0.5.10 ndarray的索引和切片运算
• ndarray对象的内容可以通过索引或切片来访问和修改,用法与Python
中 列表list 的索引和切片操作一样。
• 对于二维或者多维数组,索引和切片可以写在一个中括号内来一次性完
成。
• 语法
一维数组[索引或切片]
二维数组[第一个维度(行)索引或切片, 第二个维度(列)索引或切片]
三维数组[第一个维度(页), 第二个维度(行), 第三个维度(列)]
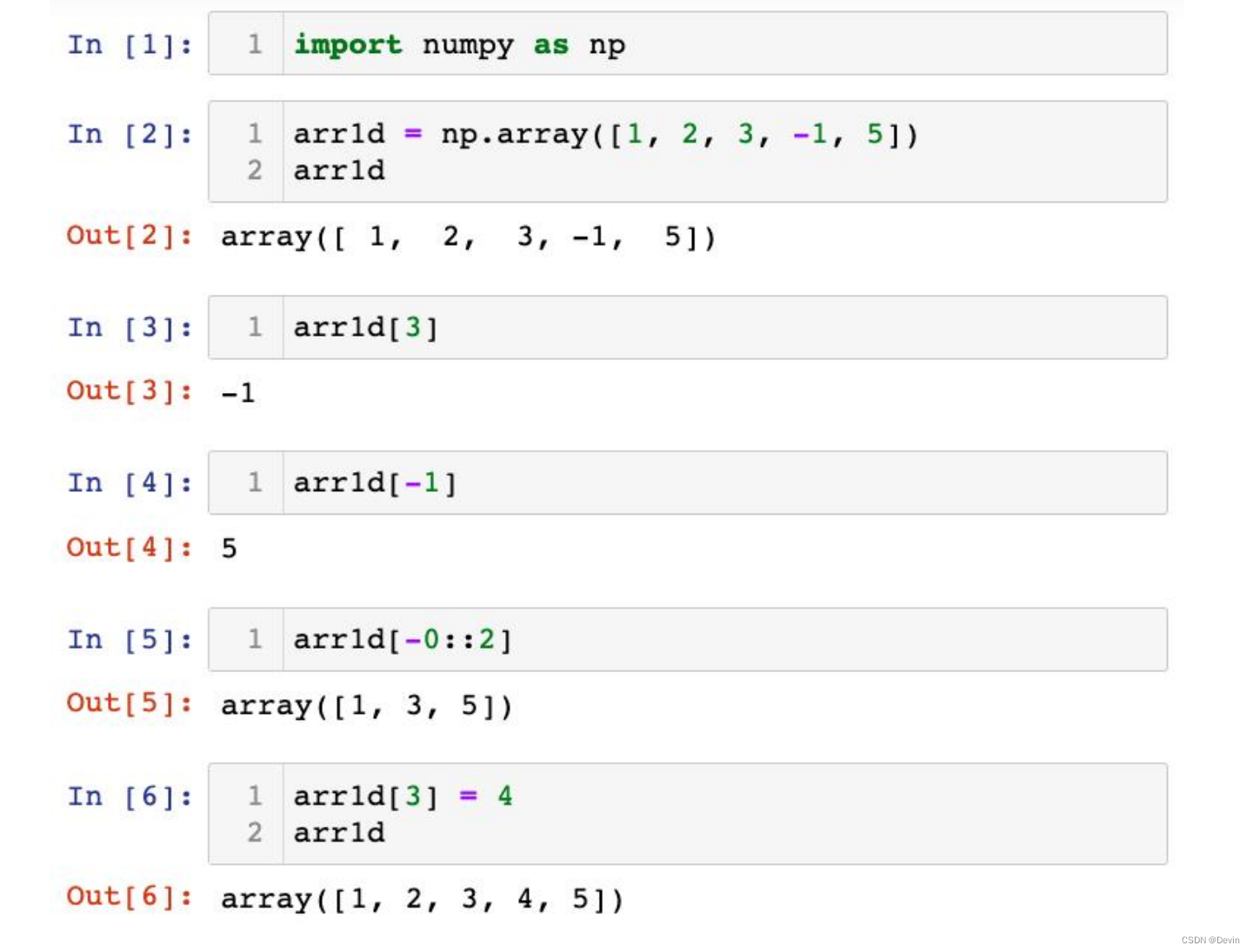
0.5.10.1一维数组的索引和切片示例:
实例:
import numpy as np
a = np.arange(10)
s = slice(2,7,2) # 从索引 2 开始到索引 7 停止,间隔为2
print (a[s])
输出结果为:
[2 4 6]
以上实例中,我们首先通过 arange() 函数创建 ndarray 对象。 然后,分别设置起始,终止和步长的参数为 2,7 和 2。
我们也可以通过冒号分隔切片参数 start:stop:step 来进行切片操作:
import numpy as np
a = np.arange(10)
b = a[2:7:2] # 从索引 2 开始到索引 7 停止,间隔为 2
print(b)
输出结果为:
[2 4 6]
0.5.10.2 二维数组的索引和切片示例

0.5.11 NumPy 高级索引
整数数组索引
整数数组索引是指使用一个数组来访问另一个数组的元素。这个数组中的每个元素都是目标数组中某个维度上的索引值。
以下实例获取数组中 (0,0),(1,1) 和 (2,0) 位置处的元素。
实例
import numpy as np
x = np.array([[1, 2], [3, 4], [5, 6]])
y = x[[0,1,2], [0,1,0]]
print (y)
输出结果为:
[1 4 5]
以下实例获取了 4X3 数组中的四个角的元素。 行索引是 [0,0] 和 [3,3],而列索引是 [0,2] 和 [0,2]。
import numpy as np
x = np.array([[ 0, 1, 2],[ 3, 4, 5],[ 6, 7, 8],[ 9, 10, 11]])
print (‘我们的数组是:’ )
print (x)
print (‘\n’)
rows = np.array([[0,0],[3,3]])
cols = np.array([[0,2],[0,2]])
y = x[rows,cols]
print (‘这个数组的四个角元素是:’)
print (y)
输出结果为:
我们的数组是:
[[ 0 1 2]
[ 3 4 5]
[ 6 7 8]
[ 9 10 11]]
这个数组的四个角元素是:
[[ 0 2]
[ 9 11]]
返回的结果是包含每个角元素的 ndarray 对象。
可以借助切片 : 或 … 与索引数组组合。如下面例子:
实例
import numpy as np
a = np.array([[1,2,3], [4,5,6],[7,8,9]])
b = a[1:3, 1:3]
c = a[1:3,[1,2]]
d = a[…,1:]
print(b)
print©
print(d)
输出结果为:
[[5 6]
[8 9]]
[[5 6]
[8 9]]
[[2 3]
[5 6]
[8 9]]
布尔索引
我们可以通过一个布尔数组来索引目标数组。
布尔索引通过布尔运算(如:比较运算符)来获取符合指定条件的元素的数组。
以下实例获取大于 5 的元素:
实例
import numpy as np
x = np.array([[ 0, 1, 2],[ 3, 4, 5],[ 6, 7, 8],[ 9, 10, 11]])
print (‘我们的数组是:’)
print (x)
print (‘\n’)
现在我们会打印出大于 5 的元素
print (‘大于 5 的元素是:’)
print (x[x > 5])
输出结果为:
我们的数组是:
[[ 0 1 2]
[ 3 4 5]
[ 6 7 8]
[ 9 10 11]]
大于 5 的元素是:
[ 6 7 8 9 10 11]
以下实例使用了 ~(取补运算符)来过滤 NaN。
实例
import numpy as np
a = np.array([np.nan, 1,2,np.nan,3,4,5])
print (a[~np.isnan(a)])
输出结果为:
[ 1. 2. 3. 4. 5.]
以下实例演示如何从数组中过滤掉非复数元素。
实例
import numpy as np
a = np.array([1, 2+6j, 5, 3.5+5j])
print (a[np.iscomplex(a)])
输出结果为:
[2.0+6.j 3.5+5.j]
花式索引
花式索引指的是利用整数数组进行索引。
花式索引根据索引数组的值作为目标数组的某个轴的下标来取值。
对于使用一维整型数组作为索引,如果目标是一维数组,那么索引的结果就是对应位置的元素,如果目标是二维数组,那么就是对应下标的行。
花式索引跟切片不一样,它总是将数据复制到新数组中。
一维数组
一维数组只有一个轴 axis = 0,所以一维数组就在 axis = 0 这个轴上取值:
实例
import numpy as np
x = np.arange(9)
print(x)
#一维数组读取指定下标对应的元素
print(“-------读取下标对应的元素-------”)
x2 = x[[0, 6]] # 使用花式索引
print(x2)
print(x2[0])
print(x2[1])
输出结果为:
[0 1 2 3 4 5 6 7 8]
-------读取下标对应的元素-------
[0 6]
0
6
二维数组
1、传入顺序索引数组
实例
import numpy as np
x=np.arange(32).reshape((8,4))
print(x)
#二维数组读取指定下标对应的行
print(“-------读取下标对应的行-------”)
print (x[[4,2,1,7]])
print (x[[4,2,1,7]]) 输出下表为 4, 2, 1, 7 对应的行,输出结果为:
[[ 0 1 2 3]
[ 4 5 6 7]
[ 8 9 10 11]
[12 13 14 15]
[16 17 18 19]
[20 21 22 23]
[24 25 26 27]
[28 29 30 31]]
-------读取下标对应的行-------
[[16 17 18 19]
[ 8 9 10 11]
[ 4 5 6 7]
[28 29 30 31]]
传入倒序索引数组
实例
import numpy as np
x=np.arange(32).reshape((8,4))
print (x[[-4,-2,-1,-7]])
输出结果为:
[[16 17 18 19]
[24 25 26 27]
[28 29 30 31]
[ 4 5 6 7]]
3、传入多个索引数组(要使用 np.ix_)
np.ix_ 函数就是输入两个数组,产生笛卡尔积的映射关系。
笛卡尔乘积是指在数学中,两个集合 X 和 Y 的笛卡尔积(Cartesian product),又称直积,表示为 X×Y,第一个对象是X的成员而第二个对象是 Y 的所有可能有序对的其中一个成员。
例如 A={a,b}, B={0,1,2},则:
A×B={(a, 0), (a, 1), (a, 2), (b, 0), (b, 1), (b, 2)}
B×A={(0, a), (0, b), (1, a), (1, b), (2, a), (2, b)}
实例
import numpy as np
x=np.arange(32).reshape((8,4))
print (x[np.ix_([1,5,7,2],[0,3,1,2])])
输出结果为:
[[ 4 7 5 6]
[20 23 21 22]
[28 31 29 30]
[ 8 11 9 10]]
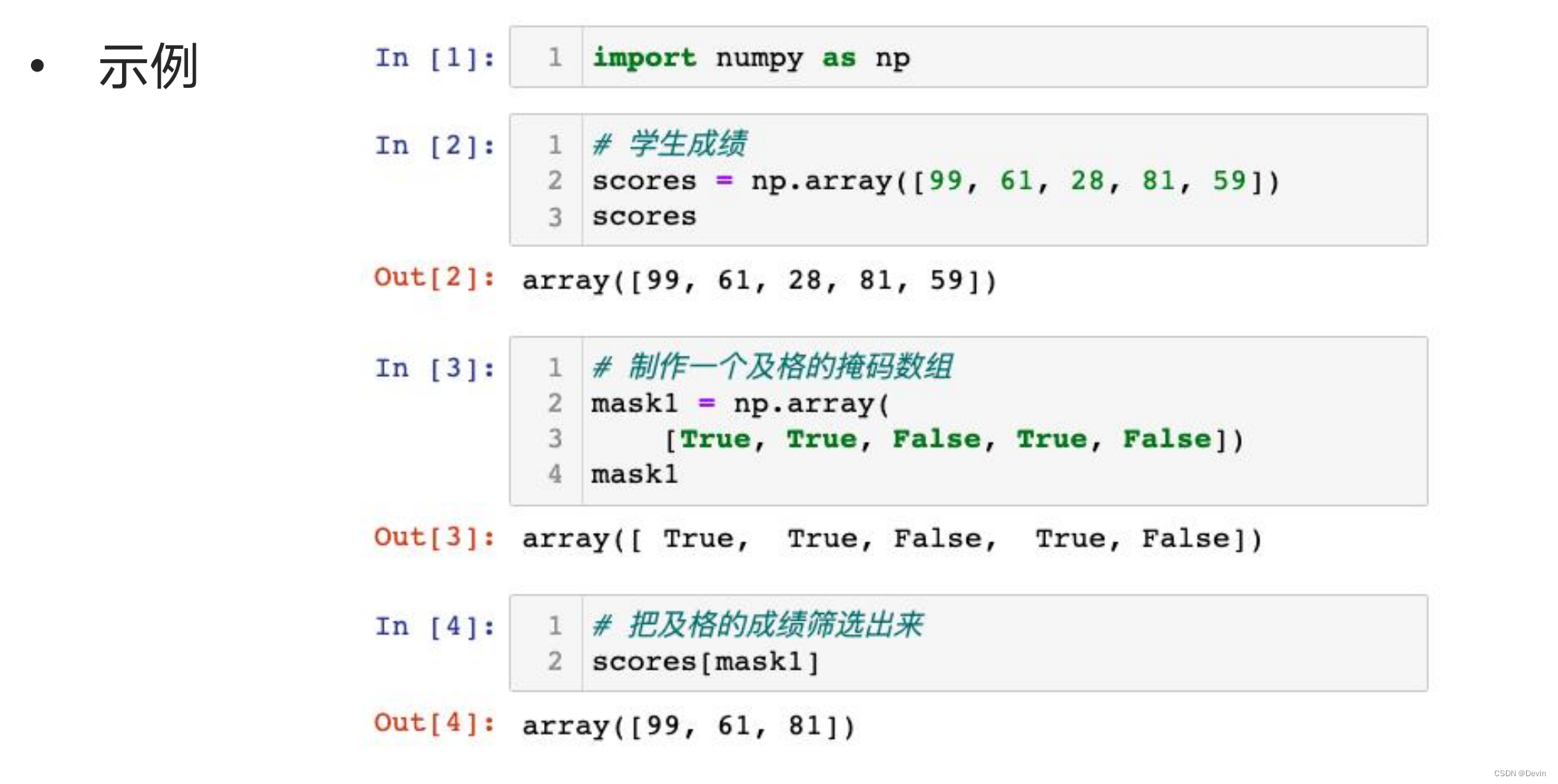
0.5.12 ndarray的掩码数组
什么是掩码数组:
• 在许多情况下,数据集可能存在不完整或无效数据,numpy引入掩码数
组提供标记数据的方法,此方法在一个数组内使用True/False类型的数
据可以标记数据是否有效。
• 使用数组掩码可以快速的对数据进行筛选和修改。
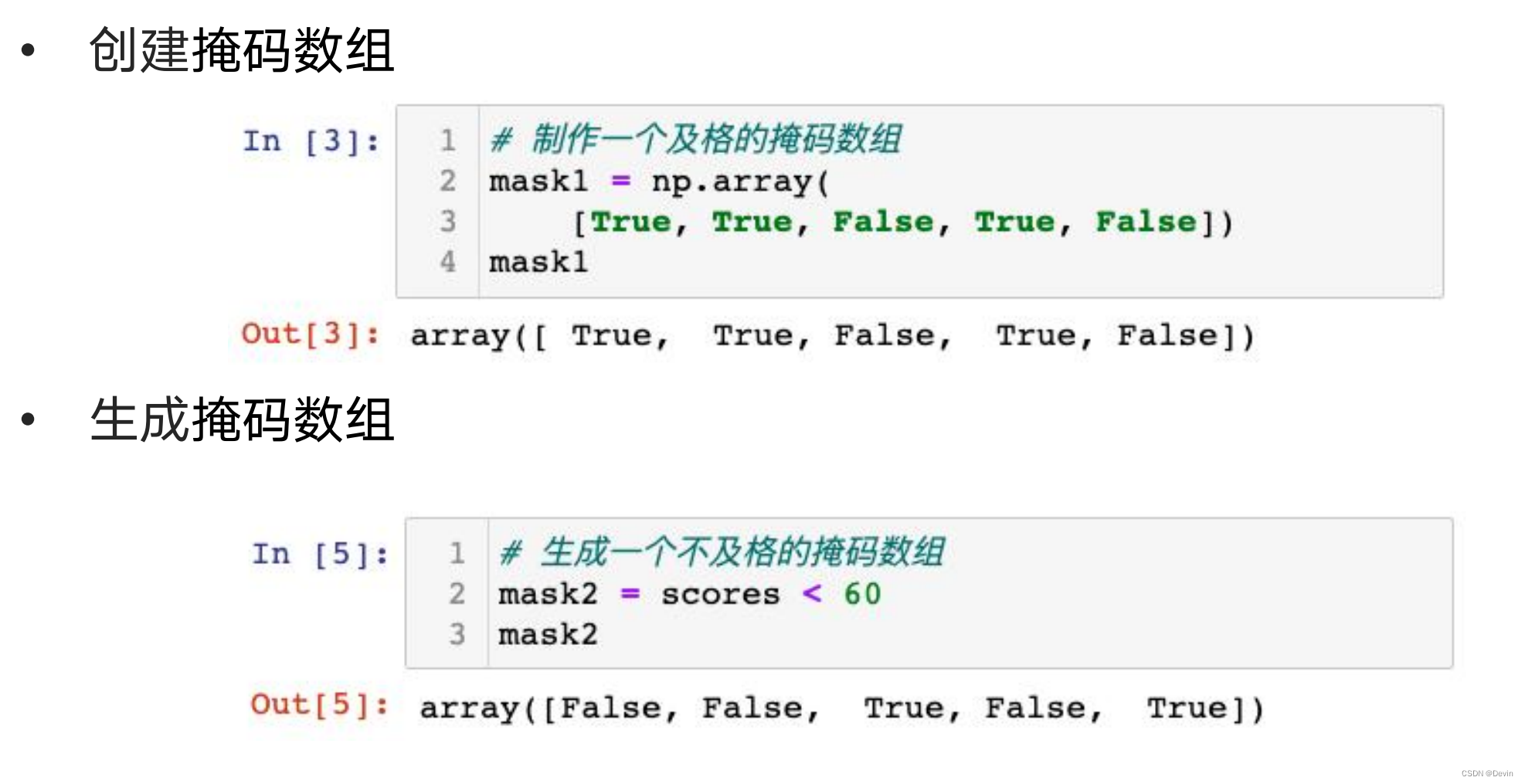
ndarray的掩码数组示例
ndarray的掩码数组的生成
0.5.12.1ndarray的掩码数组的布尔运算
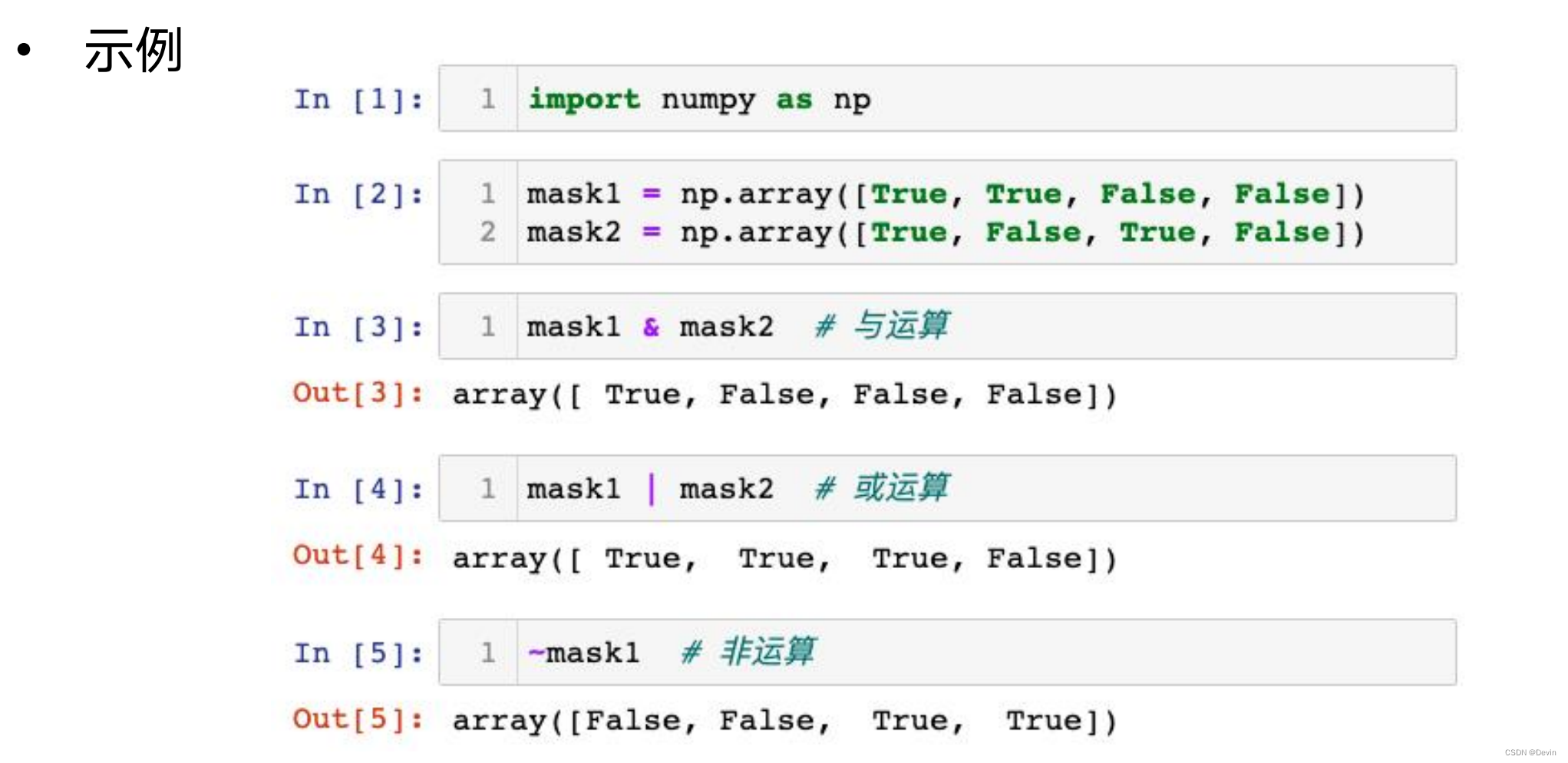
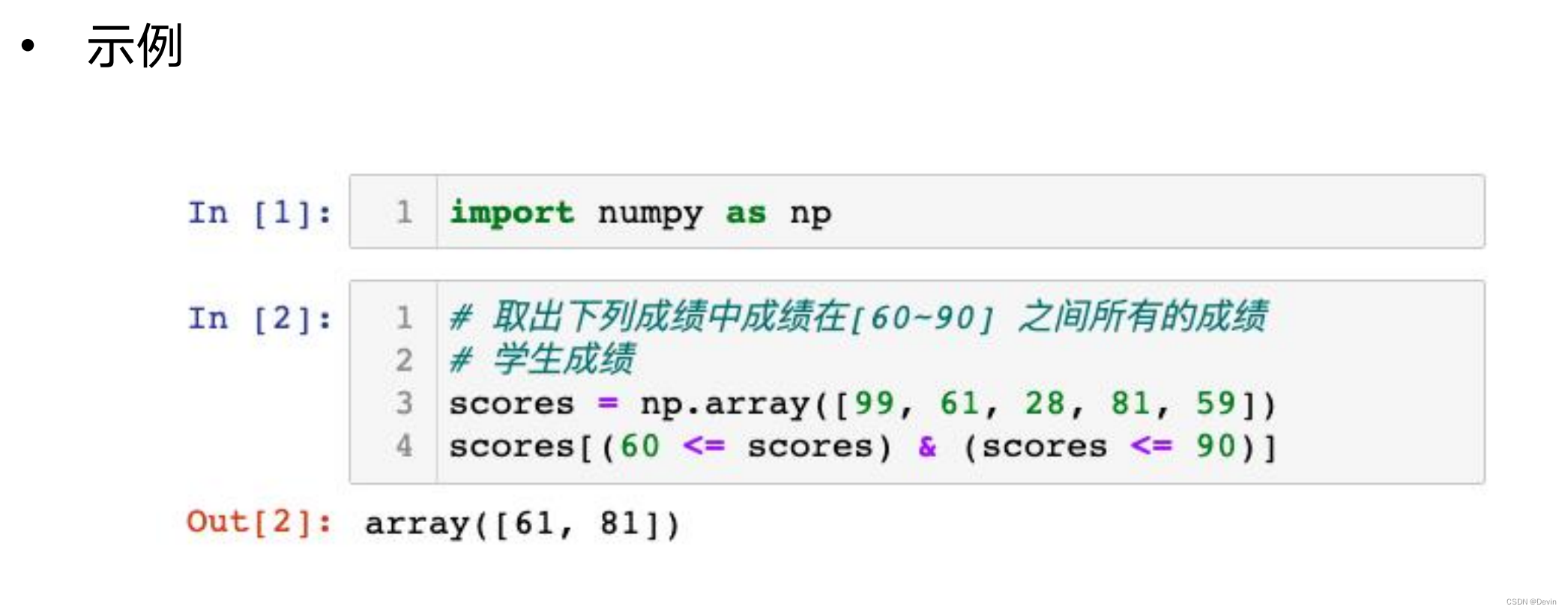
ndarray的掩码数组的布尔运算示例1
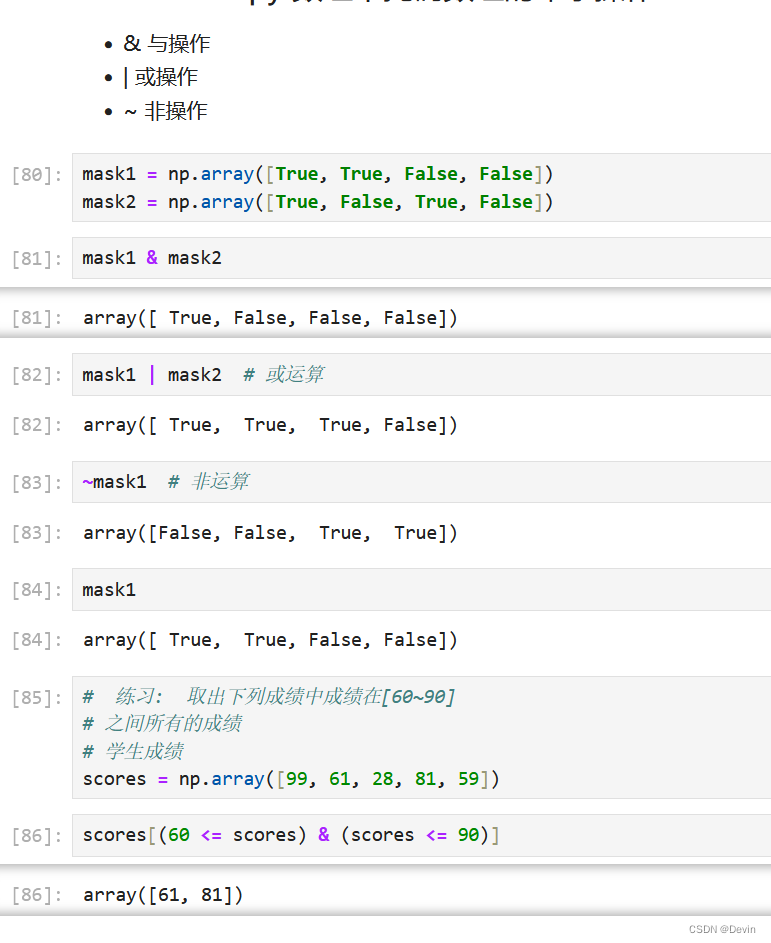
ndarray的掩码数组的布尔运算示例2
0.6 Numpy常用函数
0.6.1算数函数
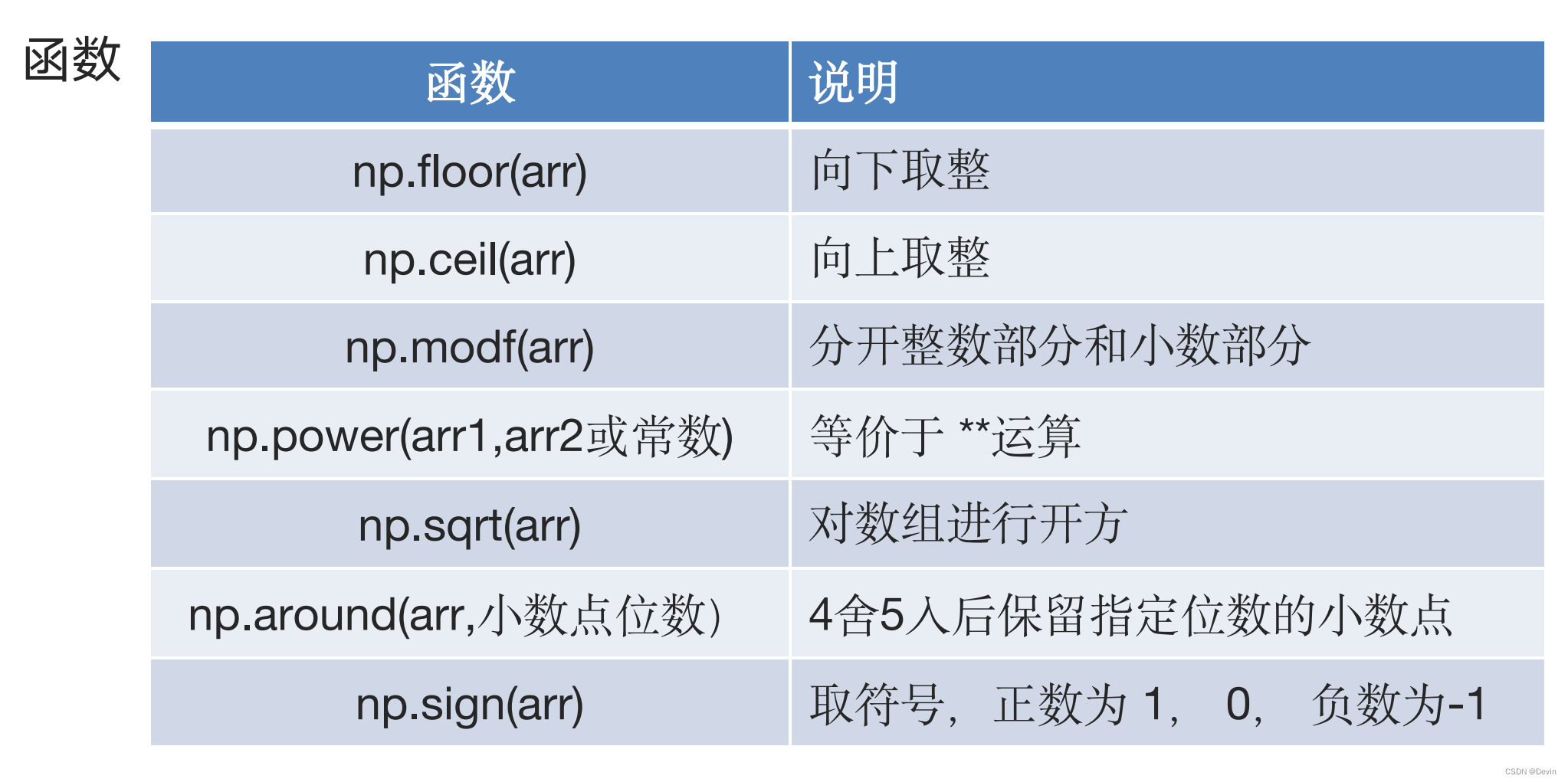
算数函数示例1

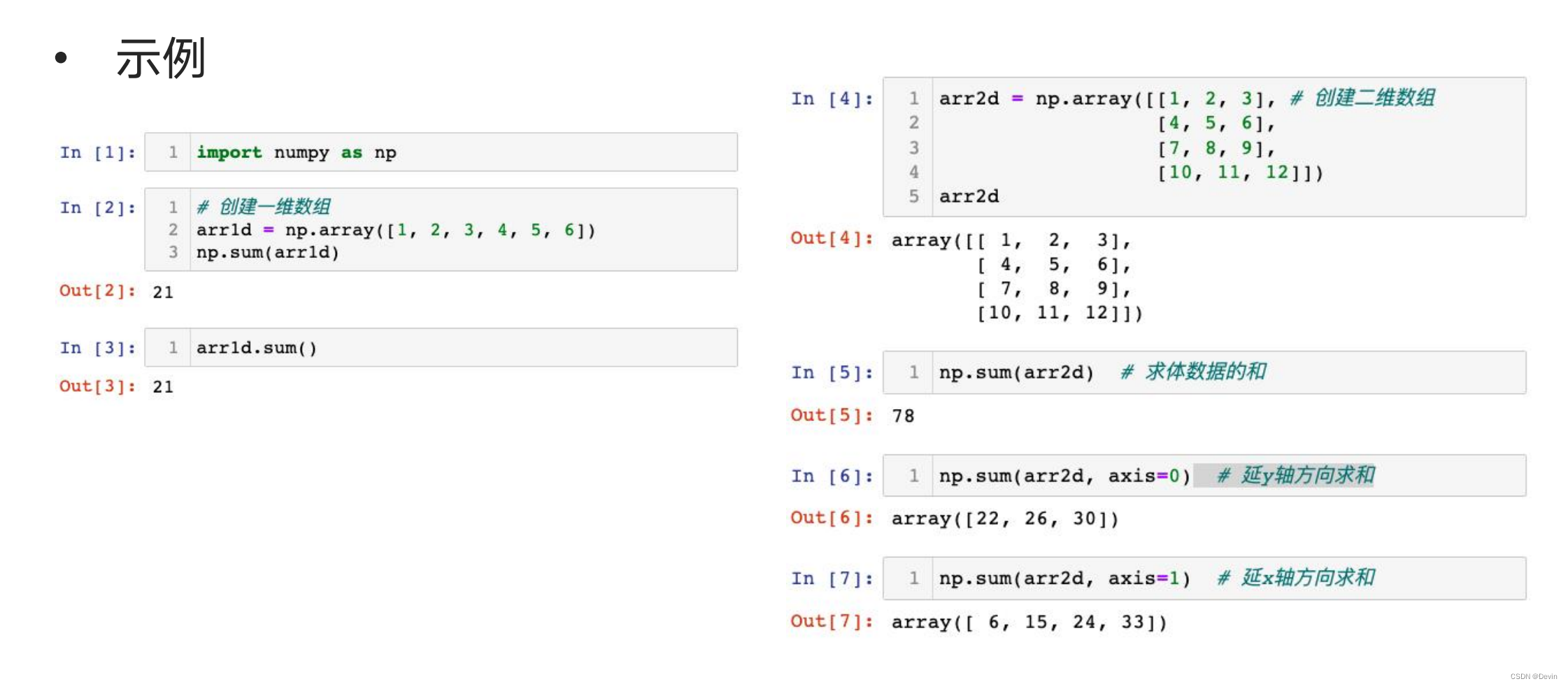
0.6.2 统计函数
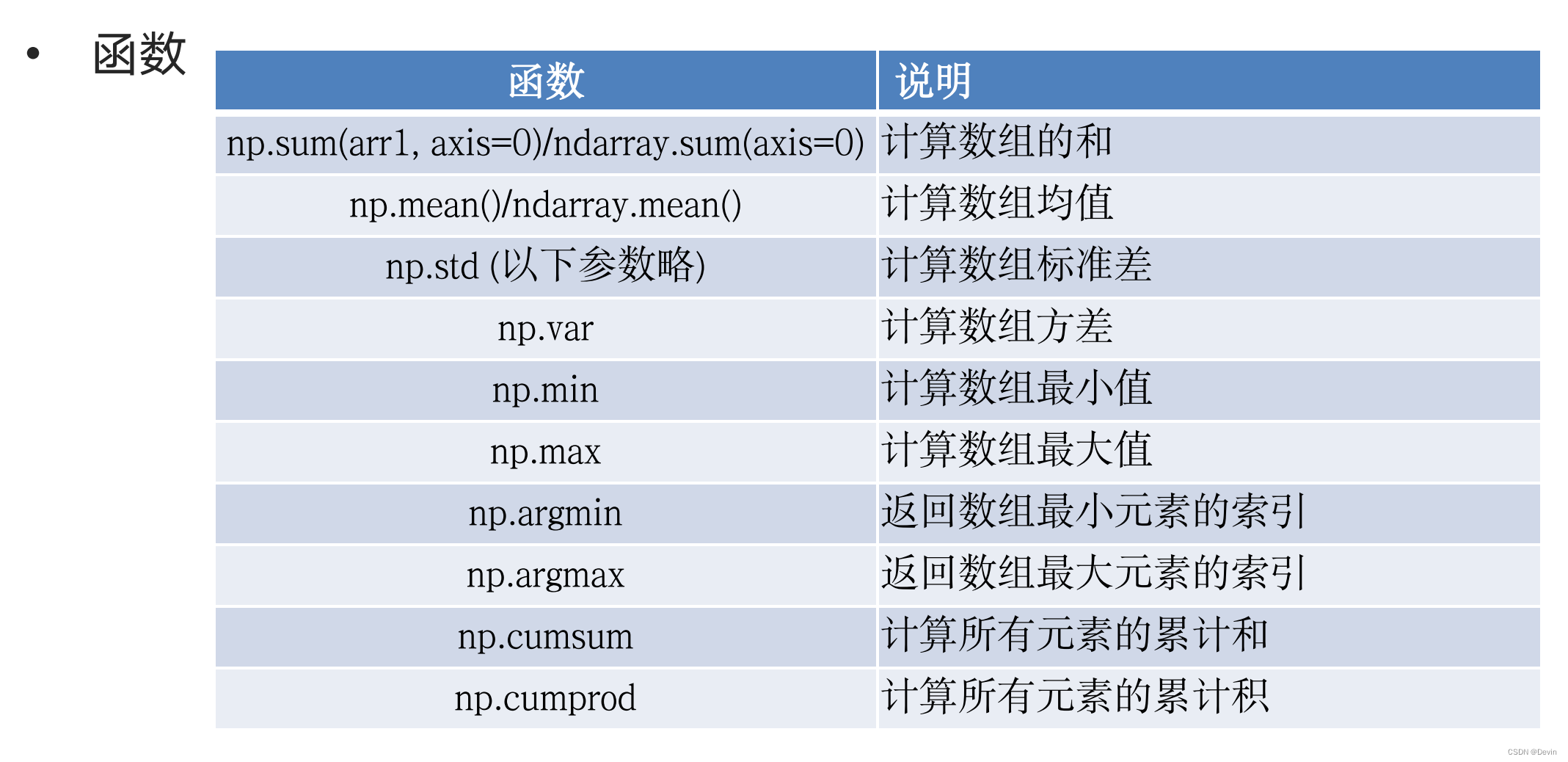
np.sum函数代码示例
统计函数代码示例1
统计函数代码示例2

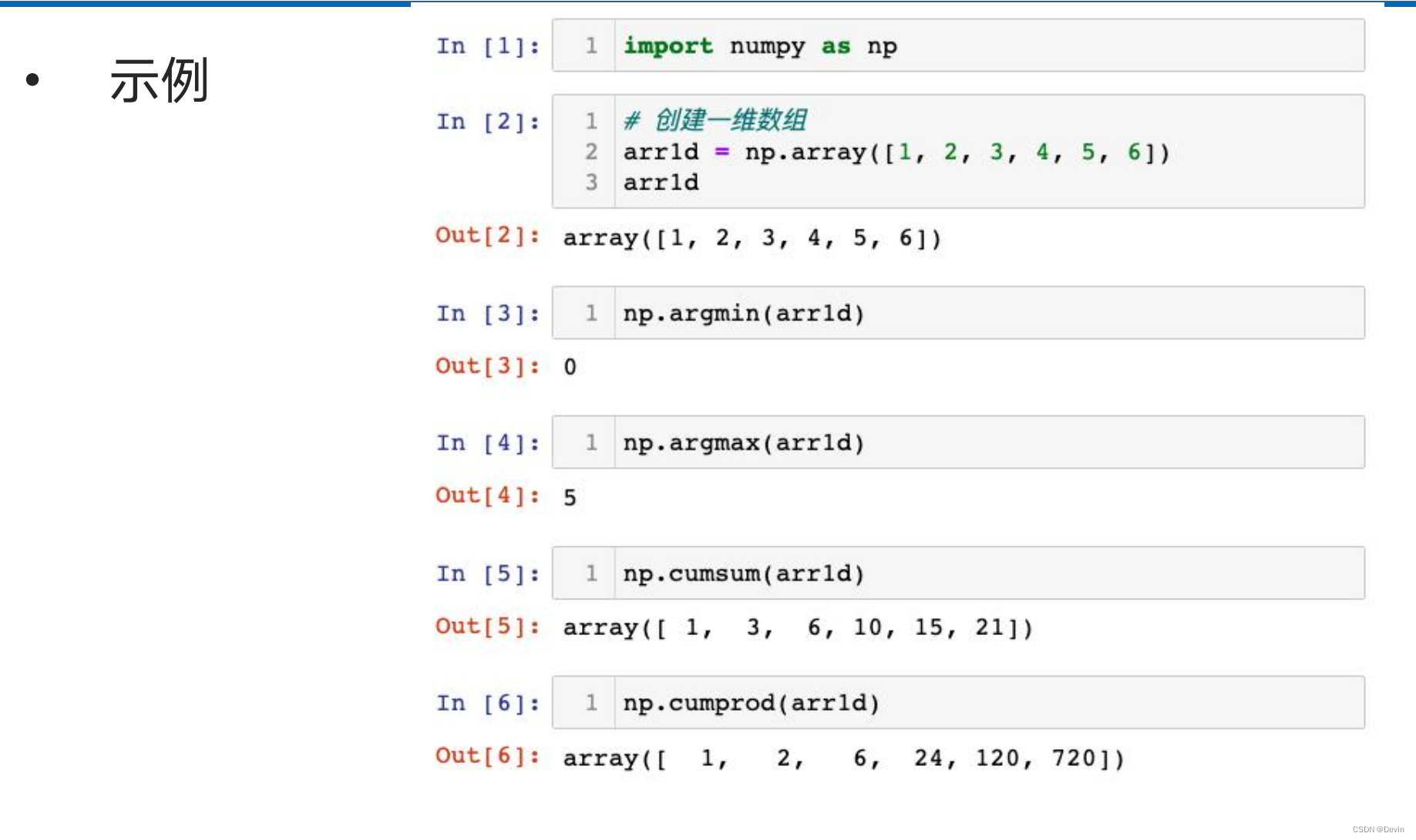
0.6.3 其他函数
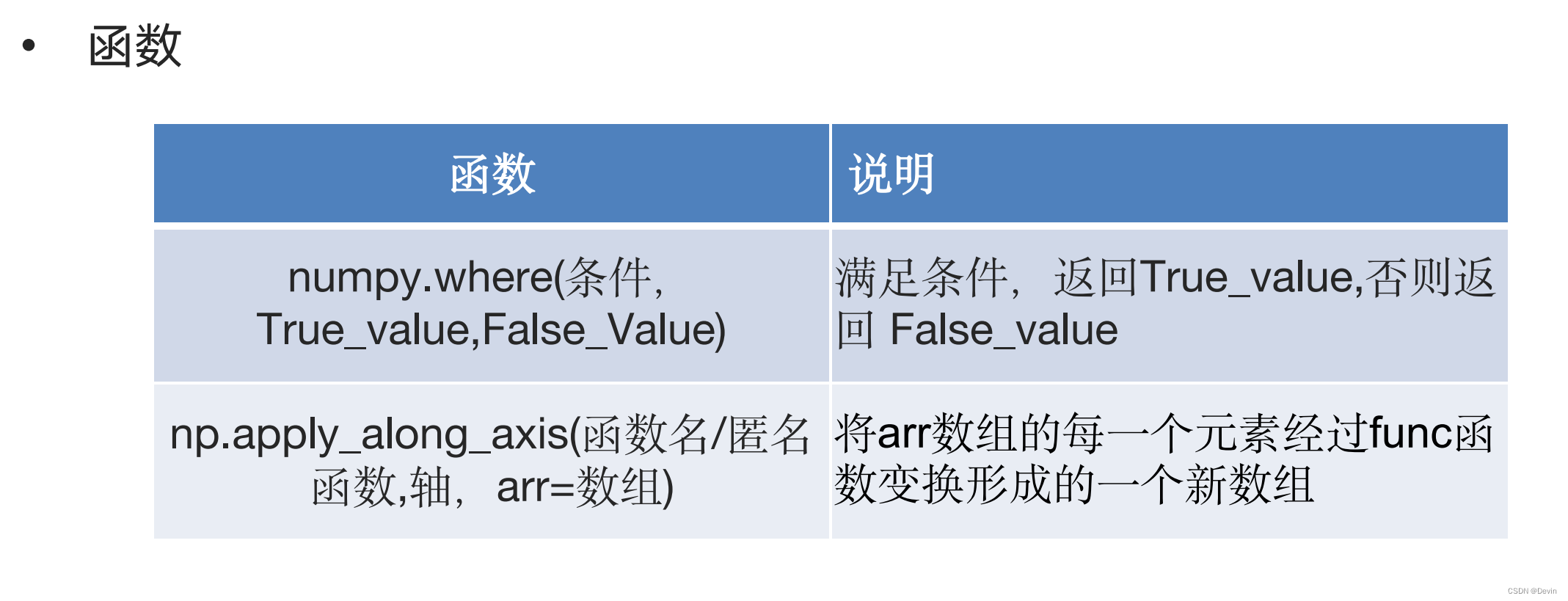
where函数示例
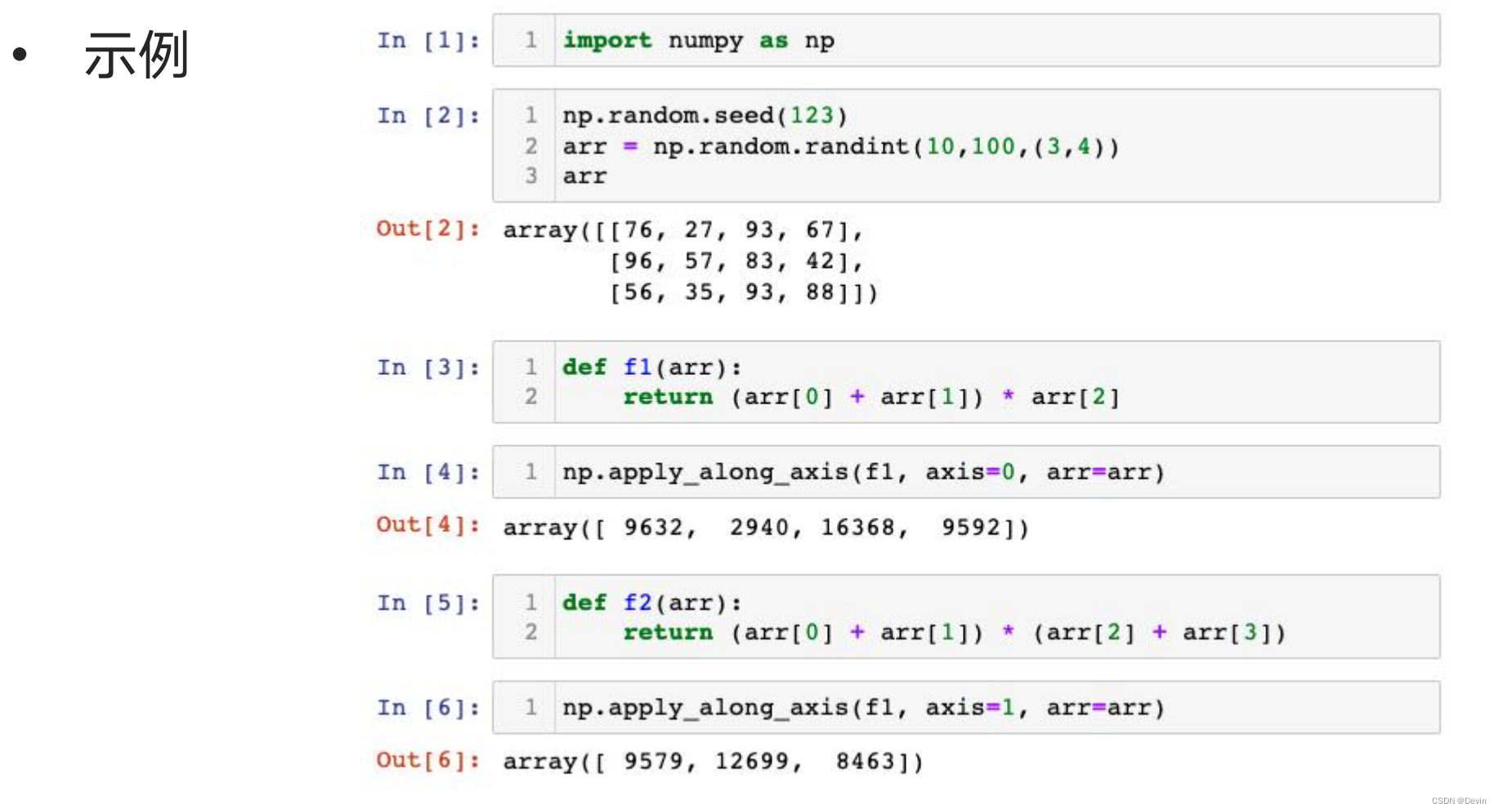
apply_along_axis函数示例

0.7 numpy 其他参考链接
https://www.numpy.org.cn/user/basics/types.html
https://www.runoob.com/numpy/numpy-tutorial.html
















 7万+
7万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









