







主题模型(Topic Model)
以非监督学习的方式对文档中的隐含语义结构进行聚类的统计模型。
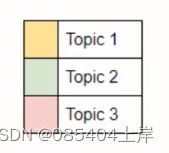 你可以从高亮的词语中总结出,这段话有三个主题"概念:主题 1、2、3。一个良好的主题模型可以识别出相似的语,并将它们放在一组或一个主题下。在上面的示例中,这段话最重要的主题是:主题 2 -- 表明这段文字主要是关于虚假视频的。在本实验中,将学习一种叫做‘ 主题建模’ 的文本挖掘方法。这是一种非常有用的提取主题的技术,在面对 NLP 挑战时你会经常使用到它。
你可以从高亮的词语中总结出,这段话有三个主题"概念:主题 1、2、3。一个良好的主题模型可以识别出相似的语,并将它们放在一组或一个主题下。在上面的示例中,这段话最重要的主题是:主题 2 -- 表明这段文字主要是关于虚假视频的。在本实验中,将学习一种叫做‘ 主题建模’ 的文本挖掘方法。这是一种非常有用的提取主题的技术,在面对 NLP 挑战时你会经常使用到它。
潜在语义分析(Topic Model)
潜在语义分析的目的是利用词语周国的上下文,以捕获隐藏的概念或主题,LSA 最初是用在语义检索上,为了解决一词多义和一义多词的问题。
为了能够解决解决一词多义和一义多词的问题,需要将词项 (Term)中的概念Concept 提取出来,建立一个语和概念的关联关系(T-C Relationship),这样一个文档就能表示成为概念的向量。在输入一段检索词之后,就可以先将检索词转换为概念,再通过概念去匹配文档。假设,我们有 m 篇文档,其中包含 n个唯一词项(单词)。我们希望从所有文档的文本数据中提取出 k 个主题。主题数 ,必须由用户给定。
- 首先,生成一个m*n维的文档-词项矩阵(Document-Term Matrix),矩阵元素为TF-IDF分数:
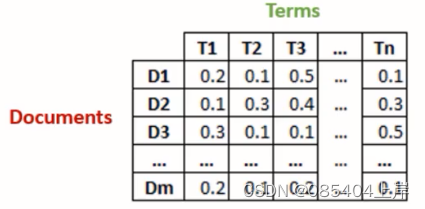
- 然后,我们使用奇异值分解(Singular Value Decomposition, SVD)把上述矩阵的维度降到 k (预期的主题数) 维:
- SVD 将一个矩阵分解为三个矩阵。假设我们利用 SVD 分解矩阵 A,我们会得到矩阵 U,矩阵 S 和矩阵 V 的转置

- 矩阵 U(Document-Term Matrix) 的每个行向量代表相应的文档。这些向量的长度是 k,是预期的主题数。
- 代表数据中词项的向量可以在矩阵 Vk(Term-Topic matrix) 中找到。
- 因此,SVD 为数据中的每篇文档和每个词项都提供了向量,每个向量的长度均为k。我们可以使用余孩相似度的方法通过这些向量找到相似的单词和文档。
总结:
潜在狄利克雷分配(LDA)
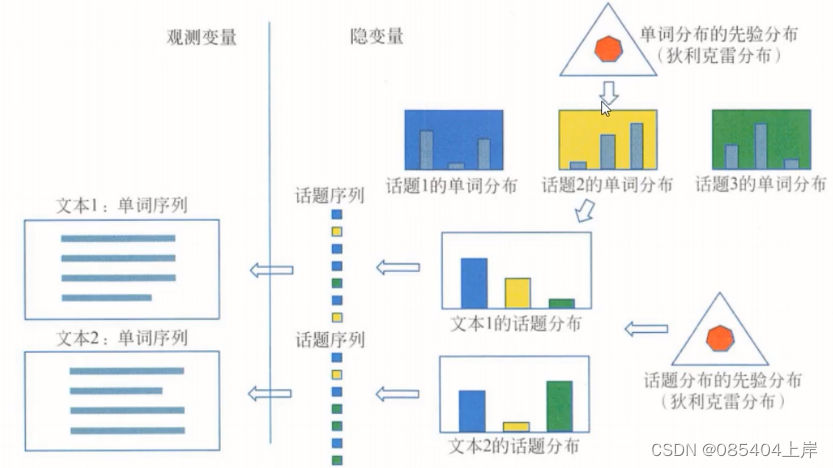
潜在狄利克雷分配(latent Dirichlet Alocation,LDA),作为基于贝叶斯学习的话题模型,是潜在语义分析、概率潜在语义分析的扩展,于 2002 年由 Blei等提出。LDA在文本数据挖掘、图像处理、生物信息处理等领域被广泛使用。
















 9081
9081

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









