






0 前言
在准备考研,背单词,然后用扇贝背的单词,在第一轮背完之后我突发奇想,能不能把这个单词书的单词导出来,然后让ai根据这些我刚背诵过的单词定制生成文章,定向的提升我的阅读能力,防止出现会背诵但是不会使用的情况。
但是这个扇贝竟然不提供直接导出整本单词书的词表的这个功能,实在是十分恼火。
最后实在没办法的我只好用尝试使用爬虫来爬,下面是我的代码。
编程小白,不足之处还请见谅。
1 快速使用
代码如果过审的话,小伙伴们应该可以在文章首部看到,想看详细过程的可以移步到第二块
这个爬虫是用node.js写的,不懂的小伙伴也不用担心,想要使用的话整体需要改动的地方还是很少的。
打开main.js文件,进行如下修改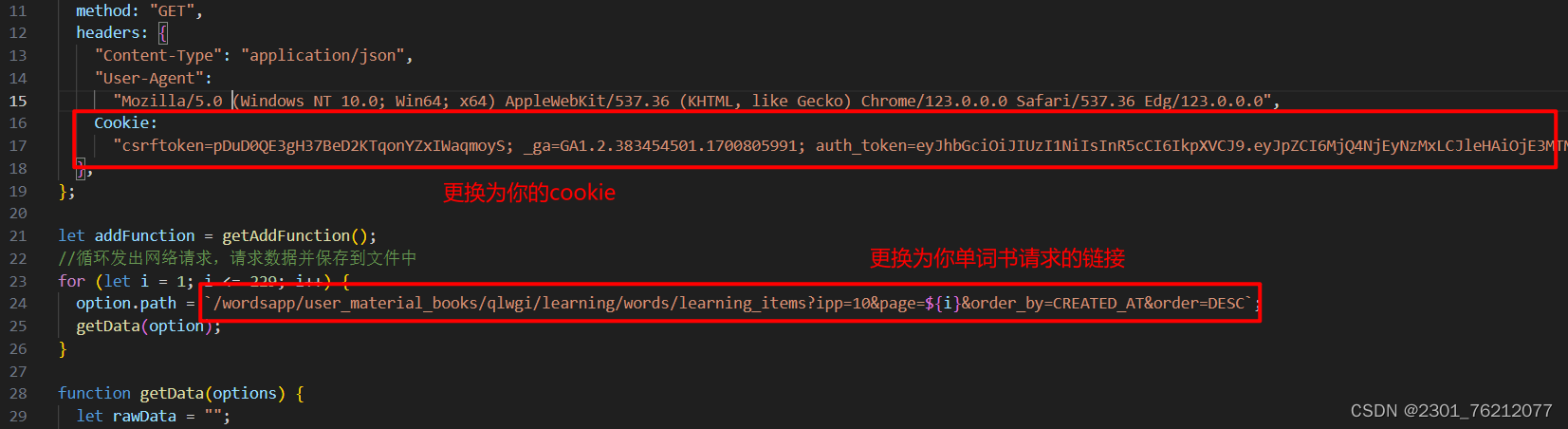
完成这些修改之后直接执行main.js文件你的单词书就会存放在生成的output.txt文件中了。
对node.js不太熟悉的小伙伴们可以问一下ai,快速了解一下,很快就可以上手
2 研究过程
我们打开检查器,进入我们想要爬取的单词书页面中
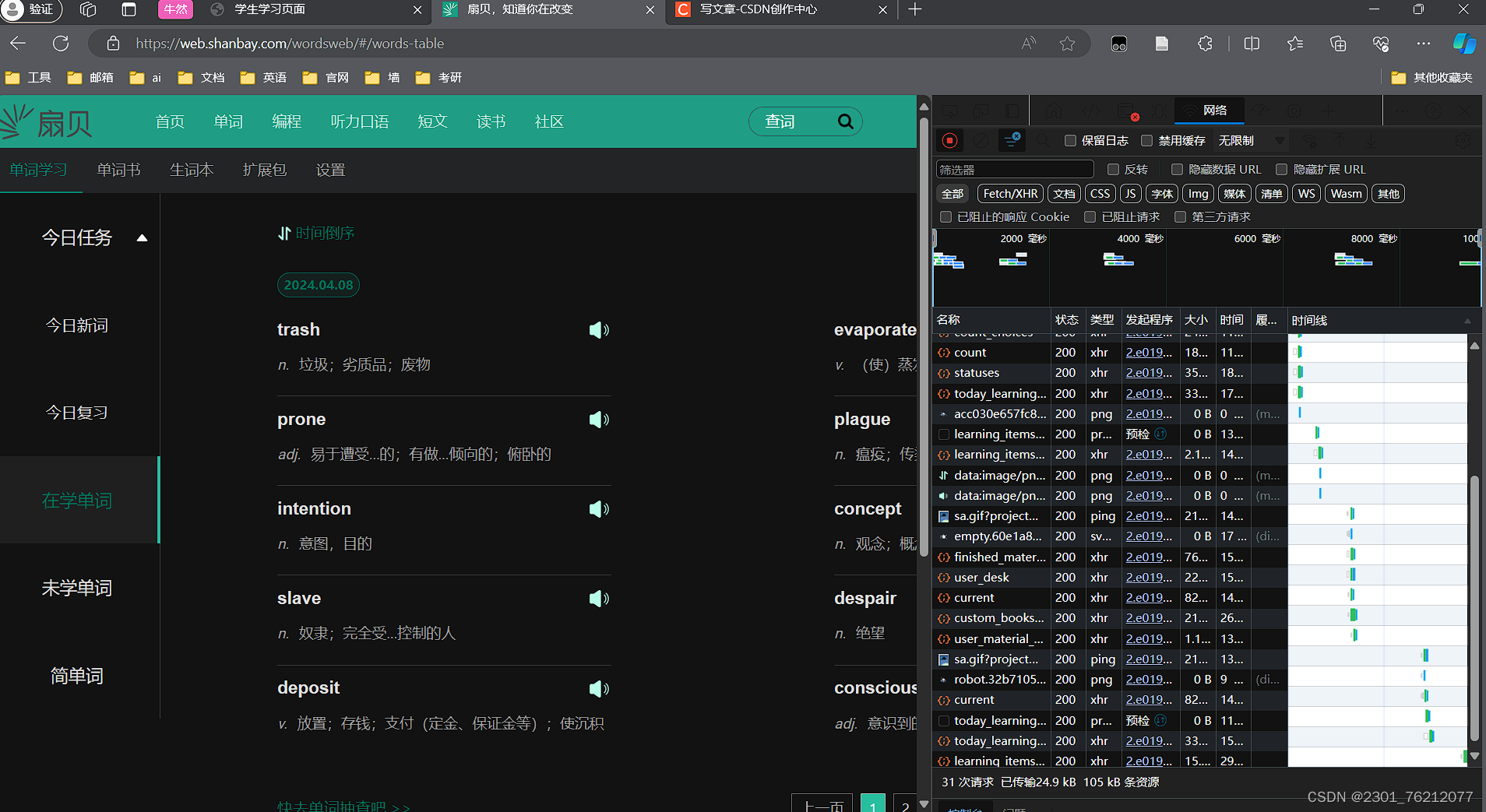
稍微刷新一下应该就能看到一个包
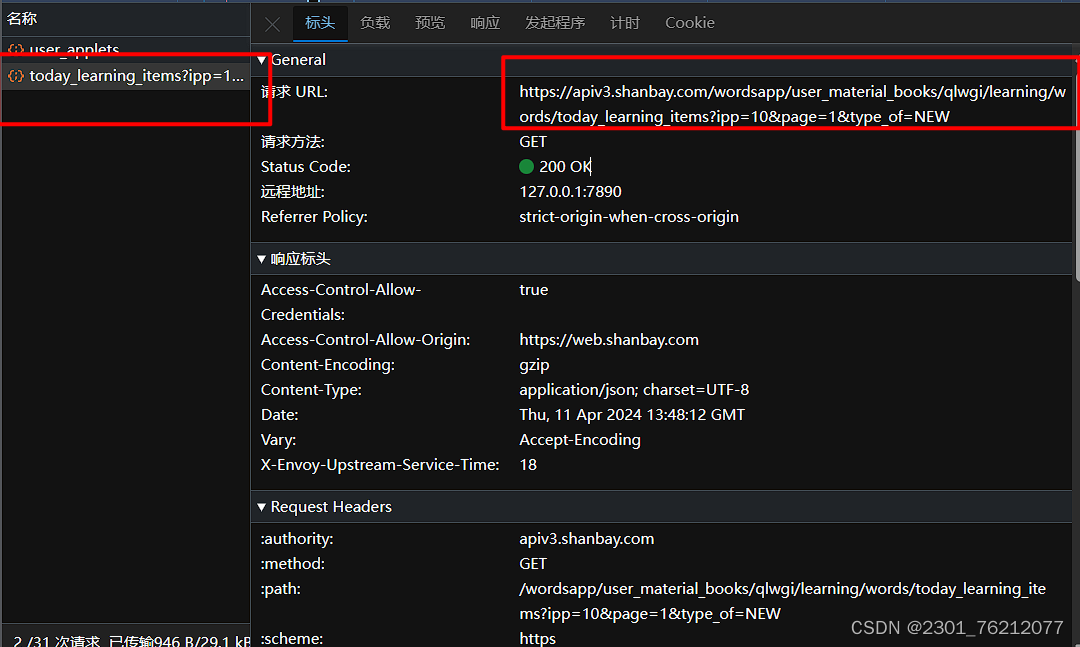 解读一下它这个url,我们可以很明显的看出,这个就是我们想要的单词内容
解读一下它这个url,我们可以很明显的看出,这个就是我们想要的单词内容

但是当我们预览的时候,我们可以很明显的看到,这个数据并不是明文,是经过了一定的加密。
我原本以为是base64编码,但是解码之后并没有结果。所以这里的数据很明显是进行了加密。
那该如何解密啊。
不用担心,我们不会,可以上源码里找啊,它终归是要向这个链接请求数据的,我们只要找到请求数据的地方,顺藤摸瓜的就能找到解密的地方。
我们查看它的js代码,直接在里面搜索这个链接中一部分(不搜索全部的原因是这个链接可能是拼接形成的,这样大概率搜索不到)。
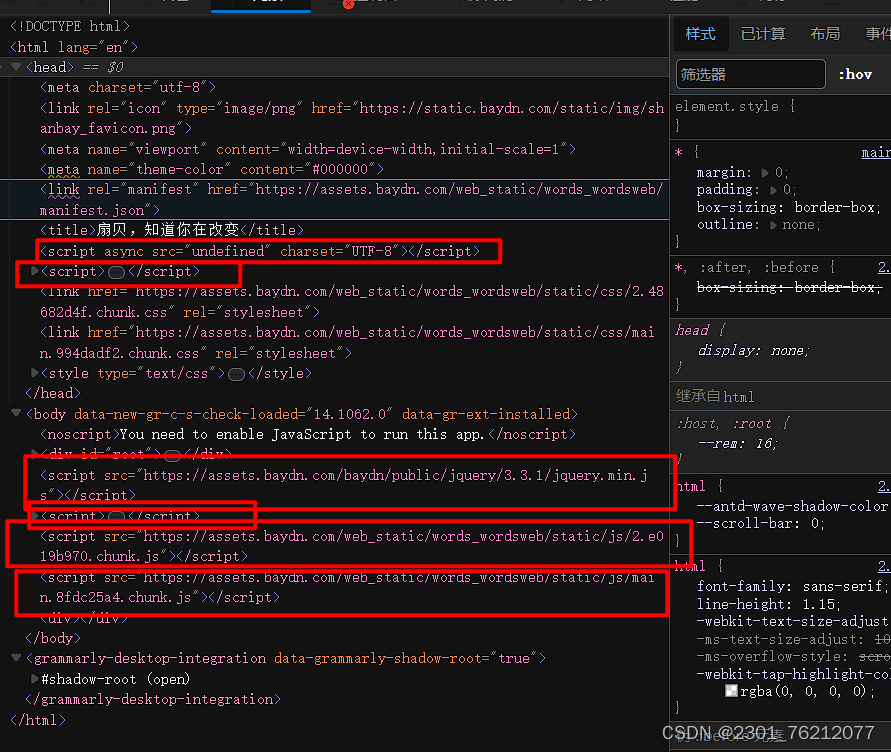
链接形式的js代码建议down下来再查找,这样方便一些(ps:中间可以会出现代码过长导致无法格式化代码的情况,可以下载格式化代码的插件来解决)
经过一番寻找,我们可以在main.8fdc25a4.chunk.js这个文件中找到链接的踪迹。
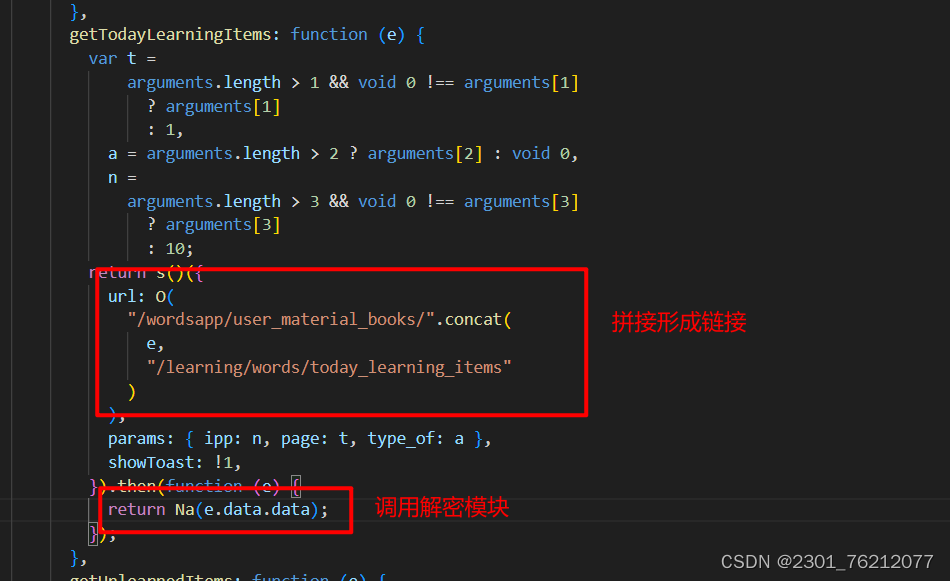
我们继续往下寻找这个解密的代码

他是直接调用了一个自定义的bays4.d()方法完成了解密,这显然是一个自定义的解密方法,我们再次在js代码中进行寻找。不过这次的关键字换成了bays4
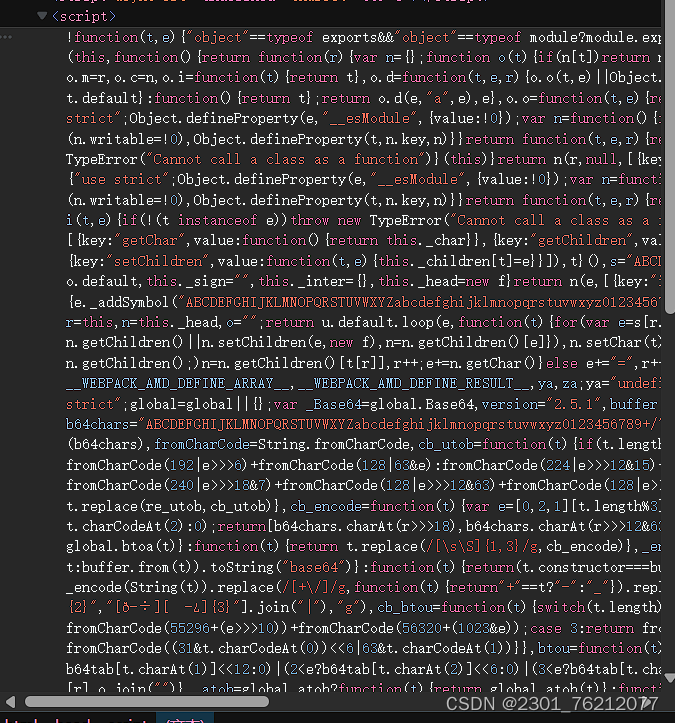
经过查找,我们在head区的js代码中搜索到了这个关键字,我们把代码down下来,详细看一下这里直接从这个视图中获得的代码是不完整的,我们从下面的试视图中下载。
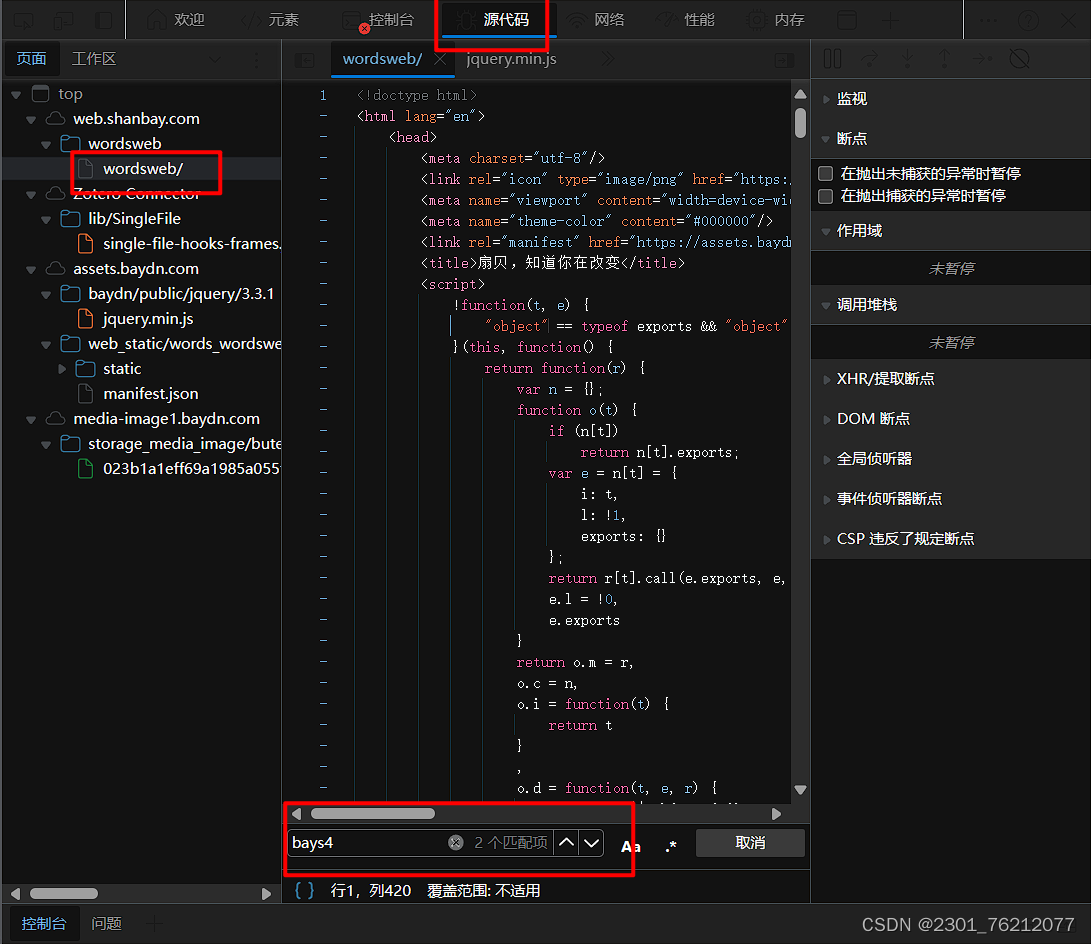
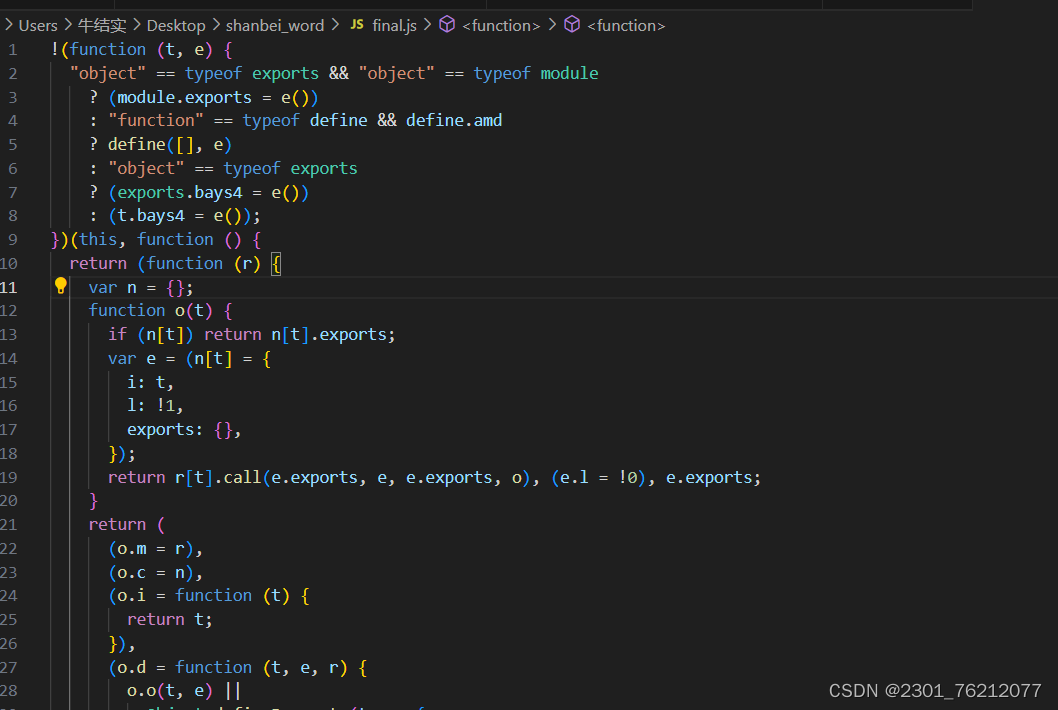
可以看到这部分代码很复杂,语法很奇怪,我们看不懂,可以直接丢给ai来进行分析。
ai说这是封装了一个模块,名字叫做bays4,正好就是我们想要的。
我们直接在js中导入这个模块,然后尝试着用这个方法解密我们之前得到的字符串
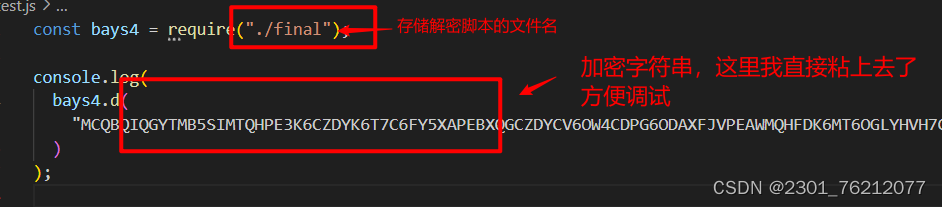
执行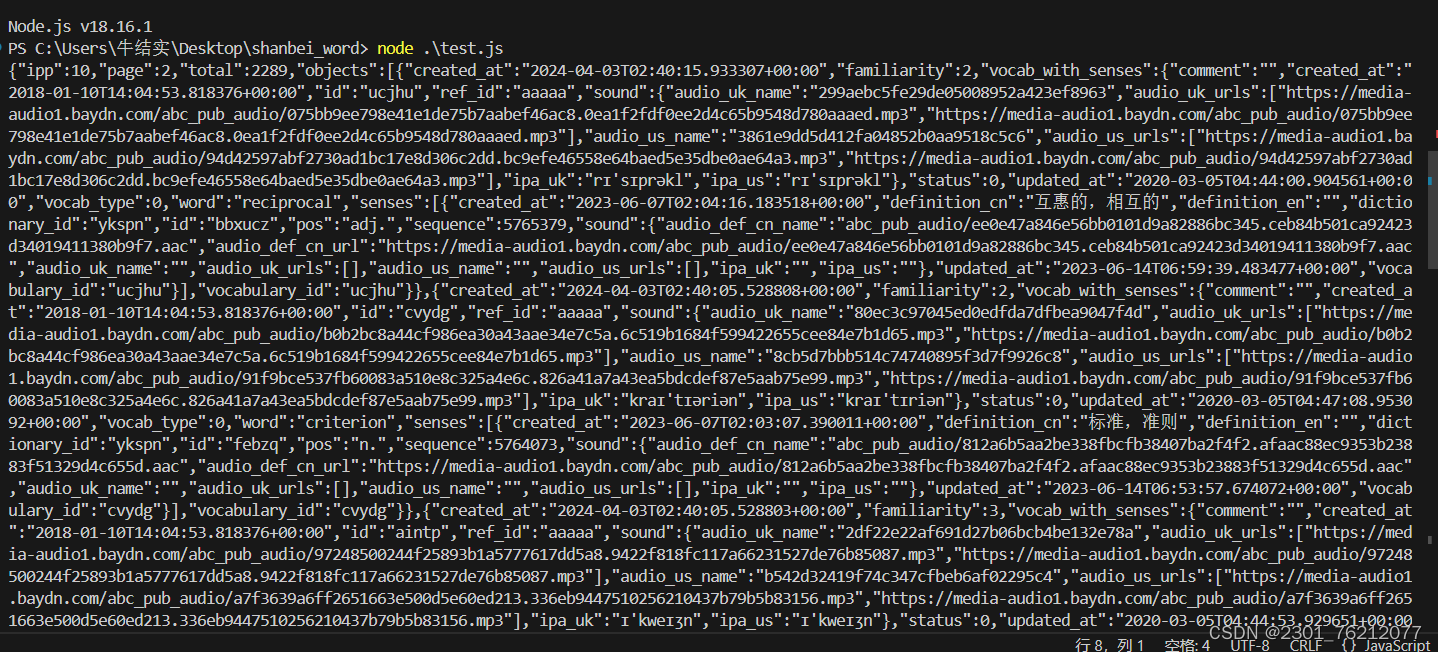 很显然已经拿到了数据。
很显然已经拿到了数据。
剩下的就是解析JSON字符串,然后选择出自己想要的字段了,循环便利获取了。这些工作都比较简单,我在这里就不过多赘述了。
到这里,我们获取扇贝单词的爬虫就完成了。
喜欢的不妨点个赞。

















 836
836

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









