







MongoDB是一个介于关系数据库和非关系数据库之间的产品,是非关系数据库当中 功能最丰富、最像关系数据库的NoSQL数据库;它支持的查询语言非常强大,其语法有 点类似于面向对象的查询语言,可以实现类似关系数据里单表查询的绝大部分功能,而且还支持对数据建立索引。
1.2 MongoDB特点
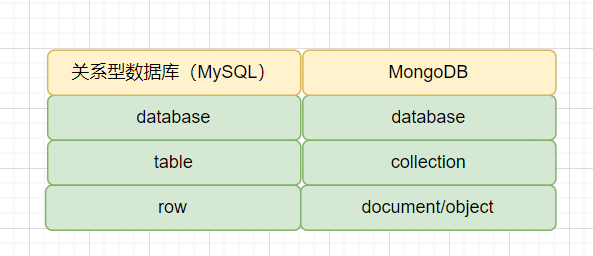
它用与JSON格式类似的键值对来存储(在MongoDB中叫BSON对象),其中值的数据类型有常见的字符串、数字、日期,还可以是BSON对象、数组以及数组的元素,也可以是BSON对象,通过这种嵌套的方式,使MongoDB的数据类型变得相当丰富。 MongoDB与传统关系数据库还有一个重大区别就是:可扩展的表结构。也就是说collection (表)中的document (—行记录)所拥有的字段(列)是可以变化的,下面文档对象document ( —行记录)比上面列出的文档对象document (—行记录)多一个time字段,但它们可以共存在同一个collection (表)中。
db.movies.find()
{ "\_id" : ObjectId("65a8e26baa7aec49b06f7918"), "title" : "The Favourite", "genres" : [ "Drama", "History" ], "runtime" : 121, "rated" : "R", "year" : 2018, "directors" : [ "Yorgos Lanthimos" ], "cast" : [ "Olivia Colman", "Emma Stone", "Rachel Weisz" ], "type" : "movie" }
{ "\_id" : ObjectId("65a8e29caa7aec49b06f7919"), "title" : "Jurassic World: Fallen Kingdom", "genres" : [ "Action", "Sci-Fi" ], "runtime" : 130, "rated" : "PG-13", "year" : 2018, "directors" : [ "J. A. Bayona" ], "cast" : [ "Chris Pratt", "Bryce Dallas Howard", "Rafe Spall" ], "type" : "movie" }
{ "\_id" : ObjectId("65a8e931aa7aec49b06f791b"), "title" : "Jurassic World: Fallen Kingdom", "genres" : [ "Action", "Sci-Fi" ], "runtime" : 130, "rated" : "PG-13", "year" : 2018, "directors" : [ "J. A. Bayona" ], "cast" : [ "Chris Pratt", "Bryce Dallas Howard", "Rafe Spall" ], "type" : "movie" }
{ "\_id" : ObjectId("65a92e692725916a6012a44e"), "title" : "Jurassic World: Fallen Kingdom", "genres" : [ "Action", "Sci-Fi" ], "runtime" : 130, "rated" : "PG-13", "year" : 2018, "directors" : [ "J. A. Bayona" ], "cast" : [ "Chris Pratt", "Bryce Dallas Howard", "Rafe Spall" ], "type" : "movie", "time" : "2024-01-18" }
MongoDB查询语句不是按照SQL的标准来开发的,它围绕JSON这种特殊格式的文 档型存储模型开发了一套自己的查询体系,这就是现在非常流行的NoSQL体系。关系数据库中常用的SQL语句在MongoDB中都有对应的解决方案。当然也有例外,MongoDB不支持Join语句。我们知道传统关系数据库中Join操作可能会产生笛卡尔积的虚拟表,消耗较多系统资源,而MongoDB的文档对象集合collection可以是任何结构,我们可以通过设计较好的数据模型尽量避开这样的操作需求。如果真的需要从多个collection (表)中检索数据,那我们可以通过多次查询得到。
在关系数据库中经常用到的group by等分组聚集函数,在MongoDB中也有,而且MongoDB提供了更加强大的MapReduce方案(GOOGLE提出的并行编程),为海量数据的统计、分析提供了便利。
MongoDB支持日志功能Journaling,对数据库的增、删、改操作会记录在日志文件中。MongoDB每100ms将内存中的数据刷到磁盘上,如果意外停机,在数据库重新启动时,MongoDB能通过Journaling日志功能恢复。
MongoDB支持复制集(Replset), —个复制集在生产环境中最少需要3台独立的机器 (测试的时候为了方便可能都部署在一台机器上),一台作主节点(primary), —台作次节点(secondary), —台作仲裁节点(只负责选出主节点),备份、自动故障转移,这些特性都是复制集支持的。
MongoDB支持自动分片Sharding,分片的功能实现海量数据的分布式存储,分片通常与复制集配合起来使用,实现读写分离、负载均衡,当然如何选择片键是实现分片功能的关键。如何实现读写分离我们后面会详细分析。
1.3. 适合哪些业务
- Web应用程序
传统的关系数据库表结构都是固定的,增加一个业务或者横向扩展数据库都会带来 巨大的工作量。MongoDB支持无固定结构的表模型,因此很容易增加或减少表中的字段,适应业务的变化;同时MongoDB本身就支持分片集群,很容易实现水平扩展,将数据分散到集群中的各个片上,提高了系统的存储容量和读写吞吐量。Web应用程序还有一个特点就是“热数据”读并发很高,也就是说最新的数据被请求的次数会最多。
为了提供读的性能,在传统的关系数据将中会采用其他的缓存技术来将这部分数据放在内存中,而MongoDB本身就支持这一点,它是通过内存映射数据文件来实现的。它会维护一个工作集,将最热的数据放在内存中,不需要其他技术的协助,这为系统开发提供了简便性。
2.缓存系统
这种使用场景是与关系数据库搭配使用,作为关系数据库的缓存前端。目前缓存技术有很多种,最常见的就是使用memcached,但是这些缓存系统都有个缺点,就是支持的数据类型有限,查询语句也有限,只能保存少量的数据且不能持久化。而MongoDB这些都能支持,因此可以作为缓存使用。
3.日志分析系统
这类系统的特点是数据量大,允许部分数据丢失,不会影响整个系统的可靠性。以前将日志直接保存到操作系统的文件上,我们需要用其他工具打开日志文件或编写工具读曰志进行分析,这样的话对于大量的日志查询会比较困难。如果用MongoDB数据库来保存这些日志,一来可以利用分片集群使日志系统的容量海量大,二来使用MongoDB特有的查询语句自酿快速找到某条日志记录。最重要的是MongoDB支持聚集分析甚至MapReduce的能力,为大数据的分析和决策提供了强有力的支持。
网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!














 634
634











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









