






前言
最近学了一点python,想着搞个爬虫练一下手,记录一下学习过程
基于requests库和lxml库编写的爬虫
借鉴于python爬虫实战——小说爬取
讲的很详细且易懂
本文的例子只是在其基础上补充一下,可先看了上面的再回来看这里,更容易理解
主体
本文记载了两个本人练手的爬虫,爬取的网站分别是:
1.http://www.365kk.cc/
2.某小说网站(跟1差不多,但存在一个坑)Exception has occurred: IndexError list index out of range File “D:\Desktop\vscode\python\biquge_book.py”, line 111, in bookTitle=main_html.xpath(‘/html/body/div[5]/div[2]/h1/text()’)[0] IndexError: list index out of range
1.借鉴和补充后的源码
import os
import requests
from lxml import etree
import time
import random
# 获取下一页链接的函数
def next_url(next_url_element):
nxturl = 'http://www.365kk.cc/255/255036/'
# rfind('/') 获取最后一个'/'字符的索引
index = next_url_element.rfind('/') + 1
nxturl += next_url_element[index:]
return nxturl
# 数据清洗函数
def clean_data(filename, info,output_folder):
"""
:param filename: 原文档名
:param info: [bookTitle, author, update, introduction]
"""
print("\n==== 数据清洗开始 ====")
# 新的文件名
btitle ="new"+info[0]+".txt"
#new_filename ="new"+filename
#保存到文件夹里
new_filename = f"{output_folder}/{btitle}"
# 打开两个文本文档
f_old = open(filename, 'r', encoding='utf-8')
f_new = open(new_filename, 'w', encoding='utf-8')
# 首先在新的文档中写入书籍信息
f_new.write('== 《' + info[0] + '》\r\n') # 标题
f_new.write('== ' + info[1] + '\r\n') # 作者
f_new.write('== ' + info[2] + '\r\n') # 最后更新时间
f_new.write("=" * 10)
f_new.write('\r\n')
f_new.write('== ' + info[3] + '\r\n') # 简介
f_new.write("=" * 10)
f_new.write('\r\n')
lines = f_old.readlines() # 按行读取原文档中的内容
empty_cnt = 0 # 用于记录连续的空行数
# 遍历原文档中的每行
for line in lines:
if line == '\n': # 如果当前是空行
empty_cnt += 1 # 连续空行数+1
if empty_cnt >= 2: # 如果连续空行数不少于2
continue # 直接读取下一行,当前空行不写入
else: # 如果当前不是空行
empty_cnt = 0 # 连续空行数清零
if line.startswith("\u3000\u3000"): # 如果有段首缩进
line = line[2:] # 删除段首缩进
f_new.write(line) # 写入当前行
elif line.startswith("第"): # 如果当前行是章节标题
f_new.write("\r\n") # 写入换行
f_new.write("-" * 20) # 写入20个'-'
f_new.write("\r\n") # 写入换行
f_new.write(line) # 写入章节标题
else: # 如果当前行是未缩进的普通段落
f_new.write(line) # 保持原样写入
f_old.close()
f_new.close()
print(f"\n==== 数据清洗完成,新文件已保存到 {new_filename} ====")
"""
# 请求头,使用前需填入自己浏览器的信息
headers= {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/119.0.0.0 Safari/537.36 Edg/119.0.0.0',
'Cookie': 'fontFamily=null; fontColor=null; fontSize=null; bg=null; ASP.NET_SessionId=2xgsi3yqhveljdny3gp4vvox; bookid=255036; booklist=%257B%2522BookId%2522%253A255036%252C%2522ChapterId%2522%253A4147599%252C%2522ChapterName%2522%253A%2522%25u7B2C%25u4E00%25u7AE0%2520%25u5C0F%25u5C0F%25u7075%25u5A25%2522%257D',
'Host': 'www.365kk.cc',
'Connection': 'keep-alive'
}
"""
'''
#反爬
headers_list = [
{
'user-agent': 'Mozilla/5.0 (iPhone; CPU iPhone OS 13_2_3 like Mac OS X) AppleWebKit/605.1.15 (KHTML, like Gecko) Version/13.0.3 Mobile/15E148 Safari/604.1'
}, {
'user-agent': 'Mozilla/5.0 (Linux; Android 8.0.0; SM-G955U Build/R16NW) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.141 Mobile Safari/537.36'
}, {
'user-agent': 'Mozilla/5.0 (Linux; Android 10; SM-G981B) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.162 Mobile Safari/537.36'
}, {
'user-agent': 'Mozilla/5.0 (iPad; CPU OS 13_3 like Mac OS X) AppleWebKit/605.1.15 (KHTML, like Gecko) CriOS/87.0.4280.77 Mobile/15E148 Safari/604.1'
}, {
'user-agent': 'Mozilla/5.0 (Linux; Android 8.0; Pixel 2 Build/OPD3.170816.012) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/102.0.0.0 Mobile Safari/537.36'
}, {
'user-agent': 'Mozilla/5.0 (Linux; Android) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/88.0.4324.109 Safari/537.36 CrKey/1.54.248666'
}, {
'user-agent': 'Mozilla/5.0 (X11; Linux aarch64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/88.0.4324.188 Safari/537.36 CrKey/1.54.250320'
}, {
'user-agent': 'Mozilla/5.0 (BB10; Touch) AppleWebKit/537.10+ (KHTML, like Gecko) Version/10.0.9.2372 Mobile Safari/537.10+'
}, {
'user-agent': 'Mozilla/5.0 (PlayBook; U; RIM Tablet OS 2.1.0; en-US) AppleWebKit/536.2+ (KHTML like Gecko) Version/7.2.1.0 Safari/536.2+'
}, {
'user-agent': 'Mozilla/5.0 (Linux; U; Android 4.3; en-us; SM-N900T Build/JSS15J) AppleWebKit/534.30 (KHTML, like Gecko) Version/4.0 Mobile Safari/534.30'
}, {
'user-agent': 'Mozilla/5.0 (Linux; U; Android 4.1; en-us; GT-N7100 Build/JRO03C) AppleWebKit/534.30 (KHTML, like Gecko) Version/4.0 Mobile Safari/534.30'
}, {
'user-agent': 'Mozilla/5.0 (Linux; U; Android 4.0; en-us; GT-I9300 Build/IMM76D) AppleWebKit/534.30 (KHTML, like Gecko) Version/4.0 Mobile Safari/534.30'
}, {
'user-agent': 'Mozilla/5.0 (Linux; Android 7.0; SM-G950U Build/NRD90M) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/62.0.3202.84 Mobile Safari/537.36'
}, {
'user-agent': 'Mozilla/5.0 (Linux; Android 8.0.0; SM-G965U Build/R16NW) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.111 Mobile Safari/537.36'
}, {
'user-agent': 'Mozilla/5.0 (Linux; Android 8.1.0; SM-T837A) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.80 Safari/537.36'
}, {
'user-agent': 'Mozilla/5.0 (Linux; U; en-us; KFAPWI Build/JDQ39) AppleWebKit/535.19 (KHTML, like Gecko) Silk/3.13 Safari/535.19 Silk-Accelerated=true'
}, {
'user-agent': 'Mozilla/5.0 (Linux; U; Android 4.4.2; en-us; LGMS323 Build/KOT49I.MS32310c) AppleWebKit/537.36 (KHTML, like Gecko) Version/4.0 Chrome/102.0.0.0 Mobile Safari/537.36'
}, {
'user-agent': 'Mozilla/5.0 (Windows Phone 10.0; Android 4.2.1; Microsoft; Lumia 550) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/46.0.2486.0 Mobile Safari/537.36 Edge/14.14263'
}, {
'user-agent': 'Mozilla/5.0 (Linux; Android 6.0.1; Moto G (4)) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/102.0.0.0 Mobile Safari/537.36'
}, {
'user-agent': 'Mozilla/5.0 (Linux; Android 6.0.1; Nexus 10 Build/MOB31T) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/102.0.0.0 Safari/537.36'
}, {
'user-agent': 'Mozilla/5.0 (Linux; Android 4.4.2; Nexus 4 Build/KOT49H) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/102.0.0.0 Mobile Safari/537.36'
}, {
'user-agent': 'Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/102.0.0.0 Mobile Safari/537.36'
}, {
'user-agent': 'Mozilla/5.0 (Linux; Android 8.0.0; Nexus 5X Build/OPR4.170623.006) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/102.0.0.0 Mobile Safari/537.36'
}, {
'user-agent': 'Mozilla/5.0 (Linux; Android 7.1.1; Nexus 6 Build/N6F26U) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/102.0.0.0 Mobile Safari/537.36'
}, {
'user-agent': 'Mozilla/5.0 (Linux; Android 8.0.0; Nexus 6P Build/OPP3.170518.006) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/102.0.0.0 Mobile Safari/537.36'
}, {
'user-agent': 'Mozilla/5.0 (Linux; Android 6.0.1; Nexus 7 Build/MOB30X) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/102.0.0.0 Safari/537.36'
}, {
'user-agent': 'Mozilla/5.0 (compatible; MSIE 10.0; Windows Phone 8.0; Trident/6.0; IEMobile/10.0; ARM; Touch; NOKIA; Lumia 520)'
}, {
'user-agent': 'Mozilla/5.0 (MeeGo; NokiaN9) AppleWebKit/534.13 (KHTML, like Gecko) NokiaBrowser/8.5.0 Mobile Safari/534.13'
}, {
'user-agent': 'Mozilla/5.0 (Linux; Android 9; Pixel 3 Build/PQ1A.181105.017.A1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/66.0.3359.158 Mobile Safari/537.36'
}, {
'user-agent': 'Mozilla/5.0 (Linux; Android 10; Pixel 4) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.138 Mobile Safari/537.36'
}, {
'user-agent': 'Mozilla/5.0 (Linux; Android 11; Pixel 3) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/88.0.4324.181 Mobile Safari/537.36'
}, {
'user-agent': 'Mozilla/5.0 (Linux; Android 5.0; SM-G900P Build/LRX21T) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/102.0.0.0 Mobile Safari/537.36'
}, {
'user-agent': 'Mozilla/5.0 (Linux; Android 8.0; Pixel 2 Build/OPD3.170816.012) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/102.0.0.0 Mobile Safari/537.36'
}, {
'user-agent': 'Mozilla/5.0 (Linux; Android 8.0.0; Pixel 2 XL Build/OPD1.170816.004) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/102.0.0.0 Mobile Safari/537.36'
}, {
'user-agent': 'Mozilla/5.0 (iPhone; CPU iPhone OS 10_3_1 like Mac OS X) AppleWebKit/603.1.30 (KHTML, like Gecko) Version/10.0 Mobile/14E304 Safari/602.1'
}, {
'user-agent': 'Mozilla/5.0 (iPhone; CPU iPhone OS 13_2_3 like Mac OS X) AppleWebKit/605.1.15 (KHTML, like Gecko) Version/13.0.3 Mobile/15E148 Safari/604.1'
}, {
'user-agent': 'Mozilla/5.0 (iPad; CPU OS 11_0 like Mac OS X) AppleWebKit/604.1.34 (KHTML, like Gecko) Version/11.0 Mobile/15A5341f Safari/604.1'
}
]
'''
#headers = random.choice(headers_list)
headers= {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/119.0.0.0 Safari/537.36 Edg/119.0.0.0',
'Cookie': 'fontFamily=null; fontColor=null; fontSize=null; bg=null; ASP.NET_SessionId=2xgsi3yqhveljdny3gp4vvox; bookid=255036; booklist=%257B%2522BookId%2522%253A255036%252C%2522ChapterId%2522%253A4147599%252C%2522ChapterName%2522%253A%2522%25u7B2C%25u4E00%25u7AE0%2520%25u5C0F%25u5C0F%25u7075%25u5A25%2522%257D',
'Host': 'www.365kk.cc',
'Connection': 'keep-alive'
}
#headers['user-agent'] = random.choice(headers_list)['user-agent']
file = input('请建立一个存储图片的文件夹,输入文件夹名称即可: ')
y = os.path.exists(file)
if y == 1:
#print('文件夹已存在')
#file = input('请建立一个存储图片的文件夹,)输入文件夹名称即可: ')
#os.mkdir(file)
print('文件夹已存在,将保存进其中')
else:
os.mkdir(file)
print('文件夹不存在,已创建')
folder=file+'/'
# 小说主页
main_url = "http://www.365kk.cc/255/255036/"
# 使用get方法请求网页
main_resp = requests.get(main_url, headers=headers)
# 将网页内容按utf-8规范解码为文本形式
main_text = main_resp.content.decode('utf-8')
# 将文本内容创建为可解析元素
main_html = etree.HTML(main_text)
#bookTitle = main_html.xpath('/html/body/div[4]/div[1]/div/div/div[2]/div[1]/h1/text()')[0]
bookTitle =main_html.xpath('/html/body/div[3]/div[1]/div/div/div[2]/div[1]/h1/text()')[0]
#author = main_html.xpath('/html/body/div[4]/div[1]/div/div/div[2]/div[1]/div/p[1]/text()')[0]
author =main_html.xpath('/html/body/div[3]/div[1]/div/div/div[2]/div[1]/div/p[1]/text()')[0]
#update = main_html.xpath('/html/body/div[4]/div[1]/div/div/div[2]/div[1]/div/p[5]/text()')[0]
#introduction = main_html.xpath('/html/body/div[4]/div[1]/div/div/div[2]/div[2]/text()')[0]
update=main_html.xpath('/html/body/div[3]/div[1]/div/div/div[2]/div[1]/div/p[5]/text()')[0]
introduction=main_html.xpath('/html/body/div[3]/div[1]/div/div/div[2]/div[2]/text()')[0]
# 调试期间仅爬取六个页面
maxPages = 767
cnt = 0
# 记录上一章节的标题
lastTitle = ''
# 爬取起点
url = 'http://www.365kk.cc/255/255036/4147599.html'
# 爬取终点
#endurl = 'http://www.365kk.cc/255/255036/4148385.html'
#while url != endurl:
while True:
cnt += 1 # 记录当前爬取的页面
if cnt > maxPages:
break # 当爬取的页面数超过maxPages时停止
#resp = requests.get(url, headers)
try:
resp = requests.get(url, headers) # 超时设置为10秒
except:
for i in range(4): # 循环去请求网站
resp = requests.get(url, headers=headers, timeout=20)
if resp.status_code == 200:
break
text = resp.content.decode('utf-8')
html = etree.HTML(text)
title = html.xpath('//*[@class="title"]/text()')[0]
contents = html.xpath('//*[@id="content"]/text()')
# 输出爬取进度信息
print("cnt: {}, title = {}, url = {}".format(cnt, title, url))
#print(contents)
file_name = f"{folder}/{bookTitle}"
#file_name=bookTitle+'.txt'
#with open(bookTitle + '.txt', 'a', encoding='utf-8') as f_new:
with open(file_name + '.txt', 'a', encoding='utf-8') as f_new:
if title != lastTitle: # 章节标题改变
f_new.write(title) # 写入新的章节标题
lastTitle = title # 更新章节标题
for content in contents:
f_new.write(content)
f_new.write('\n\n')
f_new.close( )
# 获取"下一页"按钮指向的链接
next_url_element = html.xpath('//*[@class="section-opt m-bottom-opt"]/a[3]/@href')[0]
# 传入函数next_url得到下一页链接
url = next_url(next_url_element)
sleepTime = random.randint(2, 6) # 产生一个2~5之间的随机数
time.sleep(sleepTime) # 暂停2~5之间随机的秒数
clean_data(file_name + '.txt', [bookTitle, author, update, introduction],file+"/")
print("complete!")
2.笔趣阁(改编)
获取xpath路径
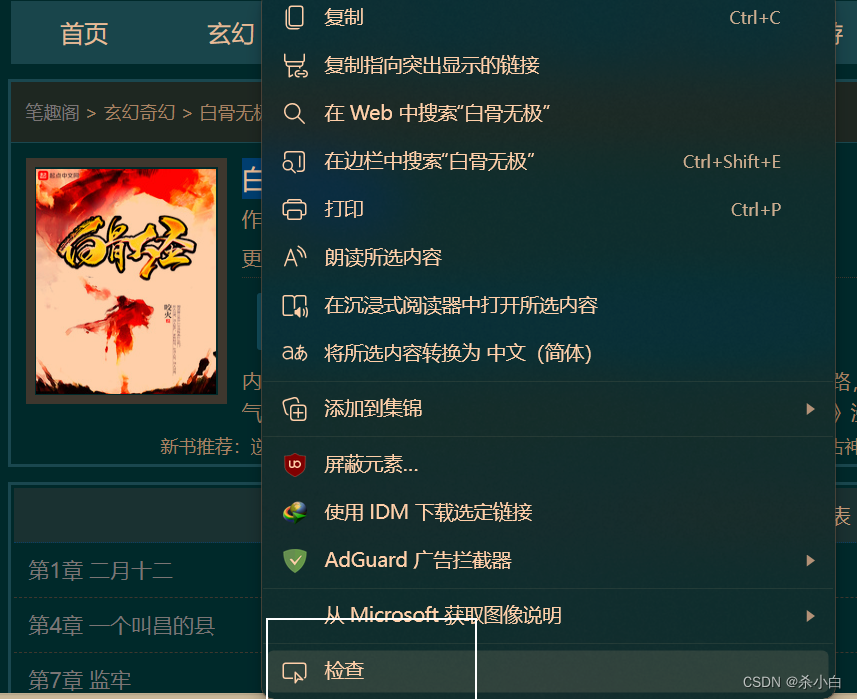
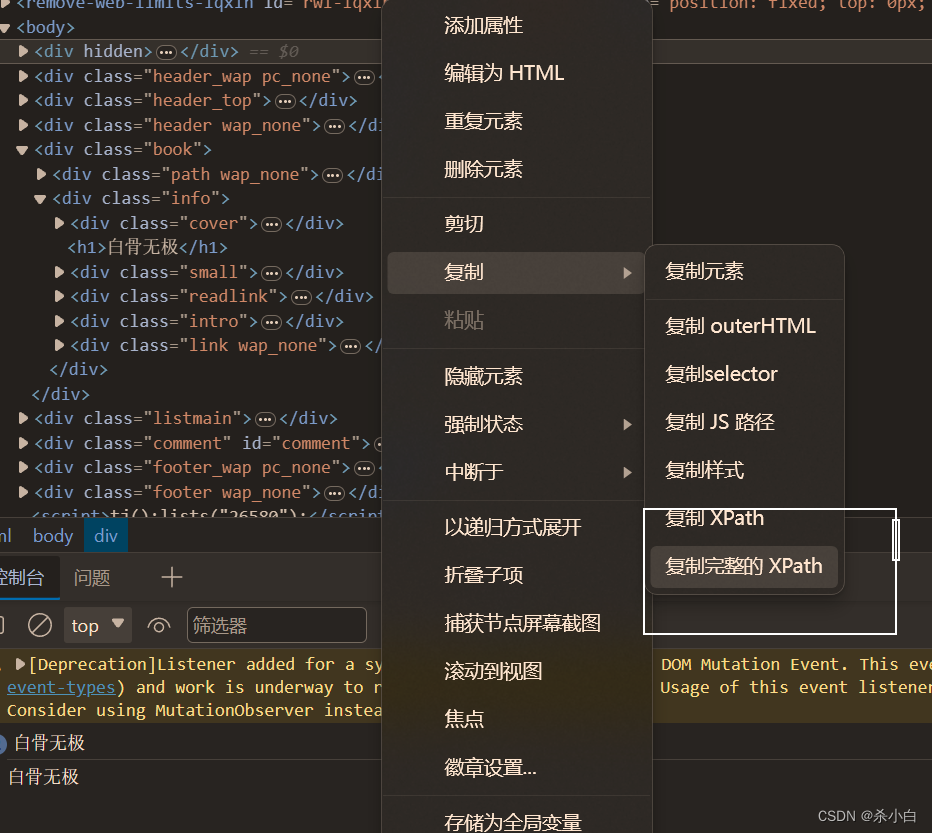
路径 报错
如果正确按照以上操作获取xpath路径,却报错:
Exception has occurred: IndexError list index out of range File “D:\Desktop\vscode\python\biquge_book.py”, line 111, in bookTitle=main_html.xpath(‘/html/body/div[5]/div[2]/h1/text()’)[0] IndexError: list index out of range
就要去仔细看一下网页源代码,看有没有啥陷阱了
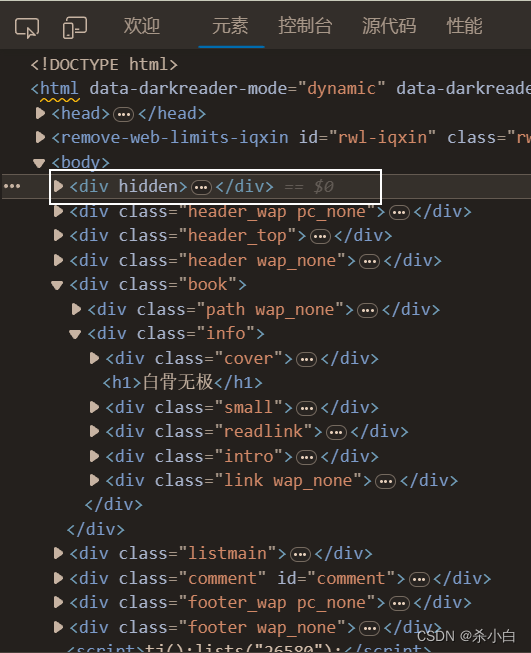
比如图上的框住的这个东西就会导致程序报错:
解决方法
服务器在返回response浏览器渲染时有时候会加上一些特殊的标签,查看源代码看不出来,导致xpath取值 为空,需print()打印出来才可以看出来!
小说主页
main_url = "https://www.bige3.cc/book/26580/"
使用get方法请求网页
main_resp = requests.get(main_url, headers=headers)
将网页内容按utf-8规范解码为文本形式
main_text = main_resp.content.decode('utf-8')
调试用
print(main_text)
打印出来后就可以对照着网页源代码,找出错误原因了
我就是在仔细看了一遍后才发现

这东西貌似没有传给程序,导致出错
知道了原因,就很容易的解决问题了
先正常获取xpath路径
再根据打印内容更改
修改前
bookTitle=main_html.xpath(‘/html/body/div[5]/div[2]/h1/text()’)[0]
修改后
bookTitle=main_html.xpath(‘/html/body/div[4]/div[2]/h1/text()’)[0]
很明显,改个数字就行了
import os
import requests
from lxml import etree
import time
import random
# 获取下一页链接的函数
def next_url(next_url_element):
#nxturl = 'http://www.365kk.cc/255/255036/'
nxturl='https://www.bige3.cc/book/66/'
# rfind('/') 获取最后一个'/'字符的索引
index = next_url_element.rfind('/') + 1
nxturl += next_url_element[index:]
return nxturl
# 数据清洗函数
def clean_data(filename, info,output_folder):
"""
:param filename: 原文档名
:param info: [bookTitle, author, update, introduction]
"""
print("\n==== 数据清洗开始 ====")
# 新的文件名
btitle ="new"+info[0]+".txt"
#new_filename ="new"+filename
#保存到文件夹里
new_filename = f"{output_folder}/{btitle}"
# 打开两个文本文档
f_old = open(filename, 'r', encoding='utf-8')
f_new = open(new_filename, 'w', encoding='utf-8')
# 首先在新的文档中写入书籍信息
f_new.write('== 《' + info[0] + '》\r\n') # 标题
f_new.write('== ' + info[1] + '\r\n') # 作者
f_new.write('== ' + info[2] + '\r\n') # 最后更新时间
f_new.write("=" * 10)
f_new.write('\r\n')
f_new.write('== ' + info[3] + '\r\n') # 简介
f_new.write("=" * 10)
f_new.write('\r\n')
lines = f_old.readlines() # 按行读取原文档中的内容
empty_cnt = 0 # 用于记录连续的空行数
# 遍历原文档中的每行
for line in lines:
if line == '\n': # 如果当前是空行
empty_cnt += 1 # 连续空行数+1
if empty_cnt >= 2: # 如果连续空行数不少于2
continue # 直接读取下一行,当前空行不写入
else: # 如果当前不是空行
empty_cnt = 0 # 连续空行数清零
if line.startswith("\u3000\u3000"): # 如果有段首缩进
line = line[2:] # 删除段首缩进
f_new.write(line) # 写入当前行
elif line.startswith("第"): # 如果当前行是章节标题
f_new.write("\r\n") # 写入换行
f_new.write("-" * 20) # 写入20个'-'
f_new.write("\r\n") # 写入换行
f_new.write(line) # 写入章节标题
else: # 如果当前行是未缩进的普通段落
f_new.write(line) # 保持原样写入
f_old.close()
f_new.close()
print(f"\n==== 数据清洗完成,新文件已保存到 {new_filename} ====")
# 请求头,使用前需填入自己浏览器的信息
headers= {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/119.0.0.0 Safari/537.36 Edg/119.0.0.0',
'Cookie': 'hm=0614940c5550f8dc77073d3a2be486aa',
#'Host': '',
'Connection': 'keep-alive'
}
file = input('请建立一个存储图片的文件夹,输入文件夹名称即可: ')
y = os.path.exists(file)
if y == 1:
#print('文件夹已存在')
#file = input('请建立一个存储图片的文件夹,)输入文件夹名称即可: ')
#os.mkdir(file)
print('文件夹已存在,将保存进其中')
else:
os.mkdir(file)
print('文件夹不存在,已创建')
folder=file+'/'
# 小说主页
main_url = "https://www.bige3.cc/book/26580/"
# 使用get方法请求网页
main_resp = requests.get(main_url, headers=headers)
# 将网页内容按utf-8规范解码为文本形式
main_text = main_resp.content.decode('utf-8')
#调试用
#print(main_text)
# 将文本内容创建为可解析元素
main_html = etree.HTML(main_text)
#bookTitle = main_html.xpath('/html/body/div[4]/div[1]/div/div/div[2]/div[1]/h1/text()')[0]
bookTitle=main_html.xpath('/html/body/div[4]/div[2]/h1/text()')[0]
#author = main_html.xpath('/html/body/div[4]/div[1]/div/div/div[2]/div[1]/div/p[1]/text()')[0]
author =main_html.xpath('/html/body/div[4]/div[2]/div[2]/span[1]/text()')[0]
#update = main_html.xpath('/html/body/div[4]/div[1]/div/div/div[2]/div[1]/div/p[5]/text()')[0]
#introduction = main_html.xpath('/html/body/div[4]/div[1]/div/div/div[2]/div[2]/text()')[0]
update=main_html.xpath('/html/body/div[4]/div[2]/div[2]/span[3]/text()')[0]
introduction=main_html.xpath('/html/body/div[4]/div[2]/div[4]/dl/dd/text()')[0]
# 调试期间仅爬取六个页面
maxPages = 6
cnt = 0
# 记录上一章节的标题
lastTitle = ''
# 爬取起点
url = 'https://www.bige3.cc/book/26580/1.html'
# 爬取终点
endurl = 'https://www.bige3.cc/book/26580/6.html'
#while url != endurl:
while True:
cnt += 1 # 记录当前爬取的页面
if cnt > maxPages:
break # 当爬取的页面数超过maxPages时停止
resp = requests.get(url, headers)
text = resp.content.decode('utf-8')
html = etree.HTML(text)
title = html.xpath('//*[@class="wap_none"]/text()')[0]
contents = html.xpath('//*[@id="chaptercontent"]/text()')
# 输出爬取进度信息
print("cnt: {}, title = {}, url = {}".format(cnt, title, url))
print(contents)
file_name = f"{folder}/{bookTitle}"
#file_name=bookTitle+'.txt'
#with open(bookTitle + '.txt', 'a', encoding='utf-8') as f_new:
with open(file_name + '.txt', 'a', encoding='utf-8') as f_new:
if title != lastTitle: # 章节标题改变
f_new.write(title) # 写入新的章节标题
lastTitle = title # 更新章节标题
for content in contents:
f_new.write(content)
f_new.write('\n\n')
f_new.close( )
# 获取"下一页"按钮指向的链接
next_url_element = html.xpath('//*[@class="Readpage pagedown"]/a[3]/@href')[0]
# 传入函数next_url得到下一页链接
url = next_url(next_url_element)
sleepTime = random.randint(2, 6) # 产生一个2~5之间的随机数
time.sleep(sleepTime) # 暂停2~5之间随机的秒数
clean_data(file_name + '.txt', [bookTitle, author, update, introduction],file+"/")
print("complete!")
收尾
全部源码
已传到仓库,
我的github仓库
我的gitee仓库https://gitee.com/aa2255/smalltask


















 3172
3172

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











