






提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档
文章目录
前言
静态网页是HTML格式的网页,这种网页在浏览器中呈现的内容都会体现在源代码中,此时我们若要抓取静态网页的数据,只需要获得网页的源代码即可。网络爬虫抓取静态网页数据的过程就是获得网页源代码的过程,这个过程模仿用户通过浏览器访问网页的过程,包括向Web服务器发送HTTP请求、服务器对HTTP请求做出响应并返回网页源代码。为帮助开发人员抓取静态网页数据,减少开发人员的开发时间,Python提供了一些功能齐全的库,包括urllib、urllib3和Requests,其中urllib是Python内置库,无须安装便可以直接在程序中使用;urllib3和Requests都是第三方库,需要另行安装后才可以在程序中使用。
一、什么是urllib库?
urllib库是Python内置的HTTP请求库,它 可以看做是处理URL的组件集合。
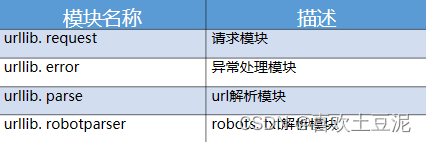
1.urllib库的安装以及导入方法
在终端输入如下代码安装
pip install urllib
导入方法:
import urllib.request
2.urllib爬取网页
使用urllib快 速爬取itcast 网页
(示例)
import urllib.request
# 调用urllib.request库的urlopen方法,并传入一个url
response = urllib.request.urlopen('http://www.baidu.com')
# 使用read方法读取获取到的网页内容
html = response.read().decode('UTF-8')
# 打印网页内容
print(html)
urlopen()是urllib库打开访问网页的函数
上述案例仅仅用了几行代码,就已经帮我们把百度的首页的全部代码下载下来了,以下是示例结果。
实际上,如果我们在浏览器打开百度主页,右键选择"查看码源",你会发现跟刚才打印出来的结果是一模一样的。
Python2中使用的是urllib2库来下载网页, 该库的用法如下所示:
import urllib2
response = urllib2.urlopen(‘http://www.baidu.com’)
Python3出现后,之前Python2中的urllib2库被移到了urllib.request模块中,之前urllib2中很多函数的路径也发生了变化,希望大家在使用的时候多加注意。
3.分析urlopen方法
前面在爬取网页时,有一句核心的爬虫代码:
response = urllib.request.urlopen(‘http://www.baidu.com’)
上述代码调用的是urllib. request模块中的urlopen方法,它传入了一个百度首页的URL,使用的协议是HTTP,这是 urlopen方法最简单的用法。
urlopen方法可以接收多个参数,定义格式如下:
urllib.request.urlopen(url, data=None, [timeout, ]*, cafile=None, capath=None, cadefault=False, context=None)
参数如下:
- url --表示目标资源在网站中的位置。
- data --用来指明向服务器发送请求的额外信息。
- timeout 一该参数用于设置超时时间,单位是秒。
- context 一 实现SSL加密传输,该参数很少使用
4.使用HTTPResponse对象
使用urlopen方法发送HTTP请求后,服务器返回 的响应内容封装在一个HTTPResponse类型的对象中,例如;
import urllib.request
response = urllib.request.urlopen('http://www.itcast.cn')
print(type(response))# <class 'http.client.HTTPResponse'>
HTTPResponse类属于http.client模块,该 类提供了获取URL、状态码、响应内容等一 系列方法。
- geturl() – 用于获取响应内容的URL,该方法可以验证发送的HTTP请求是否被重新调配。
- info() – 返回页面的元信息。
- getcode() – 返回HTTP请求的响应状态码。
示例:
import urllib.request
response = urllib.request.urlopen('http://python.org')
#获取响应信息对应的URL
print(response.geturl())
#获取响应码
print(response.getcode())
#获取页面的元信息
print(response.info())

5.构造Request对象
在构建请求时,除了必须设置的urI参数外, 还可以加入很多内容,例如下面的参数:
- data – 默认为空,该参数表示提交表单数据,同时HTTP请求方法将从默认的GET方式改为POST方式。
- headers --默认为空,该参数是一个字典类型,包含了需要发送的HTTP报头的键值对。
6.使用urllib实现数据传输
URL编码转换
当传递的URL中包含中文或者其它特殊字符(如
空格等)时,需要使用urllib.parse库中的 urlencode方法将URL进行编码,

它可以将“key:value”这样的键值对转换成“key=value” 这样的字符串。
解码使用的是url.parse库的unquote方法。
import urllib.parse
result =urllib.parse.unquote('a=%E4%BC%A0%E6%99%BA%E6%92%AD%E5%AE%A2')
print(result)
#a=传智博客
7.添加特定Headers—请求伪装
如果不是从浏览器发出的请求,我们是不能获得 响应内容的。针对这种情况,我们需要将爬虫程 序发出的请求伪装成一个从浏览器发出的请求
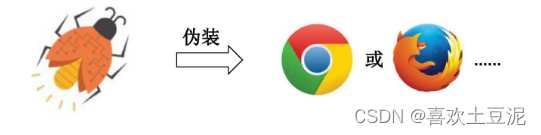
伪装浏览器需要自定义请求报头,也就是在 发送Request请求时,加入特定的Headers。
user_agent = ("User-Agent" : "Mozilla/5.0 (compatible; MSIE 9.0; Windows NT6.1; Trident/5.0)"}
request = urllib.request.Request(url, headers = user_agent)
request.add_header("Connection", "keep-alive")
8. 代理服务器
很多网站会检测某一段时间某个IP 的访问次数,如果同一IP访问过于频繁,那么该网站会禁止来自该IP的访问。碰到这种情况我们可以使用代理服务器,每隔一段时间换一个 代理。如果某个IP被禁止,那么就可以换成其他 IP继续爬取数据,从而可以有效解决被网站禁止 访问的情况。
简单的自定义opener
opener 是urllib.request.OpenerDirector类的对象,我们之前一直都在使用的urlopen, 就是模块帮我们构建好的一个opener。但是,urlopen不支持代理、Cookie等其他的 HTTP/HTTPS高级功能,所以如果要想设置代理,不能使用自带的urlopen,而是要自定义opener
自定义opener需要执行下列三个步骤:
- 首先使用相关的Handler处理器创建特定功能的处理器对象。
- 其次通过urllib.request.build_ opener()方法使用这些处理器对象创 建自定义的opener 对象。
- 最后使用自定义的opener对象,调用open方法发送 请求。
二、requests库
1.requests库的安装
打开终端输入:
pip install requests
2.发送基本请求
发送GET请求
在Requests库中,GET请求通过调用get()函数发送,该函数会根据传入的URL构建一个请求(每个请求都是Request类的对象),将该请求发送给服务器。get()函数的声明如下:
get(url, params=None, headers=None, cookies=None, verify=True,proxies=None, timeout=None, **kwargs)
- url:必选参数,表示请求的URL。
- params:可选参数,表示请求的查询字符串。
- headers:可选参数,表示请求的请求头,该参数只支持字典类型的值。
- cookies:可选参数,表示请求的Cookie信息,该参数支持字典CookieJar类对象。
- verify:可选参数,表示是否启用SSL证书,默认值为True。
- proxies:可选参数,用于设置代理服务器,该参数只支持字典类型的值。
- timeout:可选参数,表示请求网页时设定的超时时长,以秒为单位。
使用get()函数可以发送不携带url参数和携带url参数的GET请求。
不携带url参数的GET请求:
若GET请求的URL中不携带参数,我们在调用get()函数发送GET请求时只需要给url参数传入指定的URL即可
import requests
# 准备URL
base_url = 'https://www.baidu.com/'
# 根据URL构造请求,发送GET请求,接收服务器返回的响应信息
response = requests.get(url=base_url)
# 查看响应码
print(response.status_code)
携带url参数的GET请求:
若GET请求的URL中携带参数,在调用get()函数发送GET请求时只需要给url参数传入指定的URL即可
方式一:
import requests
base_url = 'https://www.baidu.com/s'
param = 'wd=python'
full_url = base_url + '?' + param # 拼接完整的URL
# 根据URL构造请求,发送GET请求,接收服务器返回的响应信息
response = requests.get(full_url)
# 查看响应码
print(response.status_code)
方式二:
import requests
base_url = 'https://www.baidu.com/s'
wd_params = {'wd': 'python'}
# 根据URL构造请求,发送GET请求,接收服务器返回的响应
response = requests.get(base_url, params=wd_params)
# 查看响应码
print(response.status_code)
发送POST请求
如果网页上form表单的method属性的值设为POST,那么当用户提交表单时,浏览器将使用POST方法提交表单内容,并将各个表单元素及数据作为HTTP请求信息中的请求数据发送给服务器
在Requests中,POST请求可以通过调用post()函数发送,post()函数会根据传入的URL构建一个请求,将该请求发送给服务器,并接收服务器成功响应后返回的响应信息。post()函数的声明如下:
post(url, data=None, headers=None, cookies=None, verify=True,
proxies=None, timeout=None, json=None, **kwargs)
- data:可选参数,表示请求数据。该参数可以接收3种类型的值,分别为字典、字节序列和文件对象。当参数值是一个字典时,字典的键为请求数据的字段,字典的值为请求数据中该字段对应的值,例如{“ie”: “utf-8”,“wd”: “python”}。
- json:可选参数,表示请求数据中的JSON数据。
以美多商城网站为例,为大家演示如何使用post()函数请求美多商城网站首页,具体代码如下。
import requests
base_url = 'http://mp-meiduo-python.itheima.net/login/'
# 准备请求数据
form_data = {
'csrfmiddlewaretoken':'FDb8DNVnlcFGsjIONtwiQoi6PtmCLeBsRgyjx2o2nsZ4MXDEGDeM2dUImEkj9O7t',
'username': 'admin',
'pwd': 'admin',
'remembered': 'on'}
response = requests.post(base_url, data=form_data) # 根据URL构造请求,发送POST请求
print(response.status_code) # 查看响应信息的状态码
处理响应
在Requests库中,Response类的对象中封装了服务器返回的响应信息,包括响应头和响应内容等。除了前面介绍的status_code属性之外,Response类中还提供了一些其他属性。
-
status_code 获取服务器返回的状态码
-
text 获取字符串形式的响应内容
-
content 获取二进制形式的响应内容
-
url 获取响应的最终URL
-
request 获取请求方式
-
headers 获取响应头
-
encoding 设置或获取响应内容的编码格式,与text属性搭配使用
-
cookies 获取服务器返回的Cookie
获取网页源代码
通过访问Response类对象的text属性可以获取字符串形式的网页源代码
import requests
base_url = 'https://www.baidu.com/'
# 根据URL构造请求,发送GET请求,接收服务器返回的响应信息
response = requests.get(url=base_url)
# 查看响应内容
print(response.text)
为了保证获取的源代码中能够正常显示中文,这里需要通过Response对象的encoding属性将编码格式设置为UTF-8。
import requests
base_url = 'https://www.baidu.com/'
# 根据URL构造请求,发送GET请求,接收服务器返回的响应信息
response = requests.get(url=base_url)
# 设置响应内容的编码格式
response.encoding = 'utf-8'
# 查看响应内容
print(response.text)
获取图片
百度首页上除了文字信息之外,还包含一个百度Logo图片。若希望获取百度Logo的图片,我们需要先根据该图片对应的请求URL发送请求,再使用content属性获取该图片对应的二进制数据,并将数据写入到本地文件中。
import requests
base_url = 'https://www.baidu.com/img/PCtm_d9c8750bed0b3c7d089fa7d55720d6cf.png'
response = requests.get(base_url)
# 获取百度Logo图片对应的二进制数据
print(response.content)
# 将二进制数据写入程序所在目录下的baidu_logo.png文件中
with open('baidu_logo.png', 'wb') as file:
file.write(response.content)
3.处理复杂请求
在互联网中,网页中的内容是千变万化的,如果只根据请求URL发送基本请求有可能无法获取网站的响应,此时需要根据网站接收请求的要求完善请求。例如,在访问登录后的页面时需要给请求头带上Cookies,在遇到403错误时需要给请求头添加User-Agent。
定制请求头
定制请求头分为两步,分别是查看请求头和设置请求头。
打开Fiddler工具,在Chrome浏览器中加载知乎网登录页面,加载完成后切换至Fiddler工具,在窗口左侧选中刚刚发送的HTTP请求,并在窗口右侧查看该请求对应的请求头信息。
在requests中,设置请求头的方式非常简单,只需要在调用请求函数时为headers参数传入定制好的请求头即可,一般是将请求头中的字段与值分别作为字典的键与值,以字典的形式传给headers参数。
import requests
base_url = 'https://www.zhihu.com/signin'
header = {'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64'
'AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.131 Safari/537.36'}
# 根据URL和请求头构造请求,发送GET请求,接收服务器返回的响应
response = requests.get(base_url, headers=header)
response.encoding = 'utf-8'
# 查看响应内容
print(response.text)
验证Cookie
Cookie(有时也用其复数形式 Cookies)是指某些网站为了辨别用户身份、进行会话跟踪,而暂时存储在客户端的一段文本数据(通常经过加密)。
在Requests库中,发送请求时可以通过两种方式携带Cookie,一种方式直接将包含Cookie信息的请求头传入请求函数的headers参数;另一种方式是将Cookie信息传入请求函数的cookies参数。不过,cookies参数需要接收一个RequestsCookieJar类的对象,该对象类似一个字典,它会以名称(Name)与值(Value)的形式存储Cookie。
以登录后的百度首页为例,使用两种方式演示如何使用Requests实现Cookie登录。
方式一:
import requests
headers = {
'Cookie': '此处填写登录百度网站后查看的Cookie信息', # 设置字段Cookie
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_11_4)'
'AppleWebKit/537.36 (KHTML, like Gecko)'
'Chrome/53.0.2785.116 Safari/537.36',} # 设置字段User-Agent
response = requests.get('https://www.baidu.com/', headers=headers)
print(response.text)
方式二:
import requests
header = {'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_11_4) '
'AppleWebKit/537.36 (KHTML, like Gecko)Chrome/53.0.2785.116 Safari/537.36'}
cookie = '此处填写登录百度网站后查看的Cookie信息‘# 准备Cookie
jar_obj = requests.cookies.RequestsCookieJar() # 创建RequestsCookieJar类对象
for temp in cookie.split(';') :# 以逗号为分隔符分割cookie,并将获得的键和值保存至jar_obj中
key, value = temp.split('=', 1)
jar_obj.set(key, value)
response = requests.get('https://www.baidu.com/',
headers=header, cookies=jar_obj)
print(response.text)
保持会话
在Requests中,Session类负责管理会话,通过Session类的对象不仅可以实现在同一会话内发送多次请求的功能,还可以在跨请求时保持Cookie信息。
使用Session类的对象先在请求一个测试网站时设置Cookie信息,然后在请求另一个网站时获取Cookie信息,具体代码如下。
import requests
# 创建会话
sess_obj = requests.Session()
sess_obj.get('http://httpbin.org/cookies/set/sessioncookie/123456789')
response = sess_obj.get("http://httpbin.org/cookies")
print(response.text)
在上代码中,首先创建了一个Session类对象sess_obj,然后基于sess_obj对象发送了一个GET请求到测试网站,并且在请求该测试网站时设置了Cookie信息,其中Cookie的名称设置为sessioncookie,内容为123456789,最后基于sess_obj对象请求另一个网站,获取上次请求时设置的Cookie信息。
{
"cookies": {
"sessioncookie": "123456789"
}
}
SSL证书验证
SSL证书是一种数字证书,类似于驾驶证、护照和营业执照的电子副本,由受信任的数字证书颁发机构CA在验证服务器身份后颁发,具有服务器身份验证和数据传输加密功能。
当使用Requests调用请求函数发送请求时,由于请求函数的verify参数的默认值为True,所以每次请求网站时默认都会进行SSL证书的验证。不过,有些网站可能没有购买SSL证书,或者SSL证书失效,当程序访问这类网站时会因为找不到SSL证书而抛出SSLError异常。
例如,使用Requests请求国家数据网站,具体代码如下。
import requests
base_url = 'https://data.stats.gov.cn/'
header = {'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64 '
'AppleWebKit/537.36 (KHTML, like Gecko)'
'Chrome/90.0.4430.212 Safari/537.36'}
response = requests.get(base_url, headers=header)
print(response.status_code)
运行上代码,程序抛出SSLError异常,具体如下所示:
…
requests.exceptions.SSLError: HTTPSConnectionPool(host=‘data.stats.gov.cn’, port=443): Max retries exceeded with url: / (Caused by SSLError(SSLCertVerificationError(1, ‘[SSL: CERTIFICATE_VERIFY_FAILED] certificate verify failed: self signed certificate in certificate chain (_ssl.c:1108)’)))
这时需要主动关闭SSL验证,即在调用get()函数时将verify参数设置为False,代码如下所示:
response = requests.get(base_url, headers=header, verify=False)
再次运行代码,控制台没有输出SSLError异常,而是输出了如下警告信息:
C:\Users\admin\AppData\Roaming\Python\Python38\site-packages\urllib3
connectionpool.py:981: InsecureRequestWarning: Unverified HTTPS request
is being made to host ‘data.stats.gov.cn’. Adding certificate verification is strongly advised. See: https://urllib3.readthedocs.io/en/latest/advanced-usage.html#ssl-warnings
这时,如果不希望收到警告信息,可以采用如下方式消除警告信息。
import urllib3
urllib3.disable_warnings()
总结
除了以上说到的东西,还有很多很多,欢迎大家评论区留言。















 491
491











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









