










基于python的抖音短视频数据分析与可视化
一、前言
抖音是一个非常流行的短视频平台,每天都有大量的用户在抖音上分享和观看视频。为了更好地了解抖音用户的行为和兴趣,我们可以使用Python进行数据分析与可视化。
在本文中,我们将介绍如何使用Python进行抖音数据分析与可视化。首先,我们将使用Python获取抖音的数据,然后使用pandas和matplotlib等库对数据进行可视化。
1.数据获取
抖音的数据可以通过API接口获取。我们可以使用Python的requests库来发送HTTP请求,获取抖音的数据。
2..数据可视化
处理完数据后,我们可以使用matplotlib等库对数据进行可视化。例如,可以使用matplotlib绘制条形图、饼图、折线图等。
3.可视化结果分析
通过可视化结果,我们可以分析抖音用户的行为和兴趣。例如,可以分析用户关注的人的类型、观看的视频类型等。
二、数据获取
数据来自于第三方监测,一共是有5000+抖音大V的数据信息。
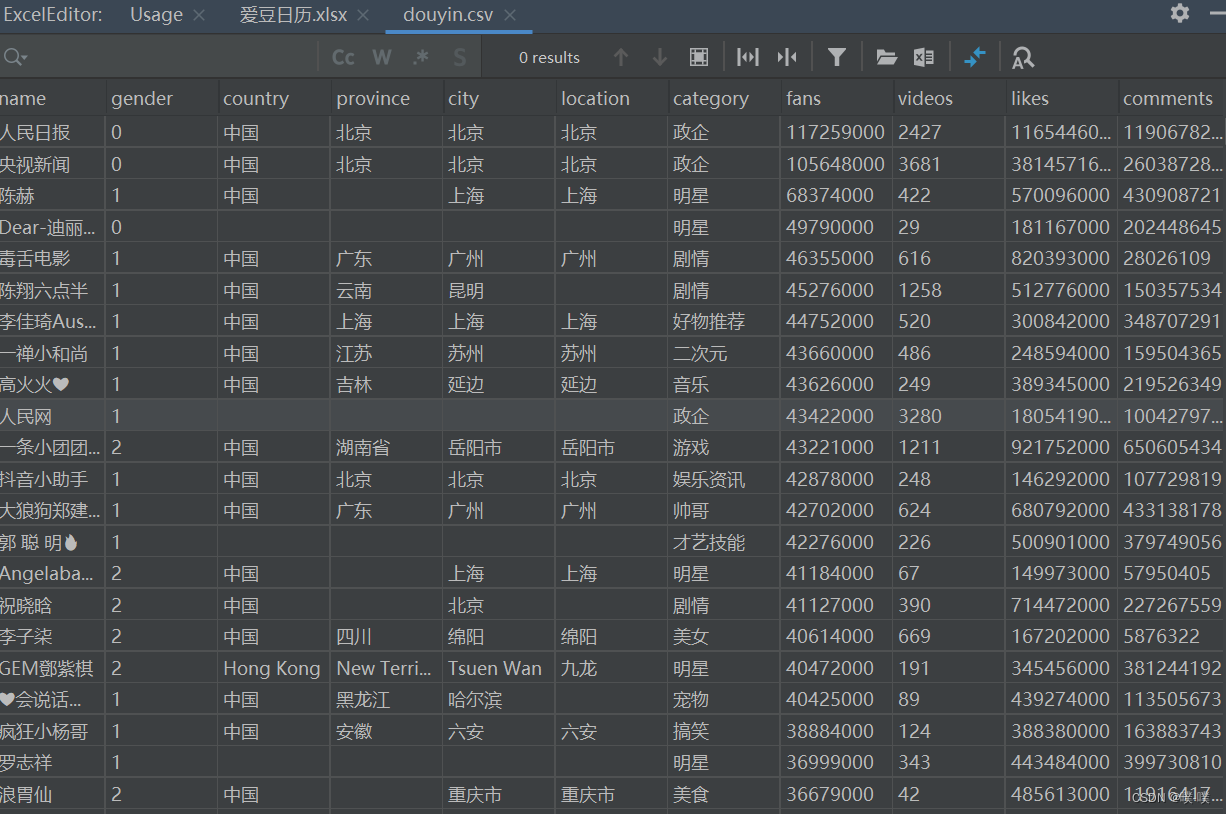
主要包含博主们的昵称、性别、地点、类型、点赞数、粉丝数、视频数、评论数、分享数、关注数、毕业学校、认证、简介等信息。
其中粉丝最多的是人民日报,接近1.2亿。其次是央视新闻,也破亿了。
三、数据可视化
首先导入相关库,然后读取数据【如何导入 看最后】
from pyecharts.charts import Pie, Bar, TreeMap, Map, Geo
from wordcloud import WordCloud, ImageColorGenerator
from pyecharts import options as opts
import matplotlib.pyplot as plt
from PIL import Image
import pandas as pd
import numpy as np
import jieba
df = pd.read_csv('douyin.csv', header=0, encoding='utf-8-sig')
print(df)1.性别分布情况
可视化代码如下:
def create_gender(df):
df = df.copy()
# 修改数值
df.loc[df.gender == '0', 'gender'] = '未知'
df.loc[df.gender == '1', 'gender'] = '男性'
df.loc[df.gender == '2', 'gender'] = '女性'
# 根据性别分组
gender_message = df.groupby(['gender'])
# 对分组后的结果进行计数
gender_com = gender_message['gender'].agg(['count'])
gender_com.reset_index(inplace=True)
# 饼图数据
attr = gender_com['gender']
v1 = gender_com['count']
# 初始化配置
pie = Pie(init_opts=opts.InitOpts(width="800px", height="400px"))
# 添加数据,设置半径
pie.add("", [list(z) for z in zip(attr, v1)], radius=["40%", "75%"])
# 设置全局配置项,标题、图例、工具箱(下载图片)
pie.set_global_opts(title_opts=opts.TitleOpts(title="抖音大V性别分布情况", pos_left="center", pos_top="top"),
legend_opts=opts.LegendOpts(orient="vertical", pos_left="left"),
toolbox_opts=opts.ToolboxOpts(is_show=True, feature={"saveAsImage": {}}))
# 设置系列配置项,标签样式
pie.set_series_opts(label_opts=opts.LabelOpts(is_show=True, formatter="{b}:{d}%"))
pie.render("抖音大V性别分布情况.html")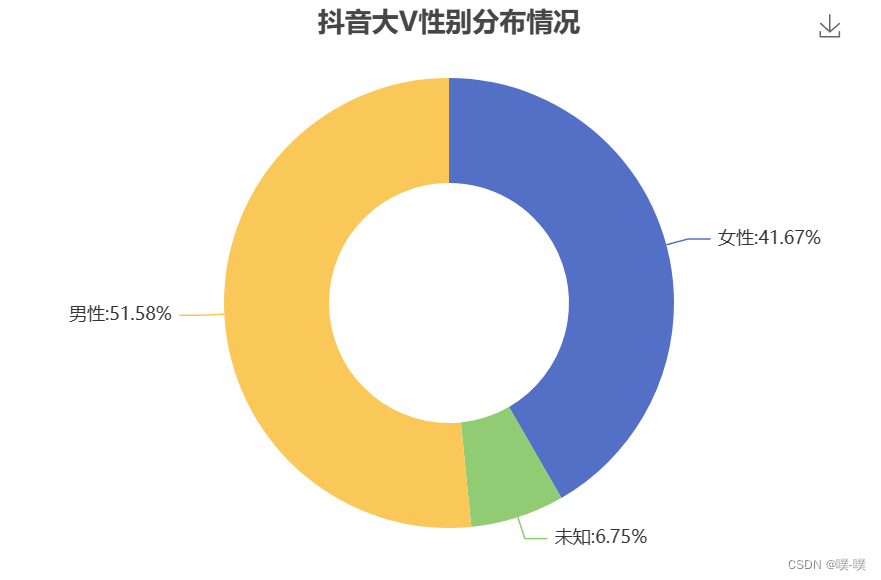
整体上看,男女比例差别不大,除去未知的数据,基本是1:1。
2.点赞数 、点赞分布情况
可视化代码如下:
def create_likes(df):
# 排序,降序
df = df.sort_values('likes', ascending=False)
# 获取TOP10的数据
attr = df['name'][0:10]
v1 = [float('%.1f' % (float(i) / 100000000)) for i in df['likes'][0:10]]
# 初始化配置
bar = Bar(init_opts=opts.InitOpts(width="800px", height="400px"))
# x轴数据
bar.add_xaxis(list(reversed(attr.tolist())))
# y轴数据
bar.add_yaxis("", list(reversed(v1)))
# 设置全局配置项,标题、工具箱(下载图片)、y轴分割线
bar.set_global_opts(title_opts=opts.TitleOpts(title="抖音大V点赞数TOP10(亿)", pos_left="center", pos_top="18"),
toolbox_opts=opts.ToolboxOpts(is_show=True, feature={"saveAsImage": {}}),
xaxis_opts=opts.AxisOpts(splitline_opts=opts.SplitLineOpts(is_show=True)))
# 设置系列配置项,标签样式
bar.set_series_opts(label_opts=opts.LabelOpts(is_show=True, position="right", color="black"))
bar.reversal_axis()
bar.render("抖音大V点赞数TOP10(亿).html")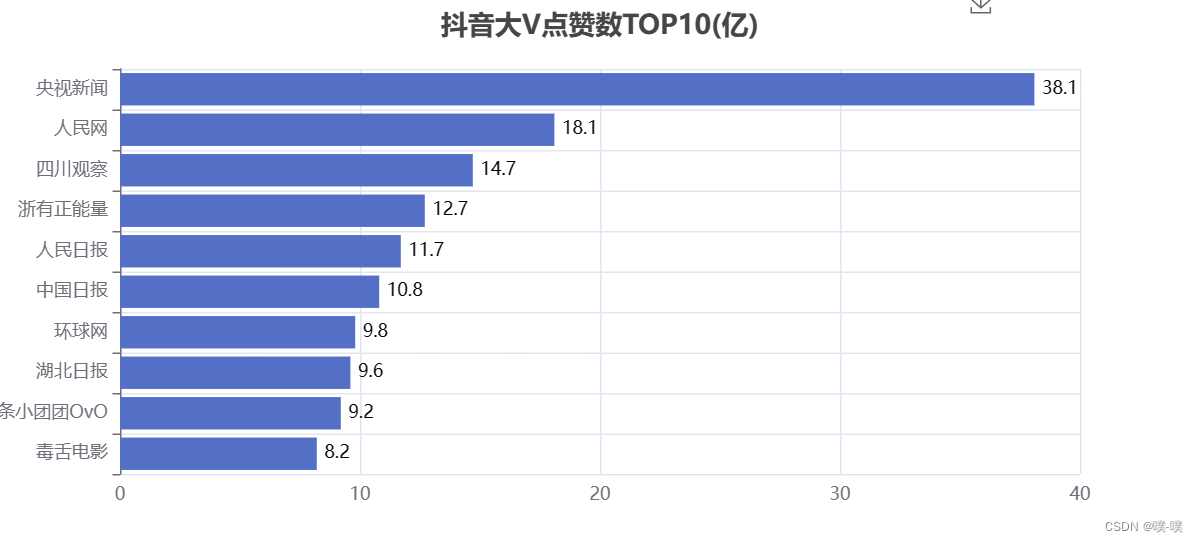
可视化代码如下:
def create_cut_likes(df):
# 将数据分段
Bins = [0, 1000000, 5000000, 10000000, 25000000, 50000000, 100000000, 5000000000]
Labels = ['0-100', '100-500', '500-1000', '1000-2500', '2500-5000', '5000-10000', '10000以上']
len_stage = pd.cut(df['likes'], bins=Bins, labels=Labels).value_counts().sort_index()
# 获取数据
attr = len_stage.index.tolist()
v1 = len_stage.values.tolist()
# 生成柱状图
bar = Bar(init_opts=opts.InitOpts(width="800px", height="400px"))
bar.add_xaxis(attr)
bar.add_yaxis("", v1)
bar.set_global_opts(title_opts=opts.TitleOpts(title="抖音大V点赞数分布情况(万)", pos_left="center", pos_top="18"),
toolbox_opts=opts.ToolboxOpts(is_show=True, feature={"saveAsImage": {}}),
yaxis_opts=opts.AxisOpts(splitline_opts=opts.SplitLineOpts(is_show=True)))
bar.set_series_opts(label_opts=opts.LabelOpts(is_show=True, position="top", color="black"))
bar.render("抖音大V点赞数分布情况(万).html")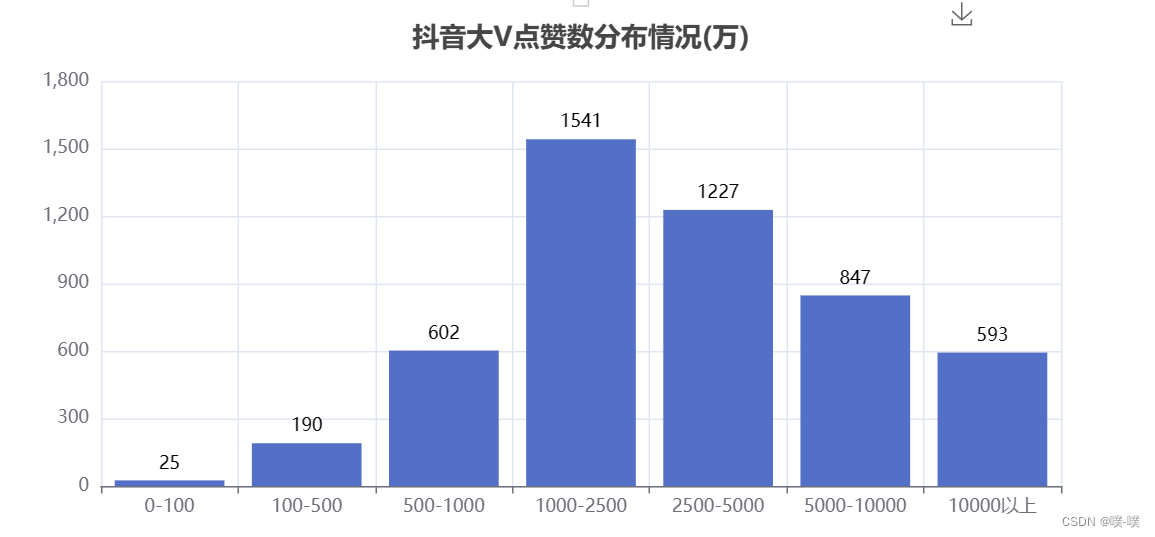
3. 粉丝数、粉丝分布情况
可视化代码如下:
def create_fans(df):
df = df.sort_values('fans', ascending=False)
attr = df['name'][0:10]
v1 = ['%.1f' % (float(i) / 10000) for i in df['fans'][0:10]]
bar = Bar(init_opts=opts.InitOpts(width="800px", height="400px"))
bar.add_xaxis(list(reversed(attr.tolist())))
bar.add_yaxis("", list(reversed(v1)))
bar.set_global_opts(title_opts=opts.TitleOpts(title="抖音大V粉丝数TOP10(万)", pos_left="center", pos_top="18"),
toolbox_opts=opts.ToolboxOpts(is_show=True, feature={"saveAsImage": {}}),
xaxis_opts=opts.AxisOpts(splitline_opts=opts.SplitLineOpts(is_show=True)))
bar.set_series_opts(label_opts=opts.LabelOpts(is_show=True, position="right", color="black"))
bar.reversal_axis()
bar.render("抖音大V粉丝数TOP10(万).html")
create_fans(df)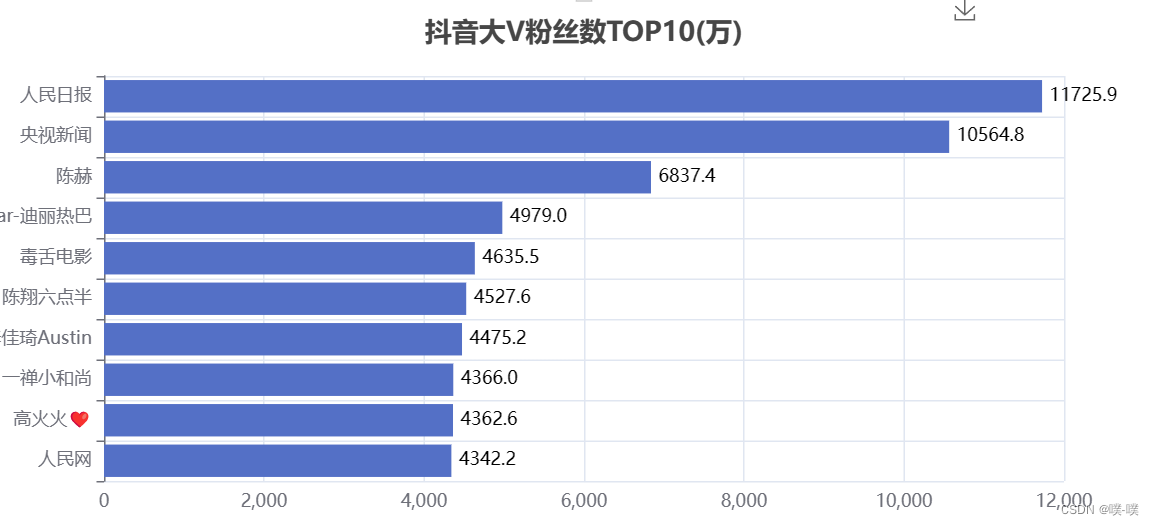 「人民日报」和「央视新闻」粉丝都破亿了。
「人民日报」和「央视新闻」粉丝都破亿了。
可视化代码如下:
def create_cut_fans(df):
Bins = [0, 1500000, 2000000, 5000000, 10000000, 25000000, 200000000]
Labels = ['0-150', '150-200', '200-500', '500-1000', '1000-2500', '5000以上']
len_stage = pd.cut(df['fans'], bins=Bins, labels=Labels).value_counts().sort_index()
attr = len_stage.index.tolist()
v1 = len_stage.values.tolist()
bar = Bar(init_opts=opts.InitOpts(width="800px", height="400px"))
bar.add_xaxis(attr)
bar.add_yaxis("", v1)
bar.set_global_opts(title_opts=opts.TitleOpts(title="抖音大V粉丝数分布情况(万)", pos_left="center", pos_top="18"),
toolbox_opts=opts.ToolboxOpts(is_show=True, feature={"saveAsImage": {}}),
yaxis_opts=opts.AxisOpts(splitline_opts=opts.SplitLineOpts(is_show=True)))
bar.set_series_opts(label_opts=opts.LabelOpts(is_show=True, position="top", color="black"))
bar.render("抖音大V粉丝数分布情况(万).html")
create_cut_fans(df)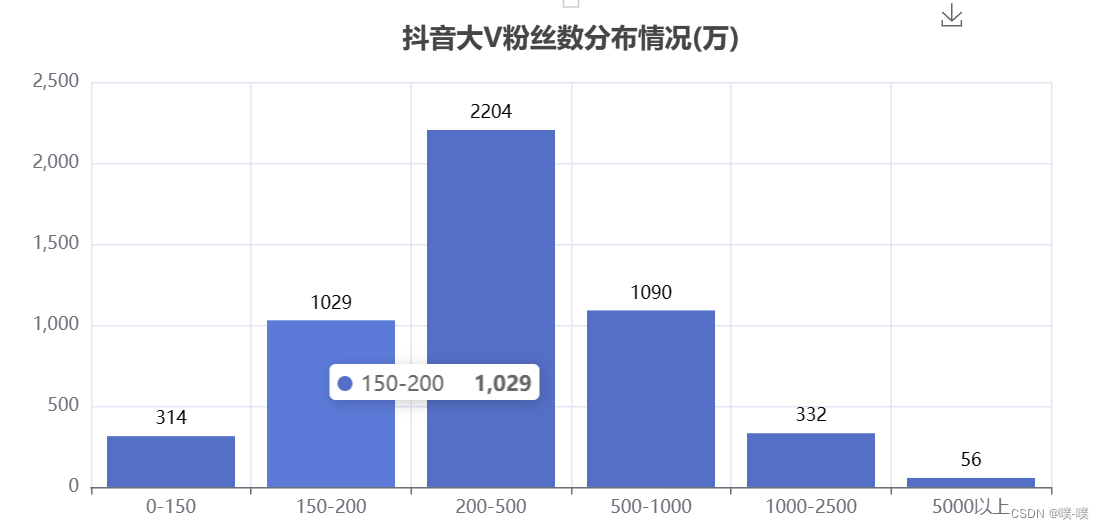
5000万以上56个,妥妥的大佬。200w~500w的人数最多,好多一时爆火的博主,一段时间后也基本不怎么涨粉了
4. 评论数
可视化代码如下:
def create_comments(df):
df = df.sort_values('comments', ascending=False)
attr = df['name'][0:10]
v1 = ['%.1f' % (float(i) / 100000000) for i in df['comments'][0:10]]
bar = Bar(init_opts=opts.InitOpts(width="800px", height="400px"))
bar.add_xaxis(list(reversed(attr.tolist())))
bar.add_yaxis("", list(reversed(v1)))
bar.set_global_opts(title_opts=opts.TitleOpts(title="抖音大V评论数TOP10(亿)", pos_left="center", pos_top="18"),
toolbox_opts=opts.ToolboxOpts(is_show=True, feature={"saveAsImage": {}}),
xaxis_opts=opts.AxisOpts(splitline_opts=opts.SplitLineOpts(is_show=True)))
bar.set_series_opts(label_opts=opts.LabelOpts(is_show=True, position="right", color="black"))
bar.reversal_axis()
bar.render("抖音大V评论数TOP10(亿).html")
create_comments(df)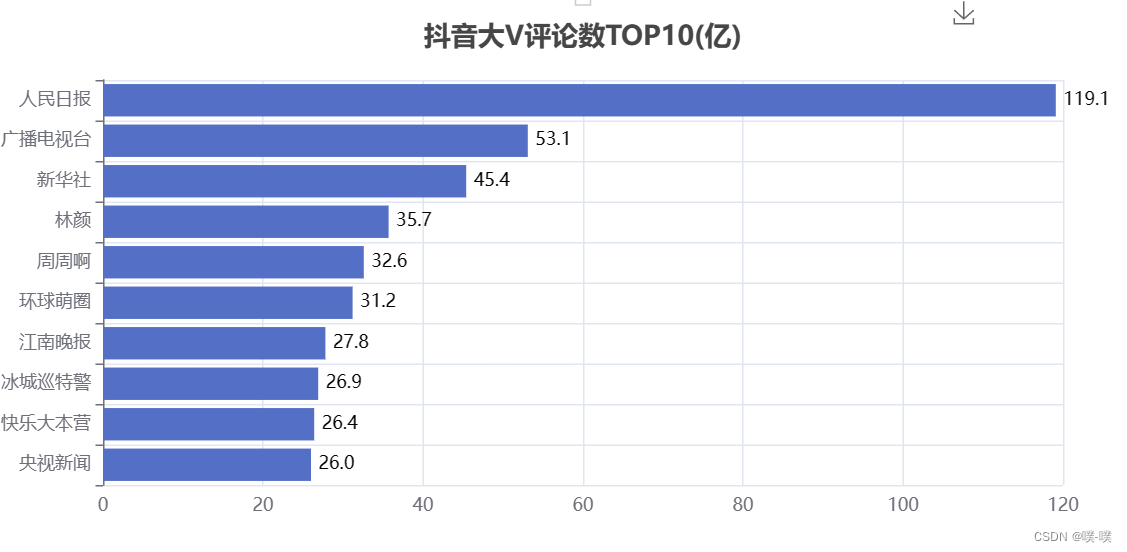
抖音视频的评论区也是比较有意思的地方。比如刷剧催更的,「赶紧去更新,都过了十几分钟了,生产队的驴都不敢休息这么久」,总的来说,媒体类的视频评论较多。
5.分享数
可视化代码如下:
def create_shares(df):
df = df.sort_values('shares', ascending=False)
attr = df['name'][0:10]
v1 = ['%.1f' % (float(i) / 100000000) for i in df['shares'][0:10]]
bar = Bar(init_opts=opts.InitOpts(width="800px", height="400px"))
bar.add_xaxis(list(reversed(attr.tolist())))
bar.add_yaxis("", list(reversed(v1)))
bar.set_global_opts(title_opts=opts.TitleOpts(title="抖音大V分享数TOP10(亿)", pos_left="center", pos_top="18"),
toolbox_opts=opts.ToolboxOpts(is_show=True, feature={"saveAsImage": {}}),
xaxis_opts=opts.AxisOpts(splitline_opts=opts.SplitLineOpts(is_show=True)))
bar.set_series_opts(label_opts=opts.LabelOpts(is_show=True, position="right", color="black"))
bar.reversal_axis()
bar.render("抖音大V分享数TOP10(亿).html")
create_shares(df)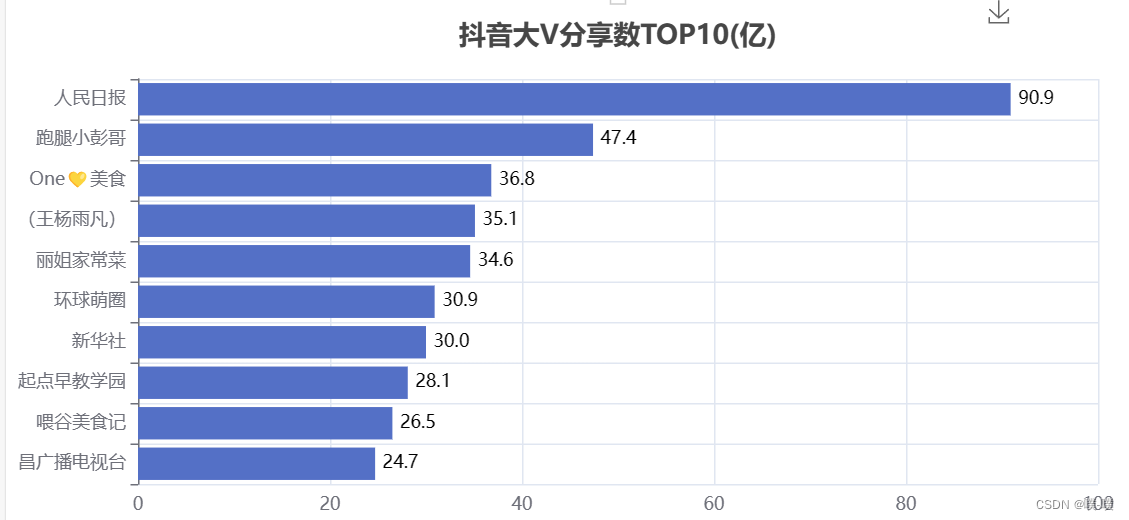
抖音的分享是视频对外传播的一个方法,可以让更多的人看到视频。从数据上看,大家还是比较喜欢分享新闻类以及美食类的视频。
6.各类型点赞数/粉丝数汇总分布图
可视化代码如下:
def create_type_likes(df):
# 分组求和
likes_type_message = df.groupby(['category'])
likes_type_com = likes_type_message['likes'].agg(['sum'])
likes_type_com.reset_index(inplace=True)
# 处理数据
dom = []
for name, num in zip(likes_type_com['category'], likes_type_com['sum']):
data = {}
data['name'] = name
data['value'] = num
dom.append(data)
print(dom)
# 初始化配置
treemap = TreeMap(init_opts=opts.InitOpts(width="800px", height="400px"))
# 添加数据
treemap.add('', dom)
# 设置全局配置项,标题、工具箱(下载图片)
treemap.set_global_opts(title_opts=opts.TitleOpts(title="各类型抖音大V点赞数汇总图", pos_left="center", pos_top="5"),
toolbox_opts=opts.ToolboxOpts(is_show=True, feature={"saveAsImage": {}}),
legend_opts=opts.LegendOpts(is_show=False))
treemap.render("各类型抖音大V点赞数汇总图.html")
create_type_likes(df)
def create_type_fans(df):
dom = []
fans_type_message = df.groupby(['category'])
fans_type_com = fans_type_message['fans'].agg(['sum'])
fans_type_com.reset_index(inplace=True)
for name, num in zip(fans_type_com['category'], fans_type_com['sum']):
data = {}
data['name'] = name
data['value'] = num
dom.append(data)
print(dom)
treemap = TreeMap(init_opts=opts.InitOpts(width="800px", height="400px"))
treemap.add('', dom)
treemap.set_global_opts(title_opts=opts.TitleOpts(title="各类型抖音大V粉丝数汇总图", pos_left="center", pos_top="5"),
toolbox_opts=opts.ToolboxOpts(is_show=True, feature={"saveAsImage": {}}),
legend_opts=opts.LegendOpts(is_show=False))
treemap.set_series_opts(treemapbreadcrumb_opts=opts.TreeMapBreadcrumbOpts(is_show=False))
treemap.render("各类型抖音大V粉丝数汇总图.html")
create_type_fans(df)
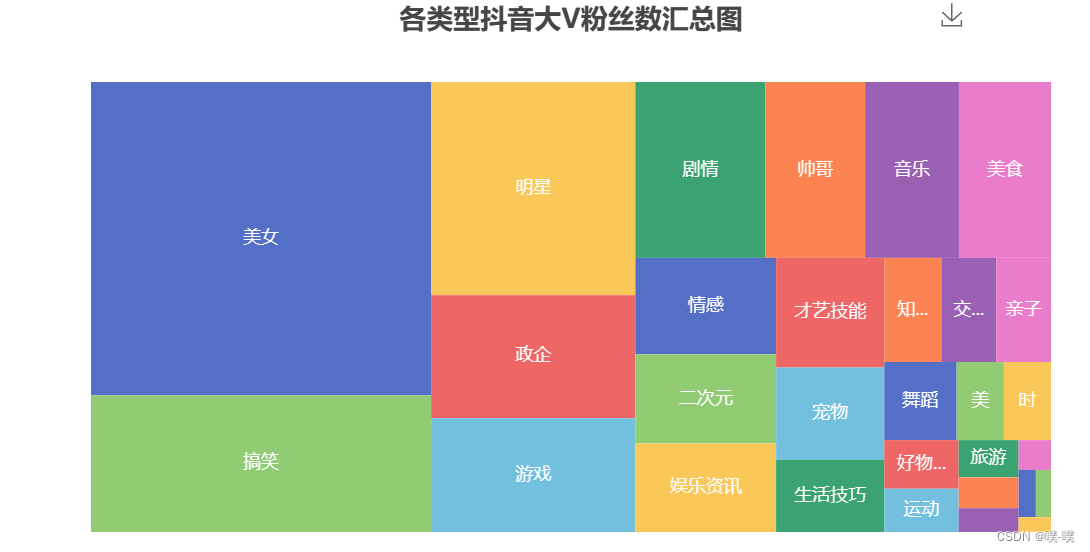
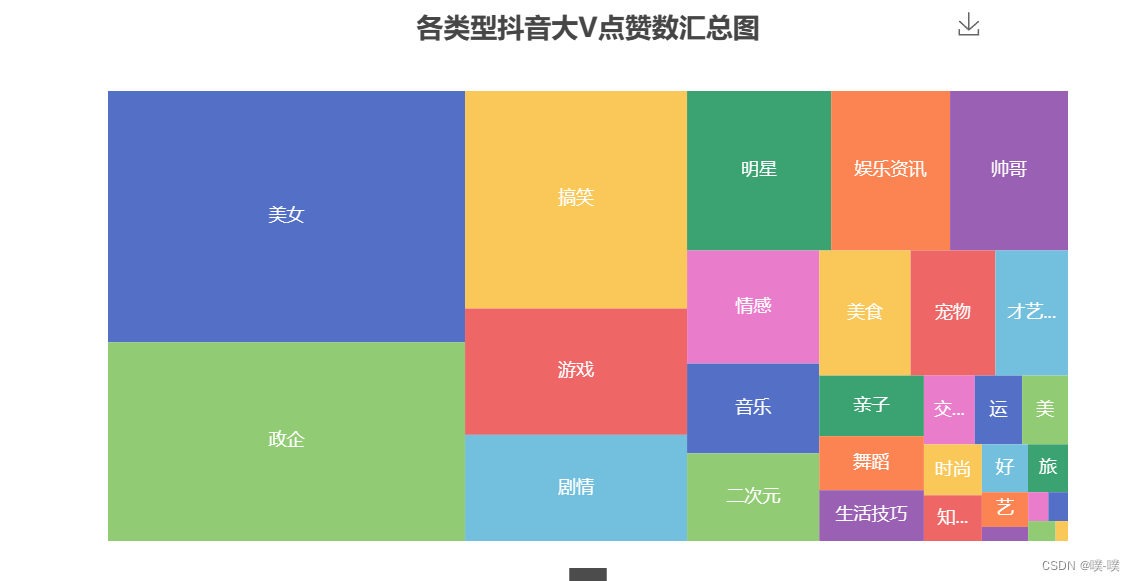
抖音这个产品是消磨你时间的,而不是节约时间,技术稍微深一点的视频基本上生存不下去。由上面的矩形树图可以知道,大家都喜欢「美女」类型的视频,毕竟谁不喜欢漂亮妹子呢~
7.平均视频点赞数/粉丝数
可视化代码如下:
def create_avg_likes(df):
# 筛选
df = df[df['videos'] > 0]
# 计算单个视频平均点赞数
df.eval('result = likes/(videos*10000)', inplace=True)
df['result'] = df['result'].round(decimals=1)
df = df.sort_values('result', ascending=False)
# 取TOP10
attr = df['name'][0:10]
v1 = ['%.1f' % (float(i)) for i in df['result'][0:10]]
# 初始化配置
bar = Bar(init_opts=opts.InitOpts(width="800px", height="400px"))
# 添加数据
bar.add_xaxis(list(reversed(attr.tolist())))
bar.add_yaxis("", list(reversed(v1)))
# 设置全局配置项,标题、工具箱(下载图片)、y轴分割线
bar.set_global_opts(title_opts=opts.TitleOpts(title="抖音大V平均视频点赞数TOP10(万)", pos_left="center", pos_top="18"),
toolbox_opts=opts.ToolboxOpts(is_show=True, feature={"saveAsImage": {}}),
xaxis_opts=opts.AxisOpts(splitline_opts=opts.SplitLineOpts(is_show=True)))
# 设置系列配置项
bar.set_series_opts(label_opts=opts.LabelOpts(is_show=True, position="right", color="black"))
# 翻转xy轴
bar.reversal_axis()
bar.render("抖音大V平均视频点赞数TOP10(万).html")
create_avg_likes(df)
def create_avg_fans(df):
df = df[df['videos'] > 0]
df.eval('result = fans/(videos*10000)', inplace=True)
df['result'] = df['result'].round(decimals=1)
df = df.sort_values('result', ascending=False)
attr = df['name'][0:10]
v1 = ['%.1f' % (float(i)) for i in df['result'][0:10]]
bar = Bar(init_opts=opts.InitOpts(width="800px", height="400px"))
bar.add_xaxis(list(reversed(attr.tolist())))
bar.add_yaxis("", list(reversed(v1)))
bar.set_global_opts(title_opts=opts.TitleOpts(title="抖音大V平均视频粉丝数TOP10(万)", pos_left="center", pos_top="18"),
toolbox_opts=opts.ToolboxOpts(is_show=True, feature={"saveAsImage": {}}),
xaxis_opts=opts.AxisOpts(splitline_opts=opts.SplitLineOpts(is_show=True)))
bar.set_series_opts(label_opts=opts.LabelOpts(is_show=True, position="right", color="black"))
bar.reversal_axis()
bar.render("抖音大V平均视频粉丝数TOP10(万).html")
create_avg_fans(df)
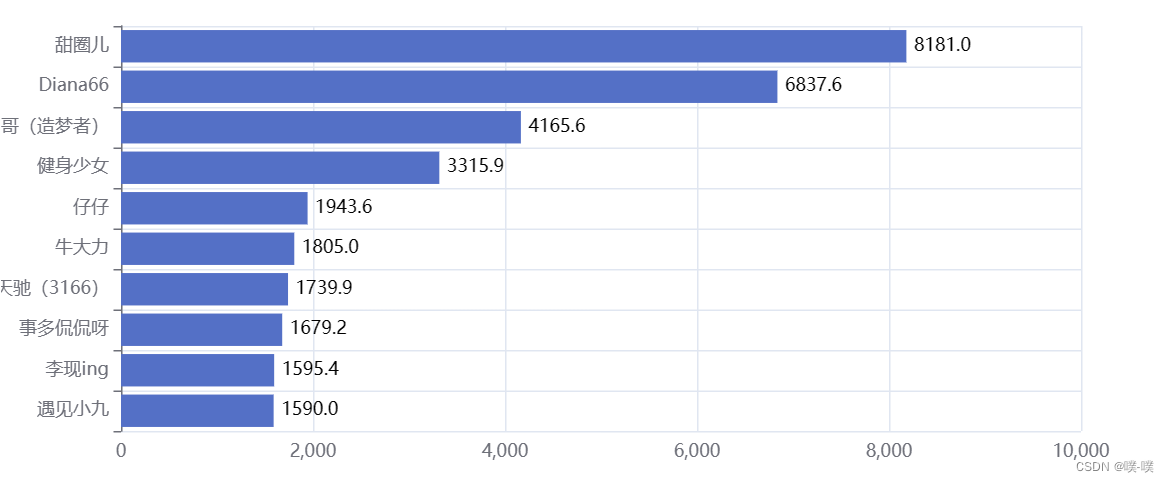
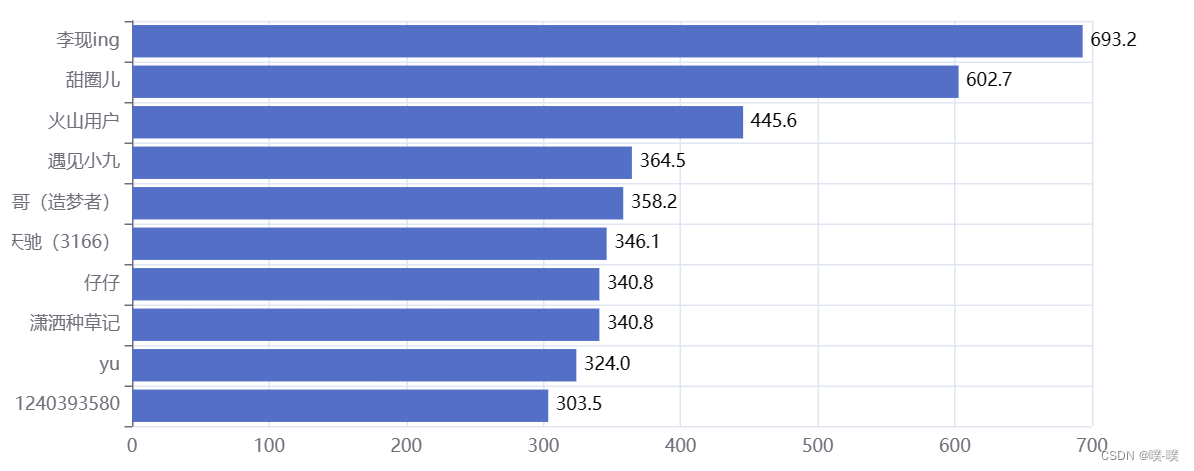 8. 抖音大V分布情况
8. 抖音大V分布情况
可视化代码如下:
def create_province_map(df):
# 筛选数据
df = df[df["country"] == "中国"]
df1 = df.copy()
# 数据替换
df1["province"] = df1["province"].str.replace("省", "").str.replace("壮族自治区", "").str.replace("维吾尔自治区", "").str.replace("自治区", "")
# 分组计数
df_num = df1.groupby("province")["province"].agg(count="count")
df_province = df_num.index.values.tolist()
df_count = df_num["count"].values.tolist()
# 初始化配置
map = Map(init_opts=opts.InitOpts(width="800px", height="400px"))
# 中国地图
map.add("", [list(z) for z in zip(df_province, df_count)], "china")
# 设置全局配置项,标题、工具箱(下载图片)、颜色图例
map.set_global_opts(title_opts=opts.TitleOpts(title="抖音大V省份分布情况", pos_left="center", pos_top="0"),
toolbox_opts=opts.ToolboxOpts(is_show=True, feature={"saveAsImage": {}}),
# 设置数值范围0-600,is_piecewise标签值连续
visualmap_opts=opts.VisualMapOpts(max_=600, is_piecewise=False))
map.render("抖音大V省份分布情况.html")
create_province_map(df)
def create_city_map(df):
df1 = df[df["country"] == "中国"]
df1 = df1.copy()
df1["city"] = df1["city"].str.replace("市", "")
df_num = df1.groupby("city")["city"].agg(count="count").reset_index().sort_values(by="count", ascending=False)
df_city = df_num["city"].values.tolist()
df_count = df_num["count"].values.tolist()
# 初始化配置
geo = Geo(init_opts=opts.InitOpts(width="800px", height="400px"))
# 中国地图
geo.add("", [list(z) for z in zip(df_city, df_count)], "china")
# 设置全局配置项,标题、工具箱(下载图片)、颜色图例
geo.set_global_opts(title_opts=opts.TitleOpts(title="抖音大V城市分布情况", pos_left="center", pos_top="0"),
toolbox_opts=opts.ToolboxOpts(is_show=True, feature={"saveAsImage": {}}),
# 设置数值范围0-600,is_piecewise标签值连续
visualmap_opts=opts.VisualMapOpts(is_piecewise=True))
geo.set_series_opts(label_opts=opts.LabelOpts(is_show=False))
map.render("抖音大V城市分布情况.html")
# create_city_map(df)
def create_city(df):
df1 = df[df["country"] == "中国"]
df1 = df1.copy()
df1["city"] = df1["city"].str.replace("市", "")
df_num = df1.groupby("city")["city"].agg(count="count").reset_index().sort_values(by="count", ascending=False)
df_city = df_num[:10]["city"].values.tolist()
df_count = df_num[:10]["count"].values.tolist()
bar = Bar(init_opts=opts.InitOpts(width="800px", height="400px"))
bar.add_xaxis(df_city)
bar.add_yaxis("", df_count)
bar.set_global_opts(title_opts=opts.TitleOpts(title="抖音大V城市分布TOP10", pos_left="center", pos_top="18"),
toolbox_opts=opts.ToolboxOpts(is_show=True, feature={"saveAsImage": {}}),
yaxis_opts=opts.AxisOpts(splitline_opts=opts.SplitLineOpts(is_show=True)))
bar.set_series_opts(label_opts=opts.LabelOpts(is_show=True, position="top", color="black"))
bar.render("抖音大V城市分布TOP10.html")
create_city(df)
def create_abroad(df):
# 筛选数据
df = df[(df["country"] != "中国") & (df["country"] != "") & (df["country"] != "暂不设置") & (df["country"] != "China")]
df1 = df.copy()
# 数据替换
df1["country"] = df1["country"].str.replace("United States", "美国").replace("大韩民国", "韩国")
# 分组计数
df_num = df1.groupby("country")["country"].agg(count="count").reset_index().sort_values(by="count", ascending=False)
df_country = df_num[:8]["country"].values.tolist()
df_count = df_num[:8]["count"].values.tolist()
# 初始化配置
bar = Bar(init_opts=opts.InitOpts(width="800px", height="400px"))
bar.add_xaxis(df_country)
bar.add_yaxis("", df_count)
bar.set_global_opts(title_opts=opts.TitleOpts(title="抖音大V国外分布TOP10", pos_left="center", pos_top="18"),
toolbox_opts=opts.ToolboxOpts(is_show=True, feature={"saveAsImage": {}}),
yaxis_opts=opts.AxisOpts(splitline_opts=opts.SplitLineOpts(is_show=True)))
bar.set_series_opts(label_opts=opts.LabelOpts(is_show=True, position="top", color="black"))
bar.render("抖音大V国外分布TOP10.html")
# create_abroad(df)
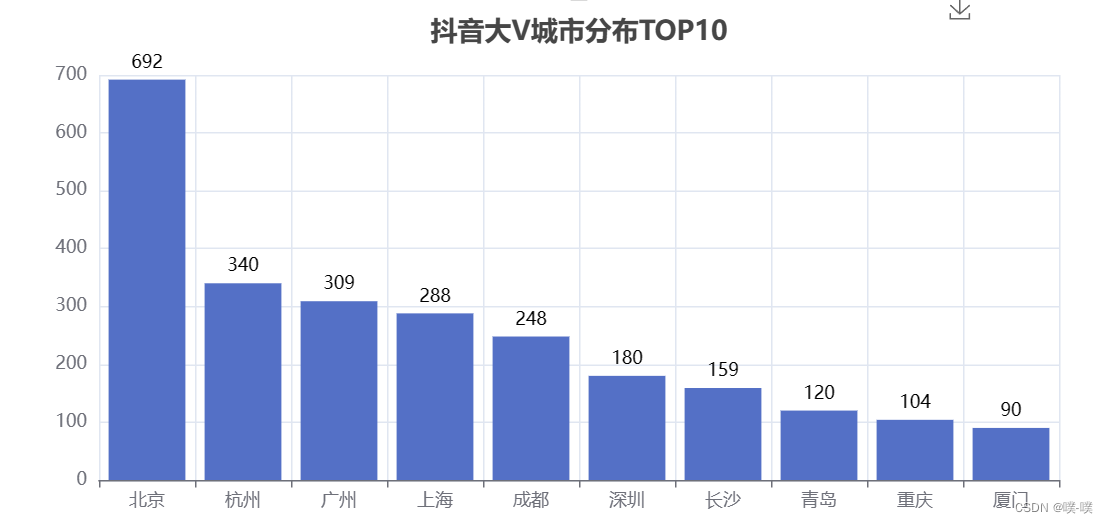
北京遥遥领先,大V的聚集地。杭州盛产网红的城市,位列第二。
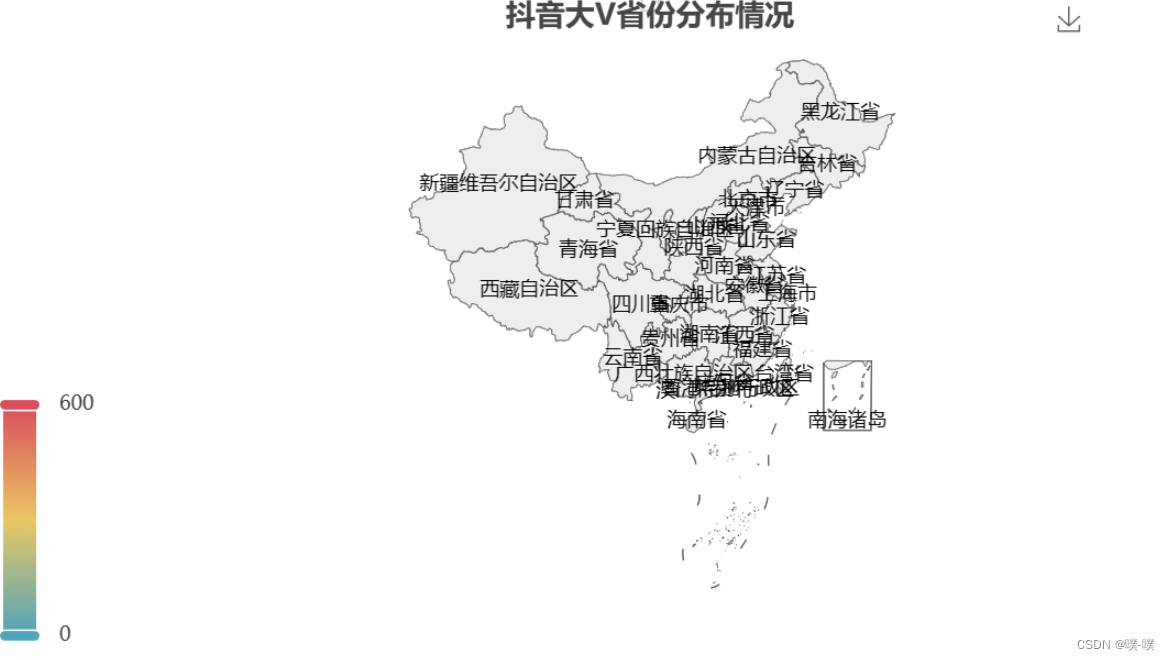
广东、浙江、四川位列前三。
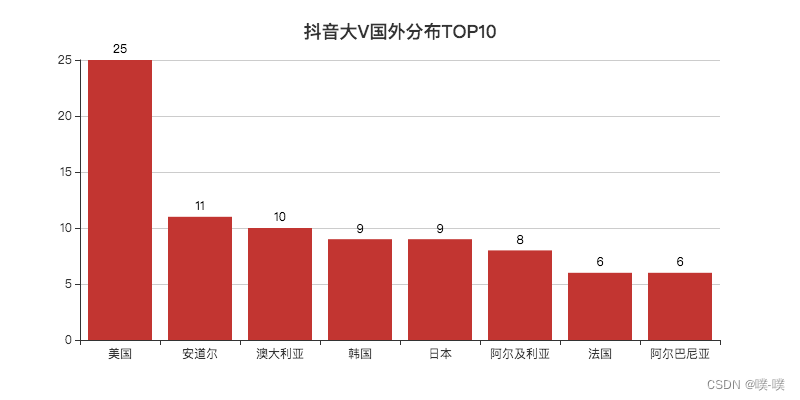
美国居第一,不少在美国的华人会分享他们在美国生活的一些事情。国内也有人感兴趣这方面的东西,看看国外的月亮究竟圆不圆。
9.抖音大V毕业学校
def create_school(df):
df1 = df[(df["school"] != "") & (df["school"] != "已毕业") & (df["school"] != "未知")]
df1 = df1.copy()
df_num = df1.groupby("school")["school"].agg(count="count").reset_index().sort_values(by="count", ascending=False)
df_school = df_num[:10]["school"].values.tolist()
df_count = df_num[:10]["count"].values.tolist()
# 初始化配置
bar = Bar(init_opts=opts.InitOpts(width="1200px", height="400px"))
bar.add_xaxis(df_school)
bar.add_yaxis("", df_count)
bar.set_global_opts(title_opts=opts.TitleOpts(title="抖音大V毕业学校TOP10", pos_left="center", pos_top="18"),
toolbox_opts=opts.ToolboxOpts(is_show=True, feature={"saveAsImage": {}}),
yaxis_opts=opts.AxisOpts(splitline_opts=opts.SplitLineOpts(is_show=True)))
bar.set_series_opts(label_opts=opts.LabelOpts(is_show=True, position="top", color="black"))
bar.render("抖音大V毕业学校TOP10.html")
create_school(df)
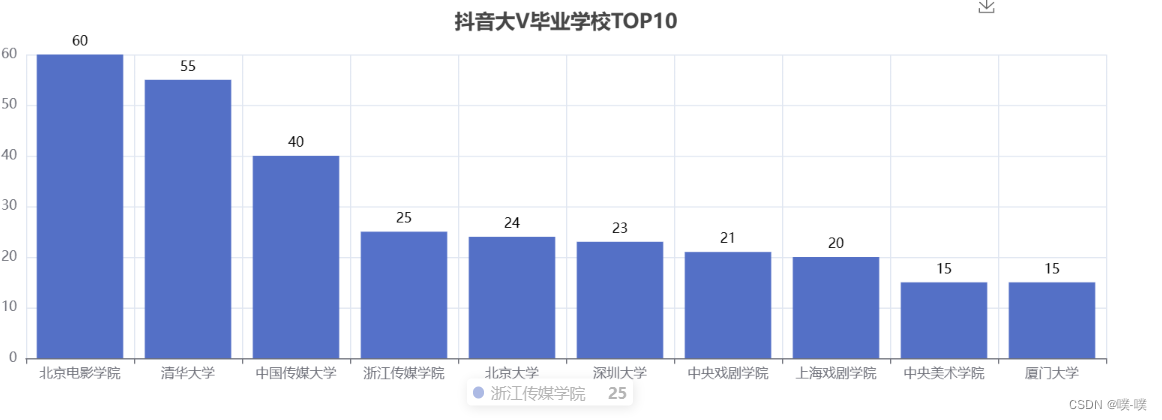 北影、中传、浙传、中戏、上戏、央美,妥妥的演艺圈大佬。
北影、中传、浙传、中戏、上戏、央美,妥妥的演艺圈大佬。
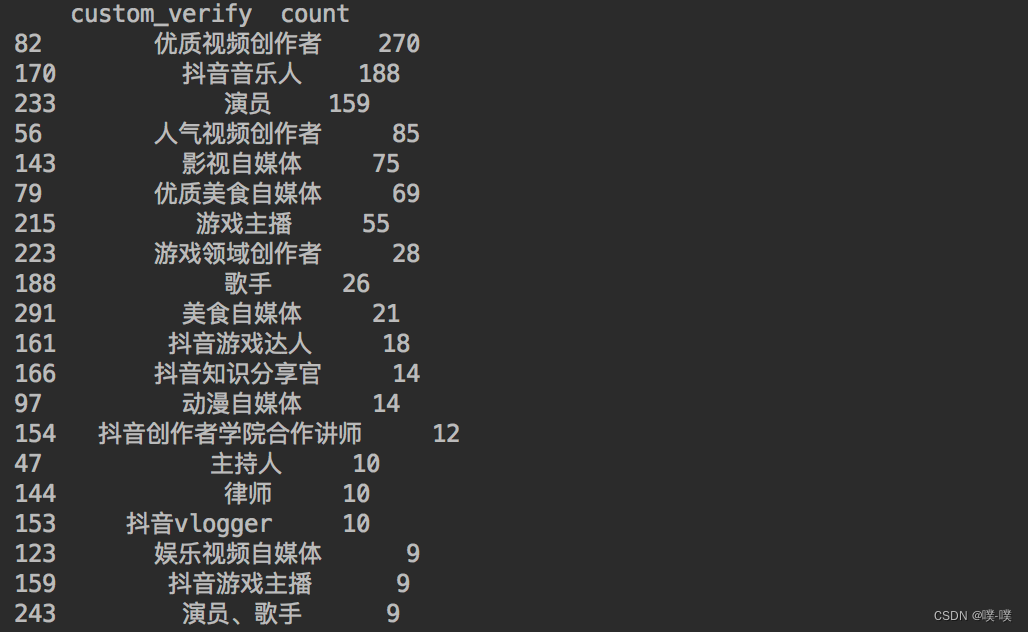
这里 通过代码查询一下大V们的认证情况:
df1 = df[(df["custom_verify"] != "") & (df["custom_verify"] != "未知")]
df1 = df1.copy()
df_num = df1.groupby("custom_verify")["custom_verify"].agg(count="count").reset_index().sort_values(by="count", ascending=False)
print(df_num[:20])得到结果如下:
10. 抖音大V简介词云
可视化代码如下:
def create_wordcloud(df, picture):
words = pd.read_csv('chineseStopWords.txt', encoding='gbk', sep='\t', names=['stopword'])
# 分词
text = ''
df1 = df[df["signature"] != ""]
df1 = df1.copy()
for line in df1['signature']:
text += ' '.join(jieba.cut(str(line).replace(" ", ""), cut_all=False))
# 停用词
stopwords = set('')
stopwords.update(words['stopword'])
backgroud_Image = plt.imread('douyin.png')
# 使用抖音背景色
alice_coloring = np.array(Image.open(r"douyin.png"))
image_colors = ImageColorGenerator(alice_coloring)
wc = WordCloud(
background_color='white',
mask=backgroud_Image,
font_path='方正兰亭刊黑.TTF',
max_words=2000,
max_font_size=70,
min_font_size=1,
prefer_horizontal=1,
color_func=image_colors,
random_state=50,
stopwords=stopwords,
margin=5
)
wc.generate_from_text(text)
# 看看词频高的有哪些
process_word = WordCloud.process_text(wc, text)
sort = sorted(process_word.items(), key=lambda e: e[1], reverse=True)
print(sort[:50])
plt.imshow(wc)
plt.axis('off')
wc.to_file(picture)
print('生成词云成功!')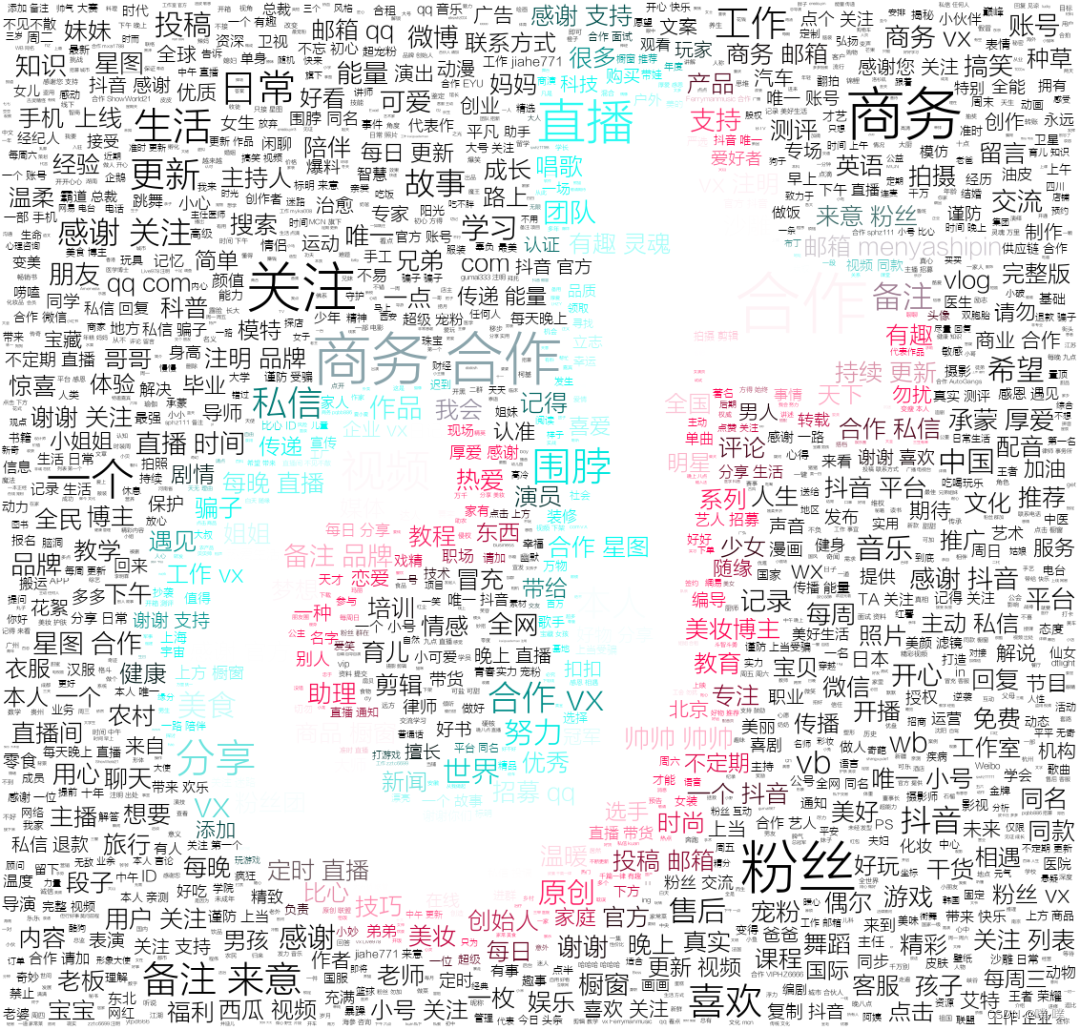
四、注意事项
1.所有的代码放到同一个py文件中
2.在数据可视化过程中,难免会需要导入不同的库,这里建议使用WIN+R打开命令提示符,并使用国内镜像安装库(下载快),比如安装wordcloud库是,使用下列代码:
pip install wordcloud -i https://pypi.tuna.tsinghua.edu.cn/simple/这里用的是清华的镜像,其他镜像:
企业贡献:
(1).网易开源镜像站:http://mirrors.163.com/
(2).华为开源镜像站:https://mirrors.huaweicloud.com/
(3).阿里开源镜像站:https://developer.aliyun.com/mirror/
大学教学:
(1).清华大学开源镜像站:https://mirrors.tuna.tsinghua.edu.cn/
(2).浙江大学开源镜像站:http://mirrors.zju.edu.cn/
(3).东北大学开源镜像站:http://mirror.neu.edu.cn/
安装库的时候,建议更新一下你的pip库,命令:
python -m pip install --upgrade pip3.最后运行成功后会自动生成.html文件,如果你想要看到图,这时你就需要把.html文件拉到桌面上,用浏览器打开

如果需要源码,可在评论区说。



















 1084
1084

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











