







学好 Python 不论是就业还是做副业赚钱都不错,但要学会 Python 还是要有一个学习规划。最后大家分享一份全套的 Python 学习资料,给那些想学习 Python 的小伙伴们一点帮助!
一、Python所有方向的学习路线
Python所有方向路线就是把Python常用的技术点做整理,形成各个领域的知识点汇总,它的用处就在于,你可以按照上面的知识点去找对应的学习资源,保证自己学得较为全面。

二、学习软件
工欲善其事必先利其器。学习Python常用的开发软件都在这里了,给大家节省了很多时间。

三、全套PDF电子书
书籍的好处就在于权威和体系健全,刚开始学习的时候你可以只看视频或者听某个人讲课,但等你学完之后,你觉得你掌握了,这时候建议还是得去看一下书籍,看权威技术书籍也是每个程序员必经之路。

四、入门学习视频
我们在看视频学习的时候,不能光动眼动脑不动手,比较科学的学习方法是在理解之后运用它们,这时候练手项目就很适合了。

五、实战案例
光学理论是没用的,要学会跟着一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。

六、面试资料
我们学习Python必然是为了找到高薪的工作,下面这些面试题是来自阿里、腾讯、字节等一线互联网大厂最新的面试资料,并且有阿里大佬给出了权威的解答,刷完这一套面试资料相信大家都能找到满意的工作。


网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!

图像为128x128大小的绿色图像。
@zhangziju
from PIL import Image
im = Image.open(“E:\mywife.jpg”)
n_im= Image.new(“RGB”, (128, 128),“green”)
n_im.show()

### Copy类
>
> im.copy() ⇒ image
>
>
>
拷贝这个图像。如果用户想粘贴一些数据到这张图,可以使用这个方法,但是原始图像不会受到影响。
from PIL import Image
im = Image.open(“E:\mywife.jpg”)
im_copy = im.copy()
图像im\_copy和im完全一样。
### Crop类
>
> im.crop(box) ⇒ image
>
>
>
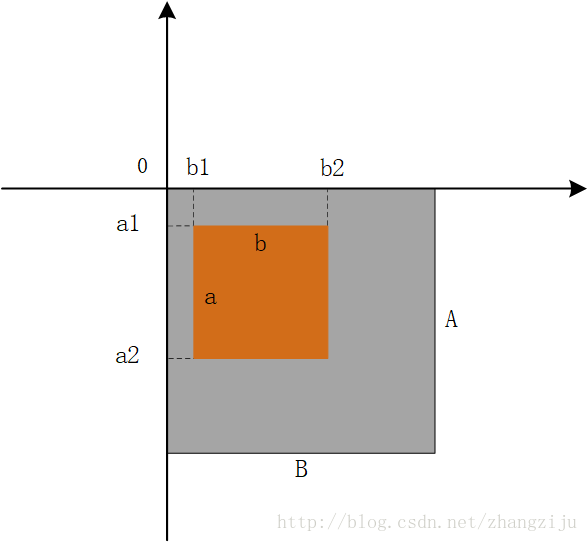
从当前的图像中返回一个矩形区域的拷贝。变量box是一个四元组,定义了左、上、右和下的像素坐标。用来表示在原始图像中截取的位置坐标,如**box(100,100,200,200)**就表示在原始图像中以左上角为坐标原点,截取一个100\*100(像素为单位)的图像,为方便理解,如下为示意图box(b1,a1,b2,a2)。作图软件为Visio2016。这是一个懒操作。对源图像的改变可能或者可能不体现在裁减下来的图像中。为了获取一个分离的拷贝,对裁剪的拷贝调用方法load()。
@zhangziju
from PIL import Image
im = Image.open(“E:\mywife.jpg”)
box = (300, 100, 700, 700) ##确定拷贝区域大小
region = im.crop(box) ##将im表示的图片对象拷贝到region中,大小为box
region.show()
如下图为box截取的图像区域显示。

### Paste类
>
> im.paste(image,box)
>
>
>
将一张图粘贴到另一张图像上。变量box或者是一个给定左上角的2元组,或者是定义了左,上,右和下像素坐标的4元组,或者为空(与(0,0)一样)。如果给定4元组,被粘贴的图像的尺寸必须与区域尺寸一样。如果模式不匹配,被粘贴的图像将被转换为当前图像的模式。
@zhangziju
from PIL import Image
im = Image.open(“E:\mywife.jpg”)
box=[0,0,100,100]
im_crop = im.crop(box)
print(im_crop.size,im_crop.mode)
im.paste(im_crop, (100,100)) ##(100,100,0,0)
im.paste(im_crop, (400,400,500,500))
im.show()
如下图为paste操作:

### Filter类
>
> im.filter(filter) ⇒ image
>
>
>
返回一个使用给定滤波器处理过的图像的拷贝。具体参考图像滤波在ImageFilter 模块的应用,在该模块中,预先定义了很多增强滤波器,可以通过filter( )函数使用,预定义滤波器包括:**BLUR、CONTOUR、DETAIL、EDGE\_ENHANCE、EDGE\_ENHANCE\_MORE、EMBOSS、FIND\_EDGES、SMOOTH、SMOOTH\_MORE、SHARPEN**。其中BLUR就是均值滤波,CONTOUR找轮廓,FIND\_EDGES边缘检测,使用该模块时,需先导入。
@zhangziju
from PIL import Image
from PIL import ImageFilter ## 调取ImageFilter
imgF = Image.open(“E:\mywife.jpg”)
bluF = imgF.filter(ImageFilter.BLUR) ##均值滤波
conF = imgF.filter(ImageFilter.CONTOUR) ##找轮廓
edgeF = imgF.filter(ImageFilter.FIND_EDGES) ##边缘检测
imgF.show()
bluF.show()
conF.show()
edgeF.show()
滤波处理下的gakki~

### Blend类
>
> Image.blend(image1,image2, alpha) ⇒ image
>
>
>
使用给定的两张图像及透明度变量alpha,插值出一张新的图像。这两张图像必须有一样的尺寸和模式。
>
> 合成公式为:out = image1 *(1.0 - alpha) + image2* alpha
>
>
>
若变量alpha为0.0,返回第一张图像的拷贝。若变量alpha为1.0,将返回第二张图像的拷贝。对变量alpha的值无限制。
@zhangziju
from PIL import Image
im1 = Image.open(“E:\mywife.jpg”)
im2 = Image.open(“E:\mywife2.jpg”)
print(im1.mode,im1.size)
print(im2.mode,im2.size)
im = Image.blend(im1, im2, 0.2)
im.show()
需保证两张图像的模式和大小是一致的,如下为显示im1和im2的具体信息。

im1和im2按照第一张80%的透明度,第二张20%的透明度,合成为一张。

### Split
>
> im.split() ⇒ sequence
>
>
>
返回当前图像各个通道组成的一个元组。例如,分离一个“RGB”图像将产生三个新的图像,分别对应原始图像的每个通道(红,绿,蓝)。
from PIL import Image
im = Image.open(“E:\mywife.jpg”)
r,g,b = im.split()
print(r.mode)
print(r.size)
print(im.size)

### Composite类
>
> Image.composite(image1,image2, mask) ⇒ image
>
>
>
复合类使用给定的两张图像及mask图像作为透明度,插值出一张新的图像。变量mask图像的模式可以为“1”,“L”或者“RGBA”。所有图像必须有相同的尺寸。
@zhangziju
from PIL import Image
im1 = Image.open(“E:\mywife.jpg”)
im2 = Image.open(“E:\mywife2.jpg”)
r,g,b = im1.split() ##分离出r,g,b
print(b.mode)
print(im1.mode,im1.size)
print(im2.mode,im2.size)
im = Image.composite(im1,im2,b)
im.show()
b.mode为”L”,两图尺寸一致。

最终效果

### Eval类
>
> Image.eval(image,function) ⇒ image
>
>
>
使用变量function对应的函数(该函数应该有一个参数)处理变量image所代表图像中的每一个像素点。如果变量image所代表图像有多个通道,那变量function对应的函数作用于**每一个通道**。注意:变量function对每个像素只处理一次,所以不能使用随机组件和其他生成器。
@zhangziju
from PIL import Image
im = Image.open(“E:\mywife.jpg”)
def fun01(x):
return x0.3
def fun02(y):
return y2.0
im1_eval = Image.eval(im, fun01)
im2_eval = Image.eval(im, fun02)
im1_eval.show()
im2_eval.show()
在函数fun01和fun02下的图像显示。

### Merge类
>
> Image.merge(mode,bands) ⇒ image
>
>
>
合并类使用一些单通道图像,创建一个新的图像。变量bands为一个图像的元组或者列表,每个通道的模式由变量mode描述。所有通道必须有相同的尺寸。
**变量mode与变量bands的关系:**
>
> len(ImageMode.getmode(mode).bands)= len(bands)
>
>
>
@zhangziju
from PIL import Image
im1 = Image.open(“E:\mywife.jpg”)
im2 = Image.open(“E:\mywife2.jpg”)
r1,g1,b1 = im1.split()
r2,g2,b2 = im2.split()
print(r1.mode,r1.size,g1.mode,g1.size)
print(r2.mode,r2.size,g2.mode,g2.size)
new_im=[r1,g2,b2]
print(len(new_im))
im_merge = Image.merge(“RGB”,new_im)
im_merge.show()
打印信息显示

merge操作

### Draft类
>
> im.draft(mode,size)
>
>
>
配置图像文件加载器,使得返回一个与给定的模式和尺寸尽可能匹配的图像的版本。
@zhangziju
from PIL import Image
im = Image.open(“E:\mywife.jpg”)
print(im.size,im.mode)
new_im = im.draft(“L”, (200,200))
print(new_im.size,new_im.mode)
new_im.show()
关键信息显示

转换效果

### Getbands类
>
> im.getbands()⇒ tuple of strings
>
>
>
返回包括每个通道名称的元组。例如,对于RGB图像将返回(“R”,“G”,“B”)。
@zhangziju
from PIL import Image
im = Image.open(“E:\mywife.jpg”)
print(im.getbands())

### Getbbox类
>
> im.getbbox() ⇒ 4-tuple or None
>
>
>
计算图像非零区域的包围盒。这个包围盒是一个4元组,定义了左、上、右和下像素坐标。如果图像是空的,这个方法将返回空。
@zhangziju
from PIL import Image
im = Image.open(“E:\mywife.jpg”)
print(im.getbbox())

### Getdata类
>
> im.getdata() ⇒ sequence
>
>
>
以包含像素值的sequence对象形式返回图像的内容。这个sequence对象是扁平的,以便第一行的值直接跟在第零行的值后面,等等。这个方法返回的sequence对象是PIL内部数据类型,它只支持某些sequence操作,包括迭代和基础sequence访问。使用list(im.getdata()),将它转换为普通的sequence。Sequence对象的每一个元素对应一个像素点的R、G和B三个值。
@zhangziju
from PIL import Image
im = Image.open(“E:\mywife.jpg”)
sequ = im.getdata()
sequ0 = list(sequ)
print(sequ0[0])
print(sequ0[1])
print(sequ0[2])
可视化显示sequence0里面的数据。
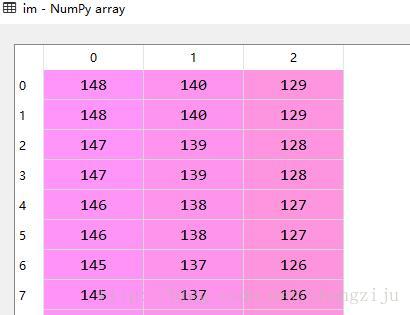
打印显示结果,与前面对比。

### Getextrema类
>
> im.getextrema() ⇒ 2-tuple
>
>
>
返回一个2元组,包括该图像中的最小和最大值。
@zhangziju
from PIL import Image
im = Image.open(“E:\mywife.jpg”)
print(im.getextrema())
该方法返回了R/G/B三个通道的最小和最大值的2元组。

## Getpixel类
>
> im.getpixel(xy) ⇒ value or tuple
>
>
>
返回给定位置的像素值。如果图像为多通道,则返回一个元组。**该方法执行比较慢;如果用户需要使用python处理图像中较大部分数据,可以使用像素访问对象(见load),或者方法getdata()。**
@zahngziju
from PIL import Image
im = Image.open(“E:\mywife.jpg”)
print(im.getpixel((0,0)))
print(im.getpixel((4,0)))
r,g,b = im.split()
print(b.getpixel((11,8)))

### Histogram类
>
> im.histogram()⇒ list
>
>
>
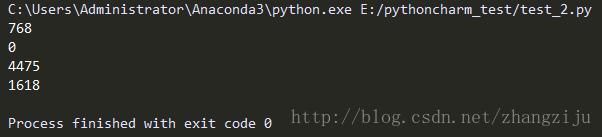
返回一个图像的直方图。这个直方图是关于像素数量的list,图像中的每个象素值对应一个成员。如果图像有多个通道,所有通道的直方图会连接起来(例如,“RGB”图像的直方图有768个值)。二值图像(模式为“1”)当作灰度图像(模式为“L”)处理。
@zhangziju
from PIL import Image
im = Image.open(“E:\mywife.jpg”)
imhis = im.histogram()
print(len(imhis))
print(imhis[0])
print(imhis[150])
print(imhis[300])
>
> im.histogram(mask)⇒ list
>
>
>
返回图像中模板图像非零地方的直方图。模板图像与处理图像的尺寸必须相同,并且要么是二值图像(模式为“1”),要么为灰度图像(模式为“L”)。
@zhangziju
from PIL import Image
im = Image.open(“E:\mywife.jpg”)
r,g,b = im.split()
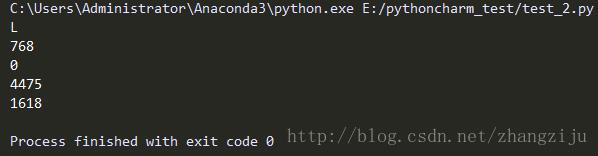
imhis = im.histogram()
print(r.mode)
print(len(imhis))
print(imhis[0])
print(imhis[150])
print(imhis[300])
### Load类
>
> im.load()
>
>
>
为图像分配内存并从文件中加载它(或者从源图像,对于懒操作)。正常情况下,用户不需要调用这个方法,因为在第一次访问图像时,Image类会自动地加载打开的图像。在1.1.6及以后的版本,方法**load()**返回一个用于读取和修改像素的像素访问对象。这个访问对象像一个二维队列,如:
>
> pix = im.load()
> print pix[x, y]
> pix[x, y] =value
>
>
>
通过这个对象访问比方法getpixel()和putpixel()快很多。
@zhangziju
from PIL import Image
im = Image.open(“E:\mywife.jpg”)
pix = im.load()
print(pix[0,2])

>
> im.paste(colour,box)
>
>
>
使用同一种颜色填充变量box对应的区域。对于单通道图像,变量colour为单个颜色值;对于多通道,则为一个元组。
@zhangziju
from PIL import Image
im = Image.open(“E:\mywife.jpg”)
im.paste((256,256,0),(0,0,100,100)) ##(256,256,0)表示黄色
im.show()

@zhangziju
from PIL import Image
im = Image.open(“E:\mywife.jpg”)
im.paste(“blue”,(0,0,100,100)) ##或者“blue”
im.show()

>
> im.paste(image,box, mask)
>
>
>
使用变量mask对应的模板图像来填充所对应的区域。可以使用模式为“1”、“L”或者“RGBA”的图像作为模板图像。模板图像的尺寸必须与变量image对应的图像尺寸一致。如果变量mask对应图像的值为255,则模板图像的值直接被拷贝过来;如果变量mask对应图像的值为0,则保持当前图像的原始值。变量mask对应图像的其他值,将对两张图像的值进行透明融合,**如果变量image对应的为“RGBA”图像,即粘贴的图像模式为“RGBA”,则alpha通道被忽略。用户可以使用同样的图像作为原图像和模板图像**。
@zhangziju
from PIL import Image
im = Image.open(“E:\mywife.jpg”)
box=[300,300,400,400]
im_crop =im.crop(box)
r,g,b =im_crop.split()
im.paste(im_crop, (200,200,300,300), r)
im.show()

### Putdata类
>
> im.putdata(data)
> im.putdata(data, scale, offset)
>
>
>
从sequence对象中拷贝数据到当前图像,从图像的左上角(0,0)位置开始。变量scale和offset用来调整sequence中的值:
>
> pixel = value\*scale + offset
>
>
>
如果变量scale忽略,则默认为1.0。如果变量offset忽略,则默认为0.0。
@zhangziju
from PIL import Image
im = Image.open(“E:\mywife.jpg”)
r, g, b = im.split()
print(
r.getpixel((0, 0)),
r.getpixel((1, 0)),
r.getpixel((2, 0)),
r.getpixel((3, 0)),
r.putdata([1, 2, 3, 4]),
r.getpixel((0, 0)),
r.getpixel((1, 0)),
r.getpixel((2, 0)),
r.getpixel((3, 0)),
)

### Resize类
>
> im.resize(size) ⇒ image
> im.resize(size, filter) ⇒ image
>
>
>
返回改变尺寸的图像的拷贝。变量size是所要求的尺寸,是一个二元组:(width, height)。变量filter为NEAREST、BILINEAR、BICUBIC或者ANTIALIAS之一。如果忽略,或者图像模式为“1”或者“P”,该变量设置为NEAREST。在当前的版本中bilinear和bicubic滤波器不能很好地适应大比例的下采样(例如生成缩略图)。用户需要使用ANTIALIAS,除非速度比质量更重要。
@zhangziju
from PIL import Image
im = Image.open(“E:\mywife.jpg”)
region = im.resize((400, 400)) ##重新设定大小
region.show()
很明显由于大小的重新设定,图片的显示效果有所转变,gakki依然美腻~

### Rotate类
>
> im.rotate(angle) ⇒ image
> im.rotate(angle,filter=NEAREST, expand=0) ⇒ image
>
>
>
返回一个按照给定角度顺时钟围绕图像中心旋转后的图像拷贝。变量filter是NEAREST、BILINEAR或者BICUBIC之一。如果省略该变量,或者图像模式为“1”或者“P”,则默认为NEAREST。变量expand,如果为true,表示输出图像足够大,可以装载旋转后的图像。如果为false或者缺省,则输出图像与输入图像尺寸一样大。
@zhangziju
from PIL import Image
im = Image.open(“E:\mywife.jpg”)
im_45 = im.rotate(45)
im_30 = im.rotate(30, Image.NEAREST,1)
print(im_45.size,im_30.size)
im_45.show()
im_30.show()


### Seek类
>
> im.seek(frame)
>
>
>
在给定的文件序列中查找指定的帧。如果查找超越了序列的末尾,则产生一个EOFError异常。当文件序列被打开时,PIL库自动指定到第0帧上。
@zhangziju
from PIL import Image
im_gif = Image.open(“E:\mywife.gif”)
print(im_gif.mode)
im_gif.show() ##第0帧
im_gif.seek(3)
im_gif.show()
im_gif.seek(9)
im_gif.show()
来来来~这是gakki原图欣赏下~

查找帧seek()的效果如下:

### Tell类
>
> im.tell() ⇒ integer
>
>
>
返回当前帧所处位置,从0开始计算。
@zhangziju
from PIL import Image
im_gif = Image.open(“E:\mywife.gif”)
print(im_gif.tell())
im_gif.seek(8)
print(im_gif.tell())

### Thumbnail类
>
> im.thumbnail(size)
> im.thumbnail(size, filter)
>
>
>
修改当前图像,使其包含一个自身的缩略图,该缩略图尺寸不大于给定的尺寸。这个方法会计算一个合适的缩略图尺寸,使其符合当前图像的宽高比,调用方法draft()配置文件读取器,最后改变图像的尺寸。变量filter应该是NEAREST、BILINEAR、BICUBIC或者ANTIALIAS之一。如果省略该变量,则默认为NEAREST。注意:在当前PIL的版本中,滤波器bilinear和bicubic不能很好地适应缩略图产生。用户应该使用ANTIALIAS,图像质量最好。如果处理速度比图像质量更重要,可以选用其他滤波器。这个方法在原图上进行修改。如果用户不想修改原图,可以使用方法copy()拷贝一个图像。这个方法返回空。
@zhangziju
from PIL import Image
im = Image.open(“E:\mywife.jpg”)
im.thumbnail((100,100))
### Transform类
>
> im.transform(size,method, data) ⇒ image
> im.transform(size, method, data, filter) ⇒ image
>
>
>
使用给定的尺寸生成一张新的图像,与原图有相同的模式,使用给定的转换方式将原图数据拷贝到新的图像中。在当前的PIL版本中,参数method为EXTENT(裁剪出一个矩形区域),AFFINE(仿射变换),QUAD(将正方形转换为矩形),MESH(一个操作映射多个正方形)或者PERSPECTIVE。变量filter定义了对原始图像中像素的滤波器。在当前的版本中,变量filter为NEAREST、BILINEAR、BICUBIC或者ANTIALIAS之一。如果忽略,或者图像模式为“1”或者“P”,该变量设置为NEAREST。
@zhangziju
from PIL import Image
im = Image.open(“E:\mywife.jpg”)
print(im.size)
imtra = im.transform((200, 200), Image.EXTENT, (0, 0, 500, 500))
print(imtra.size)
imtra.show()


>
> im.transform(size,EXTENT, data) ⇒ image
> im.transform(size, EXTENT, data, filter) ⇒ image
>
>
>
从图像中裁剪一个区域。变量data为指定输入图像中两个坐标点的4元组(x0,y0,x1,y1)。输出图像为这两个坐标点之间像素的采样结果。例如,如果输入图像的(x0,y0)为输出图像的(0,0)点,(x1,y1)则与变量size一样。这个方法可以用于在当前图像中裁剪,放大,缩小或者镜像一个任意的长方形。它比方法crop()稍慢,但是与resize操作一样快。
>
> im.transform(size, AFFINE, data) ⇒ image
> im.transform(size, AFFINE,data, filter) ⇒ image
>
>
>
对当前的图像进行仿射变换,变换结果体现在给定尺寸的新图像中。变量data是一个6元组(a,b,c,d,e,f),包含一个仿射变换矩阵的第一个两行。输出图像中的每一个像素(x,y),新值由输入图像的位置(ax+by+c, dx+ey+f)的像素产生,使用最接近的像素进行近似。这个方法用于原始图像的缩放、转换、旋转和裁剪。
@zhangziju
from PIL import Image
im = Image.open(“E:\mywife.jpg”)
print(im.size)
imtra = im.transform((200, 200), Image.AFFINE, (1,2,3,2,1,4))
print(imtra.size)
imtra.show()


>
> im.transform(size,QUAD, data) ⇒ image
> im.transform(size, QUAD, data, filter) ⇒ image
>
>
>
输入图像的一个四边形(通过四个角定义的区域)映射到给定尺寸的长方形。变量data是一个8元组(x0,y0,x1,y1,x2,y2,x3,y3),它包括源四边形的左上,左下,右下和右上四个角。
@zhangziju
from PIL import Image
im = Image.open(“E:\mywife.jpg”)
print(im.size)
imtra = im.transform((200, 200), Image.QUAD, (0,0,0,500,600,500,600,0))
print(imtra.size)
imtra.show()


>
> im.transform(size,PERSPECTIVE, data) ⇒ image
> im.transform(size, PERSPECTIVE, data, filter) ⇒ image
>
>
>
对当前图像进行透视变换,产生给定尺寸的新图像。变量data是一个8元组(a,b,c,d,e,f,g,h),包括一个透视变换的系数。对于输出图像中的每个像素点,新的值来自于输入图像的位置的(a x + b y + c)/(g x + h y + 1), (d x+ e y + f)/(g x + h y + 1)像素,使用最接近的像素进行近似。这个方法用于原始图像的2D透视。
@zhangziju
from PIL import Image
im = Image.open(“E:\mywife.jpg”)
print(im.size)
imtra = im.transform((200, 200), Image.PERSPECTIVE, (1,2,3,2,1,6,1,2))
print(imtra.size)
网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!















 684
684

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









