







使用 requests 库的 get 方法请求网站内容,将其解码为文本形式,输出结果验证,完整的代码如下:
import requests
# 请求头,添加你的浏览器信息后才可以正常运行
headers= {
'User-Agent': '...',
'Cookie': '...',
'Host': 'www.365kk.cc',
'Connection': 'keep-alive'
}
# 小说主页
main_url = "http://www.365kk.cc/255/255036/"
# 使用get方法请求网页
main_resp = requests.get(main_url, headers=headers)
# 将网页内容按utf-8规范解码为文本形式
main_text = main_resp.content.decode('utf-8')
print(main_text)
运行代码前,需要向
headers中填入你自己浏览器的信息。
输出结果如下:
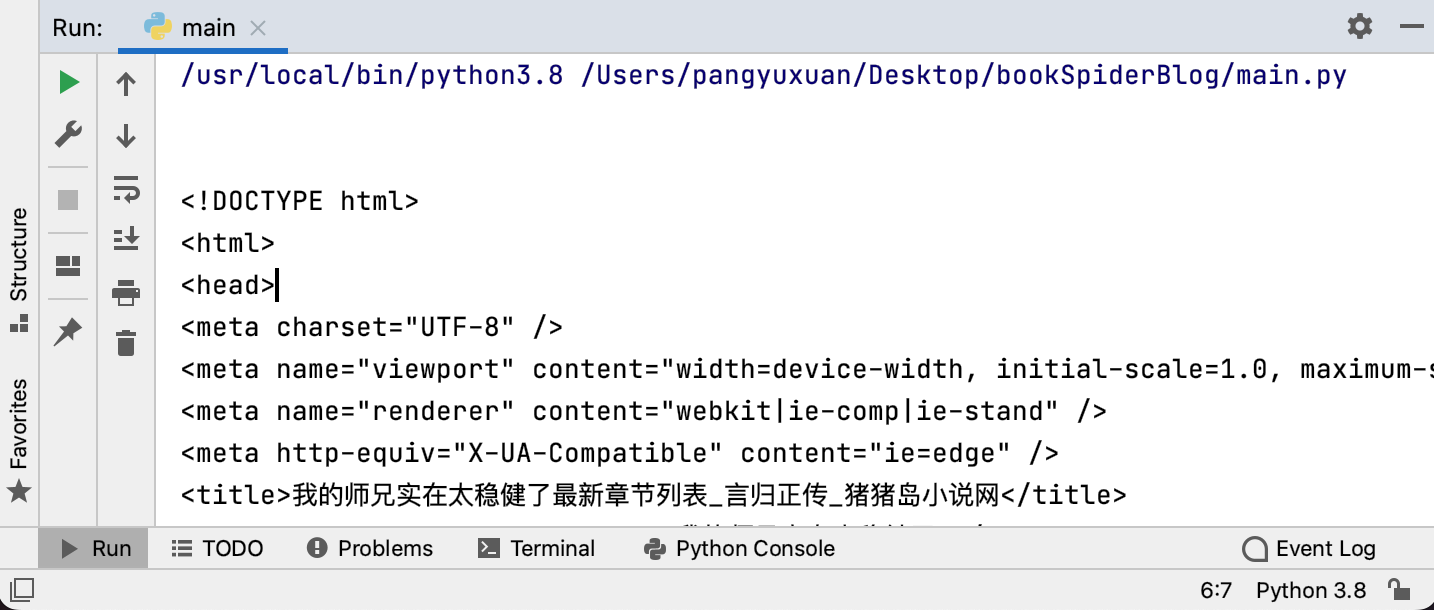
可以看出,我们成功请求到了网站内容,接下来只需对其进行解析,即可得到我们想要的部分。
解析网页内容
我们使用 lxml 库来解析网页内容,具体方法为将文本形式的网页内容创建为可解析的元素,再按照XPath路径访问其中的内容,代码如下:
import requests
from lxml import etree
# 请求头
headers= {
'User-Agent': '...',
'Cookie': '...',
'Host': 'www.365kk.cc',
'Connection': 'keep-alive'
}
# 小说主页
main_url = "http://www.365kk.cc/255/255036/"
# 使用get方法请求网页
main_resp = requests.get(main_url, headers=headers)
# 将网页内容按utf-8规范解码为文本形式
main_text = main_resp.content.decode('utf-8')
# 将文本内容创建为可解析元素
main_html = etree.HTML(main_text)
# 依次获取书籍的标题、作者、最近更新时间和简介
# main\_html.xpath返回的是列表,因此需要加一个[0]来表示列表中的首个元素
bookTitle = main_html.xpath('/html/body/div[4]/div[1]/div/div/div[2]/div[1]/h1/text()')[0]
author = main_html.xpath('/html/body/div[4]/div[1]/div/div/div[2]/div[1]/div/p[1]/text()')[0]
update = main_html.xpath('/html/body/div[4]/div[1]/div/div/div[2]/div[1]/div/p[5]/text()')[0]
introduction = main_html.xpath('/html/body/div[4]/div[1]/div/div/div[2]/div[2]/text()')[0]
# 输出结果以验证
print(bookTitle)
print(author)
print(update)
print(introduction)
输出结果如下:
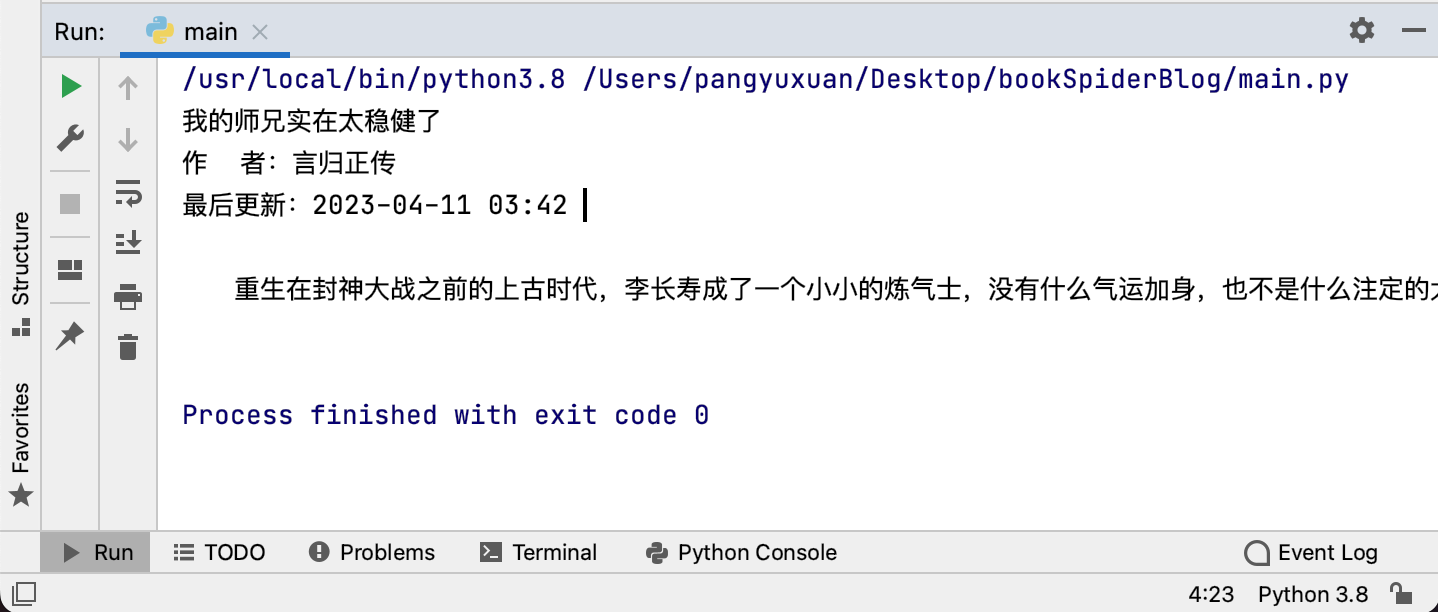
至此,我们已经学会了基本的网页请求方法,并学会了如何获取目标页面中的特定内容。
正文爬取与解析
接下来,我们开始爬取正文。首先尝试获取单个页面的数据,再尝试设计一个循环,依次获取所有正文数据。
单个页面数据的获取
以第一章为例,链接:http://www.365kk.cc/255/255036/4147599.html,获取章节标题和正文的XPath路径如下:
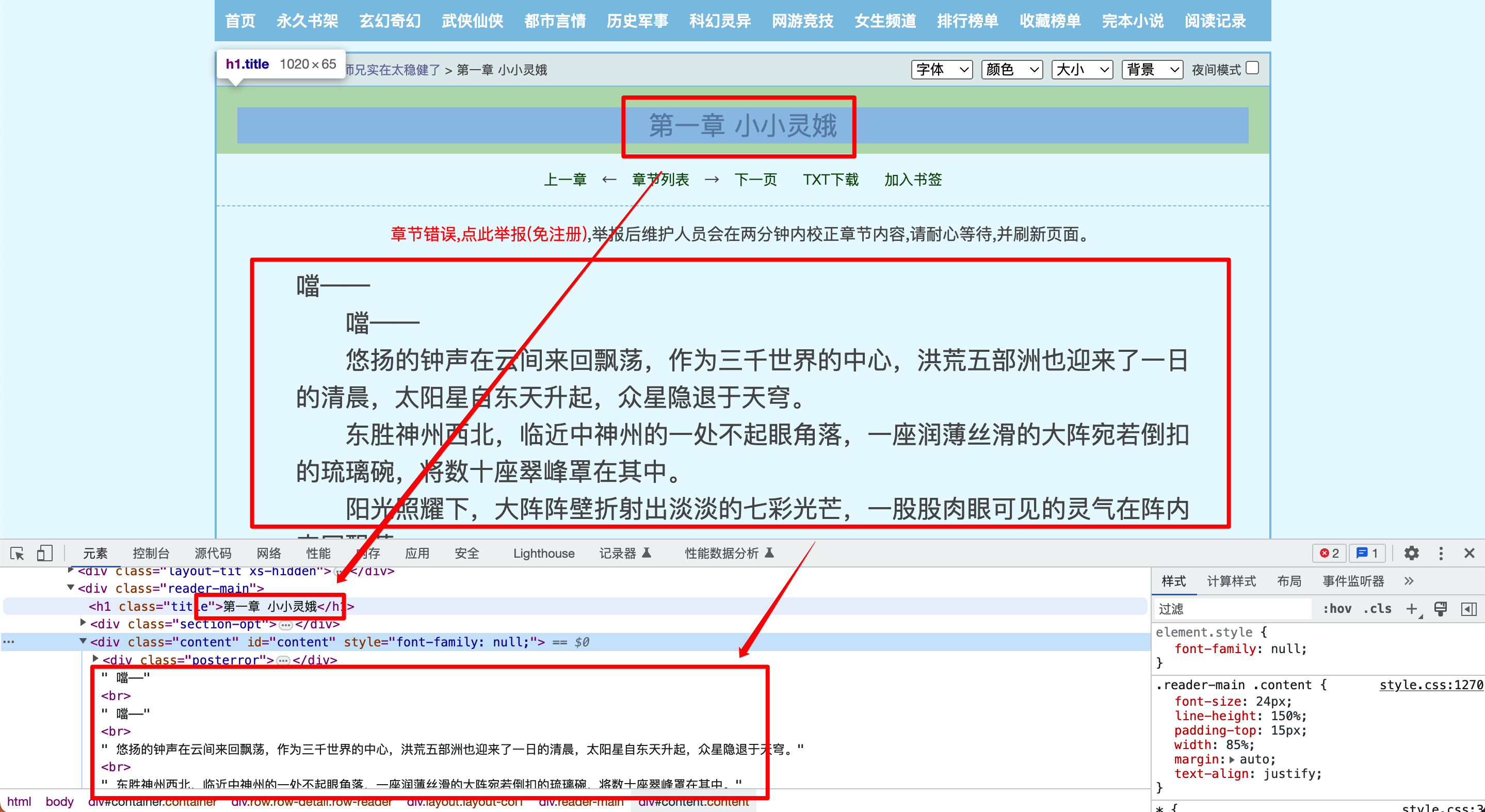
//*[@id="container"]/div/div/div[2]/h1/text()
//*[@id="content"]/text()
按照与上文一致的方法请求并解析网页内容,代码如下:
import requests
from lxml import etree
# 请求头
headers= {
'User-Agent': '...',
'Cookie': '...',
'Host': 'www.365kk.cc',
'Connection': 'keep-alive'
}
# ...
# 上一部分的代码
# ...
# 当前页面链接
url = 'http://www.365kk.cc/255/255036/4147599.html'
resp = requests.get(url, headers)
text = resp.content.decode('utf-8')
html = etree.HTML(text)
title = html.xpath('//\*[@id="container"]/d 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1967
1967

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









